클라우드 쪽을 공부하다보면 느끼는 것 중 하나는 aws, gcp, azure 같은 기술들보다 linux같은 기본기를 공부해야겠다는 생각이 계속든다. 엄청 어려운 것 같은 플랫폼 엔지니어링 기술들도 내부를 파고들면, 그냥 linux command를 go에서 실행하고 있거나, shell로 linux command로 호출하고 있는게 대부분이다. 그래서 어렴풋이 linux를 공부해놓지 말고 이 참에 좀 다시 정리할 겸 공부를 해보려고 한다.
해외에 유명한 linux 저서가 있다. https://www.amazon.com/How-Linux-Works-Brian-Ward/dp/1718500408
'How linux works'라는 책인데, 매우 쉽게 쓰여져있고 넓은 내용을 다룬다. 물론 한 파트마다의 깊은 내용을 다룬다고 할 수는 없다. 깊은 내용은 업무를 하면서, 관련된 파트를 깊게 배우면 된다고 생각한다.
한국에도 번역본이 있다.
https://product.kyobobook.co.kr/detail/S000001890789
이름도 투박하게 '리눅스 작동법'이라고 하여 열심히 번역을 해주셨다. 현재 'How linux works'는 3판인 것에 비해, '리눅스 작동법'은 2판이다. 물론 2판과 3판이 엄청 크게 달라지진 않았다. 좀 시간이 어느정도 경과되었지만, 추가된 내용들은 클라우드 쪽의 linux 내용 뿐이고, 어렵고 투박한 표현들을 잘라내거나 수정했다는 정도이다.
그래도 3판을 읽으면서 한국어로 번역해보기로 했다. 영어를 유창하게 잘 못하니 한국어로 번역한 내용에서 번역이 너무 괴랄하거나 이상할 수 있으니 알아서 필터링해서 읽어주길 바란다.
The Big Pircture
linux는 굉장히 방대하고, 어려우며, 복잡하다. 이를 전부 이해하는 것은 많은 시간이 소요됨으로, linux를 가장 쉽게 이해하고 접근할 수 있는 방법은 바로 '추상화'이다. 가령 우리가 차를 운전할 때 이 차가 어떻게 구동되고 어떤 나사를 쓰며, 누가 이 부품들을 분해 결합했는 지 알지 못한다. 그저 사용방법과 어떻게 움직이는 지에 대한 추상적인 부분만 알 뿐이다.
linux 역시도 마찬가지이고, 나아가 컴퓨터 사이언스도 마찬가지이다. 추상화는 개념의 이해를 도와주고 더 큰 틀에서 해당 분야를 이해할 수 있는 도움을 주는 것이다.
1.1 Linux system의 추상화 수준 및 계층
추상화를 사용하여 linux system을 component들로 나눌 수 있다. 이 component들을 layer또는 level로 분류하거나 배열하여 linux system자체를 추상적으로 이해할 수 있을 것이다.
linux system은 3가지 주요한 level, layer가 있다. 아래의 그림을 보도록 하자.
