.png)
AWS GLUE란?
◾ 분석, 기계 학습 및 애플리케이션 개발을 위해 데이터를 쉽게 탐색, 준비, 그리고 조합할 수 있도록 지원하는 서버리스 데이터 통합 서비스
◾ 데이터 통합에 필요한 모든 기능 제공 , 몇 분 안에 데이터 분석을 시작하고 내용 활용이 가능함
데이터 통합?
▪ 분석, 기계 학습 및 애플리케이션 개발을 위해 데이터를 준비하고 결합하는 프로세스
▪ 데이터 검색 및 추출, 데이터 강화, 정리, 정규화 및 결합, 데이터베이스, 데이터 웨어하우스 및 데이터 호수에 데이터 로드 및 구성 등의 여러 작업을 포함
◾ AWS Glue DataBrew 를 사용하여 코드를 작성하지 않고도 데이터를 시각적으로 정리하고 정규화 가능
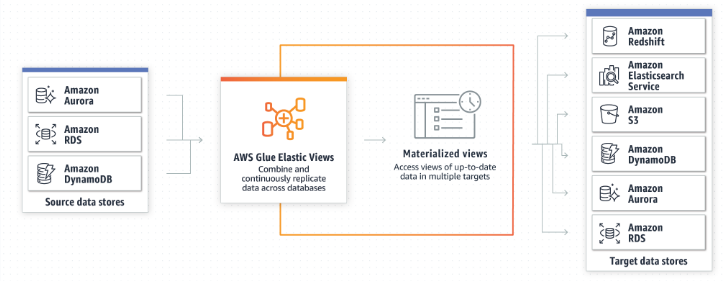
◾ AWS Glue Elastic Views 를 통해 애플리케이션 개발자는 익숙한 SQL을 사용하여 다른 데이터 저장소 간의 데이터를 조합 및 복제할 수 있습니다.
AWS Glue DataBrew?
데이터를 쉽게 정리하고 표준화하여 분석 및 기계 학습에 대비할 수 있도록 하는 새로운 시각적 데이터 준비 툴 -> 코드 작성 없이 자동화 가능 / 데이터가 준비되면 즉시 분석 및 기계 학습 프로젝트에 사용 가능 pay-as-you-go 서비스
AWS Glue Elastic Views?
사용자 지정 코드를 작성하지 않고도 여러 데이터스토어에서 데이터를 결합하고 복제할 수 있는 구체화된 보기를 쉽게 구축
기능
1. 데이터 검색
◼ 모든 AWS 데이터 세트에서 검색
AWS Glue 데이터 카탈로그
▪ 데이터의 위치와 관계없이 모든 데이터 자산을 위한 영구 메타데이터 스토어
▪ AWS Glue 환경을 관리하는 데 도움이 되는 테이블 정의, 작업 정의, 스키마 및 기타 제어 정보가 존재
▪ 데이터에 대한 쿼리를 효율적이고 비용 효과적으로 수행할 수 있도록 자동으로 통계를 계산하고 파티션을 등록
▪ 종합적인 스키마 버전 내역을 유지 관리 -> 시간이 지나면서 데이터가 어떻게 변경되었는지 파악 가능
◼ 자동 스키마 검색
AWS Glue 크롤러
▪ 소스 또는 대상 데이터 스토어에 연결 -> 우선순위가 지정된 분류기 목록을 거치면서 데이터의 스키마를 결정 -> AWS Glue 데이터 카탈로그에 메타데이터를 생성
▪ 메타데이터는 데이터 카탈로그의 테이블에 저장되고 ETL 작업의 승인 프로세스에 사용됩▪ 크롤러를 일정에 따라 또는 온디맨드로 실행하거나 이벤트를 기반으로 트리거하여 메타데이터를 최신 상태로 유지 가능
◼ 데이터 스트림 스키마 관리 및 적용
▪ AWS Glue의 서버리스 기능인 AWS Glue 스키마 레지스트리를 통해 추가 요금 없이 등록된 Apache Avro 스키마를 사용하여 스트리밍 데이터의 변화를 검증하고 제어 가능
AWS Glue 스키마 레지스트리?
