Linux Network - basic
linux network layer에 대해서 알아보기 전에 간단한 network 구성을 살펴보도록 하자.
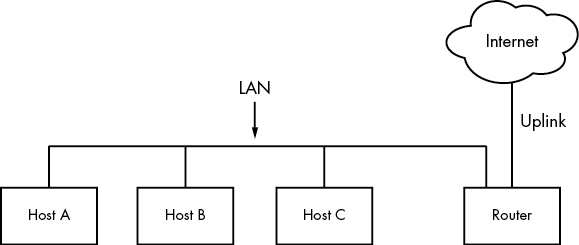
위의 그림과 같이 host들은 LAN(local area network)라는 network에 연결되어있는데, LAN이라는 것은 어떠한 구체적인 정의는 없고 다음과 같이 local network가 구성되면 LAN이라한다. LAN은 무선, 유선 상관없이 host들과 router를 잇는데, host들은 office나 집에서의 computer들을 일컫는다. 이들은 같은 LAN에 연결되어있기 때문에 서로 통신이 가능한데, Internet과 같은 외부 network에 접속하기 위해서는 router라는 host를 통해서만 가능하다. router는 LAN의 data를 또 다른 network로 전달하는 것으로 보면 된다.
router는 uplink를 통해서 internet 또는 cloud에 연결되는데, 이를 local network보다 크다하여 WAN(wide area network)라고 한다. router는 LAN과 WAN에 모두 연결되어 있기 때문에 LAN에 연결된 모든 host들은 WAN(또는 internet)에 접속하기 위해서는 router를 거쳐가야 한다.
이러한 network 구성은 전체적인 network의 일부이지만, 자세히 보면 모든 network가 이것과 동일하게 만들어져 있다. 즉, 이러한 network 구조가 모두 연결되어 하나의 큰 network를 이루는 것 뿐이다.
computer는 network를 통해 data를 전달하는데 작은 chunk단위로 전달한다. 이를 packet이라고 하는 것이다. packet은 두 가지 부분으로 나뉘는데, protocol과 source, destination과 같은 metadata를 담은 header와 본문 msg가 담긴 payload이다.
대부분의 경우 OS에서 packet에 대한 처리를 담당하기 때문에 application layer에서 깊이 알 필요는 없다. 그러나 network 내에서 packet의 role을 알고 있는 것은 꽤나 큰 도움이 된다.
Network Layers
network를 구성하는 데 있어서 일련의 'network stack'이라 불리는 layer들이 있다. 이들이 먼저 만들어지고 network가 만들어졌다라기 보다는 network가 구성되고, network를 설명하고 고도화되기 위해서 만들어진 layer이자 stack이라고 생각하면 된다. 한국에서는 OSI 7계층이 면접(?) 질문으로 대부분을 차지하지만, 사실 OSI 7계층보다도 TCP/IP 4계층 stack이 더욱 network를 설명하기에 적합하며, 해외에서는 network stack이라 하면 TCP/IP 4계층을 떠올린다. 이제 TCP/IP 4계층을 위에서부터 아래로 정리해보도록 하자.
---------------Application layer---------------
| HTTP, TLS, HTTPS, FTP |
| |
| |
-----------------------------------------------
-----------------Transport layer---------------
| TCP, UDL |
| |
| |
-----------------------------------------------
-------------------Netwok layer----------------
| IP |
| |
| |
-----------------------------------------------
-----------------Physical layer----------------
| ethernet, modem |
| |
| |
------------------------------------------------
Application layer: user space에서 처리하는 application에 관한 것들이며, application과 server가 통신하기 위해서 사용하는 protocol들이 존재한다. 대표적으로 HTTP, FTP가 있으며 데이터 암호화를 제공하는 TLS가 있다. 또한, 이들끼리 합쳐질 수도 있는데, HTTP와 TLS를 합쳐서 HTTPS가 만들어진 것이다.
-
Transport layer: application layer의 데이터 전송 특징을 정의한다. 이 layer에서는 data 정합성 점검, 목적지와 출발지 port들, host에서 application data를 packet들로 분해하는 spec들을 포함하고, 목적지에서 이 분해한 packet을 재조립하여 하나의 data를 만드는 역할도 한다. 해당 layer에는 Transmission Control Protocol(TCP)와 User Datagram Protocol(UDP)들이 포함되어, transport layer는 'protocol layer'로도 불린다. transport layer 부터 아래에 있는 layer들은 모두 packet을 kernel단계에서 처리하는데, 일부만이 user space에서 처리될 수도 있다.
-
Netwok or internet layer: packet을 출발지에서 목적지로 전달하는 방법을 정의한다. packet 전달 규칙에 관한 것이 바로 'internet protocol'(IP)이다.
-
Physical layer: raw data들을 물리적인 매개체를 통해서 전달하는 방법을 정의한다. 가령 ethernet 또는 modem이 있다. 해당 layer는 종종 'link layer' 또는 'host-to-network layer'라고 불린다.
application을 통해서 전달하는 packet들은 이 4가지 layer를 최소한 2번은 거친다. packet을 전달하는 host에서 한번, packet을 받는 host에서 한 번 씩말이다.
그런데, 모든 network 구동 방식이 이 4 layer를 순서대로 오고가는 것은 아니다. 가령, device의 경우 예전에는 physical layer의 역할로 raw data를 물리적 매개체를 통해 전달만 했지만, 요새는 internet layer나 transport layer data를 받아서 filtering하거나 data를 빠르게 라우팅하기도 한다. 추가적으로 용어들도 헷갈릴 수 있는데, TLS의 경우 암호화에 초점을 맞추면 appliction layer가 맞지만 transport layer security라는 말에 맞게 전송에 대한 protocol도 관장한다. 따라서, TLS는 application layer인지 transport layer인지 애매한 부분이 있는데, 딱히 RFC에서도 정확하게 TLS가 어느 계층이라고 정의한 부분이 없기 때문에, 반드시 'application layer'라고는 할 수 없다. 이는 위의 layer들 자체가 사실은 network를 설명하기 위해서 만들어진 것일 뿐, 반드시 해당 스펙대로만 동작해야한다는 것은 아니다.
