GO언어를 위한 SOLID 디자인 principle
SOLID는 유명한 다섯가지 객체지향 소프트웨어 디자인 원칙의 약자를 모은 것이다.
- 단일 책임 원칙(Single Responsibility Principle, SRP)
- 개방/폐쇄 원칙(Open/Closed Principle, OCP)
- 리스코프 치환 원칙(Liskov Substitution Principle, LSP)
- 인터페이스 분리 원칙(Interface Segregation Principle, ISP)
- 의존성 역전 원칙(Dependency Inversion Principle, DIP)
단일 책임 원칙(SRP)
클래스는 하나의 기능만을 가지며 클래스를 변경해야 하는 이유는 오직 하나뿐이어야 한다.
GO언어는 클래스를 갖고 있지 않지만, 클래스는 객체(구조체, 함수, 인터페이스, 패키지)로 바꿔보면 이 원칙을 적용할 수 있다.
오직 한 가지 기능만을 갖도록 객체를 디자인하는 것은 추상화 관점에서 매우 적합하지만, 더 많은 코드를 추가해야 한다는 문제가 있다. 물론 그렇다고해서 복잡도가 증가하는 것은 아니다. 실제로 이러한 원칙을 적용하는 것은 복잡도를 상당히 줄여준다. 각 코드는 작은 단위로 분리되므로 이해하기 쉽고, 테스트가 용이해진다. 이것이 바로 단일 책임 원칙이 가져다주는 첫 번째 장점이다
SRP는 코드를 더 작고 간결한 조각으로 분해해 복잡성을 줄여준다.
'단일 책임 원칙'이라는 이름에서 보여지는 것처럼 책임(기능)에 관한 것이라고 가정하는 편이 무난해 보이지만, 사실 앞서 설명한 모든 내용은 '변경'에 관한 것이다. 다음의 예제를 살펴보자.
type Calculator struct {
data map[string]float64
}
func (c *Calculator) Calculate(path string) error {
return nil
}
func (c *Calculator) Output(writer io.Writer) {
for path, result := range c.data {
fmt.Fprintf(writer, "%s -> %.1f\n", path, result)
}
}위 코드는 SRP를 준수하고 있지 않고있다. 결과를 csv 파일 형식으로 써주는 코드를 만든다고 하자.
type Calculator struct {
data map[string]float64
}
func (c *Calculator) Calculate(path string) error {
return nil
}
func (c *Calculator) Output(writer io.Writer) {
for path, result := range c.data {
fmt.Fprintf(writer, "%s -> %.1f\n", path, result)
}
}
func (c *Calculator) OutputCSV(writer io.Writer) {
for path, result := range c.data {
fmt.Fprintf(writer, "%s,%.1f\n", path, result)
}
}다음과 같이 OutputCSV 메서드를 하나 더 만들어야 한다. 이는 구조체에 많은 책임이 부여된 것이며, 그 결과로 인해 어플리케이션 복잡도가 증가한 것이다. 현재는 별로 큰 영향을 미칠 것 같아보이진 않을 것 같지만 구조체가 더 커지고 복잡해짐에 따라 변경 사항이 깔끔하게 적용되지 않을 것이다.
책임을 Calculate와 Output으로 세분화하려면 더 많은 Output 메서드를 추가하기 위해 새로운 구조체를 정의해야 한다. 또한 기본 출력 형식이 마음에 들지 않을 경우에는 다른 부분과 별도로 구현하도록 변경할 수 있다.
- calculator.go
type Calculator struct {
data map[string]float64
}
func (c *Calculator) Calculate(path string) error {
return nil
}
func (c *Calculator) getData() map[string]float64 {
return nil
}- printer.go
type Printer interface {
Output(data map[string]float64)
}
type DefaultPrinter struct {
Writer io.Writer
}
func (d *DefaultPrinter) Output(data map[string]float64) {
for path, result := range data {
fmt.Fprintf(d.Writer, "%s -> %.1f\n", path, result)
}
}
type CSVPrinter struct {
Writer io.Writer
}
func (c *CSVPrinter) OutputCSV(data map[string]float64) {
for path, result := range data {
fmt.Fprintf(c.Writer, "%s,%.1f\n", path, result)
}
}이렇게 코드를 나누게 되면 코드의 구현량은 훨씬 더 많아졌지만, 이들을 분리할 수 있게되었다. 즉 Calculator 구조체는 더 이상 Output 메서드와 관련이 없어진다는 것이다. 또한 Output메서드는 동일한 형식을 갖는 모든 데이터에 사용할 수 있다. 이것이 바로 SRP가 가져다주는 두번째 장점이다.
SRP는 코드의 재사용 가능성을 높여준다.
또한, 이들 간의 의존성을 분리하였으므로 이들의 입출력 테스트가 훨씬 더 간단해진다. 이것이 SRP가 주는 세 번째 장점이다.
SRP는 좀 더 쉽게 테스트를 작성하고 유지 보수 할 수 있게 해준다.
