
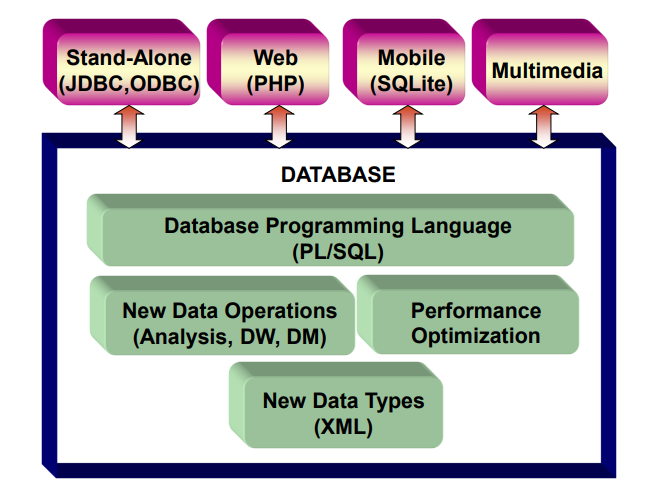
데이터베이스는 크게 전통적인 관계형 데이터베이스와 비관계형 데이터베이스로 구분될 수 있고, 그 외에도 분석과 운영 목적에 따라 분류될 수 있습니다. "빅 데이터" 환경에서는 특히 다양한 데이터 유형과 대량의 데이터를 처리하기 위해 다양한 데이터베이스 시스템이 사용된다.
관계형 데이터베이스(Relational Database)
예: Oracle, MySQL, PostgreSQL, MS SQL Server
정규화된 데이터 구조와 SQL(Structured Query Language)을 사용하여 데이터를 저장하고 검색한다. 테이블 간의 관계를 통해 데이터의 무결성을 유지하고 중복을 최소화한다.
비관계형 데이터베이스(Non-Relational Database)
- Document-based: 예를 들어 MongoDB는 JSON 유사한 형태로 데이터를 저장하며, 각 문서는 유연한 스키마를 가짐
- Key-Value stores: 예를 들면 Redis나 DynamoDB는 각 키에 하나의 값을 저장하는 구조
- Columnar stores: 예를 들면 Cassandra나 HBase는 컬럼 기반으로 데이터를 저장하며, 대량의 데이터를 빠르게 읽을 수 있음
Graph databases: 예를 들면 Neo4j나 OrientDB는 노드와 엣지로 데이터를 표현하여 복잡한 관계를 탐색
분석 데이터베이스(Analytic Database)
예: Redshift, Snowflake, Google BigQuery
대규모의 데이터를 빠르게 분석하기 위해 설계되었다.
쿼리 최적화와 병렬 처리 기술을 사용하여 대규모 데이터셋에 대한 쿼리를 빠르게 수행한다.
운영 데이터베이스(Operational Database)
실시간의 트랜잭션 처리와 CRUD(Create, Read, Update, Delete) 연산에 중점을 둔 데이터베이스이다.
대표적인 예로는 Oracle, MySQL, PostgreSQL 등이 있다.
빅데이터 환경에서는 데이터의 양, 다양성 및 속도에 따라 적절한 데이터베이스를 선택해야 한다. 예를 들어, 실시간 데이터 스트림을 처리해야 하는 경우 Apache Kafka와 같은 메시지 큐와 함께 NoSQL 데이터베이스를 사용할 수 있다. 대량의 로그 데이터나 이벤트 데이터를 분석하는 경우에는 컬럼 기반의 데이터베이스나 분석 데이터베이스를 사용하는 것이 좋을 수 있다.
빅 데이터 생태계는 데이터 수집, 저장, 처리 및 분석을 위한 다양한 도구와 기술로 구성되어 있다. 이러한 도구들은 서로 연동되어 대량의 데이터를 효과적으로 다루는데 필요한 기능들을 제공한다. 빅 데이터 생태계에서 가장 잘 알려진 것 중 하나는 바로 "Hadoop 생태계"이다.
Hadoop 생태계
-
Hadoop HDFS (Hadoop Distributed File System)
분산 파일 시스템으로, 빅 데이터를 여러 노드에서 분산 저장하고 처리할 수 있게 한다. 고장 내성이 있으며 대규모 데이터를 안정적으로 저장할 수 있습니다. -
Hadoop MapReduce
데이터 처리를 위한 프로그래밍 모델
데이터를 분할하고 각 노드에서 독립적으로 처리하며 (Map), 그 후에 결과를 집계하여 (Reduce) 최종 결과를 얻는다. -
YARN (Yet Another Resource Negotiator)
Hadoop 클러스터의 리소스 관리 및 작업 스케줄링을 담당한다.
Hadoop 2.0부터 도입되어 MapReduce 외에도 다양한 데이터 처리 프레임워크와 함께 작동할 수 있게 되었다. -
Apache Pig
데이터 플로우 스크립트 언어로, 복잡한 Hadoop 변환 작업을 단순화하고, MapReduce 작업을 쉽게 작성할 수 있게 한다. -
Apache Hive
Hadoop 상에서 SQL과 유사한 질의 언어인 HQL (Hive Query Language)을 제공하여 데이터를 분석하게 해주는 데이터 웨어하우스 도구이다. -
Apache HBase
Hadoop 위에 구축된 분산 NoSQL 데이터베이스로, 대량의 비정형 데이터를 실시간으로 처리하고 저장하는 데 사용된다. -
Apache ZooKeeper
분산 애플리케이션의 설정 관리, 네임 서비스, 분산 동기화 등을 위한 도구이다. -
Apache Flume & Apache Sqoop
- Flume: 실시간 로그 데이터를 HDFS로 이동시키는데 사용됩니다.
- Sqoop: 관계형 데이터베이스와 Hadoop 간에 데이터를 전송하는 도구입니다.
하둡 생태계는 빅 데이터 처리 및 분석 분야에서 꾸준히 발전하고 있으며, 다양한 애플리케이션과 시나리오에 적용될 수 있다.