Internet Layer
오늘날의 internet은 IPv4 (internet protocol version v4)와 IPv6로 이루어져 있다. internet layer의 가장 중요한 측면 중 하나는 이것이 software network로 어떠한 하드웨어나 OS에 의존하지 않는다는 것이다. 이 아이디어를 통해서 우리는 internet packet을 하드웨어나 OS에 상관없이 전달하고 받을 수 있는 것이다.
internet topology는 분산화되어 있는데, 이는 network가 작은 network인 'subnet'들로 이루어져 있다는 것이다. 가령, 위의 그림에서 LAN으로 host들이 서로 연결된 것을 보고 subnet의 구성을 알 수 있다.
host들은 하나 이상의 subnet에 연결될 수 있는데, 위의 그림에서는 router가 바로 그 역할을 하고 있는 것이다. 이렇게 여러 개의 subnet에 연결된 router는 서로 다른 subnet끼리의 통신을 도와주며, 이 router를 두고 다른 subnet과 연결된다고 하여 'gateway'라고 부르기도 한다.
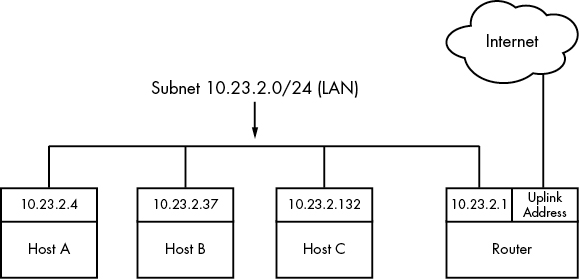
위의 그림에서 보듯이 각 host들은 IP를 가지고 있고, 같은 형식의 IP 대역으로 연결된 subnet이 있다는 것을 볼 수 있다. 재밌는 것은 router는 두 개의 IP로 이루어진 것을 볼 수 있다. 이를 통해서 router는 두 개의 subnet에 연결된 것을 알 수 있는데, 10.23.2.는 host A, B, C와의 통신을 위한 network이고 Uplink Address는 internet과의 연결을 위한 IP이다. 위는 정확한 값을 써놓지 않았는데, 값이 중요하진 않기 때문이다.
각 host들은 연결된 subnet마다 최소한 한 개의 IP를 가지고 있어야 하는데, 이 IP는 a.b.c.d 형식을 가진다. 즉, 10.23.2.37과 같다. 각 host의 IP주소는 전체 internet에서 고유한 값이어야 하는데, 현실적으로 IP를 고유한 값으로 배정받는 것은 어려운 일이다. 뒤에 나올 private network와 Network Address Translation(NAT)이 해당 문제를 해결해준다.
참고로 IP주소는 4byte로 32bit로 이루어져 있다. 즉 a.b.c.d 각 4개의 영역은 8bit씩 나뉘어져 있다고 볼 수 있는데, 이는 0~255개의 값을 가진다.
하나의 host에서는 여러 개의 IP 주소를 가질 수 있다. 이는 여러 개의 physical interface를 가지거나 virtual internal network들을 가질 때 그렇다. 다음의 명령어로 IP주소가 어떻게 할당되어 있는 지 확인해보도록 하자.
ip addr show
...
2: enp0s31f6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 40:8d:5c:fc:24:1f brd ff:ff:ff:ff:ff:ff
inet 10.23.2.4/24 brd 10.23.2.255 scope global noprefixroute enp0s31f6
valid_lft forever preferred_lft foreverip 명령어는 internet layer과 physical layer에 대한 자세한 내용들을 포함한다. inet부분을 보면 ip가 적혀있을 텐데 10.23.2.4가 해당 host의 network interface card에 설정된 IP이고 /24는 IP주소가 속한 subnet에 대한 정보를 제공해준다. 이에 대해서는 아래에 배워보도록 하자.
subnets
subnet은 특정한 IP 범위를 가지고 있는 host들의 그룹이라고 볼 수 있다. 가령 모든 host의 IP범위가 10.23.2.1에서 10.23.2.254사이라면 이는 subnet으로 묶어낼 수 있다. 대게 subnet host들은 같은 physical network에 있다.
subnet은 두 가지로 구성되는데, network prefix(routing prefix)와 subnet mask(network mask, routing mask)로 이루어져 있다. 가령, 10.23.2.1에서 10.23.2.254사이의 ip주소를 포함하는 subnet을 만들고 싶다고 하자. network prefix는 host들이 사용하는 IP의 common한 부분들을 말한다. 가령 10.23.2.x을 말한다. x부분을 그냥 0으로 표시하여 10.23.2.0으로 둔다. 이것이 network prefix이며 subnet maske로는 255.255.255.0을 가진다고 한다. 그렇다면 subnet mask의 255.255.255.0은 어디서 온 것일까?
subnet mask는 딱히 특별한게 없는데, subnet의 network prefix을 bit-wise로 필터링해주는 기준일 뿐이다. 즉, host IP가 있다면 어디서부터가 subnet의 network prefix인지를 알려주는 부분이라는 것이다. 다음은 10.23.2.0과 255.255.255.0을 bit로 표현한 것이다.
10.23.2.0: 00001010 00010111 00000010 00000000
255.255.255.0: 11111111 11111111 11111111 00000000이 둘을 bit-wise and연산을 해보자, bit-wise and연산은 알겠지만 둘 다 1이되야지만 1로 나온다. 따라서, 다음과 같이 나온다.
10.23.2.0: 00001010 00010111 00000010 00000000해당 결과를 통해 알 수 있는 것이 바로 subnet의 network prefix이다. 즉, host들끼리 subnet에 의해 common하게 사용하고 있는 IP대역이 무엇인지 알 수 있는 것이다.
가령 특정 host의 IP가 10.23.2.1이고, subnet mask가 255.255.255.0이라면 이들끼리 bitwise and 연산을 하여 subnet에서 common하게 쓰이는 network prefix를 알아낼 수 있다.
10.23.2.1: 00001010 00010111 00000010 00000001
255.255.255.0: 11111111 11111111 11111111 00000000
(bitwide and)
10.23.2.0: 00001010 00010111 00000010 0000000010.23.2.0이 subnet mask에 의해 필터링된 network prefix이다. 즉, 해당 subnet에 연결된 모든 host는 10.23.2.x를 가지고 x부분이 각 host마다 다른 값이라는 것이다. 위에서도 말했지만 각 부분이 8bit이기 때문에 x부분은 0~255까지의 값을 가진다.