SRP는 또한 코드의 가독을 향상시켜주는 좋은 방법 중 하나다.
func loadUserHandler(res http.ResponseWriter, req *http.Request) {
err := req.ParseForm()
if err != nil {
res.WriteHeader(http.StatusInternalServerError)
return
}
userID, err := strconv.ParseInt(req.Form.Get("UserID"), 10, 64)
if err != nil {
res.WriteHeader(http.StatusPreconditionFailed)
return
}
row := DB.QueryRow("SELECT * FROM Users WHERE ID = ?", userID)
person := &Person{}
err = row.Scan(&person.ID, &person.Name, &person.Phone)
if err != nil {
res.WriteHeader(http.StatusInternalServerError)
return
}
encoder := json.NewEncoder(res)
encoder.Encode(person)
}다음의 코드를 좀 더 짧게 만들면 다음과 같다.
func loadUserHandler(res http.ResponseWriter, req *http.Request) {
userID, err := extractIDFromRequest(req)
if err != nil {
res.WriteHeader(http.StatusPreconditionFailed)
return
}
person, err := loadPersonByID(userID)
if err != nil {
res.WriteHeader(http.StatusInternalServerError)
return
}
outputPerson(res, person)
}함수 레벨에서 SRP를 적용해 함수의 코드를 줄이고 가독성을 향상시켰다. 함수에 적용된 단일 책임 원칙은 이제 다른 함수에 대한 호출을 조정한다.
DI를 코드에 적용할 떄는 일반적으로 의존성 객체를 함수의 매개변수로 받은 뒤 사용한다. 코드에 삽입된 의존성이 많은 함수가 있는 경우는 해당 메서드가 너무 많은 역할을 수행하고 있다는 것을 의미한다. 또한, SRP를 적용하면 객체에 대한 디자인 정보를 제공할 수 있다. 이를 통해 DI를 언제, 어디서 사용할 지 파악하는 데 도움이 된다.
SRP는 객체를 변경하는 이유를 식별하는 데 도움을 준다. 객체를 변경해야 하는 이유가 하나 이상일 경우, 그 객체는 하나 이상의 책임(기능)을 갖고 있는 것이다. 이러한 책임을 분리하면 더 나은 추상화를 구현할 수 있다.
개방 폐쇄 원칙(OCP)
소프트웨어 개체(클래스, 모듈, 함수 등)은 확장에 대해서는 열려있어야 하고, 수정에 대해서는 닫혀있어야 한다.
개방(open), 폐쇄(closed)라는 용어는 약간의 설명이 필요하다.
개방은 새로운 동작과 기능을 추가해서 코드를 확장하거나 조정하는 것을 의미한다. 폐쇄는 버그 또는 다른 종류의 회귀를 초래할 수 있는 기존 코드의 변경을 피해야 하는 것을 의미한다.
이 두가지 특징은 서로 모순되는 것처럼 보이지만, 흩어져 있는 퍼즐 조각들과 같다. 개방을 이야기할 때는 소프트웨어의 디자인이나 구조를 언급한다. 이러한 관점에서 볼 때, 개방성은 새로운 패키지, 새로운 인터페이스, 또는 기존의 인터페이스에 새로운 구현을 쉽게 추가할 수 있는 것을 의미한다.
폐쇄를 이야기할 때는 보통 기존 코드를 언급하고, 특히 다른 사람들이 사용하는 API에 대한 변경 사항을 최소화하는 것을 말한다. 이는 OCP가 가져다주는 첫 번째 장점이다.
OCP는 추가 및 확장에 대한 위험을 줄이는 데 도움을 준다.
OCP는 일종의 위험 완화 전략으로 생각할 수 있다. 기존 코드에 대한 변경은 항상 위험이 따르고, 해당 코드를 사용하는 부분을 변경해야 한다. 코드를 변경할 때 단위 테스트를 통해 이러한 위험으로부터 보호할 수 있지만 단위 테스트가 잘못 수행될 수도 있고 검증을 위해 생각할 수 있는 테스트 시나리오는 상당히 제한적이다. 이처럼 단위 테스트는 모든 것을 커버할 수 없다.
다음은 OCP 원칙을 준수하지 않는 예제 코드이다.
func BuildOutput(res http.ResponseWriter, format string, person Person) {
var err error
switch format {
case "csv":
err = outputCSV(res, person)
case "json":
err = outputJSON(res, person)
}
if err != nil {
res.WriteHeader(http.StatusInternalServerError)
return
}
res.WriteHeader(http.StatusOK)
}만약, 요구사항이 변경되고 출력 형식(csv, json)이 추가하거나 제거되면 어떻게 해야할까?? 다음의 수정이 필요하다.
- switch 문에 다른 조건의 case를 추가한다.
- 다른 형식으로 출력하는 함수를 작성한다.
- 메서드의 호출자(caller)에서 새로운 형식을 사용하도록 업데이트한다.
- 새로운 형식에 일치하는 테스트 시나리오 세트를 추가한다.
작고 간단한 변경으로 시작된 것이 실제 의도한 것보다 더 힘들고 위험한 것으로 인식되기 시작했다.
추상화를 통해 입력 매개변수 format과 switch문을 다음 코드와 같이 개선해보자.
func BuildOutput(res http.ResponseWriter, formatter PersonFormatter, person Person) {
err := formatter.Format(res, person)
if err != nil {
res.WriteHeader(http.StatusInternalServerError)
return
}
res.WriteHeader(http.StatusOK)
}이번에는 얼마나 많은 변경이 필요할까??
PersonFormatter인터페이스에 새로운 형식에 대한 구현을 추가해야 한다.- 메서드 호출자에서 새로운 형식을 사용하도록 업데이트 한다.
