Disks and Filesystems
이제 disk와 linux system이 어떻게 같이 동작하는 지 자세히 알아보도록 하자.
알는 간단한 linux disk에 대한 그림이다.
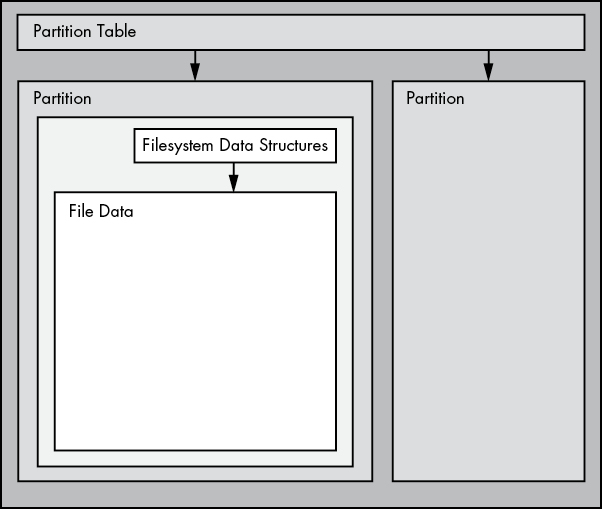
partitions들은 전체 disk에 대한 subdivision들로 전체 block device를 나눈 숫자를 의미한다. 따라서 이들의 이름이 /dev/sda1, /dev/sda3으로 나뉜다. kernel은 각 partition을 하나의 block device로 표현하는 것이다. 각 partition들은 partition table(disk label)이라 불리는 하나의 작은 disk 영역으로 정의된다. 즉, 하나의 disk를 나누는 partition들이, 하나의 partition table에 정의된다는 것이다.
+--------------------------------------------------+
| Physical Disk |
+--------------------------------------------------+
| Block 0 | Block 1 | Block 2 | Block 3 | ... (연속된 블록들)
+--------------------------------------------------+
+---------------------------+----------------------+
| Partition 1 | Partition 2 |
+---------------------------+----------------------+
| Block 0 ~ Block 499 | Block 500 ~ Block 999 |
+---------------------------+----------------------+
(디스크의 블록 일부를 각 파티션이 차지)disk는 여러 block들로 나뉘고, 이 block들의 구역을 나눈 것이 partition들이다.
partition 위의 다음 계층은 filesystem으로, 이는 사용자 공간에서 일반적으로 사용하는 파일과 디렉터리의 데이터베이스 역할을 한다.
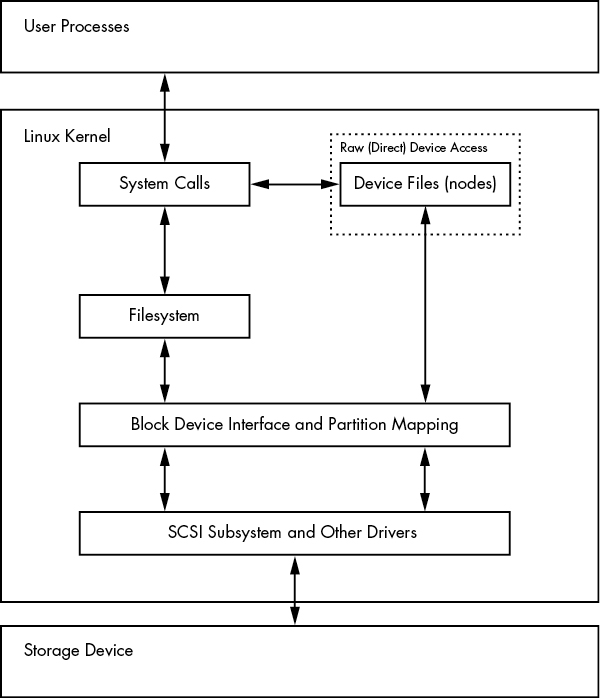
파일 내 데이터를 액세스하려면 먼저 데이터가 있는 disk의 partition table에서 적절한 partition 위치를 찾고, 해당 partition의 파일 시스템 데이터베이스를 검색하여 원하는 파일 데이터를 찾아야 한다.
디스크의 데이터를 액세스하기 위해 Linux 커널은 위에 나타난 계층 구조를 사용한다. SCSI 하위 시스템 및 기타 요소들은 하나의 블록으로 표현된다. 디스크 장치를 통해 직접 작업할 수도 있고, 파일 시스템을 통해 작업할 수도 있다는 점에 주목하자. 두 가지 방법이 어떻게 동작하는지는 이 장에서 살펴볼 것이다. 단순화를 위해 위의 그림은 LVM(linux volume manager)이 포함되지 않았지만, LVM은 블록 장치 인터페이스와 사용자 공간의 몇 가지 관리 구성 요소를 포함하고 있다.
이제 모든 개념이 어떻게 연결되는지 이해하기 위해, 가장 기본적인 partition부터 시작해 보자.
Partitioning Disk Devices
partition table 자체는 단지 disk의 block이 어떻게 나뉘어있는 지를 나타내는 단순한 데이터 집합이다. partition table은 여러 종류가 있다.
예전에는 MBR(Master Boot Record) 방식을 사용하고, 여러 가지 제한이 있다. 대부분의 최신 시스템에서는 전역 고유 식별자 partition table인 GPT(Globally Unique Identifier Partition Table)
다음은 여러 가지 Linux 파티션 도구 중 일부이다:
- parted (“partition editor”): MBR과 GPT를 모두 지원하는 텍스트 기반 도구.
- gparted: parted의 그래픽 버전.
- fdisk: 전통적인 텍스트 기반 Linux 디스크 파티션 도구. 최신 버전의 fdisk는 MBR, GPT뿐만 아니라 다양한 종류의 partition table을 지원하지만, 오래된 버전은 MBR만 지원했다.
MBR과 GPT를 오랫동안 지원해 왔으며, 단일 명령으로 쉽게 파티션 레이블을 확인할 수 있기 때문에 partition table을 표시할 때는 parted를 사용할 것이다. 그러나 partition table을 생성하고 수정할 때는 fdisk를 사용할 것이다. 이를 통해 두 인터페이스를 비교하고, 많은 사용자가 fdisk를 선호하는 이유에 대해서 알아보도록 하자.
참고로 filesystem과 partitioning system은 서로 다르다.