그런데, 매번 이렇게 subnet mask를 써주는 것은 귀찮은 일이다. 따라서 다음과 같이 짧은 notation으로 표현한다.
Common Subnet Masks and CIDR Notation
대부분 subnet에 대한 notation을 표현할 때 10.23.2.0/255.255.255.0라고 쓰지 않는다. 보통 10.23.2.0/24로 쓰는데, 이는 subnet 표현법으로 'Classless InterDomain Routing(CIDR)' 표기법이라고 한다. CIDR은 별다른게 아니라 subnet mask를 간단하게 표현해주는 또 다른 방법일 뿐이다.
subnet mask의 값을 binary값으로 변경하면 1이 쭉 나오다가 0으로 나오게 된다. 이 1에 해당하는 부분이 host IP에서 network prefix에 해당하는 것이다. 즉, subnet에서 common하게 쓰이는 부분이라는 것이다. 가령 255.255.255.0이라면 1이 24개 나오고 0이 8개가 뒤따라 나온다. 이를 이용하여 CIDR 표기법은 앞에 1이 몇 개 나오는 가를 표현한 것이 전부이다. 따라서, 255.255.255.0은 1이 24개 나오므로 10.23.2.0/24로 쓰는 것이다. /을 기준으로 앞은 subnet prefix 뒤는 subnet mask를 CIDR로 표현한 것이다.
다음의 table은 subnet mask에서 가장 많이 사용되는 CIDR를 보여주는 것이다.
| Subnet mask | CIDR form |
|---|---|
| 255.0.0.0 | /8 |
| 255.255.0.0 | /16 |
| 255.240.0.0 | /12 |
| 255.255.255.0 | /24 |
| 255.255.255.192 | /26 |
가령 255.240.0.0을 binary로 표현하면 다음과 같다.
255.240.0.0 11111111 11110000 00000000 000000001이 12개 이므로 /12가 되는 것이다.
subnet과 CIDR를 바탕으로 위에서 ip addr show를 통해서 확인한 host주소인 10.23.2.4/24가 무엇을 의미하는 지 알 수 있을 것이다. host IP는 10.23.2.4이고 subnet mask는 255.255.255.0이며 subnet의 common한 주소인 network prefix는 10.23.2.0이다. 이렇게 host IP와 subnet을 아는 것은 network를 이해하는 가장 기초가 되는 부분이다.
그럼 어떻게 subnet들끼리 연결이 되는 것일까?
kernel routing table과 routes
internet인 연결된 subnet과 연결하는 것은 대게 하나 이상의 subnet과 연결된 host를 통해서 data를 전달하는 process이다.
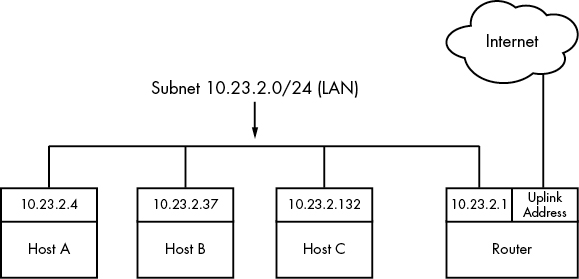
해당 그림을 다시보면 10.23.2.4 IP address에 대해서 생각해보자. 이 host는 local network인 10.23.2.0/24에 연결되고 이 subnet network를 통해서, 직접 다른 host들과 연결이 가능하다. 만약, internet에 접근하고 싶다면 해당 host는 internet subnet과 연결된 10.23.2.1 router(host)를 통해서 접근이 가능하다.
즉, 정리하자면 10.23.2.4 IP를 가진 host에서 10.23.2.132로 packet을 보내는 것과 외부 internet에 있는 host에 IP를 보내는 것은 목적지가 다르다는 것이다. 외부 internet으로 보내는 packet은 10.23.2.1을 통해야한다는 것이다.
linux kernel은 이러한 두 다른 종류의 목적지에 대해서 routing table을 제공하여 routing 동작을 결정한다. routing table을 보기위해서 ip route show 명령어를 사용해보자.
ip route show
...
default via 10.23.2.1 dev enp0s31f6 proto static metric 100
10.23.2.0/24 dev enp0s31f6 proto kernel scope link src 10.23.2.4 metric 100
...각 라인이 routing rule들이다. 먼저 두 번째 라인을 보도록 하자.
첫번째 field가 10.23.2.0/24인 것을 볼 수 있다. 이는 목적지 network로 host의 local subnet을 나타낸다. 즉, enp0s31f6라는 네트워크 인터페이스 카드를 통해서 10.23.2.0/24 subnet에 연결되어있고, 10.23.2.x IP에 대한 packet은 enp0s31f6를 통해서 연결된 subnet network를 거친다는 것이다.
참고로 router(gateway)는 subnet에서 맨 마지막 값을 1로 잡는다. 가령 10.23.2.1로 잡듯이 말이다. 단, 이는 어디까지나 convention이지 예외는 언제나 존재한다.
이제 첫 번째 라인을 보도록 하자.
첫 번째 라인은 default network 목적지에 대한 것으로 이 rule은 host가 보낸 packet에 적힌 목적지 IP가 다른 rule들에 의해서 필터링되지 않으면 default network로 전달된 다는 것이다. 중요한 것은 10.23.2.1 IP를 통해서 전달된다는 것인데, 이는 internet과 연결된 router host에 전달된다는 것이다. 따라서 enp0s31f6를 통해서 10.23.2.1로 packet이 전달된다.
default는 routing table에서 특별히 사용되는 이름으로, 다른 routing table rule이 매칭되지 않으면 해당 default routing table에 의해서 라우팅이 실행이 된다. 따라서 default는 CIDR에서 0.0.0.0을 사용하고 있으며 'default gateway'라고도 불린다. internet에 있는 IP들의 경우 우리의 local network에 없으므로, default gateway를 거치게되고 라우팅되는 것이다.