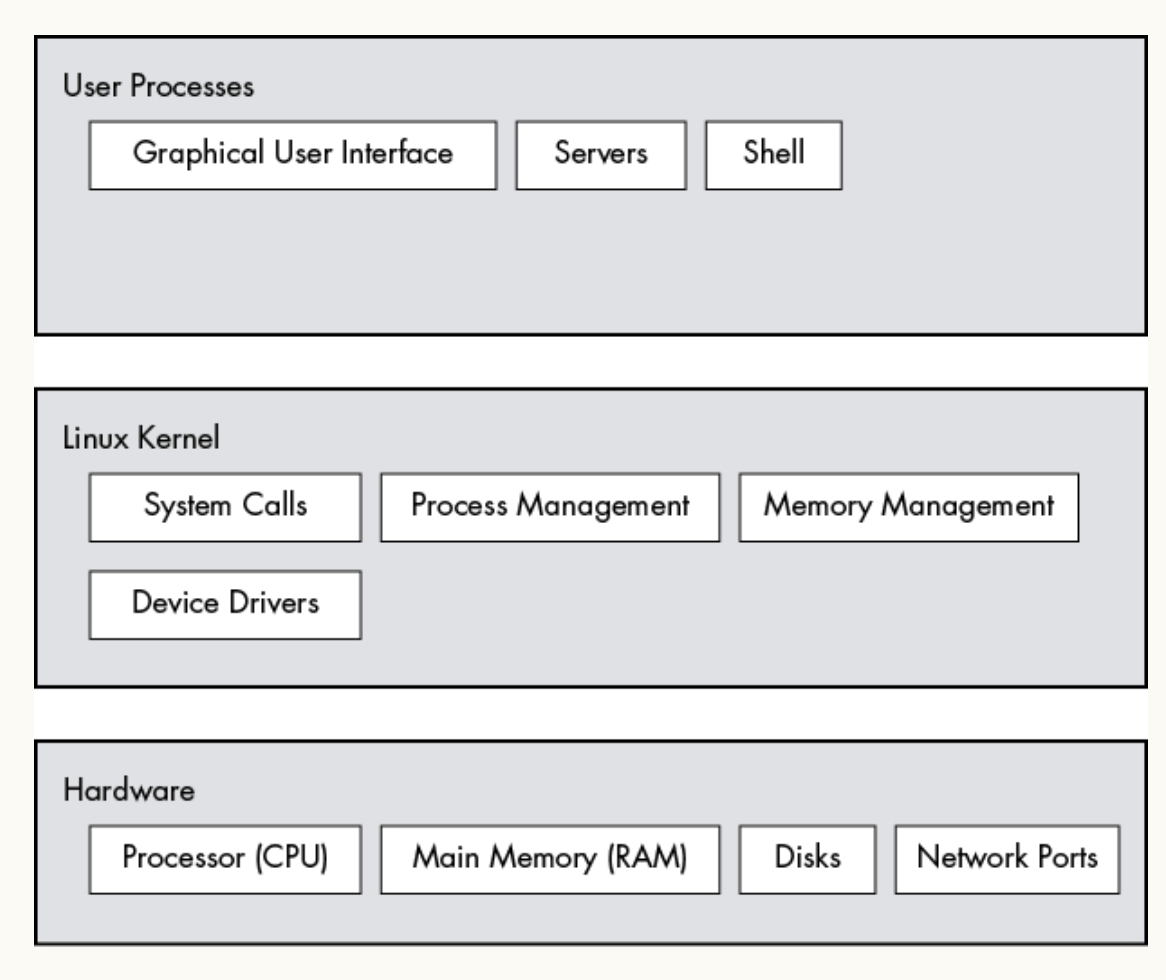
가장 아래에 base로 자리잡고 있는 것은 hardware이다. hardware는 데이터를 기록하는 memory와 memory를 이용하여 연산을 수행하는 cpu, 네트워크나 각종 컴퓨터 인터페이스를 동작해주는 device 등이 있다.
다음은 kernel인데 kernel은 운영체제의 핵심으로, 메모리에 상주해 있는 software이다. 이는 CPU에게 다음 동작으로 어디를 볼지에 대한 기능을 제공해주고, 메모리와 같은 hardware들을 관리해주고 hardware와 program 사이의 주요한 interface를 제공해준다.
processes는 kernel에 의해 관리되는 program들로 system의 상위 레벨에 있어 user space라고도 불린다. 더 정확히는 user process라고 한다. 가령 모든 web server들은 user process들로 동작한다.
kernel과 user processes는 둘 다 software이지만 아주 큰 차이를 가지고 있다. kernel은 kernel mode로 동작하는 반면 user processes는 user mode로 동작하기 때문이다. kernel mode에 동작하는 프로그램들은 processor와 memory에 제한없이 접근할 수 있다. 이는 매우 강력한 권리인데, 잘못 사용하면 시스템 전체를 망치기 때문이다. memory에는 kernel만이 접근할 수 있는 영역까지도 있는데, 이 영역을 kernel space라고 한다.
반면에 user mode는 memory와 CPU에 대한 접근이 제한되어 일부 안전하게 사용할 수 있는 기능들을 제공받는다. user space는 main memory에서 user process들이 접근 가능한 공간을 말한다. 만약 user mode에 있는 process에서 에러가 발생하고 크래쉬가 발생하도 이 결과는 시스템 전체에 미치지 않고 kernel에 의해 정리된다.
물론 user mode에 있는 process들도 권한을 받아 db data들을 모두 삭제한다는 등, 심각한 에러들을 발생시킬 수 있지만, kernel mode에 있는 kernel process들은 그냥 컴퓨터 자체를 아작 낼 수도 있다.
참고로 user mode, kernel mode는 process를 실행하는 CPU와 관련된 일이다. 만약 CPU가 일반적인 process의 연산을 처리한다면 user mode이고, CPU가 process에 대한 관리나 I/O 처리, system call 처리와 같은 kernel관련 일이 필요할 때는 kernel mode롤 변환하여 kernel process를 실행한다고 생각하면 된다.