Viewing a Partitioning Table
parted -l 명령어를 사용하면 subsystem의 partition table을 볼 수 있다.
parted -l
Model: ATA KINGSTON SM2280S (scsi)
1 Disk /dev/sda: 240GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 223GB 223GB primary ext4 boot
2 223GB 240GB 17.0GB extended
5 223GB 240GB 17.0GB logical linux-swap(v1)
Model: Generic Flash Disk (scsi)
2 Disk /dev/sdf: 4284MB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 1050MB 1049MB myfirst
2 1050MB 4284MB 3235MB mysecond두 disk에 대한 partition table들이 있는 것을 볼 수 있다. 첫번째 partition table은 /dev/sda에 관한 것으로 MBR partition table type을 사용한다. 이는 위에서 msdos라는 것으로 표현된다. 두번째는 /dev/sdf disk로 GPT partition table type을 가지는 것을 볼 수 있다.
partition table을 읽을 때 단위 크기에 주의해야 한다. parted의 출력은 사람이 읽기 쉽게 보이도록 크기를 대략적으로 표시한다. 반면, fdisk -l은 정확한 숫자를 표시하지만, 대부분의 경우 단위가 512바이트 "섹터"로 되어 있어 혼란을 줄 수 있다. 이 때문에 디스크와 파티션 크기가 실제보다 두 배로 보일 수도 있다.
fdisk의 partition table을 자세히 보면, 섹터 크기에 대한 정보도 포함되어 있음을 확인할 수 있다.
위 예제에서 MBR 테이블은 기본(primary), 확장(extended), 논리(logical) 파티션을 포함하고 있다. 기본 파티션은 디스크의 일반적인 분할 방식이며, 파티션 1이 그 예시이다.
MBR의 기본 구조는 최대 4개의 기본 파티션만 지원하므로, 그 이상이 필요할 경우 하나를 확장 파티션(extended partition)으로 지정해야 한다. 확장 파티션은 여러 개의 논리 파티션으로 나뉘며, 운영 체제는 이를 일반 파티션처럼 사용할 수 있다. 예제에서 파티션 2가 확장 파티션이며, 이 안에 논리 파티션 5가 포함되어 있다.
일반적으로 확장 partition은 무시되며, 그 안에 있는 논리 파티션만 접근하는 경우가 많다.
partition table을 확인할 때 LVM(code 8e)으로 표시된 파티션, /dev/dm-* 장치, 또는 "device mapper"에 대한 참조가 보인다면, 해당 시스템은 LVM을 사용 중인 것이다.
우리는 먼저 전통적인 직접 디스크 파티셔닝 방식부터 살펴볼 것이며, LVM을 사용하는 시스템과는 약간 다른 방식으로 보일 것이다.
먼저, LVM을 사용하는 시스템(parted -l 출력 예제)이 어떻게 표시되는지 간단히 확인해 보자. 다음은 VirtualBox에서 LVM을 사용하여 Ubuntu를 새로 설치했을 때의 실제 partition table 일부이다. 일반적인 partition table과 비슷하지만, lvm 플래그가 추가된 것이 차이점이다.
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sda: 10.7GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 10.7GB 10.7GB primary boot, lvm그런 다음, 파티션처럼 보이지만 "디스크"로 표시되는 장치들이 있다.
Model: Linux device-mapper (linear) (dm)
Disk /dev/mapper/ubuntu--vg-swap_1: 1023MB
Sector size (logical/physical): 512B/512B
Partition Table: loop
Disk Flags:
Number Start End Size File system Flags
1 0.00B 1023MB 1023MB linux-swap(v1)
Model: Linux device-mapper (linear) (dm)
Disk /dev/mapper/ubuntu--vg-root: 9672MB
Sector size (logical/physical): 512B/512B
Partition Table: loop
Disk Flags:
Number Start End Size File system Flags
1 0.00B 9672MB 9672MB ext4실제로 어떻게 동작하는 것인지에 대해서는 아래에 더 자세히 알아보도록 하자.
Modifying Partition Tables
partition을 수정하는 일은 매우 위함한 작업이다. 일단 수정되고 난 뒤에는 복구가 어려우며 그 안에 있는 데이터들이 유실될 수 있다.
fdisk와 parted의 가장 큰 차이는 fdisk는 디자인한 partition table이 바로 적용되는 것이 아니라, 리뷰를 받고 이에 대해서 반영할 지 결정을 하게 된다. 반면에 parted는 command를 입력한 대로 바로 실행되어 리뷰를 받지 못한다는 차이가 있다.
이러한 차이점은 두 유틸리티가 커널과 상호 작용하는 방식에도 영향을 미친다. fdisk와 parted는 모두 사용자 공간에서 partition을 변경하며, partition table을 재작성하는 데 직접적인 커널의 지원이 필요하지 않다. 왜냐하면 사용자 공간에서는 device driver를 통해서 block 장치의 모든 것을 읽고 수정할 수 있기 때문이다.
하지만 결국 커널은 partition table을 읽어야 파티션을 블록 장치로 표시하여 사용자가 이를 이용할 수 있게 된다. fdisk는 상대적으로 간단한 방법을 사용한다. partition table을 수정한 후, fdisk는 커널에 partition table을 다시 읽도록 알려주는 하나의 system call을 실행한다. 커널은 디버깅 출력을 생성하며, 이를 journalctl -k 명령어로 확인할 수 있다. 예를 들어, /dev/sdf에 두 개의 파티션을 생성했다면 다음과 같은 출력을 볼 수 있다.
sdf: sdf1 sdf2parted 도구는 이와 같은 디스크 단위 시스템 호출을 사용하지 않는다. 대신, 개별 파티션이 변경될 때마다 커널에 신호를 보낸다. 하나의 파티션 변경을 처리한 후, 커널은 앞서 언급한 디버깅 출력을 생성하지 않는다.
파티션 변경을 확인하는 몇 가지 방법이 있다.
udevadm을 사용하여 커널 이벤트 변경을 모니터링할 수 있다. 예를 들어, udevadm monitor --kernel 명령어를 실행하면 구식 파티션 장치가 제거되고 새 파티션 장치가 추가되는 것을 볼 수 있다.
/proc/partitions에서 전체 파티션 정보를 확인할 수 있다.