- 새롭게 추가된
PersonFormatter인터페이스 구현에 대한 테스트 시나리오를 작성한다.
상황은 전보다도 훨씬 좋다졌다. switch 문만 없어도 매우 많이 개선된 것이다. 주된 함수는 전혀 변경하지 않았다. 이것이 바로 OCP의 두 번째 장점이다.
OCP는 기능을 추가하거나 제거할 떄 필요한 변경 사항을 최소화하는 데 도움이 된다.
또한 새롭게 formatter를 추가한 새로운 구조에서 버그가 발생할 경우에는 새롭게 추가된 코드 부분만 확인하면 된다. 이것이 OCP의 세번째 장점이다.
OCP는 버그가 발생할 수 있는 범위를 새롭게 추가된 코드와 해당 코드를 사용하는 부분으로 좁혀준다.
DI를 적용하지 않은 다른 예제를 살펴보자.
func GetUserHandlerV1(res http.ResponseWriter, req *http.Request){
err := req.ParseForm()
if err != nil {
res.WriteHeader(http.StatusInternalServerError)
return
}
userID, err := strconv.ParseInt(req.Form.Get("UserID"), 10, 64)
if err != nil {
res.WriteHeader(http.StatusPreconditionFailed)
return
}
user := loadUser(userID)
outputUser(res, user)
}
func DeleteUserHandlerV1(res http.ResponseWriter, req *http.Request){
err := req.ParseForm()
if err != nil {
res.WriteHeader(http.StatusInternalServerError)
return
}
userID, err := strconv.ParseInt(req.Form.Get("UserID"), 10, 64)
if err != nil {
res.WriteHeader(http.StatusPreconditionFailed)
return
}
deleteUser(userID)
}두 handler는 Form에서 데이터(userID)를 가져와서 ParseInt함수를 통해 정수로 변환한다. 시간이 지나 validation을 위해 UserID가 양수인지 확인하는 단계를 추가한다고 하자. 그렇다면 두 함수 모두 검증하는 코드를 넣어줄 수 밖에 없다. 이를 해결하기 위해서는 반복되는 로직을 하나로 통합하고, 이곳에 새로운 validation logic을 추가하는 것이다. OCP원칙이 적용된 예제 코드는 다음과 같다.
func GetUserHandlerV1(res http.ResponseWriter, req *http.Request) {
err := req.ParseForm()
if err != nil {
res.WriteHeader(http.StatusInternalServerError)
return
}
userID, err := extractUserID(req.Form)
if err != nil {
res.WriteHeader(http.StatusPreconditionFailed)
return
}
user := loadUser(userID)
outputUser(res, user)
}
func DeleteUserHandlerV1(res http.ResponseWriter, req *http.Request) {
err := req.ParseForm()
if err != nil {
res.WriteHeader(http.StatusInternalServerError)
return
}
userID, err := extractUserID(req.Form)
if err != nil {
res.WriteHeader(http.StatusPreconditionFailed)
return
}
deleteUser(userID)
}코드의 양이 줄어들지는 않았지만 가독성이 좋아졌고, UserID필드의 유효성 검사 로직이 변경될 경우도 대비할 수 있게 되었다. 위 두가지 예제에서 OCP원칙을 만족시키기 위한 핵심은 정확한 추상화를 찾는 것이다.
DI는 의존관계에 있는 리소스(함수, 구조체)를 추상화하는 코딩 방식이라고 했다. OCP를 사용하면 좀 더 깔끔하고 견고한 추상화를 구현할 수 있다.
일반적으로 OCP에 대해 논의할 때는 그 예제로 추상 클래스, 상속, 가상 함수 등 GO언어에는 없는 것들이 포함되어 있다. 그렇다면 실제로 추상 클래스란 무엇인가? 추상 클래스는 왜 사용하는 것일까??
추상 클래스는 여러 구현체 간에 공유되는 코드를 위한 장소를 제공한다. GO언에서는 composition을 통해 추상 클래스를 구현할 수 있다. GO언어에서 추상클래스를 구현하는 코드는 다음과 같다.
type rowConverter struct {
}
func (d *rowConverter) populate(in *Person, scan func(dest ...interface{}) error) error {
return scan(in.Name, in.Email)
}
type LoadPerson struct {
rowConverter
}
func (loader *LoadPerson) ByID(id int) (Person, error) {
row := loader.loadFromDB(id)
person := Person{}
err := loader.populate(&person, row.Scan)
return person, err
}
type LoadAll struct {
rowConverter
}
func (loader *LoadPerson) All() ([]Person, error) {
rows := loader.loadAllFromDB()
defer rows.Close()
output := []Person{}
for rows.Next() {
person := Person{}
err := loader.populate(&person, rows.Scan)
if err != nil {
return nil, err
}
}
return output, nil
}LoadPerson, LoadAll은 populate라는 추상 메서드(또는 추상 클래스)를 사용한다. 그럼 rowConverter를 추상 클래스로 보면 되지않을까? 생각할 수 있지만 GO는 객체지향언어가 아니다. 1대1로 대응할 필요가 없다. 사실 rowConverter은 추상 클래스보다는 오히려 구현체에 가깝다.