1.2 Hardware: Main memory에 대한 이해
main memory(RAM)은 0과 1로 이루어진 큰 저장 공간이다. 이 공간 안에서 kernel process와 user process들이 적재되어 동작하게 되는 것이다. 따라서, process는 하나의 큰 bit덩어리에 불과하다. CPU는 그저 main memory의 operator로 CPU 명령어를 읽어서 data를 main memory로 부터 쓰거나 읽는 것을 반복할 뿐이다.
computer system에서의 state는 그저 bit의 정렬 순서를 말할 뿐이다. 가령, main memory에서 bit가 0110이면 0001과 다른 state인 것이다.
그러나 이러한 bit 덩어리로 무언가를 표현하기 보다는 state로 process들을 설명해주는 것이다. 가령, '현재는 process가 block 상태에 있다'라고 말하면 되는 것이다. 즉, bit 덩어리를 추상적인 state로 표현하는 것이다.
1.3 The Kernel
Kernel이 하는 일들의 모든 것들은 거의 main memory와 관련이 깊다. kernel의 일 중 하나는 memory를 다수의 하위 구역으로 나누는 것이다. 또한, kernel은 이러한 메모리의 하위 구역들에 대한 특정 state를 동시에 유지해야한다. 각 process들은 memory에 자신들에 대한 점유를 가지며, kernel은 각 process가 그들의 memory 점유를 보장해주어야 한다.
kernel은 4가지의 일반적인 system 구역들에서의 일들을 책임진다.
Processes: kernel은 어떤 process들이 CPU를 사용할 지 결정하는 책임을 가진다.Memory: kernel은 모든 memory들을 기록하고 있어야한다. 가령, 어떤 부분들이 특정 process에 허용되었는 지, 어떤 부분들이 process들끼리 공유될 수 있는 지, 어떤 부분들이 free한 상태인지Device drivers: kernel은 hardware(가령 Disk)와 process 사이의 인터페이스로 동작한다. 대게 hardware를 동작시키는 일이 kernel의 일이다.System calls and support: process들은 system call을 사용하여 kernel과 통신한다.
1.3.1 Process 관리
process management는 process의 생애주기인 시작, 멈춤, 재시작, 스케줄링, 종료를 설명한다.
오늘 날의 modern operating system에서 수 많은 process들은 동시에 동작한다. 가령, 웹브라우저를 보면서 엑셀을 만질 수 있는 것을 생각해보면 된다. 그러나, 이러한 것들이 겉으로 보이는 것과 다를 수 있다. 이러한 application들이 동작하는 process들은 일반적으로 정확히 동시에 동작하지 않는다.
one-core CPU를 생각해보자, 수많은 process들이 CPU를 사용하고 싶어하지만, 오직 하나의 process만이 CPU를 사용할 수 있다. 하나의 process가 아주 잠시 CPU를 사용하고, 다음 process에 CPU를 넘겨준다음 동작을 잠시 멈춘다. 다음 CPU도 잠시 동안 CPU를 사용하고 다음 process에 CPU를 넘긴다. 이렇게 process가 현재 사용하고 있던 CPU를 다른 process에 넘기고 다음 CPU 할당을 기다리기 위해 잠시 멈추는 것을 context switch라고 한다.
CPU를 잠시 쓸 수 있는 잠시 동안의 시간을 time slice라고 한다. 이 아주 작은 time slice만 있어도 process들은 상당한 양의 연산들을 수행할 수 있다. 이러한 time slice는 매우 작은 값이기 때문에, 사용자들은 이를 인지할 수 없어 마치 여러 개의 process들이 동시에 동작하는 것처럼 느끼는 것이다. 이러한 것을 multitasking이라고 하는 것이다.
kernel은 context switching을 담당한다. 이러한 동작을 이해하기 위해서 user mode에서 동작하는 process가 time slice를 다 썼을 상황을 생각해보자.
-
CPU는 time slice시간에 맞게 현재 CPU를 사용중인 process에 interrupt를 걸고, kernel mode로 전환한다. 또한, kernel에 제어권을 넘겨준다.
-
kernel은 현재의 CPU와 memory의 상태를 기록한다. 이러한 CPU, memory 상태는 방금 전에 interrupt된 process를 다시 재시작(resuming)시키기 위해서 필요하다.
-
kernel은 이전 time slice에서 발생했을 수 있는 모든 작업들을 수행한다. 가령, I/O 작업이나, I/O 작업으로 얻은 data를 모으는 일들이 있다.