/sys/block/device/에서 변경된 파티션 시스템 인터페이스를 확인하거나 /dev에서 변경된 파티션 장치를 확인할 수 있다.
partition table 수정 사항을 반드시 확인해야 할 경우, blockdev 명령어를 사용하여 fdisk에서 발행하는 오래된 방식의 시스템 호출을 수행할 수 있다. 예를 들어, /dev/sdf에서 partition table을 강제로 다시 읽게 하려면 다음 명령을 실행한다:
blockdev --rereadpt /dev/sdf이제 빈 디스크에서 partition table을 생성하는 방법을 실행해보자. 아래는 다음의 시나리오를 보여준다.
- 4GB 디스크
- MBR sytle의 partition table
- ext4 file system을 채울 두 partition 200MB, 3.8GB
- disk 장치 위치는
/dev/sdd로lsblk로 장치 위치를 찾아야 한다. - 작업은
fdisk를 사용한다.fdisk는 대화형 명령어로, 디스크에 아무것도 마운트 되지 않았는지 확인한 후 디바이스 이름을 지정하여 명령 프롬프트에서 시작한다.
fdisk /dev/sdd이후 아래와 같은 prompt가 나온다.
Command (m for help):먼저 p 명령어로 현재 partition table을 출력한다. 상호작용은 대체로 다음과 같아 보일 것이다.
Command (m for help): p
Disk /dev/sdd: 4 GiB, 4284481536 bytes, 8368128 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x88f290cc
Device Boot Start End Sectors Size Id Type
/dev/sdd1 2048 8368127 8366080 4G c W95 FAT32 (LBA)대부분의 device는 이미 FAT 스타일의 partition이 하나 있을 것이다. 여기서는 리눅스를 위한 새 partition을 위해 기존 partition을 삭제한다. d 명령어 사용
Command (m for help): d
Selected partition 1
Partition 1 has been deleted.fdisk는 명시적으로 partition table을 저장하기 전까지는 변경을 하지 않으므로, 실수로 복구할 수 없는 변경을 했다면 q 명령어로 종료할 수 있따.
이제 첫 번째 200MB partition을 n 명령어로 생성한다.
Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
Select (default p): p
Partition number (1-4, default 1): 1
First sector (2048-8368127, default 2048): 2048
Last sector, +sectors or +size{K,M,G,T,P} (2048-8368127, default 8368127): +200M위 명령어에서 fdisk는 MBR partition style, partition number, 시작 섹터, 끝 섹터(또는 크기)를 묻는다.
두 번째 파티션을 만들 때는 동일한 방식으로 작업하지만, 모든 기본 값을 그대로 사용한다. 작업이 끝나면 p 명령어로 파티션 테이블을 다시 출력하여 확인한다.
partition table을 작성하려면 w 명령어를 사용하면 된다. 이를 통해서 kernel이 알게되어 partition을 적용하는 것이다.
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.fdisk는 사용자가 확인하지 않더라도 즉시 작업을 완료하고 종료하므로 항상 신중해야한다.
Navigating Disk and Partition Geometry
하드 디스크를 블록 장치로 생각하고 어느 블록이든 무작위로 접근할 수 있다고 생각할 수 있지만, 시스템이 디스크에 데이터를 배치하는 방식에 신경 쓰지 않으면 성능에 심각한 영향을 미칠 수 있다. 예를 들어, 단일 플래터 디스크의 물리적 특성을 고려해보자.
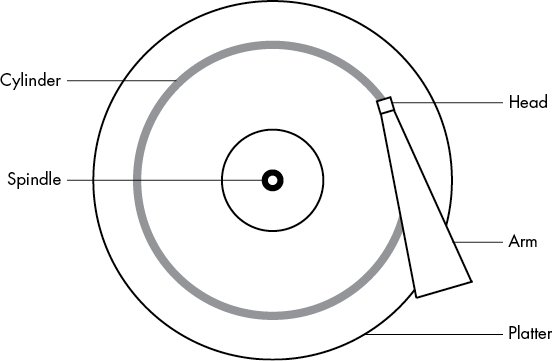
disk는 spin들에 장착된 회전하는 플래터로 구성되어 있으며, 디스크의 반경을 가로지르며 움직일 수 있는 팔에 부착된 헤드가 데이터를 읽는다. disk가 헤드 아래에서 회전할 때, 헤드는 데이터를 읽을 수 있다. 팔이 한 위치에 있을 때, 헤드는 고정된 원에서만 데이터를 읽을 수 있다. 이 원은 실린더라고 불리며, 더 큰 disk에는 여러 개의 플래터가 있으며, 모든 플래터는 하나의 스핀들을 중심으로 회전한다. 각 플래터에는 상단과/또는 하단에 대한 헤드가 하나 또는 두 개 있을 수 있으며, 모든 헤드는 같은 팔에 연결되어 함께 움직인다. 팔이 움직이기 때문에 디스크에는 작은 실린더부터 디스크 주변의 큰 실린더까지 많은 실린더가 존재한다. 마지막으로, 실린더는 섹터라고 불리는 조각으로 나눌 수 있다. 디스크 기하학을 이렇게 생각하는 방식을 CHS(실린더-헤드-섹터)라고 하며, 구형 시스템에서는 이 세 가지 매개변수로 디스크의 어느 부분이든 접근할 수 있었다.
트랙은 실린더의 일부로, 하나의 헤드가 접근하는 부분이다. 따라서 위 그림에서 실린더는 트랙이기도 하다. 트랙에 대해서 걱정할 필요는 없다.
커널과 여러 파티션 프로그램은 디스크가 보고하는 실린더 수를 알려준다. 그러나 최근의 하드 디스크에서는 보고되는 값이 사실이 아니다! CHS를 사용하는 전통적인 주소 지정 방식은 현대 디스크 하드웨어에 맞지 않으며, 외부 실린더에 더 많은 데이터를 배치할 수 있다는 사실을 고려하지 않는다. 디스크 하드웨어는 논리 블록 주소 지정(LBA)을 지원하여 디스크의 위치를 블록 번호로 지정한다(이것은 훨씬 더 직관적인 인터페이스이다). 그러나 CHS의 잔재는 여전히 존재한다. 예를 들어, MBR 파티션 테이블에는 CHS 정보와 LBA 동등 값이 포함되어 있으며, 일부 부트 로더는 여전히 CHS 값을 믿는 경우가 있다(걱정하지 마라—대부분의 리눅스 부트 로더는 LBA 값을 사용한다).