공유되는 로직의 일부를 추출해 rowConverter구조체로 통합했다. 그런 다음, 해당 구조체를 다른 구조체에 포함해서 변경 없이 사용할 수 있다. 이러한 과정을 통해 추상 클래스와 OCP의 목표를 달성했다. 위 예제 코드는 개방되어 있다. 폐쇄된 곳이라면 어디든지 위와 같이 코드를 삽입할 수 있다. 포함된 클래스는 해당 클래스가 다른 클래스에 포함되었다는 사실을 알 필요가 없으며, 포함하는 클래스는 포함된 클래스의 메서드를 사용할 때 내용을 알 필요가 없다.
앞부분에서 폐쇄는 변경되지 않은 것으로 정의했지만, 외부에 노출되어 있거나 다른 곳에서 사용되고 있는 API로 그 범위를 한정했다. private 맴버 변수를 포함해 내부 구현에 대한 세부 사항이 절대로 변경되지 않을 것으로 믿는 것은 좋지 않다. 가장 좋은 방법은 구현에 대한 세부 사항을 숨기는 것이고 이것이 캡슐화(encapsulation)이라고 한다.
패키지 레벨에서 캡슐화는 간단하다. 단순히 private를 만들면 된다. 가장 좋은 방법은 모든 것을 private으로 선언하고, 정말로 필요한 것들만 public으로 선언하는 것이다. 이렇게 하는 목적은 위험 요소와 불필요한 작업을 줄이는 데 있다. 만약 개발 과정에서 특정 객체를 외부에 노출시킨다면, 사용자는 해당 객체에 의존하게 된다. 해당 객체에 대한 의존성이 생길 경우, 그 객체는 폐쇄되어야 한다. 해당 코드에 대한 유지 보수를 해야하며, 어떠한 변경 사항이 발생할 경우 다른 부분에 더 큰 영향을 미칠 수도 있다. 따라서 적당한 캡슐화를 통해 패키지 내의 변경 사항을 외부에 숨겨야 한다.
객체 레벨에서 private는 다시 말해, 그 객체가 무엇을 하는 지 알 필요가 없다는 것이며, 이는 객체가 어떻게 동작하는 지를 외부에 숨기는 것을 의미한다. private 맴버변수에 직접 접근하는 것을 허용하면 객체 간의 결합도를 강하게 만들고 그로 인한 피해는 고스란히 개발자에게 돌아온다.
GO언어 타입 시스템의 가장 좋은 기능 중 하나는 어떤 타입에도 메서드를 정의할 수 있다는 것이다. 상태 검사(health check)에 응답하는 HTTP 처리기 코드를 작성한다고 가정해보자. 해당 코드를 실행할 떄 외부 요청에 대해 HTTP 상태 코드 204로 응답하는 것 외에는 아무런 동작도 하지 않을 것이다. 구현해야 할 인터페이스는 다음과 같다.
리스코프 치환 원칙(LSP)
"타입 S의 객체 o1과 타입 T의 인스턴스 o2가 있을 떄, 어떤 프로그램에서 타입 T의 객체로 P가 사용된다고 하자. S가 T의 서브타입(subtype)이라면 P에 대입된 o1이 o2로 치환된다고해도 P의 행위는 바뀌지 않는다." -바바라 리스코프
이해하지 못했다면 제정신인 것이다. 감사하게도 로버트 마틴이 이를 쉽게 요약해주었다.
"서브타입은 언제나 자신의 기반(base)타입으로 교체할 수 있어야 한다."
즉, 어떤 부모 클래스(base class)의 자식 클래스(sub class)는 부모와 교체해도 문제가 없어야 한다는 것이다. 따라서 부모 클래스의 자식 클래스들은 언제나 부모 클래스와 교체할 수 있으므로, 3단 논법으로 인해 자식클래스끼리도 서로 교체할 수 있다. 교체(치환)할 수 있다는 것은 기능적으로 동일한 기능을 해야한다는 것이 아니라, 문법적으로 문제가 없어야 한다는 것이다. 즉, 자식만이 가지고 있는 메서드가 따로 없어야 한다는 것이다. 이 사실을 깨닫고 다시 바바라 리스코프의 글을 보면 어느정도 이해가 간다. golang에서는 추상 클래스나 상속이 없지만, 컴포지션과 인터페이스가 존재한다.
LSP 원칙의 동기(motivation)은 무엇인가?? LSP는 서브타입 간에 서로 대체 가능함을 요구한다. 이를 위해 GO인터페이스를 사용할 수 있으며 이 기능은 항상 유효하다.
LSP원칙을 어긴 코드를 통해 LSP가 무엇인지 배워보도록 하자.
func GO(vehicle action) {
if sled, ok := vehicle.(*Sled); ok {
sled.pushStart()
} else {
vehicle.startEngine()
}
vehicle.drive()
}
type action interface {
drive()
startEngine()
}
type Vehicle struct {
}
func (v Vehicle) drive() {
}
func (v Vehicle) startEngine() {
}
func (v Vehicle) stopEngine() {
}
type Car struct {
Vehicle
}
type Sled struct {
Vehicle
}
func (s Sled) startEngine() {
}
func (s Sled) stopEngine() {
}
func (s Sled) pushStart() {
}Vehicle 구조체를 composition하고 있는 Car와 Sled를 보도록 하자. Sled는 Vehicle이 가지고 있는 메서드 이외에도 추가적인 메서드를 가지고 있다. 상속이 아닌 composition이지만 golang에서 LSP 관점으로 볼 떄 이들이 서로 치환되지 않는다. 즉, Vehicle과 Sled는 서로 치환되지 않고, Sled와 Car는 치환되지 않는다. LSP 원칙을 위반하고 있기 때문에 아래와 같이 인터페이스를 추가해 문제를 해결해보자.
