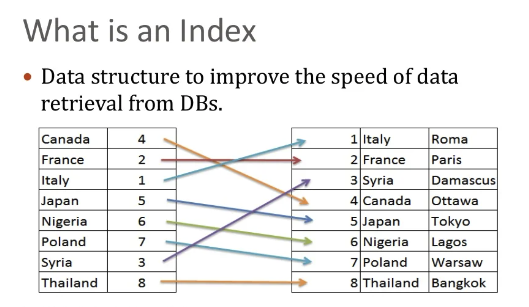
인덱스란?
인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상 시키기 위한 자료구조이다. 가장 대표적인 예로 책에서 원하는 내용을 찾는다고 하면, 모든 책의 내용을 보며 찾는 것은 힘들기 때문에 저자들은 책의 앞 혹은 뒤에 색인을 추가한다.
여기에서 색인이란?
색인(索引)은 책 속의 낱말이나 구절, 또 이에 관련한 지시자를 찾아보기 쉽도록 일정한 순서로 나열한 목록을 가리킨다. (index)라고도 한다.
여기에서 색인과 목차를 혼동하는 사람이 있는데, 이 둘은 다른 개념이라고 한다. 목차는 "이 내용이 뭐다" 라고 순서대로 보여주는 것이고, 색인은 "이 내용을 알고 싶으면 몇 페이지로 가라" 라고 지름길 역할을 해준다고 한다.
책의 뒷 부분을 보면 찾아보기 혹은 색인 이라고 적혀있는 곳을 보면 단어별(?)로 페이지를 찾아 갈 수 있게 정리를 해놓았다.
본론으로 돌아와서, 결국 인덱스를 사용하는 이유는 보다 빠르게 검색하기 위해서, 즉 테이블 조회 성능 향상을 위해 사용하는 것이다.
데이터베이스에서 인덱스
테이블의 특정 컬럼에 인덱스를 생성하면 해당 컬럼을 정렬한 뒤 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장된다. 여기서 물리적 주소란 실제 테이블내에 저장된 데이터의 주소를 말한다.
결국 인덱스를 생성하면 설정한 컬럼들로만 이루어진 테이블이 생성 된다. 이 인덱스 테이블을 사용하면 Full Scan을 할 필요가 없기 때문에 더욱더 빠른 조회 성능 향상을 이루어 낼 수 있다.
인덱스의 단점
테이블 조회 성능 향상을 위해서라면 인덱스를 사용하는게 맞는데, 그렇다면 단점은 뭐가 있을까?
INSERT, UPDATE , DELETE 성능의 악영향
간략하게 말하면 INSERT, UPDATE, DELETE 행위를 하게되면 인덱스 테이블도 변경이 되어야 해서 악영향을 미친다.
INSERT
INSERT를 하게 되면, 정렬되어 있던 인덱스 테이블의 정렬이 깨지기 때문에 인덱스 분리 형상을 통해서 데이터를 INSERT 한다. 인덱스 테이블에 모두 INSERT가 되면 기준 테이블에 데이터를 삽입한다. 그렇기 때문에 성능적으로 느리다.
인덱스 분리 현상
기존에 있던 인덱스의 데이터를 반으로 나눠 분리하여 아래쪽은 새로운 블록에 할당을 하고 새로운 데이터가 들어가야 할 자리 밑의 데이터부터 한줄씩 밀고 그 사이에 새로운 데이터가 들어가도록 한다.
DELETE
기준 테이블에서는 DELETE 실행시 데이터가 삭제되지만, INDEX에서는 사용 안함 만 체크가 된다. 그렇기 때문에 삭제를 하더라도 용량은 변하지 않는다.
UPDATE
UPDATE는 삭제 후 삽입이 되는 DML 이기 때문에 실행속도가 느리다.
추가 공간 필요
DB에 저장된 데이터의 주소를 인덱스의 Key 값으로 가지려면 별도의 공간에 저장하므로 추가 저장 공간이 필요하다.
INDEX 관리를 위한 인력 필요
인덱스를 생성하고 주기적으로 관리할 인력과 시간이 필요하다.
결론적으로는 인덱스가 많으면 많을수록, DML 작업의 성능이 하락한다.
무분별한 인덱스 사용 보다는 아래와 같은 상황에서 사용하면 좋다.
- 데이터가 많은 테이블일 경우
- INSERT, UPDATE, DELETE 를 자주 하지 않는 컬럼일 경우
- WHERE, JOIN, ORDER BY 를 자주 사용하는 컬럼일 경우
인덱스의 종류
Clustered Index(클러스터형 인덱스)
특정 열(Column) 또는 여러개의 열들을 기준으로 데이터가 정렬 가능하게 하는 자료구조이다.