실린더라는 개념은 한때 파티션을 만들 때 매우 중요했다. 실린더는 파티션의 이상적인 경계로, 실린더에서 데이터를 읽는 것은 매우 빠르다. disk가 회전하면서 헤드는 데이터를 계속해서 읽을 수 있기 때문이다. 인접한 실린더들로 구성된 파티션은 헤드가 실린더 간에 먼 거리를 이동하지 않아도 되므로 빠른 연속 데이터 접근을 가능하게 한다.
비록 disk 예전과 비슷하게 보이지만, 정밀한 파티션 정렬 개념은 더 이상 중요하지 않다. 일부 오래된 파티션 프로그램은 파티션을 실린더 경계에 정확히 배치하지 않으면 불평하지만, 신경 쓰지 말라. 현대 디스크의 보고된 CHS 값은 단순히 사실이 아니기 때문이다. 디스크의 LBA 방식과 최신 파티션 유틸리티의 더 나은 논리는 파티션이 합리적인 방식으로 배치되도록 보장한다.
Reading from Solid-State Disks
이동하는 부품이 없는 저장 장치인 솔리드 스테이트 디스크(SSD)는 회전하는 디스크와는 접근 특성이 근본적으로 다르다. SSD의 경우, 회전하는 플래터를 가로질러 헤드가 움직일 필요가 없으므로 랜덤 접근에 문제가 되지 않지만, SSD 성능에 영향을 미칠 수 있는 몇 가지 특성이 있다.
SSD 성능에 영향을 미치는 가장 중요한 요소 중 하나는 파티션 정렬이다. SSD에서 데이터를 읽을 때, 데이터를 청크 단위(페이지라고 불린다. 단, 가상 메모리 페이지와는 구별됨)로 읽으며, 보통 4,096바이트 또는 8,192바이트씩 읽는다. 읽기는 그 크기의 배수로 시작해야 한다. 즉, 파티션과 그 데이터가 경계에 맞지 않으면, 디렉터리 내용과 같은 작은 일반적인 작업을 수행할 때 한 번의 읽기 대신 두 번의 읽기를 해야 할 수 있다.
상당히 최신 버전의 파티션 유틸리티는 새로 생성된 파티션을 디스크의 시작 지점에서 적절한 오프셋(partition이 disk의 시작지점으로부터 얼마정도나 떨어져 있는 가)으로 배치하는 로직을 포함하고 있으므로, 부적절한 파티션 정렬에 대해 걱정할 필요는 없을 것이다. 현재 파티션 도구는 계산을 하지 않고, 대신 파티션을 1MB 경계에 정렬하거나, 더 정확하게는 2,048개의 512바이트 블록에 맞춰 배치한다. 이는 매우 보수적인 접근 방식으로, 이 경계는 4,096바이트, 8,192바이트 등의 페이지 크기와, 심지어 1,048,576바이트에 맞춰 정렬된다.
하지만, 궁금하거나 파티션이 경계에서 시작하는지 확실히 알고 싶다면, /sys/block 디렉토리에서 이 정보를 쉽게 확인할 수 있다. 예를 들어, /dev/sdf2 파티션의 경우는 다음과 같이 확인할 수 있다:
cat /sys/block/sdf/sdf2/start
1953126여기서 출력된 값은 디스크 시작 지점에서 파티션의 오프셋(partition이 disk의 시작지점으로부터 얼마정도나 떨어져 있는 가)을 512바이트 단위로 표시한 것이다(리눅스 시스템에서는 혼동을 피하기 위해 섹터라고도 한다). 만약 이 SSD가 4,096바이트 페이지를 사용한다면, 페이지당 8개의 섹터가 있다. 이제 파티션 오프셋을 8로 나눠서 나누어 떨어지는지 확인하면 된다. 이 경우, 나누어 떨어지지 않으므로 파티션은 최적 성능을 얻지 못할 것이다.
Filesystems
커널과 사용자 공간 간의 마지막 연결은 일반적으로 파일 시스템이다. 이는 ls, cd와 같은 명령어를 실행할 때 우리가 일반적으로 상호작용하는 부분이다. 파일 시스템은 데이터베이스의 일종으로 파일 시스템은 단순한 블록 장치를 사용자가 이해할 수 있는 정교한 파일과 하위 디렉토리 계층 구조로 변환하는 구조를 제공한다.
전통적으로 파일 시스템은 커널에서 구현되었지만, Plan 9의 9P(https://en.wikipedia.org/wiki/9P_(protocol))가 혁신적인 영향을 미쳤고, 이를 통해 사용자 공간 파일 시스템의 개발이 가능해졌다. 리눅스에서 사용자 공간 파일 시스템을 가능하게 하는 기능은 FUSE(File System in User Space)이다.
가상 파일 시스템(VFS) 추상화 계층은 파일 시스템 구현을 완성한다. SCSI 서브시스템이 다양한 장치 유형과 커널 제어 명령 간의 통신을 표준화하는 것처럼, VFS는 모든 파일 시스템 구현이 표준 인터페이스를 지원하도록 하여 사용자 공간 애플리케이션이 파일과 디렉토리에 동일한 방식으로 접근할 수 있게 해준다. VFS 지원 덕분에 리눅스는 엄청나게 많은 파일 시스템을 지원할 수 있게 되었다.
Filesystem Types
리눅스에서 인식되는 파일 시스템 유형은 다음과 같다.
- 확장된 파일 시스템(ext4)은 리눅스에 네이티브로 최적화된 파일 시스템 라인의 현재 버전이다. 두 번째 확장 파일 시스템(ext2)은 전통적인 유닉스 파일 시스템인 Unix File System(UFS)과 Fast File System(FFS)을 참고하여 리눅스 시스템의 기본 파일 시스템으로 오랫동안 사용되었다. 세 번째 확장 파일 시스템(ext3)은 저널 기능을 추가하여 데이터 무결성을 향상시키고 부팅 속도를 빠르게 했다. ext4 파일 시스템은 점진적인 개선을 거쳐 ext2나 ext3보다 더 큰 파일과 더 많은 하위 디렉토리를 지원한다.