func GO(vehicle actions) {
switch concrete := vehicle.(type) {
case poweredActions:
concrete.startEngine()
case unpoweredActions:
concrete.pushStart()
}
vehicle.drive()
}
type actions interface {
drive()
}
type poweredActions interface {
actions
startEngine()
stopEngine()
}
type unpoweredActions interface {
actions
pushStart()
}
type Vehicle struct {
}
func (v Vehicle) drive() {
}
type PoweredVehicle struct {
Vehicle
}
func (v PoweredVehicle) startEngine() {
}
func (v PoweredVehicle) stopEngine() {
}
type Car struct {
PoweredVehicle
}
type Buggy struct {
Vehicle
}
func (b Buggy) pushStart() {
}
func main() {
var in actions
in = &Car{}
GO(in)
}Car와 Buggy는 각각 PoweredVehicle과 Vehicle을 composition 관계로 가지고 있고 인터페이스는 poweredActions와 unpoweredActions로 나뉜다. 당장의 서로 부모가 다르고 구현하는 인터페이스가 다르기 때문에, 이전 보다는 괜찮은 것 같아보이지만 사실은 인터페이스 actions의 구현체인 Vehicle를 동시에 가지고 있기 때문에 이들은 리스코프 치환법칙이 성립해야 한다. 그러나 Car와 Buggy간에는 LSP가 성립되지 않는다. 즉, Car를 Buggy로 변경하면 pushStart()도 없고 불필요한 startEngine(), stopEngine() 메서드를 구현해야하는 문제가 생긴다는 것이다.
이를 해결하기 위해 다음과 같이 코드를 변경할 수 있다.
func GO(vehicle actions) {
vehicle.drive()
vehicle.start()
}
type actions interface {
drive()
start()
}
type PoweredVehicle struct {
}
func (v PoweredVehicle) startEngine() {
}
type Car struct {
PoweredVehicle
}
func (c Car) start() {
c.PoweredVehicle.startEngine()
}
func (c Car) drive() {
}
type Buggy struct {
}
func (b Buggy) start() {
}
func (b Buggy) drive() {
}이전보다 훨씬 좋아졌는데 Car와 Buggy의 기반 클래스(인터페이스)를 갖고 있기 떄문에 Car와 Buggy는 서로 치환가능해야 한다. 이들은 서로 치환가능하다. 서로 같은 메서드들을 갖고 있기 때문이다. 그러나, 이들의 기능은 다르다. Car가 PoweredVehicle를 가지고 있지만 이들은 부모-자식 클래스 관계가 아니라 composition이다. 이를 이용하여 Car만의 startEngine이라는 새로운 기능을 구현할 start안에 작동시킬 수 있었던 것이다.
이것이 LSP 원칙의 핵심을 보여준다.
LSP는 동작에 대한 정의만 할 뿐이며 상세 구현은 하지 않는다.
객체는 원하는 인터페이스를 구현할 수 있지만, 그렇다고 해서 동일한 인터페이스의 다른 구현과 동일하게 동작할 필요는 없다.
type Collection interface {
Add(item interface{})
Get(index int) interface{}
}
type CollectionImpl struct {
items []interface{}
}
func (c *CollectionImpl) Add(item interface{}) {
c.items = append(c.items, item)
}
func (c *CollectionImpl) Get(index int) interface{} {
return c.items[index]
}
type ReadOnlyCollection struct {
CollectionImpl
}
func (ro *ReadOnlyCollection) Add(item interface{}) {
}CollectionImpl, ReadOnlyCollection 둘 모두 Collection의 구현체이다. 그러나 이들의 동작은 같지 않다. 이들은 Get까지는 같지만 CollectionImpl의 Add는 데이터를 append하는 반면 ReadOnlyCollection의 Add는 아무것도 하고있지 않다. 즉 같은 인터페이스를 구현한 두 구현체가 같은 동작을 할 필요는 없는 것이다.
LSP의 원칙을 따르면 코드가 주입된 의존성에 관계없이 일관되게 동작한다. 반면에 LSP 원칙을 위반하는 것은 또한 OCP 원칙을 위반하는 것이기도 하다. 이와 같은 원칙을 위반할 경우, 상위 계층에서 하위 계층의 서비스를 시용할 때 하위 계층의 세부 구현 내용을 코드로 작성해야 하므로 의존성 주입에 의한 추상화가 깨지게 된다. 즉, 인터페이스에는 없는 하위 계층만의 추가적인 메서드가 있다면 이를 사용하기 위해서는 어쩔 수 없이 상위 계층에서 타입 단언을 사용해야하고 이는 코드의 추상성이 무너지게 된다.
go언어에서 composition을 이용해 인터페이스를 구현하면 객체지향 언어에서 사용하는 LSP원칙과 유사하다는 것을 알 수 있다. 인터페이스를 구현할 때 인터페이스를 일관되게 동작하도록 구현하는 LSP원칙을 적용함으로써 잘못된 추상화를 갖도록 하는 코드 속 나쁜 냄새를 제거할 수 있다.