-
kernel은 이제 다른 process를 동작시킨다. kernel은
ready상태에 있는 process들을 분석하여 하나를 선택한다. -
kernel은 CPU를 할당받을 process를 위한 memory 공간을 준비하고, CPU를 준비한다.
-
kernel은 CPU에게 새로운 process의 time slice가 얼마나 오래 지속될 지 알려준다.
-
kernel은 CPU를 user mode로 돌려주고 CPU에게 process에 대한 제어권을 넘겨준다.
context switch의 동작을 보면 언제 kernel이 동작하는 지 알 수 있다. kernel은 process time slice사이에서 context switch 중에 동작한다는 것이다.
현재의 컴퓨터들은 multi-CPU를 사용하여 동시에 process들을 여러개 동작 시킬 수 있다. 굳이 위에서 처럼 context switch를 짧은 time slice동안 발생시킬 필요도 많이 없어졌지만, 성능과 CPU자원 효율을 위해서 time slice만큼 process를 수행하고 context switch를 동작하는 것이 훨씬 좋다. 즉, 어찌됐거나 현대에 들어서도 kernel이 위에서와 같은 동작으로 동작한다는 것이다.
1.3.2 Memory 관리
kernel은 context switch 동안에 memory를 관리해야한다. 이는 굉장히 복잡한 작업인데, 다음의 조건들을 만족해야한다.
- kernel은 kernel 자신의 private한 공간을 memory에 가져야하며 이 공간은 user process가 접근하지 못해야한다.
- 각 user process는 자신의 memory 공간을 필요로 한다.
- user process들은 자신의 공간 이외에 다른 user process의 private한 공간을 침범 할 수 없다.
- user process는 memory 공유가 가능하다.
- user process의 일부 memory 공간은 read-only이다.
- system은 보조로 disk를 사용하여 실제 memory공간 보다 더 큰 memory공간을 사용할 수 있다.
modern CPU는 `memory menagement unit(MMU)를 포함하여 'virtual memory'라 불리는 memory 접근 schema를 제공해준다. virtual memory를 사용할 때, process는 hardware안의 물리적 공간을 이용하여 memory에 직접 접근하는 것이 아니다. process가 memory의 일부 공간에 접근할 때, MMU가 접근을 가로채고 memory address map을 사용하여 process 입장에서 접근하려던 memory 공간을 실제 memory 공간으로 변경해준다. kernel은 계속 이 memory address map을 초기화하고, 유지하고, 변경해야한다. 가령, context switch가 발생하면 kernel은 CPU 할당에서 나가는 process에서 CPU할당을 받은 process로 memroy address map을 변경해야한다.
이러한 memory address map의 구현체를 page table이라고 한다.
1.3.3 Device Drivers와 관리
device는 오직 kernel mode에서만 접근이 가능한데, user process에 의해서 system이 망가지는 것을 막기위해서이다. 문제는 이러한 device들이 같은 기능을 제공하는 목적으로 만들어져도, 서로 다른 interface를 가지고 있기 때문에 사용자가 이를 고려하여 코드를 만들기 어렵다. 따라서, kernel은 software 개발자에게 일관된 device 제어 interface를 제공해주도록 한다.
이렇듯 kernel은 user process가 system에 영향을 미치지 않을 정도로 안전하게 device를 제어할 수 있도록 해주며, 일관된 interface를 제공해주어 사용의 편의성을 증대 시켜준다.
1.3.4 System call과 support
user process에서 kernel에 할 수 있는 몇 가지 종류의 feature들이 있는데, 가령 system calls(syscalls)가 있다. 이는 user process에서 할 수 없는 일을 kernel에서 수행하는 것인데, 가령 file을 열고, 읽고, 쓰고하는 작업들은 system call들과 관련되어 있다.
system call들 중에서 가장 중요한 것 중 두 개는 fork()와 exec()이다. 이 둘은 process가 어떻게 시작하는 지 이해하는 데 매우 중요하다.
-
fork(): process가fork()system call을 호출하면 kernel은 현재 process에 거의 비슷한 자식 process를 생성한다. -
exec(): process가exec(program)system call을 호출하면 kernel은program을 적재하고 시작하여 현재 process를 대체한다.
linux system에서 가장 처음에 시작되는 init process이외의 모든 user process는 모두 fork()로 시작된다. 즉, 모든 user process가 init process의 child process라는 것이다. 그리고 exec()을 호출하여 현재의 process가 아니라 새로운 program을 구동시킬 수 있다.