사실 routing table rule을 적용하여 어느 곳으로 packet을 라우팅할 지 결정하는 것은 CIDR을 통해서, subnet이 일치하는 부분이 가장 긴 곳으로 라우팅된다. 가령 10.23.2.132로 packet을 보낸다면 host는 default gateway와 10.23.2.0/24모두 비교하는데, default gateway는 subnet mask가 0.0.0.0이므로 일치하는 부분이 0이다. 반면에 10.23.2.0/24는 24개나 되므로 가장 길게 일치한 10.23.2.0/24 subnet으로 전달되어 packet이 라우팅되는 것이다.
IPv6 주소와 network
IPv4의 경우는 전체가 32bit밖에 안되므로 IP수가 턱없이 부족해졌다. 이에 따라 IPv6를 통해서 부족한 IP값을 해결하기 위한 개발이 진행되었다.
IPv6주소는 128bits로 16ytes로 이루어져 있다. 너무 길기 때문에 각 16진수 2byte로 8개의 bit set을 나누어 표기한다. address는 다음과 같이 쓰여진다.
2001:0db8:0a0b:12f0:0000:0000:0000:8b6e16진수로 1byte는 두개의 값이기 대문에 20, 01로 쓰인 것이다.
0으로 쌓여있는 부분들이 다음과 같이 생략이 가능하다.
2001:db8:a0b:12f0::8b6eCIDR도 사용되는데, 보통 64bit를 subnet mask로 사용한다. 나머지 부분은 각 host마다 고유한 address를 가지는 부분을 'interface ID'라고 한다. 아래의 그림은 64bit의 subnet과 64bit의 interface id를 표현한 것이다.
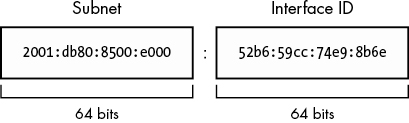
IPv6를 사용하는 host는 최소한 두 개의 주소를 사용하는데, 첫번째는 internet 사이에서 유효한 'global unicase address'이고 두 번째는 local network에서 사용하는 'link-local address'이다. link-local address는 항상 fe80::/10 prefix를 가지며 54bit의 0인 network ID와 64bit의 interface ID로 이루어져 있다. 이는 link-local address를 system에서 보면 fe80::/64 subnet을 가진다는 것이다.
반면에 global unicast address는 prefix로 2000::/3을 갖는다. 왜냐하면 첫번째 byte가 001로 시작하는데 이는 0010, 0011 밖에 없기 때문이다. 따라서, global unicast address는 항상 2나 3으로 시작한다.
host의 IPv6를 보고 싶다면 -6 옵션을 사용하면 된다.
ip -6 address show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 state UNKNOWN qlen 1000
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s31f6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 state UP qlen 1000
inet6 2001:db8:8500:e:52b6:59cc:74e9:8b6e/64 scope global dynamic noprefixroute
valid_lft 86136sec preferred_lft 86136sec
inet6 fe80::d05c:97f9:7be8:bca/64 scope link noprefixroute
valid_lft forever preferred_lft foreverenp0s31f6에 두 개의 address가 있는 것을 볼 수 있다. global unicast address는 scope global로 표시되어있는데, link-local address는 scope link label을 가지고 있다.
route를 보도록 하자.
ip -6 route show
::1 dev lo proto kernel metric 256 pref medium
1 2001:db8:8500:e::/64 dev enp0s31f6 proto ra metric 100 pref medium
2 fe80::/64 dev enp0s31f6 proto kernel metric 100 pref medium
3 default via fe80::800d:7bff:feb8:14a0 dev enp0s31f6 proto ra metric 100 pref medium첫번째는 global subnet이고, 두번째는 link-local subnet이다. default는 link-local subnet에 있는 IP를 사용하였는데, 이 덕분에 global IP주소가 변해도 default를 수정하지 않아도 된다.
host에 IPv4와 IPv6 모두 사용하도록 network를 설정할 수 있는데, 이를 'dual-stack network'라고 한다. IPv4와 IPv6가 독립적으로 host에서 사용되고, IPv6로부터 올라온 packet이 IPv4로 쓰이는 일은 없다. 그저 독립적으로 이 둘이 동시에 사용되는 것을 'dual-stack'이라고 한다.
ICMP 툴과 DNS 툴
host들끼리의 상호작용을 위한 두 가지 툴을 사용해보도록 하자. 이 툴들은 두 개의 protocol을 사용하는데 하나는 Internet Control Message Protocol(ICMP)로 routing과 연결성에 대한 문제를 드러내준다. 다른 하나의 protocol은 Domain Name Service(DNS)로 name을 IP 주소로 맵핑해주도록 한다.
ICMP는 transport layer protocol로 internet network를 검사하고 설정하기 위해서 사용한다. 다른 protocol들과 달리 실제 user data를 전달하지 않기 때문에 application layer가 없다. 반면에 DNS는 application layer protocol로 가독성이 좋은 이름을 internet 주소로 맵핑해준다.
ping은 가장 기본적인 네트워크 디버깅 툴로 ICMP echo 요청 packet을 host에 전달해 응답을 받는 지 못받는 지 확인한다. 만약 수령자 host가 요청을 받으면 ICMP echo 응답 packet을 반환값으로 보낸다.
가령 ping 10.23.2.1을 실행하고 결과를 확인해보자.
ping 10.23.2.1
PING 10.23.2.1 (10.23.2.1) 56(84) bytes of data.
64 bytes from 10.23.2.1: icmp_req=1 ttl=64 time=1.76 ms
64 bytes from 10.23.2.1: icmp_req=2 ttl=64 time=2.35 ms
64 bytes from 10.23.2.1: icmp_req=4 ttl=64 time=1.69 ms
64 bytes from 10.23.2.1: icmp_req=5 ttl=64 time=1.61 ms첫번째 line을 통해서 10.23.2.1에 84-byte packet을 전달했다는 것을 알 수 있다. 56은 이 중 해당 packet의 payload가 56 byte라는 것이다. 이 다음 line부터는 10.23.2.1에서부터의 응답을 보여준다. 응답 byte는 요청 56byte에서 8이 추가된 64byte라는 것이다. 중요한 것은 icmp_req와 time이다. 전달한 sequence number와 round-trip time을 나타내는 것이다.
잘보면 icmp_req가 2에서 4로 가는 것을 볼 수 있는데, icmp_req 3에서 network문제가 발생해서 packet이 순서대로 들어오지 않은 것이다. 즉, 일종의 연결성 장애가 발생했다는 것을 의미하는 것이다.