인터페이스 분리 원칙(ISP)
"클라이언트는 자신이 사용하지 않는 메서드에 의존하지 않아야 한다." - 로버트 마틴
단순히 말하자면 '인터페이스는 가능한 작은 단위로 분리해야 한다'이다. ISP는 인터페이스 자체를 분리하는 것이 중점이고, 너무 많은 기능이 있는 인터페이스를 분리하여 작은 기능 단위로 만들도록 하여 클라이언트가 자신이 사용하고자하는 인터페이스의 메서드에만 의존하도록 만드는 것이다.
먼저 '뚱뚱한 인터페이스(fat interface)'가 나쁜 이유에 대해서 생각해보자. 큰 덩어리의 인터페이스는 많은 메서드를 갖고 있으므로 이해하기 어렵다. 또한 이러한 인터페이스는 구현, mock, stub 등을 사용하기 위해 많은 작업이 필요하다. 인터페이스가 변경될 경우에는 모든 사용자에게 미치는 파급 효과가 매무 크며, 이는 OCP 원칙을 위반하고 무수히 많은 변경의 분산 상황을 야기한다.
ISP는 날씬한 인터페이스를 정의하도록 요구한다.
새로운 인터페이스를 정의하지 않고, 기존 인터페이스에 기능을 추가해서 인터페이스를 점점 뚱뚱하게 만드는 것은 자연스러운 행동이다. 이로 인해 때로는 인터페이스의 구현 부분이 해당 인터페이스의 사용자와 강하게 결합되는 상황이 발생한다. 이러한 강한 결합은 인터페이스, 인터페이스의 구현 부분, 사용자의 변경에 대한 저항성을 갖도록 한다.
type Item struct {
}
type FatDBInterface interface {
BatchGetItem(IDs int) ([]Item, error)
BatchGetItemWithContext(context context.Context, items ...Item) ([]Item, error)
BatchPutItem(items ...Item) error
BatchPutItemWithContext(context context.Context, IDs int) error
DeleteItem(IDs int) error
DeleteItemWithContext(context context.Context, IDs int) error
GetItem(IDs int) (Item, error)
GetItemWithContext(context context.Context, IDs int) (Item, error)
PutItem(item Item) error
PutItemWithContext(context context.Context, item Item) error
Query(query string, args ...interface{}) ([]Item, error)
QueryWithContext(context context.Context, query string, args ...interface{}) ([]Item, error)
UpdateItem(item Item) error
UpdateItemWithContext(context context.Context, item Item) error
}
type Cache struct {
db FatDBInterface
}
func (c *Cache) Get(key string) interface{} {
//생략
_, _ = c.db.GetItem(43)
return nil
}
func (c *Cache) Set(key string, value interface{}) {
//생략
_ = c.db.PutItem(Item{})
}모든 메서드가 하나의 인터페이스에 있어서 하나의 구현체가 이를 모두 구현하는 상황이다. GetItem()과 GetItemWithContext()와 같은 메서드 쌍은 부분적으로 동일한 코드를 공유한다. 또한, 해당 코드를 사용하는 클라이언트는 GetItem()을 쓰기 시작하면 GetItemWithContext()는 점점 쓰지않게 될 것이다. 이는 클라이언트가 자신이 사용하고자하는 기능 이외에 다른 기능들을 의존하고 있는 것이다. 위 코드를 점점 더 작은 인터페이스로 분리하여 구현해보자.
type Item struct {
}
type myDB interface {
GetItem(ID int) (Item, error)
PutItem(key int, item Item) error
}
type CacheV2 struct {
db myDB
}
func (c *CacheV2) Get(key int) interface{} {
_, _ = c.db.GetItem(key)
return nil
}
func (c *CacheV2) Set(key int, value Item) {
_ = c.db.PutItem(key, value)
}이렇게 새롭게 정의된 날씬한 인터페이스(thin interface)를 사용할 경우, 함수 시그니처가 좀 더 명확해지고 유연해진다. 이것이 ISP의 두 번쨰 장점이다.
ISP는 함수의 입력을 명확히 한다.
또한, 날씬한 인터페이스는 쉽게 구현할 수 있으므로 LSP가 갖는 잠재적인 문제를 방지할 수 있다.
메서드의 입력으로 인터페이스를 사용하는 것은 인터페이스가 뚱뚱해질 우려가 있고 해당 메서드가 SRP 원칙을 위반하고 있다는 신호이다. 다음의 코드를 살펴보자.
func Encrypt(ctx context.Context, data []byte) ([]byte, error) {
stop := ctx.Done()
result := make(chan []byte, 1)
go func() {
defer close(result)
keyRaw := ctx.Value("encryption-key")
if keyRaw == nil {
panic("encryption key not found in context")
}
key := keyRaw.([]byte)
ciperText := performEncryption(key, data)
result <- ciperText
}()
select {
case ciperText := <-result:
return ciperText, nil
case <-stop:
return nil, errors.New("operation cancelled")
}
}위 예제에서는 메서드의 입력으로 context 인터페이스를 사용하고 있다. 단순히 메서드의 입력으로 인터페이스를 사용한 것이 문제가 아니라 context 인터페이스를 완전히 다른 두 가지 목적으로 사용하고 있기 때문에 문제가 되는 것이다. 첫번쨰는 짧은 작업이 필요하거나 시간 초과 시 작업을 중단시킬수 있는 컨트롤 채널이고 두번째는 값을 전달하기 위해 사용한다. 이는 ISP원칙을 위반하고 SRP원칙을 위반하기 때문에 코드가 변경에 대한 저항성을 갖게 된다.