확장 파일 시스템 시리즈는 어느 정도의 하위 호환성을 갖고 있다. 예를 들어, ext2와 ext3 파일 시스템은 서로 마운트할 수 있고, ext2와 ext3 파일 시스템은 ext4로 마운트할 수 있지만, 반대로 ext4를 ext2나 ext3으로 마운트할 수는 없다.
- Btrfs(B-tree 파일 시스템)는 리눅스를 위해 설계된 최신 파일 시스템으로, ext4의 한계를 넘어서는 확장성을 제공한다.
- FAT 파일 시스템(msdos, vfat, exfat)은 Microsoft 시스템과 관련이 있다. msdos는 MS-DOS 시스템에서 매우 간단한 단일 대소문자 파일 시스템을 지원한다. 대부분의 이동식 플래시 미디어(예: SD 카드, USB 드라이브)는 기본적으로 vfat(4GB 이하) 또는 exfat(4GB 이상) 파티션을 포함한다. Windows 시스템은 FAT 기반 파일 시스템 또는 더 발전된 NT 파일 시스템(ntfs)을 사용할 수 있다.
- XFS는 고성능 파일 시스템으로, Red Hat Enterprise Linux 7.0 이상에서 기본적으로 사용된다.
- HFS+(hfsplus)는 대부분의 맥 시스템에서 사용되는 Apple의 표준 파일 시스템이다.
- ISO 9660(iso9660)은 CD-ROM 표준으로, 대부분의 CD-ROM은 이 표준의 변형을 사용한다.
새로운 storage를 준비하는 경우, partition 작업을 완료했다면 filesystem 생성 준비가 완료된 것이다. partition 작업과 마찬가지로 filesystem을 생성하는 작업도 사용자 공간에서 진행된다. 사용자 공간 process는 block장치에 직접 접근하고 이를 조작할 수 있기 때문이다.
# mkfs -t ext4 /dev/sdf2위의 명령어를 통해서 /dev/sdf2로 ext4 type의 filesystem을 연결할 수 있다. 그러나, 생성한 것일 뿐 연결된 것은 아니다. 이를 위해서는 mount가 필요하다.
mkfs program은 자동으로 장치의 블록 수를 결정하고 몇 가지 합리적인 기본값을 설정한다. 일반적으로는 기본값을 변경하지 않는 것이 좋다.
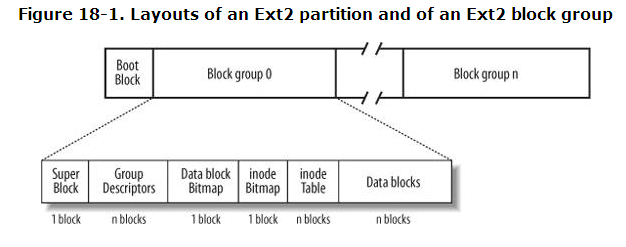
참고로 disk는 여러 개의 partition으로 나뉠 수 있고, 각 partition에는 filesystem 적용을 받아서, 여러 개의 block group으로 나뉠 수 있다. 즉, block group은 filesystem에서 block들을 관리하기 위한 그룹인 것이다. filesystem에 대한 메타 데이터를 저장하고 관리하는 것이 바로 super block이며 filesystem 당 하나이다. 즉, filesystem에 n개의 block group이 있다고 하더라도, superblock은 한 개이며, 각 block group에 superblock이 가진 filesystem 메타 데이터가 적용된다는 것이다.
파일 시스템을 생성할 때, mkfs는 작업을 진행하면서 진단 출력을 표시하며, 그 중에는 super block과 관련된 출력도 포함된다. super block은 파일 시스템 데이터베이스의 최상위 수준에 있는 핵심 구성 요소로, 매우 중요하다. mkfs는 원본 super block이 손상될 경우를 대비해 여러 개의 백업을 생성한다. 디스크 장애가 발생했을 때 super block을 복구할 필요가 있을 경우를 대비해, mkfs가 실행될 때 몇 개의 슈퍼블록 백업 번호를 기록하는 것이 좋다.
파일 시스템 생성 작업은 새 디스크를 추가하거나 오래된 디스크를 재파티셔닝한 후에만 수행해야 한다. 기존에 데이터가 있는 파티션에 파일 시스템을 생성하면, 기존 데이터를 사실상 파괴하게 된다.
Mounting a Filesystem
unix에서 filesystem을 실행 중인 시스템에 연결하는 과정을 마운팅(mounting)이라고 한다. 시스템이 부팅될 때, 커널은 일부 구성 데이터를 읽고 이를 바탕으로 루트(/) 파일 시스템을 마운트한다.
filesystem을 마운트하려면 다음과 같은 정보를 알아야 한다.
- filesystem의 장치, 위치 또는 식별자 (실제 파일 시스템 데이터가 있는 디스크 파티션 등). proc나 sysfs와 같은 일부 특수 목적 파일 시스템은 위치가 필요 없다.
- 파일 시스템 유형
- mount point: filesystem이 시스템의 현재 디렉터리 계층에 연결될 위치. 마운트 지점은 항상 정상적인 디렉터리여야 한다. 예를 들어, 음악 파일을 포함하는 파일 시스템의 경우
/music을 마운트 지점으로 사용할 수 있다. 마운트 지점은/아래에 반드시 있을 필요는 없으며, 시스템의 어느 곳에나 있을 수 있다.
파일 시스템을 마운트할 때의 일반적인 용어는 "장치를 마운트 지점에 마운트하다"이다. 시스템의 현재 파일 시스템 상태를 확인하려면mount명령을 실행한다.
mount
/dev/sda1 on / type ext4 (rw,errors=remount-ro)
proc on /proc type proc (rw,noexec,nosuid,nodev)
sysfs on /sys type sysfs (rw,noexec,nosuid,nodev)
fusectl on /sys/fs/fuse/connections type fusectl (rw)
debugfs on /sys/kernel/debug type debugfs (rw)
securityfs on /sys/kernel/security type securityfs (rw)
udev on /dev type devtmpfs (rw,mode=0755)
devpts on /dev/pts type devpts (rw,noexec,nosuid,gid=5,mode=0620)
tmpfs on /run type tmpfs (rw,noexec,nosuid,size=10%,mode=0755)
--snip--각 라인은 현재 마운트된 파일 시스템 하나를 나타내며, 항목은 다음 순서로 구성된다:
- 장치, 예를 들어 /dev/sda3. 이 중 일부는 실제 장치가 아닌, proc처럼 장치 이름을 대신하는 특수 파일 시스템일 수 있다.