만약, 요청이 목적지로 전달될 방법이 없다면 host unreachable을 router에서 전달해준다.
참고로 internet에서의 host들은 보안 issue를 위해서 ICMP echo를 막아두었으니 ping이 전달되지 않을 것이다.
-4와 -6 옵션이 있기 때문에 IPv4, IPv6로 ICMP를 강제로 보낼 수 있다.
그런데 ping은 이전에도 말했듯이 application layer에서 동작하지 않기 때문에 IP가 아닌 domain 이름으로는 응답이 전달되지 않는다. 따라서 DNS가 제대로 설정되었는 지에 대한 것은 host라는 명령어를 통해 확인해야한다.
IP는 유동적이고, 사람이 외우기도 쉽지 않다. 따라서 IP에 name을 맵핑하도록 하는데, name이 오면 IP를 전달해주는 것이 바로 DNS(Domain Name Service)이다. DNS libray는 각 system에 설치되어 IP-name간 변환을 자동으로 처리해준다. name이 어떤 IP주소로 처리되는 지 알아보기 위해서 host 명령어를 사용해보도록 하자.
host www.example.com
example.com has address 172.17.216.34
example.com has IPv6 address 2001:db8:220:1:248:1893:25c8:1946www.example.com에 대한 IP들이 나오는 것을 볼 수 있다. 반대로 host $IP를 통해서 name을 얻어낼 수 있는데, 이는 신뢰할 수 없다. 왜냐하면 IP하나에 여러 name들이 있을 수 있기 때문이다. 이 경우에 host를 통해 얻은 IP가 진짜 내가 name을 사용할 때 얻은 IP인지 확신을 얻을 수가 없다.
host말고도 DNS 명령어들은 여러 개 있으니 아래에 더 다루어보도록 하자.
Physical layer와 Ethernet
internet 자체는 software network이지만 hardware와 OS의 도움없이는 동작이 불가능하다. 오늘날 역시도 또 다른 computer들 끼리의 통신을 위해서 일종의 hardware 위에 network layer를 올려야하는데, 이 hardware와 network layer간의 interface가 바로 physical layer이다.
physical layer에서 가장 흔히 사용되는 것은 'Ethernet network'이다. IEEE 802에서는 여러 ethernet network들을 정의했지만, 다음의 공통 사항이 있다.
-
ethernet network의 모든 device들은 Media Access Control(MAC) address를 가진다. 이는 때때로 hardware address라고 불리는데, IP와는 독립적이고 host의 ethernet network에서 유일한 값이어야 한다. 그러나, internet같은 큰 network에서는 unique할 필요는 없다. mac address는 다음과 같이 생겼다.
10:78:d2:eb:76:97 -
ethernet network의 device들은 'frame'이라는 단위로 message를 전달한다. 'frame'은 전달할 data를 wrapping하여 출발지, 목적지 MAC 주소를 추가해준다.
ethernet은 실제로 single network에서의 hardware를 넘어 데이터를 전달하려고 하지 않는다. 가령 두 개의 다른 ethernet network를 가진 host가 있다고 하자. 이 host는 두 개의 다른 NIC를 가지고 있어 두 개의 다른 ethernet network를 가진다. 그러나 같은 host에 있다고 하더라도 하나의 ethernet에서 다른 ethernet으로 데이터를 전송할 수 없다. 이는 ethernet 자체가 자신의 network에서 벗어나지 않으려고 하기 때문이다. 따라서, ethernet들 끼리를 잇는 ethernet bridge를 이어주어야 한 ethernet에서 다른 ethernet으로 frame을 직접 전송할 수 있다. 즉, ethernet network는 일반적으로 하나의 subnet을 가지는 것이다.
서로 다른 network에서 data를 주고 받는 일은 한 단계 상위 layer인 internet layer가 담당하는 일이다. 따라서, 'frame'은 한 물리적 network를 벗어나지 못하더라도 router는 'frame'에서 데이터를 꺼내어 다시 packaging해 다른 물리적 network의 host로 보낼 수 있다. 이렇게 internet이 동작하는 것이다.
physical layer과 internet layer는 서로 간의 독립성을 제공하여 시스템의 유연함을 부여해야한다. 따라서, 이들을 이어주는 system이 필요한데, linux kernel에서는 (kernel) network interface를 제공하여, 이 두 layer가 통신을 하도록 하면서도, 각자의 독립적인 영역을 유지할 수 있도록 해준다. network interface를 설정할 때, internet side로부터 physcial device side에 hardware 식별을 위한 IP 주소를 설정한다. 이는 internet layer 측에서 hardware를 식별하기 위해 사용하는 것이라 생각하면 된다. 반면에 hardware측면에서는 NIC의 고유한 이름을 network layer에서 식별자로 사용한다. 가령 enp0s31f6와 같이 설정한다. 이러한 이름을 'predictable network interface device name'이라고 하는데, reboot 이후에도 동일하게 남아있기 때문이다. 참고로 eth로 시작하는 것은 computer의 ethernet card이고, wlan은 wireless interface이다.
-----Network Layer------
| |
------------------------
|
|
(IP)
(kernel) Network Interface
(MAC)
|
|
--Physical Layer(ethernet)
| |
-------------------------ip address show 명령어를 통해서 network interface setting을 볼 수 있다.
2: enp0s31f6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state 1 UP group default qlen 1000
2 link/ether 40:8d:5c:fc:24:1f brd ff:ff:ff:ff:ff:ff
inet 10.23.2.4/24 brd 10.23.2.255 scope global noprefixroute enp0s31f6
valid_lft forever preferred_lft forever
inet6 2001:db8:8500:e:52b6:59cc:74e9:8b6e/64 scope global dynamic noprefixroute
valid_lft 86054sec preferred_lft 86054sec
inet6 fe80::d05c:97f9:7be8:bca/64 scope link noprefixroute
valid_lft forever preferred_lft forever각 network interface는 숫자를 가지는데, 여기서는 2를 가진다. interface 1은 항상 loopback이다. flag로 UP이 있는데, 이는 해당 interface가 1로 working 중이라는 것이다. 추가적으로 internet layer 측에서 physical layer에 부여한 IP주소는 link/ether 뒤를 보면 된다.
ip가 하드웨어 관련된 정보를 보여주어도, 이는 주로 interface에 부착된 software layer들을 보여주고 설정하기 위해 디자인된 것이 목적이다. 따라서 더 깊이 network interface의 hardware와 physical layer에 대해서 파고들기 위해서는 ethtool과 같은 것들을 사용하여 ethernet card에 대한 설정을 바꿀 수 있다.