ISP 원칙을 적용해 다음 코드와 같이 범용적인 인터페이스를 측화된 두 개의 인터페이스로 분리할 수 있다.
ype Value interface {
Value(key interface{}) interface{}
}
type Monitor interface {
Done() <-chan struct{}
}
func EncryptV2(keyValue Value, monitor Monitor, data []byte) ([]byte, error) {
stop := monitor.Done()
result := make(chan []byte, 1)
go func() {
defer close(result)
keyRaw := keyValue.Value("encryption-key")
if keyRaw == nil {
panic("encryption key not found in context")
}
key := keyRaw.([]byte)
ciperTest := performEncryption(key, data)
result <- ciperTest
}()
select {
case ciperTest := <-result:
return ciperTest, nil
case <-stop:
return nil, errors.New("operation cancelled")
}
}위 예제는 목적이 서로 다른 chan을 나누어 사용한다. 하는 result로 값을 보내는 역할을 하고 하나는 stop으로 종료하기 위한 chan이다. 이렇게 인터페이스를 분리해놓으면 좋은 장점은 코드의 concern이 명확해지고, 더이상 이 둘이 context에 의존하지 않아 기능의 확장이 가능하다는 것이다.
참고로 client는 위 코드를 사용하기위해 기존에 사용했던 context를 버리지 않아도 된다. 다음과 같이 사용할 수 있기 때문이다.
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
ctx = context.WithValue(ctx, "encryption-key", "-select-")
_,_, = EncryptV2(ctx, ctx, []byte("my data"))이것이 ISP의 마지막 장점이다.
ISP는 구체적인 구현에서 입력을 분리해 다른 부분에 영향을 주지 않고 변경할 수 있다.
정리하자면 ISP는 인터페이스를 하나로 묶지 않고 놀리적인 구별을 통해 각 인터페이스가 하나의 기능을 갖도록 하는 것이다. DI에서 이러한 역할 인터페이스(role interface)를 사용함으로써 코드상에서 입력과 구제적인 구현이 분리된다. 이러한 분리 코드의 일부분을 다른 부분과 독립적으로 변경할 수 있게 해줄 뿐 아니라, 테스트 벡터(어플리케이션이나 시스템을 테스트하기 위해 제공되는 입력값의 집합)를 쉽게 구분할 수 있도록 해준다.
테스트 벡터를 만들면 다음과 같다.
입력값 value에 대한 테스트 벡터는 다음과 같다.
- happy path(case): 유효한 값을 반환한다.
- error path(case): 빈 값을 반환한다.
입력값 monitor에 대한 테스트 벡터는 다음과 같다.
- happy path(case): 완료 신호(done signal)을 반환하지 않는다.
- error path(case): 즉시 완료 신호를 반환한다.
이전에 함수의 매개변수로 인터페이스를 받아들이고, 구조체를 반환하라는 GO언어에서의 유명한 관용 표현을 소개했다. 이 아이디어는 ISP를 결합하는 것으로부터 시작한다. 코드에서 이러한 원칙이 반영된 함수는 입력이 간결함과 동시에 출력이 명확하다. 다른 개발 언어에서는 함수의 출력을 추상화 형식으로 정의하거나 어댑터 클래스를 생성해 함수를 사용자로부터 완전히 분리할 수 있다. 그러나 GO언어의 경우에는 암시적 인터페이스(implicit interface)를 지원하기 때문에 이와 같은 작업이 필요하지 않다.
암시작 인터페이스란 구조체에서 구현해야 할 인터페이스를 정의할 필요 없이 인터페이스를 충족시키는 메서드를 정의하기만 하면 되는 언어적 특징을 말한다. 이를 보여주는 코드가 다음과 같다.
type Talker interface {
SayHello() string
}
type Dog struct{}
func (d Dog) SayHello() string {
return "Woof!"
}
func Speak() {
var talker Talker
talker = Dog{}
fmt.Println(talker.SayHello())
}c++,java와 같은 명시적 인터페이스(explicit interface)를 사용할 떄 구현 객체와 종속 객체 사이에 다소 명확한 링크가 있기 때문에 이들은 어느 정도 결합되어 있다. 그럼에도 명시적 인터페이스를 사용하는 이유는 단순함때문이다. go언어에서 가장 유명한 인터페이스를 보자.
type Stringer interface {
String() string
}위 인터페이스는 그렇게 인상적이지 않지만 fmt패키지가 해당 인터페이스를 다음과 같이 동작하도록 지원한다.
type Cat struct{}
func (c Cat) String() string {
return "Meow"
}
func main() {
kitty := Cat{}
fmt.Printf("kitty [%s]", kitty)
}명시적 인터페이스(explicit interface)를 사용하는 경우, Stringer를 구현하기 위해 메서드를 선언하는 횟수를 상상해보자. Go환경에서 암시적 인터페이스가 상당한 이점을 제공하는 경우는 아마 ISP, DI와 함께 사용할 때일 것이다. 이 3가지(암시적 인터페이스, ISP, DI)를 함께 조합하여 사용함으로써 특정 사용 사례에 한정된 입력 인터페이스를 정의하자. 또한, 인터페이스를 사용하는 패키지의 인터페이스를 정의하면 코드 작업을 할 때 필요한 지식 범위가 좁아지며, 이를 통해 더 쉽게 이해하고 테스트할 수 있다.
