그래프
🎯 Keyword : Graph, DFS, BFS, Flood Fill
1. 그래프란
1-1. 개론
그래프의 정의는 다음과 같다.
그래프는 vertex와 edge로 구성된 한정된 자료구조를 의미한다. vertex는 정점, edge는 정점과 정점을 연결하는 간선이다. - 위키피디아
다음은 정점과 간선을 3개씩 갖는 그래프다. 원이 정점, 원 사이를 잇는 화살표가 간선이다.
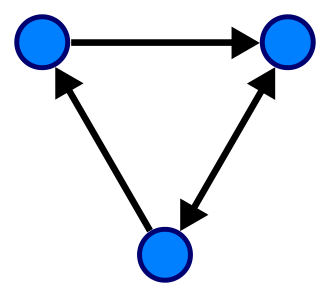
1-2. 왜 그래프인가?
그래프는 포함된 요소들 사이의 관계를 표현하는 데 용이하다. 아래 그림은 서울의 지하철 노선도이다. 지하철 역은 정점, 지하철 사이를 잇는 철도는 간선으로 표현했음을 알 수 있다.
1-3. 그래프의 표현
컴퓨터 프로그램 상에서 그래프를 표현하는 대표적인 방법으로 인접 행렬 방식과 인접 리스트 방식이 있다.
1-3-1) 인접 행렬
인접 행렬 방식은 2차원 배열을 이용하는 방식이다. 정점 와 가 연결되어 있다면 행 열의 원소 로 표현한다. 연결되지 않았다면 으로 표현한다. 수식으로 나타내면 다음과 같다.
예를 들어 다음 그래프를 살펴보자.
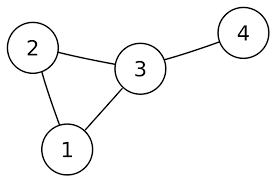
위 그래프에서 얻을 수 있는 정보는 다음과 같다.
정점 1은 정점 2, 3에 연결되어 있다.
정점 2는 정점 1, 3에 연결되어 있다.
정점 3은 정점 1, 2, 4에 연결되어 있다.
정점 4는 정점 3에 연결되어 있다.
위 정보를 행렬의 형태로 나타내면 다음과 같다.
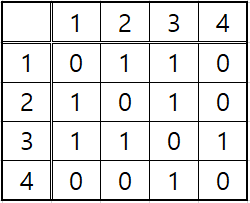
C언어에서는 다음과 같이 인접행렬을 사용할 수 있다.
int adj[<정점 개수>][<정점 개수>] = { 0, }; // 인접 행렬 생성 및 초기화
adj[<정점1 번호>][<정점2 번호>] = adj[<정점2 번호>][<정점1 번호>] = 1; // 정점1과 정점2 사이를 연결함
adj[<정점1 번호>][<정점2 번호>] = adj[<정점2 번호>][<정점1 번호>] = 0; // 정점1과 정점2 사이의 연결을 끊음위 코드에서 인접 행렬은 정점 개수가 개일 때 byte의 메모리 공간을 차지한다. 0과 1은 1비트만으로도 표현할 수 있으므로 인접행렬방식은 적어도 byte의 메모리 공간을 차지함을 알 수 있다.
1-3-2) 인접 리스트
인접 배열에서는 정점이 연결되어 있으면 1, 정점이 연결되어 있지 않으면 0으로 표현했다. 인접 리스트에서는 한 정점에 연결된 정점들만 집합의 형태로 표현한다는 점에서 다르다. 수식으로 나타내면 다음과 같다.
이번에는 위에서 살펴본 그래프를 인접 리스트로 나타내보자.
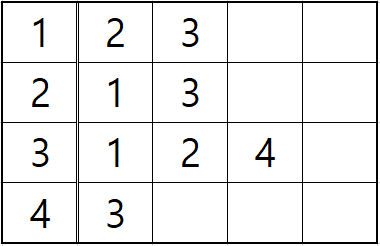
위와 같이 번째 행에는 정점 와 연결된 정점들의 번호를 저장한다. C++ 코드로 나타내면 다음과 같다.
#include <vector>
vector<int> adj[<정점 개수>]; // 인접 리스트 생성
// 정점1과 정점2 사이를 연결함
adj[<정점1 번호>].push_back(<정점2 번호>);
adj[<정점2 번호>].push_back(<정점1 번호>);
// 정점1과 정점2 사이의 연결을 끊음
adj[<정점1 번호>].erase(std::remove(adj[<정점1 번호>].begin(), adj[<정점1 번호>].end(), <정점2 번호>), adj[<정점1 번호>].end());
adj[<정점2 번호>].erase(std::remove(adj[<정점2 번호>].begin(), adj[<정점2 번호>].end(), <정점1 번호>), adj[<정점2 번호>].end());std::remove와 std::vector.erase()는 이 곳을 참조하세요.