Network interface 설정
이제 network layer와 physical layer를 kernel의 network interface로 같이 묶어내어 linux machine을 internet에 연결해보도록 하자. 이를 위해서 다음의 사항을 설정해야한다.
- network hardware(NIC)가 연결되어 있고 kernel이 이에 대한 driver를 가지고 있는 지 확인한다.
ip address show를 통해서 device entry를 볼 수 있다. - 추가적인 physical layer를 설정하도록 한다. 가령 network name 또는 password 를 설정한다.
- IP address와 subnet을 kernel network interface에 할당한다. 이를 통해서 kernel의 device drivers(physical layer)와 internet subsystem(internet layer)가 서로 통신할 수 있다.
- default gateway와 같은 추가적인 route를 추가해준다.
kernel이 step1을 실행해주고 step 2를 해줄 필요가 없다. step 3를 ip 명령어를 통해서 할 수 있고, step 4는 route 명령어를 통해서 할 수 있다.
이제 직접 interface를 설정해보도록 하자. 그러나, 너무 깊게하지는 말자. 이렇게 직접 network interface를 설정할 일은 거의 없기 때문이다.
ip 명령어를 통해서 interface에 internet layer를 연결 시킬 수 있다. kernel network interface에 ip주수와 subnet을 추가하기 위해서 다음과 같이 할 수 있다.
ip address add address/subnet dev interface여기서 interface는 interface name으로 enp0s31f6과 같다. address/sunet은 116.112.223.42/24와 같은 IP이다. IPv4말고도 IPv6도 가능하다.
interface가 설정되고나면 routes를 추가하여 외부 다른 network와 통신할 수 있도록 해야한다. 가장 대표적으로 default gateway를 추가해야 internet에 packet이 전송될 수 있는 것이다.
ip route add default via gw-address dev interfacegw-address 파라미터는 default gateway의 IP 주소로 interface network interface에 접속된 subnet이어야 한다. 그래야 LAN으로 gateway에 접근이 가능하기 때문이다.
default gateway를 삭제하고 싶다면 다음과 같이 할 수 있다.
ip route del defaultroute를 설정해서 다른 network에도 쉽게 접근이 가능하다.
------------------subnet(10.23.2.0/24)--------------------
| --Host1(10.23.2.4/24)--- --Host2(10.23.2.44/24)-- |
| | | | | |
| ------------------------ ------------------------ |
| | |
------------------------------------------|---------------
|
|
-----------------subnet(192.168.45.0/24)--|---------------
| -Host3(192.168.45.3/24)- -Host4(192.168.45.3/24)- |
| | | | | |
| ------------------------ ------------------------ |
| |
----------------------------------------------------------다음과 같은 구조에서 Host1이 Host3 192.168.45.3/24에 접근하고 싶다고 하자. subnet 192.168.45.0/24에 접근하기 위해서 Host1은 같은 subnet에 있는 Host2에 접근하여 해당 packet을 subnet 192.168.45.0/24에 전달해줄 수 있다.
즉, Host1에 192.168.45.0/24 IP로의 packet을 10.23.2.44를 통해 전달하라고 하는 것이다. 10.23.2.44는 192.168.45.0/24와 연결되어 있기 때문이다.
ip route add 192.168.45.0/24 via 10.23.2.44Host1에 위와 같이 설정하면 192.168.45.0/24에 대한 packet을 보낼 때 10.23.2.44를 거쳐서 보내게 된다. 따라서 10.23.2.44는 192.168.45.0/24로 packet을 forwarding시켜주는 것이다. 이렇게 설정하면 packet이 전달은 가능하다.
문제는 응답은 못 받을 수 있다. 왜냐하면 Host3의 입장에서는 src IP인 Host1에 대한 route가 없기 때문이다. 실제로 network 설정은 이것보다 훨씬 더 복잡하고 어렵다.
이제 우리의 route를 삭제해주어 정상 복구를 해주도록 하자.
ip route del 192.168.45.0/24Hostname 결정
DNS는 다른 network 설정들과는 달리 application layer에서 동작한다. 즉, user space라는 것이다. 그러나 DNS가 없으면 network 설정과 통신부터 제대로 동작하지 않는다. 왜냐하면 오늘 날의 대부분의 system은 IP에 name을 추가하여 DNS로 name의 IP를 알아내기 때문이다.
사실상 모든 linux system 기반의 network application들은 DNS lookups를 수행한다. name 결정(resolution) process는 다음과 같다.
- application은 함수를 실행시켜 hostname에 대한 IP를 얻어내는데, 이 함수는 system의 shared libray이다. 따라서, application은 이 함수에 대해서 자세히 알 필요가 없다.
- shared libray에서의 함수가 실행되면, 함수는 정해진 rule 대로 실행이되는데, 이 rule은
/etc/nsswitch.conf에 명시되어 있는데, lookups에 대한 동작 plan을 결정한다. 가령, 일반적인 rule은 hostname에 대한 IP를 결정하기 위해 DNS로 가기전, local에 있는/etc/hostsfile을 참고하여 IP를 결정한다. - 만약 함수가 DNS를 사용해야한다면, DNS에 대한 추가적인 설정 파일을 참고하여 DNS name server를 찾는다. 이때 DNS name server는 IP address로 주어진다.
- 함수는 DNS lookup 요청을 name server에 전달한다.
- name server는 해당 hostname에 대한 IP를 전달해주고 함수는 IP주소를 application에 전달한다.
사실 많은 부분들이 생략된 간단한 버전이라고 생각하면 된다. 간단한 동작 원리를 알도록 하여 이해를 돕도록 한 것이다.
실제로 우리가 직접 DNS 설정을 건드릴 일은 없다. 그러나, 동작 방식을 알고있는 것은 큰 도움이 된다.