데이터 스트림 스키마를 중앙에서 검색, 제어 및 발전시킬 수 있는 기능
이를 사용하여 데이터 스트리밍 애플리케이션에 스키마를 관리하고 적용 가능
▪ 데이터 스트리밍 애플리케이션을 스키마 레지스트리와 통합하면 스키마 변화를 관리하는 호환성 확인을 사용하여 데이터 품질을 개선하고 예기치 않은 변경으로부터 보호 가능
▪ 레지스트리에 저장된 스키마를 사용하여 AWS Glue 테이블 및 파티션을 생성하거나 업데이트 가능
2. 데이터 변환
◼ 끌어서 놓기 인터페이스로 시각적 데이터 변환
▪ 분산 처리를 위한 확장성이 뛰어난 ETL 작업을 작성
▪ 끌어서 놓기 작업 에디터에서 ETL 프로세스를 정의 -> AWS Glue가 자동으로 코드를 생성하여 데이터를 추출, 변환 및 로드
▪ 코드는 Scala 또는 Python에서 생성되며 Apache Spark에 맞춰 작성◼ 단순한 작업 스케줄링으로 복잡한 ETL 파이프라인 구축
▪ AWS Glue 작업은 일정에 따라, 온디맨드로 또는 이벤트를 기반으로 호출
▪ 여러 개의 작업을 병렬로 시작하거나 작업 간에 종속성을 지정하여 복잡한 ETL 파이프라인을 구축 가능
▪ 내부 작업 종속성을 처리
▪ 잘못된 데이터를 필터링
▪ 실패 시 작업을 다시 수행
▪ 모든 로그와 알림은 Amazon CloudWatch로 푸시 -> 중앙 서비스에서 알림을 모니터링함
◼ 이동 중인 스트리밍 데이터 정리 및 변환
▪ 서버리스 스트리밍 ETL 작업은 Amazon Kinesis 및 Amazon MSK를 포함한 스트리밍 소스로부터 계속해서 데이터를 사용
▪ 이동 중인 데이터를 정리 및 변환
▪ 대상 데이터 스토어에서 몇 초 안에 분석에 해당 데이터를 사용할 수 있도록 지원
▪ 이 기능을 사용하여 IoT 이벤트 스트림, 클릭스트림 및 네트워크 로그와 같은 이벤트 데이터를 처리
▪ 데이터를 보강하고 집계
▪ 배치 및 스트리밍 소스를 조인
▪ 다양하고 복잡한 분석 및 기계 학습 작업을 실행
3. 데이터 복제
◼ SQL을 사용하여 여러 데이터 스토어에서 데이터 결합 및 복제
▪ AWS Glue Elastic Views에서는 여러 유형의 AWS 데이터 스토어에 저장된 데이터에 대한 보기를 생성하고 원하는 대상 데이터 스토어에서 보기를 구체화할 수 있음 -> PartiQL에서 쿼리를 작성하면 구체화된 보기를 생성
PartiQL?