이 때문에 인접 리스트가 차지하는 메모리 공간은 간선의 개수에 따라 달라진다. 정점의 개수가 unsigned short의 최대 표현 범위인 65,535를 넘어가는 일반적인 PS 상황에서는 정점의 번호를 int 또는 그보다 큰 표현 범위의 자료형으로 저장해야 할 것이다. 이 경우에는 간선의 개수 에 대해 인접 리스트의 요소가 차지하는 메모리 공간을 byte 로 표현할 수 있다. 또는 무향그래프인 경우 byte 로도 나타낼 수 있다.
1-3-3) 성능 비교
위에서 설명한 내용을 정리해보자면 인접 행렬은 byte의 메모리를, 인접 리스트는 byte의 메모리를 필요로 한다.
거의 모든 정점들 사이에 간선이 존재하는 경우에 일 것이다. 이 2 이상의 자연수일 때 이므로 인접 행렬이 인접 리스트보다 더 적은 메모리를 사용한다. 반면 간선이 거의 존재하지 않는 희소그래프의 경우에는 인접 리스트가 인접 행렬보다 더 적은 메모리를 사용한다. 따라서 상황에 맞게 판단해야 한다.
한편 위 코드에서 인접리스트를 구현하기 위해 사용한 vector의 push_back, erase, std::remove는 인접 행렬의 원소 접근보다 훨씬 느리다. 따라서 알고리즘 문제를 풀 때 메모리 공간이 충분하다면 인접 행렬을 쓰는 것이 더 나을 수 있다.
1-4. DFS
그래프 탐색이란 한 정점에서 시작해 연결된 모든 정점을 차례대로 방문하는 작업이다. 여러 그래프 탐색 방법 중 하나가 DFS다. 'DFS'는 Depth-First-Search(깊이 우선 탐색)의 약자다. 이런 이름이 붙은 이유는 가능한 깊게 파고들어가는 방식으로 탐색하기 때문이다. 스택을 이용한 DFS의 알고리즘은 다음과 같다.
- 스택에 시작노드를 push한다.
- 스택이 비어있다면 탐색을 종료한다.
- pop하여 top에 있는 노드를 꺼낸다.
- 꺼낸 노드를 이미 방문했었다면 1로 돌아간다.
- 꺼낸 노드를 방문한다.
- 꺼낸 노드와 인접하면서 아직 방문하지 않은 노드들을 스택에 push한다.
- 1로 돌아간다.
혹은 다음과 같이 알고리즘을 짜기도 한다.
- 스택에 시작노드를 push한다.
- 스택이 비어있다면 탐색을 종료한다.
- top에 있는 노드를 방문한다.
- top에 있는 노드와 인접하면서 아직 방문하지 않은 노드를 찾는다.
- 2에서 조건에 맞는 노드를 찾을 수 없었다면 pop한다.
- 2에서 조건에 맞는 노드를 찾았다면 그 중 하나를 스택에 push한다.
- 1로 돌아간다.
하지만 두번째 알고리즘의 경우 잘못 구현하면 시간복잡도가 늘어날 수 있다.
DFS의 작동은 영상으로 대체한다.
DFS의 시간복잡도는 인접행렬로 구현할 경우 이고 인접 리스트로 구현할 경우 이다.
1-5. BFS
'BFS'는 Breadth-First-Search(너비 우선 탐색)의 약자다. 시작 노드로부터 넓게 퍼져나가는 방식으로 탐색하기 때문에 이런 이름이 붙었다. 큐를 이용한 BFS의 알고리즘은 다음과 같다.
- 큐에 시작노드를 push한다.
- 큐가 비어있다면 탐색을 종료한다.
- pop하여 front에 있는 노드를 꺼낸다.
- 꺼낸 노드를 이미 방문했었다면 1로 돌아간다.
- 꺼낸 노드를 방문한다.
- 꺼낸 노드와 인접하면서 아직 방문하지 않은 노드들을 큐에 push한다.
- 1로 돌아간다.
BFS의 작동도 영상으로 대체한다.
DFS의 시간복잡도는 인접행렬로 구현할 경우 이고 인접 리스트로 구현할 경우 이다.
2. 코드 샘플
📢 코드 샘플은 이 곳에서 공유 중입니다.
2-1. DFS
📜 소스코드 (C)