가령, ls 명령어를 입력하여 directory의 내용을 확인해보도록 하자. ls를 terminal에 치게되면 shell은 fork()를 통해서 현재의 복사본 child process를 만들게되고, child process shell에서 exec(ls)를 호출한다. ls가 종료된 이후로 다시 parent shell로 돌아와서 prompt에 다음 명령어를 기다리게 되는 것이다.
한가지 오해하지 말아야할 것 중 하나는 fork()와 exec()은 c언어에서 쓰이는 syscall이다. 다른 프로그래밍 언어에서는 호출 방식이 다를 수 있다. 단, 대부분 내부를 까보면 c언어의 호출을 wrapping한 것들이 많다.
kernel은 또한 user process에게 pseudodevices라는 것을 지원해주는데, pseudodevices는 user process에게는 하드웨어 device처럼 보이지만 실제로는 완전히 software인 것들을 말한다. pseudodevices는 완전히 software이기 때문에 꼭 kernel을 통해서 user process가 접근할 필요는 사실 없지만, 안전성을 보장하여 구현하기 위해서는 system call을 통해서만 접근할 수 있게 한 것이다.
1.4 User space
main memory에는 kernel이 user process들을 위해 할당한 공간인 user space가 있다고 했다. process는 memory에 저장된 하나의 state(상태)이므로, user space는 동작중인 모든 process들의 memory 공간을 말하는 것과 같다. 간혹 user space를 userland라고도 하니까 헷갈리지 말자.
대부분의 linux system action들은 user space에서 발생한다. 비록 kernel 관점에서는 모든 process가 본질적으로 동일하지만, process들은 user들을 위해서 서로 다른 일들을 수행한다.
user process들도 서로 간의 관계가 있고, level이 존재할 수 있다. 다음은 user process들끼리의 관계와 interaction들을 보여준다.
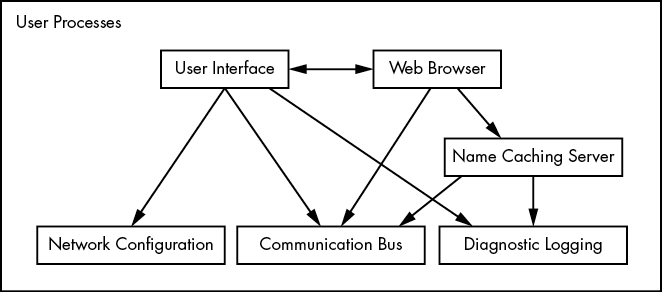
사용자와 가까운 user process들은 주로 user의 interaction을 맡고 있으며, 아래의 user process들은 kernel이나 system 하부에 가까운 일들을 처리하고 있다.
물론, 이와 같은 user process들의 배치는 사실 고정된 것이 없다. 그저 이들 간에도 개발자가 어떻게 설계하냐에 따른 level이 있다는 것만 알도록 하자.
1.5 User
linux kernel은 unix user 개념을 지원한다. user는 process를 실행하고 file을 소유할 수 있는 entity이다. user는 username과 관련이 깊은데, system은 billyjoe라는 user를 가지고 있을 수 있다. 그러나 kernel은 이러한 username들을 관리하지 않으며 대신, user들을 user ID라는 숫자 식별자들을 사용하여 식별한다.
user들은 주로 permission과 boundaries를 지원하기 위해 존재한다. 모든 user-space process는 user owner를 가지며, process들은 owner는 실행한 주체에 의해 결정된다. process를 실행한 user는 자신의 process 동작을 수정, 종료시킬 수 있다. 그러나 다른 user의 process는 관여할 수가 없다. 추가적으로 user들은 자신들만의 file을 가질 수 있고, 이러한 file들 중 일부를 다른 user들과 공유할 지 말지를 결정할 수 있다.
하나의 Linux system에서 여러 user들을 가질 수 있다. 그런데, 이들 중 대장이 있는데 그게 바로 root이다. root는 자신이 실행시킨 process 뿐만 아니라 다른 process들도 수정, 삭제, 변경시킬 수 있는 힘이 있다. 또한, 다른 user의 file에도 접근이 가능하다. 이러한 이유 때문에 root는 superuser라고 불린다. 주로 superuser는 해당 linux system의 관리자이다.
user들끼리 group을 이룰 수도 있는데, group을 만드는 주된 이유는 groupd의 맴버인 user에게 file권한을 주기 위함이다.