데이터가 테이블 형식인지, 아니면 유연한 문서와 같은 구조인지에 상관없이, 데이터를 쿼리하고 조작하는 데 사용할 수 있는 오픈 소스 SQL 호환 쿼리 언어
▪ AWS Management Console에서 쿼리 편집기를 사용하여 대화식으로 PartiQL 쿼리를 작성하거나 API 또는 CLI를 통해 쿼리를 실행
4. 데이터 준비
◼ 기본 제공 기계 학습을 통해 데이터 중복 제거 및 정리
▪ AWS Glue는 기계 학습 전문가가 아니어도 분석용 데이터를 정리 및 준비할 수 있도록 지원
FindMatches 기능? 서로 불완전하게 일치하는 기록을 복제하고 찾음
◼ 개발자 엔드포인트에서 ETL 코드 편집, 디버깅 및 테스트
▪ ETL 코드를 대화식으로 개발하려는 경우 AWS Glue에서는 생성된 코드를 사용자가 편집, 디버깅 및 테스트할 수 있도록 개발 엔드포인트를 제공
▪ 사용자 지정 리더, 라이터 또는 변환 기능을 작성 -> 이를 AWS Glue ETL 작업에 사용자 지정 라이브러리로 가져올 수 있음
▪ GitHub 리포지토리에서 다른 개발자와 함께 코드를 사용하고 공유 가능
◼ 시각적 인터페이스를 사용하여 코드 없이 데이터 정규화
▪ AWS Glue DataBrew는 데이터 분석가 및 데이터 사이언티스트와 같은 사용자가 코드를 작성하지 않고도 데이터를 정리하고 정규화 가능하게 포인트 앤 클릭 방식의 대화식 시각적 인터페이스를 제공
이점
1. 보다 빠른 데이터 통합
◾ 조직 전체의 여러 그룹이 확장 가능한 ETL 워크플로 실행(추출, 정리, 정규화, 조합, 로드) 등의 데이터 통합 작업을 함께 수행 -> 시간 단축이 가능하게 함
2. 대규모 데이터 통합 자동화
◾ 데이터 통합에 필요한 많은 작업을 자동화
◾ 데이터 원본을 크롤링하고, 데이터 형식을 파악하고, 데이터 저장을 위한 스키마를 제안
◾ 수천 개의 ETL 작업을 쉽게 실행 및 관리하거나 SQL을 사용하는 여러 데이터 저장소 간에서 데이터를 조합 및 복제가능
3. 관리할 서버 없음
◾ 서버리스 환경에서 작동
◾ 관리할 인프라가 없으며 데이터 확장 작업을 실행하는 데 필요한 리소스를 프로비저닝, 구성 및 확장함
◾ 사용되는 리소스에 대해서만 비용을 지불( pay-as-you-go 서비스 )
사용 사례
1. 이벤트 주도 ETL (추출, 변형 및 로드) 파이프라인
◾ 새 데이터가 도착하면 ETL 작업을 실행