2-2. BFS
📜 소스코드 (C)

3. 문제
3-1. 바이러스 - 백준
👀 살펴보기
문제 : 1번 정점과 연결된 정점의 개수를 구하는 문제
🎨 지도 및 설명
- 방문할 때마다 카운트를 1 증가하면 됨
- 인접 행렬 사용하도록 지도
- DFS, BFS 둘 다 사용해보도록 지도
- 기초적인 그래프 탐색의 구현을 손에 익히는 것을 목적으로 함
✅ 정답 소스코드

3-2. 미로 탐색 - 더블릿
👀 살펴보기
문제 : DFS를 이용해 방을 순회하는 문제
🎨 지도 및 설명
- 방의 연결 구조를 그래프로 표현할 수 있음
- 인접 행렬 사용하도록 지도
- DFS 사용하도록 지도
- 스택과 재귀 모두 이용해보도록 지도
- 그래프를 이용해 문제를 추상화하는 방법을 터득하는 것을 목표로 함
- DFS의 두 가지 구현 방법을 비교 및 이해하는 것을 목표로 함
✅ 정답 소스코드

3-3. 연결 요소의 개수 - 백준
👀 살펴보기
문제 : 기초적인 Flood Fill 문제
🎨 지도 및 설명
- 연결 요소는 간선으로 연결되어 있는 정점의 묶음을 의미함
- 연결 요소의 한 지점에서 그래프 탐색을 수행하면 연결 요소의 모든 정점을 순회하게 됨
- 각 정점을 순회하며 아직 방문하지 않은 정점을 찾을 때마다 DFS를 수행하고 카운트를 1 증가시킴
✅ 정답 소스코드

3-4. 섬의 개수 - 백준
👀 살펴보기
문제 : 2차원 격자 형태 그래프의 Flood Fill 문제
🎨 지도 및 설명
- 상하좌우로 간선이 연결된 그래프로 추상화할 수 있음
✅ 정답 소스코드

3-5. 단지번호붙이기 - 백준
👀 살펴보기
문제 : Flood Fill 응용 문제
🎨 지도 및 설명
- flood fill을 수행하며 연결 요소의 크기를 세어 저장해야 한다
✅ 정답 소스코드

3-6. 치즈 - 백준
👀 살펴보기
문제 : DFS(Flood Fill)을 순차적으로 적용해 주어진 치즈의 가장자리부터 제거해나가는 문제
🎨 지도 및 설명
- flood fill을 이용해 공기와 맞닿아 있는 치즈를 찾아야 한다.
- 찾은 가장자리 치즈들을 제거한다
- 제거한 가장자리 치즈의 위치에서부터 flood fill을 수행하여 위 단계를 반복한다.
✅ 정답 소스코드
.svg)
3-7. 벽 부수고 이동하기 - 백준
👀 살펴보기
문제 : 3차원 상의 그래프 탐색
🎨 지도 및 설명
- 벽을 뚫었는지 안뚫었는지 여부를 z축으로 나타낼 수 있음
- 반례 : 1 1 0 (답: 1)
✅ 정답 소스코드

