
실업급여를 받으며 공부를 더 하고 싶어 퇴사한 회사-,,
그치만 실업급여는 6개월이 아니라 8-9개월은 일했어야 했는데..!😂
암튼 미국가기 전 모아둔 돈을 다 쓸 수는 없기에 알바를 구했다.
무려 모교의 행정 조교 - ! ! !
(사유: 집이랑 가까움)
내가 처음 맡은 업무는 급여 관리였고,
엑셀에 입력된 자료를 사이트에 입력하고- 잘 입력했는지 확인 했어야 했다.
내가 눈으로 보느니 엑셀 exact가 훨씬 빠르고 정확할 것이라 생각하여 만들게 된-.. 입력된 자료 엑셀화 하기✨✨
준비물
- Python
- pip install openpyxl
- pip install bs4
- pip install requests
*cmd에서 pip 가 안 먹히면 시스템 환경 변수에 파이썬 있는 Scripts 폴더 path가 되어 있는지 확인할 것.
*새로 환경변수 입력을 했다면 cmd 껐다 켜서 불러오기 필수 ~
배경지식
HTTP 통신, 쿠키, 세션
- HTTP 통신은 브라우저와 서버 간 request, response이다.
- HTTP 통신은 Stateless! 회원 정보같은 거 저장한 통신 불가. so 쿠키 등장.
- 쿠키는 클라이언트 컴퓨터에 일시적으로 약 4KB의 데이터를 저장하는 것이나, HTTP 헤더 기반이라 사용자 임의 조작 가능.
- 그래서 등장한 게 세션. 쿠키를 이용해 ID만 쿠키에 저장하고, 모든 데이터는 웹서버에 저장하는 것 --> Stateful 통신 구현.
더 자세한 설명이 듣고 싶다면 머신러닝/딥러닝 실전 입문 YOUTUBE 강의 참고
내가 가는 웹사이트에서는?
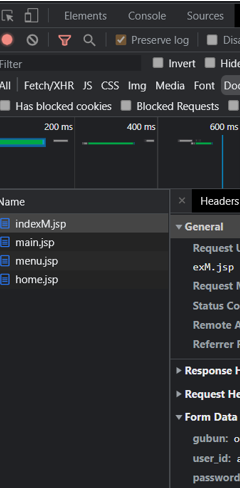
1. 개발자 도구 켜서 Network Tab에서 Preserve log 체크 후, Doc tab을 켜둔다.
2. 웹사이트에 가서 로그인 진행함.
3. 그러면 좌측 Name 있는 데에서 다 기록해주고, 이 중 Form Data(id, pw 있는)을 가지고 있는 파일을 선택하면 그 친구가 실질적인 loginPage. General의 Request Url을 후에 loginPage에 입력하면 된다.
response.content와 response.text의 차이?
- 인코딩의 유무!
.text는 추측된 response.encoding 리소스를 사용 디코드된 값.
.content는 디코드 안 되어 bytes 상태로 저장되어 있음. - 미디어 파일 서버에서 받고 싶으면 .content 사용해야 함. 그리고 여러 사이트 파싱할 때 한글 보존 가능.
코드
! 아래 코드 중 **** 은 각자에게 맞는 것들을 입력하시면 됩니다.
! 물론 사이트 구조에 따라 코드가 달라질 수 있습니다.
from openpyxl import Workbook
from bs4 import BeautifulSoup
import requests
def main():
session = requests.session()
loginPage = "****"
#data dictionary의 key, value도 다 다를 수 있겠죠.
data = {
"gubun": "****",
"user_id" : "****",
"password" : "****"
}
# 요청 모방
response = session.post(loginPage, data=data)
# 로그인 실행
response.raise_for_status()
url = input('URL을 입력해 주세요: ')
response = session.get(url)
response.raise_for_status()
if response.status_code == 200:
# 엑셀 파일 생성
wb = Workbook()
ws = wb.active
ws.append(['****','****','****']) # 열 이름들 생성
soup = BeautifulSoup(response.text, "html.parser")
maxnum = 1000 # 최대 1000명 미만의 정보가 입력되어 있다고 가정
for i in range(1, maxnum):
# 내가 크롤링할 사이트 구조상 편하게 try, catch로 구현.
try:
**** = soup.select_one('****')['value']
****
ws.append([****,****])
except:
break
filename = input('생성될 엑셀 파일 명을 입력하세요: ')
wb.save(filename+".xlsx")
else :
print(response.status_code)
if __name__ == '__main__':
main()후기
예전에 Selenium으로 크롤러 만들면서 자료 찾아봤을 때,
CSS 선택자를 이용하는 건 크롤러가 아니다 뭐 이런 얘기를 본 적 있으나-
정적인 페이지고, 임시적으로 쓰일 거라 우선은 이렇게 만들어 보았다.
전에 만들었던 건 로그인 정보가 필요없어서 이번에 session을 건드려서 재밌었다.
한창 백신매크로 유행할 때 뭣모르고 썼던 걸 제대로 써본 기분-!
anyway, any opinions or suggestions are always welcome.