가장 먼저 hostname에 대한 IP를 결정짓는 데 사용되는 설정은 /etc/hosts file이다.
cat /etc/hosts
127.0.0.1 localhost
10.23.2.3 atlantic.aem7.net atlantic
10.23.2.4 pacific.aem7.net pacific
::1 localhost ip6-localhost/etc/hosts에 위의 형식과 같이 IP와 hostname을 맵핑하면 가장 먼저 해당 설정에 따라 IP resolution을 실행한다. 단, local network에서만 유효한 것들이 대부분이기 때문에 subnet에 연결된 IP들만 hostname에 맵핑이 가능할 것이다.
local hostname 설정이 아니라, DNS server 설정은 /etc/resolv.conf를 통해 가능하다.
cat /etc/resolv.conf
search mydomain.example.com example.com
nameserver 10.32.45.23
nameserver 10.3.2.310.32.45.23, 10.3.2.3은 ISP의 name server 주소이다.
첫번째의 search는 불완전한 hostname이 오면 다음의 형식으로 변환해서 nameserver에서 찾으라는 것이다. 가령 myserver만 입력하면 myserver.mydomain.example.com 또는 myserver.example.com을 찾게 된다.
DNS 캐싱과 zero-configuration
위의 DNS 설정 방식은 예전 방식으로 두 가지 문제가 있다. 먼저 첫번째는 local machine이 name server의 응답을 캐싱하지 못한다. 이를 위해서 local DNS caching daemon을 두는 것이 있다. systemd-resolved가 대표적이며 dnsmasq, nscd 등이 있다. /etc/resolv.conf에 127.0.0.53 또는 127.0.0.1이 표시된다.
systemd-resolved는 훨씬 더 많은 기능을 하는데, 여러 name 조회 서비스를 결합하고 각 interface에 대해 다르게 노출할 수 있기 때문이다. 이러한 기능은 기존 DNS name server의 두 번째 문제를 해결한다. 많은 configuration을 건드리지 않고도 local network에서 hostname을 조회할 수 있도록 할 수 있다. 가령, 만약 우리의 network에 network 기기를 설정한다고 할 때, 이 network 기기를 name으로 호출하고 싶을 것이다. 만약 process가 local network에서 name으로 찾고 싶다면, network에 broadcast를 전달하여, IP address에 대한 응답을 받는다. 이는 Multicast DNS(mDNS)와 Link-Local Multicast Name Resolution(LLMNR)과 같은 zero-configuration name service system의 이면에 있는 아이디어이다.
resolvectl status를 통해서 현재의 DNS 설정을 볼 수 있다.
resolvectl status
...
Link 2 (enp0s31f6)
Current Scopes: DNS
LLMNR setting: yes
MulticastDNS setting: no
DNSSEC setting: no
DNSSEC supported: no
DNS Servers: 8.8.8.8
DNS Domain: ~.각 interface마다의 DNS 설정들을 볼 수 있다.
/etc/nsswitch.conf file은 예전에 사용하면 설정 파일이다.
cat /etc/nsswitch.conf
...
hosts: files dns
...dns 앞에 files를 두는 것은 hosts를 볼 때, 우리의 system이 /etc/hosts 파일을 확인한다.
Localhost
ip address show를 수행하면 lo interface를 볼 수 있을 것이다.
ip address show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft foreverlo interface는 virtual network interface로 loopback이라고 한다. loopback은 localhost로 127.0.0.1 또는 ::1 으로 연결하는데, 이는 현재 사용중인 host 자체로 연결하는 것이다. localhost로 전달되는 data들은 kernel에서 다시 src, dest를 패키징하여 lo interface를 통해 전달한다.
lo loopback interface는 한 가지 특이성을 가지는데, netmast가 /8이고 127으로 시작한다는 것이다. 이를 통해서 loopback space에서 추가적인 interface 없이도 다른 IPv4를 server에 실행시킬 수 있다.
Transport Layer: TCP, UDP and services
여태까지는 internet에서 host-to-host로 어디서 packet들이 이동하는 지에 대해서 알아보았다. 그럼, 어떤 것들을 전달하는가? 에 대한 답을 할 차례이다. 어떻게 computer가 다른 host들로부터 전달받은 packet data를 실행중인 process들에 전달하는 가는 매우 중요하다. application들은 수많은 raw packet들을 처리하기 매우 번거롭고, 어렵다. 따라서, 유연성을 제공하기 위해 raw packet들을 처리하고 application에 전달하는 bridge 역할이 필요한데, 그것이 바로 'Transport layer Protocol'이다. 이는 internet layer의 raw packet들과 application의 정제된 data를 받고 싶은 수요를 이어준다. Transport layer에서 가장 많이 사용되는 protocol이 바로 TCP와 UDP이다. 우리는 TCP에 더 집중하도록 하자.
TCP는 하나의 host에 network port들을 이용하여 수많은 network application에게 service를 제공한다. 즉, 같은 host이기 때문에 IP는 같지만 application에 대한 구분을 port로 해주는 것이다.
TCP를 사용할 때, 먼저 host의 port와 remote host의 port 사이에 connection을 열어준다. 가령, web browser는 해당 machine의 port 36406과 remote host의 80 port를 연결하는 connection을 open한다. application의 관점에서 port 36406은 local port이고 port 80은 remote port이다.
따라서, connection은 IP 주소와 port의 조합으로 식별할 수 있다. netstat을 사용하면 connection들을 볼 수 있다. 다음은 TCP connection들에 대한 예제로 -n을 사용해 DNS를 통한 hostname 결정을 실행하지 못하도록 하고 -t 옵션으로 TCP에 대한 결과를 보도록 하는 것이다.
netstat -nt
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 10.23.2.4:47626 10.194.79.125:5222 ESTABLISHED
tcp 0 0 10.23.2.4:41475 172.19.52.144:6667 ESTABLISHED
tcp 0 0 10.23.2.4:57132 192.168.231.135:22 ESTABLISHED만약 -n옵션을 주지 않으면 IP가 아니라 DNS 이름으로 나온다.
다음의 예제를 보면 Local Address가 현재 host이고, Foreign Address가 remote host이다.