- "on"이라는 단어.
- 마운트 지점.
- "type"이라는 단어.
- 파일 시스템 유형, 보통 짧은 식별자로 나타낸다.
- 마운트 옵션 (괄호 안에 표시됨).
파일 시스템을 수동으로 마운트하려면 mount 명령을 다음과 같이 사용한다.
mount -t type device mountpoint예를 들어, /dev/sdf2 장치에 있는 Fourth Extended 파일 시스템을 /home/extra에 마운트하려면 다음 명령을 사용한다:
mount -t ext4 /dev/sdf2 /home/extra보통 -t type 옵션을 지정할 필요는 없다. mount 명령이 보통 파일 시스템 유형을 자동으로 알아내기 때문이다. 그러나 두 개 이상의 비슷한 유형을 구분해야 할 때는 명시적으로 지정해야 할 수 있다. 예를 들어, 여러 가지 FAT 스타일 파일 시스템을 구분할 때 사용한다.
파일 시스템을 마운트 해제(umount) 하려면 umount 명령을 다음과 같이 사용한다:
umount mountpoint장치로 파일 시스템을 마운트 해제할 수도 있다:
umount /dev/sdf2거의 모든 리눅스 시스템에는 임시 마운트 지점인 /mnt가 포함되어 있다. 이 마운트 지점은 보통 테스트 용도로 사용된다. 시스템을 실험할 때는 이 지점을 사용해도 되지만, 장기간 파일 시스템을 마운트하려면 다른 위치를 만들거나 찾아서 사용하는 것이 좋다.
위와 같이 device 이름으로도 filesystem을 마운트할 수 있지만, blkid를 통해서 장치의 uuid를 찾아낸 후에 uuid를 통해서 마운트를 할 수도 있다. 이는 장치의 이름이 고유하지 않는 linux system의 단점을 해결하기 위한 것이다. 이에 대해서는 다루지 않는다.
mount로 파일 시스템 옵션을 활성화하려면 -o 스위치를 사용하고 뒤에 옵션을 지정한다. 예를 들어, -o remount,rw는 이미 읽기 전용으로 마운트된 파일 시스템을 읽기-쓰기 모드로 다시 마운트한다.
-r:-r옵션은 파일 시스템을 읽기 전용 모드로 마운트한다. 이 옵션은 쓰기 방지나 부팅 시 초기화 등의 용도로 사용된다. 읽기 전용 장치(예: CD-ROM)에 접근할 때는 이 옵션을 지정할 필요가 없으며, 시스템이 자동으로 처리하고 읽기 전용 상태를 알려준다.-n:-n옵션은 mount가 시스템 실행 중인 마운트 데이터베이스인/etc/mtab을 업데이트하지 않도록 한다. 기본적으로 마운트 작업은 이 파일에 쓸 수 없으면 실패하는데, 이 옵션은 부팅 시에 중요하다. 루트 파티션(시스템 마운트 데이터베이스 포함)이 처음에는 읽기 전용이기 때문이다. 또한, 단일 사용자 모드에서 시스템 문제를 해결할 때 이 옵션을 유용하게 사용할 수 있다.-t:-ttype 옵션은 파일 시스템 유형을 지정한다.
mount -t vfat /dev/sde1 /dos -o ro,uid=1000vflat filesystem type으로 /dev/sde1 장치에 대해서 /dos 디렉터리로 마운트해달라는 것이다. 단, mount 옵션으로 ro는 read-only 모드로 하겠다는 것이고, uid=1000은 파일 시스템에 있는 모든 파일을 사용자 ID 1000이 소유한 것처럼 처리한다는 것이다.
Disk Buffering, Caching, and Filesystems
-
디스크 버퍼링 (Disk Buffering): 리눅스와 다른 유닉스 계열 운영 체제에서는 디스크에 대한 쓰기 작업을 버퍼링한다. 즉, 파일 시스템의 변경 사항을 요청할 때마다 커널이 즉시 디스크에 기록하지 않는다. 대신, 변경 사항을 RAM에 저장하고, 커널이 적절한 시점을 판단해 이를 디스크에 기록한다. 이러한 버퍼링 시스템은 사용자가 인식할 수 없으며, 성능 향상에 매우 중요한 역할을 한다.
-
파일 시스템 동기화 (Sync):
umount명령을 통해 파일 시스템을 마운트 해제(unmount)하면, 커널은 자동으로 디스크와 동기화하여 RAM에 저장된 변경 사항을 디스크에 기록한다.sync명령을 실행하면, 시스템의 모든 디스크를 동기화하는데 사용된다. 이 명령을 사용하면 디스크에 남아 있는 변경 사항을 강제로 디스크에 기록할 수 있다. 시스템을 종료하기 전에 파일 시스템을 마운트 해제할 수 없을 경우, sync 명령을 먼저 실행하여 데이터 손실을 방지하는 것이 좋다. -
디스크 캐싱 (Disk Caching): 커널은 디스크에서 읽은 블록을 RAM에 캐시하여 저장한다. 이렇게 하면, 같은 파일에 대해 여러 번 접근하는 프로세스가 있을 경우, 매번 디스크에 접근하지 않고 캐시에서 읽어서 성능과 자원을 절약할 수 있다.
정리하자면 filesystem은 데이터 읽기, 쓰기에 있어서 디스크 버퍼링과 캐싱을 통해 시스템 성능을 최적화하며, 사용자는 이를 신경 쓸 필요 없이 투명하게 처리된다. sync 명령이나 umount 명령으로 디스크와 커널 간의 동기화를 관리할 수 있다.
The /etc/fstab Filesystem Table
mount 시스템들은 시스템이 종료되면 초기화된다. 따라서, 부팅 시 시스템이 자동으로 mount하도록 파일 시스템과 옵션에 대한 영구적인 목록을 저장할 수 있따. 이는 간단한 평식의 평문 파일로 /etc/fstab이 그 역할을 한다.
UUID=70ccd6e7-6ae6-44f6-812c-51aab8036d29 / ext4 errors=remount-ro 0 1
UUID=592dcfd1-58da-4769-9ea8-5f412a896980 none swap sw 0 0
/dev/sr0 /cdrom iso9660 ro,user,nosuid,noauto 0 0각 줄은 하나의 파일 시스템에 해당하며, 여섯 개의 필드로 나뉜다. 왼쪽에서 오른쪽으로 각 필드는 다음과 같다:
- 디바이스 또는 UUID: 최신 리눅스 시스템은 /etc/fstab에서 장치 이름 대신 UUID를 사용하는 것을 선호한다.