클러스터형 인덱스의 특징
- 테이블당 1개만 허용되며, 해당 컬럼을 기준으로 테이블이 물리적으로 정렬된다.
- 테이블이 물리적으로 정렬되기 때문에, 리프노드가 필요없게 되며 추가적인 공간이 필요하지 않다.
- PRIMARY KEY 설정 시 자동으로 생성되며, 이 컬럼은 데이터 변경시 항상 정렬을 유지한다.
- 조회성 쿼리 성능은 빠르나, 데이터 작업이 변경 일어날 때 프라이머리 키 관련 작업을 추가적으로 해야하므로 성능이 떨어진다.
클러스터형 인덱스를 생성 방법
PK를 설정하게 되면 자동으로 Clustered Index가 자동으로 생성된다.
1번째 방법
ALTER TABLE 테이블명 ADD CONSTRAINT pk_이름
PRIMARY KEY CLUSTERED ([컬럼명, ...]);
2번째 방법
CREATE CLUSTERED INDEX index_이름 ON 테이블명([컬럼명, ...]);Non-Clustered Index(비클러스터형 인덱스)
인덱스와 실제 데이터의 정렬 상태와는 별도이다. 비클러스터형 인덱스의 구조는 데이터 행으로부터 독립적이다.
비클러스터형 인덱스의 특징
- 테이블당 여러 개(최대 249개)를 생성할 수 있다.
- 테이블의 페이지를 정렬하지 않고 새로운 공간을 할당하므로, 클러스터 인덱스보다 많은 공간을 차지한다.
- 실제로 데이터를 가지고 있지 않고 주소를 가리킨다. 데이터 행과 분리된 구조를 가진다.
- 클러스터형 인덱스보다 검색 속도는 느리지만, 입력이나 수정, 삭제의 명령에는 성능이 더 뛰어날 수 있다
비클러스터형 인덱스를 생성 방법
첫번째 방법
CREATE NONCLUSTERED INDEX Index_이름 ON 테이블명 ([컬럼명, ...]);
두번째 방법
CREATE INDEX Index_이름 ON 테이블명 ([컬럼명, ...]);인덱스의 사용 기법
단일/복합 인덱스
단일 인덱스는 하나로만 이루어진 인덱스, 복합 인덱스는 여러개로 이루어진 인덱스를 말한다.
1. 단일 인덱스
create index idx_member_name on member(name)
2. 복합 인덱스
create index idx_member_name on member(name, phone_number)고유/비고유 인덱스
고유 인덱스는 칼럼의 값들이 유일한 경우에 만들 수 있는 인덱스이고 비고유 인덱스는 칼럼 값에 중복된 값이 있는 경우 만드는 인덱스이다.
1. 고유 인덱스
create unique index idx_member_name on member(name)
2. 비고유 인덱스
create index idx_member_name on member(name)member 테이블에서 name 컬럼이 unique 속성을 띄지 않으면 고유 인덱스를 생성할때 에러가 발생한다.
오름차순/내림차순 인덱스
기본적으로 오름차순으로 인덱스가 생성되는데 내림차순으로 인덱스를 생성 할 수도 있다.
1. 오름차순 인덱스
create index idx_member_name on member(name)
2. 내림차순 인덱스
create index idx_member_name on member(name desc)함수기반 인덱스
where 절에 함수를 사용 했을 경우 index 테이블을 이용 할 수 없다.
select * from member
where lower(name) = '홍길동'이럴 경우에는 아래와 같이 함수기반 인덱스를 만들어 사용한다.
create index idx_member_name on member(lower(name))인덱스 재구성 및 삭제
칼럼에 대해 생성된 인덱스에 변형(데이터 삽입, 삭제, 수정)이 자주 발생하는 경우 균형잡힌 트리(Balanced Tree)의 모양이 아닌 트리가 한쪽으로 기울어 지는 현상이 생길 수 있다. 이러한 경우 인덱스를 재구성 또는 삭제 후 재생성 해야 한다.
1. rebuild를 사용하여 재구성
Alter index idx_member_name rebuild;
2. MEMBER 테이블의 NAME 칼럼에 대해 생성된 인덱스를 삭제
Drop index idx_member_name;
자료 및 그림 출처
https://www.slideshare.net/jkeriaki/indexes-35553784
http://ojc.asia/bbs/board.php?bo_table=LecSQLnPlSql&wr_id=638