ex) AWS Lambda 함수를 통해 ETL 작업을 트리거하여 Amazon S3에 새로운 데이터가 저장되는 대로 ETL 작업이 실행 -> 이 ETL 작업의 일부로 AWS Glue 데이터 카탈로그에 등록할 수도 있음
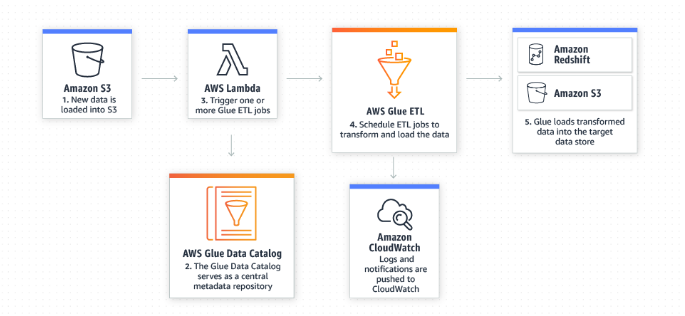
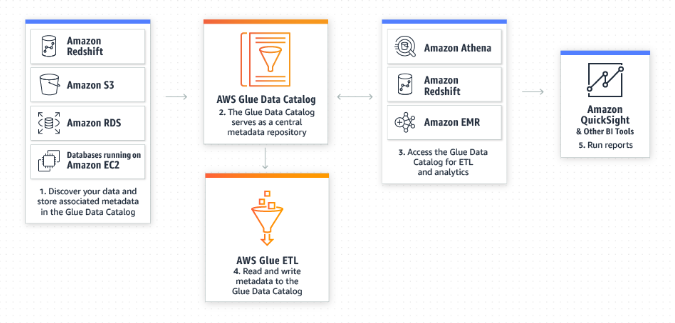
2. 통합 카탈로그를 생성하여 다양한 데이터 저장소에서 데이터를 찾기
◾ AWS GLUE를 사용하여 데이터를 이동하지 않고도 여러 AWS 데이터 세트 전체에서 신속하게 데이터를 검색할 수 있음
◾ 데이터가 카탈로그에 저장되면 Amazon Athena, Amazon EMR 및 Amazon Redshift Spectrum에서 즉시 검색 및 쿼리에 데이터를 사용할 수 있음
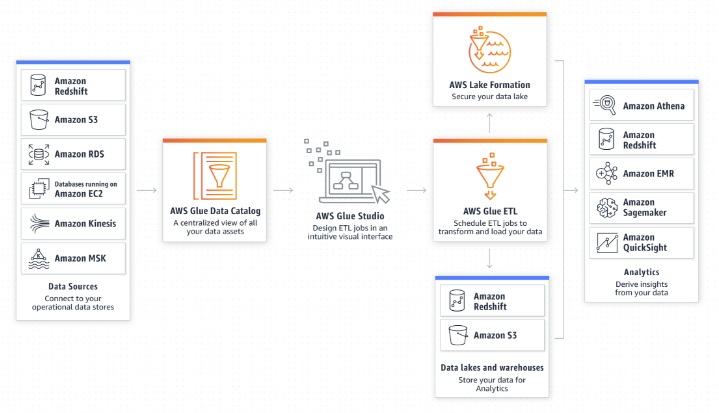
3. 코딩 없이 ETL 작업 생성, 실행 및 모니터링
◾ AWS Glue Studio를 사용하면 AWS Glue ETL 작업을 시각적으로 쉽게 생성, 실행 및 모니터링할 수 있음
◾ 드래그 앤 드롭 에디터를 사용하여 데이터를 이동 및 변형하는 ETL 작업을 구성할 수 있으며 AWS Glue는 자동으로 코드를 생성
AWS Glue Studio?
추출물을 쉽게 생성, 실행 및 모니터링할 수 있는 새로운 그래픽 인터페이스
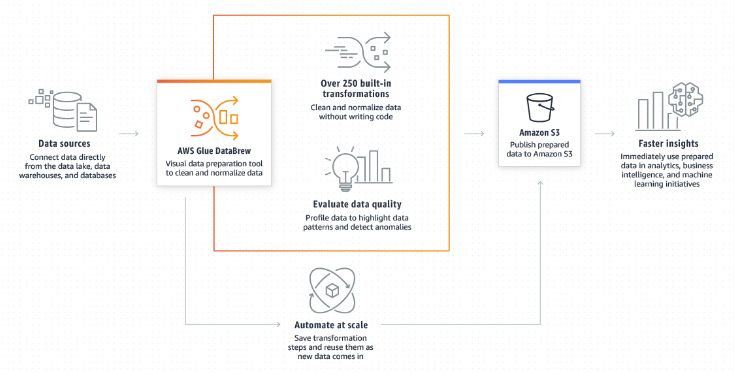
4. 데이터 탐색 및 셀프 서비스 시각적 데이터 준비
◾ AWS Glue DataBrew를 사용하면 Amazon S3, Amazon Redshift, AWS Lake Formation, Amazon Aurora 및 Amazon RDS를 비롯한 데이터 레이크, 데이터 웨어하우스 및 데이터베이스에서 직접 데이터를 탐색하고 데이터로 실험할 수 있음
◾ 필터링, 형식 표준화, 잘못된 값 수정 등의 데이터 준비 작업을 자동화할 수 있음
5. 구체화된 뷰를 구축하여 데이터 조합 및 복제
◾ AWS Glue Elastic Views는 익숙한 SQL을 사용하여 구체화된 뷰를 생성
◾ 다양한 소스 데이터 저장소의 데이터에 액세스하고 이를 조합하며, 조합한 데이터를 타겟 데이터 저장소에서 최신 상태를 유지하며 액세스 가능하게 유지
서버리스, 코딩 없이 가 glue의 핵심인듯

구체적인 설명 감사합니다!