의존성 역전 원칙(DIP)
"상위 모듈은 하위 모듈에 의존해서는 안된다. 상위 모듈과 하위 모듈 모두 추상화에 의존해야 한다. 추상화는 세부 사항에 의존해서는 안된다. 세부 사항이 추상화를 의존해야 한다."
왜 우리는 후회를 하며 살까, 잘못된 구현인지를 인지해도 프로젝트를 진행하다보면 굳이 선택이 필요없는 상황에서 선택을 하게되어 두고두고 고생하게된다. 왜 굳 선택이 필요 없는 상황에서 선택을 하게 되는 것일까??
다음의 다이어그램을 보자.

너무 평범하고 유연한 구조로 느껴지지 않는다. 추상화를 통해 관계를 변경해보자.
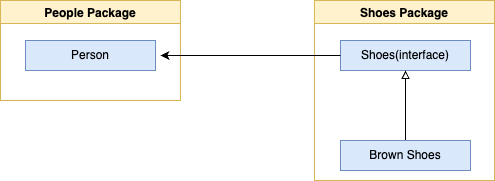
훨씬 좋아졌다. 적절한 추상화(Shoe)에 의존하고 있으며 LSP와 ISP를 모두 만족하고 있다. 패키지는 간결하고 명확하며 SRP를 만족시킨다. 그러나 아쉽게도 이는 완벽하지않는데 DIP를 만족시키지 못한다. DIP의 '역전'이라는 단어 때문이다.
위 예제에서 shoes 패키지는 shoe 인터페이스를 소유하고 있으며, 이는 전적으로 타당하다. 하지만 요구 사항이 변경될 경우 문제가 발생한다. shoes 패키지를 변경하면 shoe 인터페이스가 변경되기 쉽다. 이로써 결국 Person객체에 대한 변경이 필요해질 것이다. shoe인터페이스에 추가되는 새로운 기능들은 Person객체에서 필요로 하지 않거나 Person 객체와 관련이 없을 수도 있다. 따라서 Person객체는 여전히 shoe패키지에 결합돼 있다고 볼 수 있다. 이러한 결합을 완전히 끊기 위해서는 Person객체가 Shoe를 사용하는 관계에서 다음과 같이 Person객체가 Footwear를 필요로 하는 관계로 변경해야 한다.
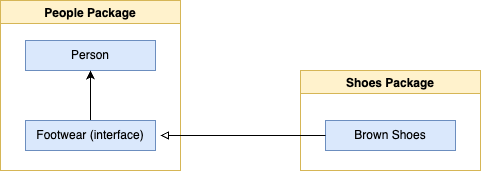
여기에는 두 가지 핵심 포인트가 있다. 첫째, DIP는 추상화의 소유권에 초점을 맞추도록 강요한다. 위 예제에서는 인터페이스를 실제로 사용되는 패키지로 옮기고 '사용'에서 '필요'로 관계를 변경한다. 이것은 미묘한 차이지만 매우 중요하다. '사용'은 사용하는 패키지 외부에서 가져다쓰는 개념이라 의존하고 있다면, '필요'는 인터페이스를 사용하는 패키지로 옮겨서 의존하지않고 있기 때문이다. 둘째, DIP는 사용에 대한 요구 사항(interface)을 구현에서 분리하도록 권장한다. 위 예제에서 Brown Shoes 객체는 Footwear 인터페이스에 대한 구현이지만 더 많은 종류의 신발을 구현하는 것을 어렵지 않게 상상할 수 있으며, 그중 일부는 신발이 아닐 수도 있다.
의존성 역전(dependency inversion)은 의존성 주입(DI)와 비슷해서 헷갈리기 쉬우며, 꽤 많은 사람들이 같은 것으로 착각해왔다. 하지만 지금까지 살펴본 바와 같이 의존성 역전은 추상적 정의(interface)에 대한 소유권에 초점을 맞추고 있는 반면, 의존성 주입은 이러한 추상화를 사용하는 데 초점을 맞추고 있다.
DI와 DIP를 적용하면, 쉽게 이해할 수 있고 확장이 용이하며 간단하게 테스트를 수행할 수 있는 잘 분리된 패키지를 정의할 수 있다.
앞서 GO언에서 지원하는 암시적(implicit) 인터페이스와 이를 활용하기 위해 다른 패키지에서 인터페이스를 가져오는 대신에 동일한 패키지 내에서 인터페이스를 사용해 의존성을 정의하는 방법을 설명했다. 이것이 바로 DIP에 대한 접근 방법이다.
이는 코드의 여러 부분에 인터페이스를 정의해야 하는 것을 의미할 수 있으며, 더 나아가 상당 부분 중복이 발생할 수 있다. 하지만 DIP를 고려하지 않고 정의한 인터페이스는 뚱뚱해지고 다루기 힘들다는 점을 알게 될 것이다. 이러한 사실은 추후 인터페이스를 변경할 때 더 많은 노력과 비용이 들어간다는 것을 의미한다.
DIP를 적용한 후에는 순환 종속성 문제가 발생하지 않을 것이다. 외부에서 코드에 가져온(import)양이 상당히 줄어들 것이며, 의존성 그래프의 형태가 단순해질 것이다. 실제로 많은 패키지가 main패키지로만 가져올 수 있다.