- 마운트 지점: 파일 시스템을 붙일 위치를 나타낸다.
- 파일 시스템 유형: 여기서는 swap 파티션을 볼 수 있다; 이는 스왑 파티션을 의미한다.
- 옵션: 쉼표로 구분된 긴 옵션들이다.
- 백업 정보: dump 명령어에서 사용되는 백업 정보로, 현재는 더 이상 관련이 없다. 이 필드는 항상 0으로 설정해야 한다.
- 파일 시스템 무결성 검사 순서: 루트 파일 시스템에는 항상 1을 설정하고, 다른 로컬 파일 시스템에는 2를 설정한다. fsck는 루트부터 먼저 검사하도록 보장한다. 0은 부팅 시 검사하지 않도록 설정한다.
/etc/fstab에 있는 모든 항목을 한 번에 마운트하려면 mount -a을 사용할 수 있다.
/etc/fstab을 대신하여 /etc/fstab.d 디렉터리를 사용하여 각 filesystem에 대한 개별적인 구성 파일을 사용할 수 있다. 또는 systemd unit을 설정하는 방법이 있다.
Filesystem Capacity
현재 마운트된 파일 시스템의 크기와 사용 상태를 확인하려면 df 명령어를 사용한다. 출력은 매우 방대할 수 있는데, 이는 전문 파일 시스템 덕분이다. 하지만 출력에는 실제 저장 장치에 대한 정보가 포함된다.
df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda1 214234312 127989560 75339204 63% /
/dev/sdd2 3043836 4632 2864872 1% /media/user/uuiddf 명령어 출력에서 각 필드에 대한 간단한 설명은 다음과 같다:
- Filesystem: 파일 시스템 장치
- 1K-blocks: 파일 시스템의 전체 용량(1,024 바이트 블록 기준)
- Used: 사용된 블록의 수
- Available: 남은(사용할 수 있는) 블록의 수
- Use%: 사용된 블록의 비율
- Mounted on: 마운트된 위치
특정 디렉터리에 대한 filesystem을 찾고 싶다면 df {path}을 사용하면 된다. 가령 df /home/ec2-user를 입력하면 ec2-user에 대한 directory가 나온다.
현재 디렉터리에 있는 파일들에 대한 용량을 알고 싶다면 du를 쓰면 된다. du {path}를 써도 된다. 옵션으로 -s를 쓰면 요약 모드로 총합만 출력된다. 참고로 일부 숨김 디렉터리는 포함이 안된다.
Checking and Repairing Filesystems
filesystem을 점검하는 도구는 fsck이다. mkfs 프로그램처럼, 리눅스가 지원하는 각 filesystem 유형에 대해 별도의 fsck 버전이 존재한다. 예를 들어, 확장 파일 시스템 시리즈(ext2/ext3/ext4)에서 fsck를 실행하면 filesystem type을 인식하고 e2fsck 유틸리티를 시작한다. 일반적으로는 e2fsck를 입력할 필요가 없으며, fsck가 filesystem type을 파악할 수 없거나 e2fsck 매뉴얼 페이지를 찾고 있을 때만 입력한다.
fsck /dev/sdb1마운트된 파일 시스템에서 fsck를 사용하지 말자, 커널이 점검을 실행하는 동안 디스크 데이터를 변경할 수 있으며, 이로 인해 실행 중 일치하지 않는 데이터가 발생해 시스템이 충돌하거나 파일이 손상될 수 있다. 유일한 예외는 루트 파티션을 읽기 전용으로 마운트한 후 단일 사용자 모드에서 실행하는 경우이다.
인터랙티브 모드에서 fsck는 각 패스에 대해 자세한 상태 보고서를 출력한다. 문제가 없을 경우 출력은 다음과 같다:
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/sdb1: 11/1976 files (0.0% non-contiguous), 265/7891 blocksfsck가 문제를 발견하면 중단하고 문제를 해결하기 위한 질문을 한다. 이 질문들은 파일 시스템의 내부 구조와 관련된 문제를 해결하는 것과 관련이 있다.
Special-Purpose Filesystems
시스템 인터페이스로서 기능하는 filesystem이 있다. 즉, 데이터를 장치에 저장하는 수단으로만 사용되는 것이 아니라, process ID나 커널 진단과 같은 시스템 정보를 나타낼 수 있는 파일 시스템이다. 이 개념은 /dev 메커니즘에서 시작되었으며, 이는 I/O 인터페이스로 파일을 사용하는 초기 모델이었다.
리눅스에서 일반적으로 사용되는 특수 목적 파일 시스템은 다음과 같다.
- proc
- 마운트 위치:
/proc - 설명:
proc는 프로세스를 의미하는 약어로, 각 디렉토리는 시스템에서 실행 중인 프로세스를 나타내며, 그 디렉토리 내 파일들은 해당 프로세스의 다양한 정보를 나타낸다. 예를 들어,/proc/1234는 프로세스 ID가 1234인 프로세스를 나타낸다. 또한/proc/self는 현재 프로세스를 나타낸다. 리눅스의 proc 파일 시스템은/proc/cpuinfo와 같은 커널 및 하드웨어 정보를 포함한다. 그러나 커널 설계 지침에 따르면, 프로세스와 관련이 없는 정보는/proc에서/sys로 이동하는 것이 권장되므로,/proc에 있는 시스템 정보가 최신 인터페이스가 아닐 수도 있다.
- sysfs
- 마운트 위치:
/sys - 설명:
/sys는 커널 객체와 그 상태를 나타내는 파일 시스템으로, 시스템의 하드웨어와 설정을 나타내는 정보를 포함한다. 예를 들어,/sys/class디렉토리는 시스템의 장치 클래스를 나타낸다. 이 파일 시스템은 커널과 사용자 공간 간의 상호 작용을 위한 중요한 메커니즘을 제공한다.