만약 IPv6로 보고 싶다면 -6옵션을 사용하면 된다.
transport layer connection을 만들기 위해서는, host에 있는 process가 local port 중 하나로부터 remote host에 있는 port에 대해서 packet의 특별한 series를 보내어 초기화한다. second host는 자신의 port에 대해서 process가 'listening'하고 있어야 한다. 연결하려는 process를 'client'라 하고, port를 열고 connection이 오기를 기다리는 litener process를 'server'라고 한다.
port에 대해서 알아야하는 중요한 점은 client가 현재 사용중이지 않은 port를 선택해야하고, server의 well-known port에 접근해야한다는 것이다. netstat 명령어를 다시 확인해보면
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 10.23.2.4:47626 10.194.79.125:5222 ESTABLISHEDclient인 local address의 47626는 동적으로 할당된 port이고, 반면에 remote port인 5222는 XMPP messaging service에서 사용하는 well-known port이다. 이 밖에 대표적으로 사용되는 HTTPS port는 443이다.
참고로 동적으로 할당되는 port를 ephemeral port라고 한다.
netstat에서 -l옵션을 사용하면 현재, server에서 listening 중인 port을 확인할 수 있다. 다음을 보도록 하자.
netstat -ntl
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
1 tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN
2 tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN
3 tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 0.0.0.0:80은 local machine이 port 80으로 remote machine에 대한 connection을 listening하고 있다. lsof를 사용하면 어떤 process가 port를 열고 listening하고 있는 지를 알 수 있는데, 이에 대해서는 나중에 알아보도록 하자.
그런데, well-known port들이 무엇인지 어떻게 아는가?? /etc/services를 확인하면 well-known port와 name을 mapping해둔 것이 있다. 이를 확인해보도록 하자.
cat /etc/services
...
ssh 22/tcp # SSH Remote Login Protocol
smtp 25/tcp
domain 53/udplinux에서는 0~1023 port는 super user가 사용할 수 있고, 일반 user는 1024 위로만 쓸 수 있다.
TCP는 내부적으로 굉장히 복잡한 기능으로 동작한다. error에 대해서도 검출하고 이를 교정하도록 해야하며, 들어온 packet들을 application의 input data stream으로도 바꿔야하며, 순서도 보장해야한다. 그러나 application 입장은 connection을 열고, 읽고, 쓰고, 닫고만 하면된다. 이는 linux kernel에서 transport layer에 대한 TCP 구현을 완료하였기 때문에 가능한 것이다.
UDP
UDP는 TCP보다 더욱 간단한 transport layer이다. UDP는 TCP와 달리 data stream이 아니라 단일 message를 전달한다. TCP와 달리 UDP는 packet의 순서도 보장하지 않고, packet 유실도 보장하지 않는다. 이는 UDP는 port를 가지지만 connection을 열지 않는다는 말이다. UDP는 packet안에 있는 data에 대한 error 검출 기능을 가지고 있어 host가 이를 알 수 있지만, error를 교정해주는 기능은 없다. 즉, error가 있다고만 알려주는 것이다.
UDP는 TCP에 비해서 overhead가 적기 때문에 msg를 전송하는데 있어서, 상대적으로 빠른 속도를 가진다. packet의 유실과, 순서를 보장하지 않기 때문에, 두 host간의 network가 신뢰성이 보장된 상황을 가정하는 것이다. UDP는 TCP의 error 교정 기능이 필요없는데, error 검출 시스템이 있기도 하고 error가 나와도 별다른 문제가 생기지 않는 경우들도 있기 때문이다.
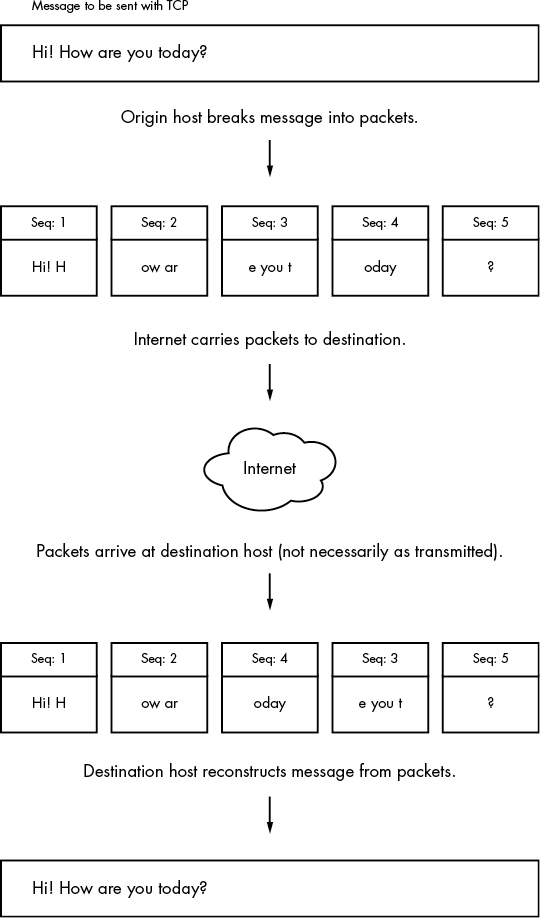
다음은 TCP를 통해서 message를 전송할 때이다. application에서 전달한 data를 정해진 packet 단위인 seq로 나누어 보낸다음, 순서를 교정하고, error를 교정한다. 또한, 유실된 packet에 대한 재요청을 실행하여 받는 이로 하여금 보장된 정보가 오도록 할 수 있다. 잘 보면 data를 정해진 크기로 나누기 때문에 data stream 형식으로 나누어서 들어오는 것을 알 수 있다.
반면, UDP는 data를 나누지 않고 그대로 하나의 packet에 넣어 전달한다. 따라서 data stream 형식이 아니라 msg를 그대로 보낸다고 생각하면 된다. 단지, error가 발생하면 검출은 하지만 교정은 하지 않으며, packet 유실의 위험이 있다.
UDP를 사용하면 application의 대표적인 예제 중 하나는 'Network Time Protocol(NTP)'이다. client는 짧고 간단한 요청을 server에 보내어 현재의 시간을 가져오는 것이다. video chat 역시도 대표적인 예제이다. 빠르게 데이터를 보내되, 응답에 있어서 유실이 발생해도 무시하거나, 다시 같은 요청을 보내기만 하면된다. 조금 응답 packet이 유실이 되어 video의 영상 품질에 모자이크가 발생해도 best affort라고 여기는 것이다.