- tmpfs
- 마운트 위치:
/run및 기타 위치 - 설명:
tmpfs는 물리적 메모리와 스왑 공간을 임시 저장소로 사용할 수 있는 파일 시스템이다. 임시 파일 저장소로 주로 사용되며, 예를 들어 시스템 부팅 시/run디렉토리가tmpfs로 마운트된다.tmpfs는 사용자가 원하는 위치에 마운트할 수 있으며,size및nr_blocks와 같은 옵션을 사용하여 최대 크기를 제어할 수 있다. 하지만 지속적으로 데이터를tmpfs에 쌓으면 시스템 메모리가 부족해져 프로그램이 크래시할 수 있으므로 주의가 필요하다.
- squashfs
- 설명:
squashfs는 읽기 전용 파일 시스템으로, 콘텐츠는 압축 형식으로 저장되며 필요에 따라 루프백 장치를 통해 동적으로 추출된다. 이 파일 시스템은snap패키지 관리 시스템에서 사용되며, 패키지는/snap디렉토리 아래에 마운트된다.squashfs는 주로 소프트웨어 배포 및 리눅스 배포판의 루트 파일 시스템으로 사용된다.
- overlay
- 설명: overlay는 여러 디렉토리를 결합하여 하나의 복합 파일 시스템을 형성하는 파일 시스템이다. 오버레이 파일 시스템은 주로 컨테이너에서 사용된다. 이는 여러 계층을 결합하여 독립적인 파일 시스템을 생성하는 방식으로, 특히 도커(Docker)와 같은 컨테이너화된 환경에서 자주 사용된다. 이 파일 시스템은 파일 시스템에 대해 읽기/쓰기 작업을 하면서도 원본 파일 시스템을 보호하는 데 유용하다.
이러한 특수 목적 파일 시스템들은 리눅스 시스템의 다양한 기능을 제공하고, 시스템 관리자가 효율적으로 작업할 수 있도록 돕는다.
Swap Space
디스크의 모든 파티션에 파일 시스템이 있는 것은 아니다. 디스크 공간을 사용하여 RAM을 확장할 수 있다. 실제 메모리가 부족할 경우, 리눅스 가상 메모리 시스템은 메모리의 일부를 디스크 저장소로 자동으로 이동시키는 방식으로 동작한다. 이를 스왑(swap)이라고 하며, 대기 중인 프로그램의 일부가 디스크로 옮겨지고, 디스크에 있던 활성 프로그램의 일부가 메모리로 불러와진다. 메모리 페이지를 저장하는 디스크 공간을 스왑 공간(swap space) 또는 간단히 스왑이라고 한다.
리눅스 시스템에서 free 명령어의 출력은 현재 스왑 사용량을 킬로바이트 단위로 보여준다.
$ free
total used free
--snip--
Swap: 514072 189804 324268디스크 파티션을 스왑으로 사용하려면 다음 단계를 따르면 된다.
- 파티션이 비어 있는지 확인하십시오.
mkswap dev명령어를 실행한다. 여기서dev는 스왑 공간으로 사용할 파티션의 장치입니다. 이 명령은 파티션에 스왑 서명을 추가하여 이를 스왑 공간으로 표시합니다.swapon dev명령어를 실행하여 커널에 스왑 공간을 등록합니다.
스왑 파티션을 생성한 후에는 /etc/fstab 파일에 새로운 스왑 항목을 추가하여 시스템이 부팅 시 자동으로 스왑 공간을 사용할 수 있도록 합니다. 예를 들어, /dev/sda5를 스왑 파티션으로 사용하려면 다음과 같은 항목을 추가한다.
/dev/sda5 none swap sw 0 0swap에는 UUID가 사용되므로, 많은 시스템에서는 장치 이름 대신 UUID를 사용한다. 참고로 0 두 개는 swap partition에 관해서 체크 및 백업 옵션을 설정하는 부분이다.
- 첫번째 0은 시스템 부팅 시
fsck명령을 실행할 지 여부로 0은 검사를 하지 않겠다는 것이다. - 두번째 0은
dump명령어로 백업할 파일 시스템의 우선 순위를 말한다. 0은 백업하지 않겠다는 것이고 1이 가장 우선순위가 높다.
위의 예시는 swap partition에 대해서 fsck 검사와 백업을 하지 않겠다는 의미이다.
디스크 파티션을 나누어 스왑 파티션을 만들 수 없는 상황에서는 일반 파일을 스왑 공간으로 사용할 수 있다. 이를 통해 디스크 파티션을 다시 나누지 않고도 스왑 공간을 확보할 수 있다. 이 방법을 사용해도 성능에 큰 문제는 발생하지 않는다.
스왑 파일을 생성하고 이를 스왑 공간에 추가하는 방법은 다음과 같다.
- 빈 file 생성
dd if=/dev/zero of=swap_file bs=1024k count=num_mb- file을 swap 공간으로 초기화
mkswap swap_file- file을 swap 공간으로 추가
swapon swap_file여기서swap_file은 새로 만든 swap 파일의 이름이고, num_mb는 원하는 스왑 파일의 크기이다.
swap 파티션이나 파일을 커널의 활성 스왑 풀에서 제거하려면 swapoff 명령어를 사용합니다. 이 작업을 수행하려면 시스템에 남아 있는 충분한 실제 메모리(스왑 포함)가 있어야 하며, 활성 페이지가 제거된 스왑 풀을 수용할 수 있어야 한다.
일반적으로 스왑 공간을 아예 설정하지 않는 것은 위험할 수 있다. 실제 메모리와 스왑 공간이 모두 부족해지면, 리눅스 커널은 Out-Of-Memory (OOM) killer를 호출하여 프로세스를 종료시켜 메모리를 확보하려고 한다. 이를 방지하려면 시스템에 적절한 스왑 공간을 확보해 두는 것이 좋다. 그러나 고성능 서버에서는 스왑 공간을 아예 사용하지 않도록 설정하는 경우도 있으며, 이러한 서버는 고급 모니터링, 중복성, 부하 분산 시스템을 통해 성능 저하를 방지한다.
그러나 swap만이 메모리 부족 현상을 해결하는 만능 열쇠는 아니다. 너무 많은 active 프로세스가 메모리를 요구하면 스왑 공간을 자주 사용하게 되고, 이 경우 디스크 I/O가 느려져 심각한 성능 문제를 겪을 수 있다. 이 문제를 해결하려면 메모리를 추가하거나, 일부 프로세스를 종료하거나, 다른 방법을 강구해야 한다.
