4.2 다양한 트리계열 머신러닝 모델 사용하기
4.2.1 랜덤포레스트
- 트리모델을 앙상블 기법에 사용(Bagging: Boostrap aggregating)
- 여러개의 트리 모델을 만들고 학습에 필요한 샘플은 부트스트랩을 이용
- 생겨나는 트리마다 랜덤하게 사용되는 변수를 정하므로 트리의 과적합 문제를 해결
- 여러개 트리의 결과를 결합해서 하나의 결과를 도출
- bias: E(theta) - theta (기대값과 모수의 차이)
기본 Tree의 성능 평가
model = DecisionTreeClassifier(random_state = 42)
model.fit(X_train, y_train)
print('Tree의 성능은: {}'.format(model.score(X_test, y_test)))
랜덤 포레스트
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state = 42)
model
- 랜덤 포레스트의 하이퍼 파라미터들
model.fit(X_train, y_train)
- n_estimators가 결합하는 Tree의 수
- 100개의 Tree를 만들어 이 결과를 결합
- 보통 Tree의 수가 많다면 좀 더 안정적인 결과를 도출하긴 함
- ccp_alpha: Complexity parameter used for Minimal Cost-Complexity Pruning.
The subtree with the largest cost complexity that is smaller than ccp_alpha will be chosen.
By default, no pruning is performed. - 수가 무한대라면 어느정도 수렴하게 되는거니까. but 시간이 많이 소요. 보통 500? 정도로
- Tree를 n_estimators만큼 만들고 그 트리들을 학습시키는 거니까 기본 트리보다 시간이 더 걸림

- Prediction 하는 것도 다 똑같음
print('RandomForest: {}'.format(model.score(X_test, y_test)))
- Tree와 비교했을 때 더 상승
- Tree의 단점인 high Var을 해결했기 때문
Feature importance
plt.figure(figsize = (10, 8))
sns.barplot(x = model.feature_importances_, y = X_train.columns)
plt.show()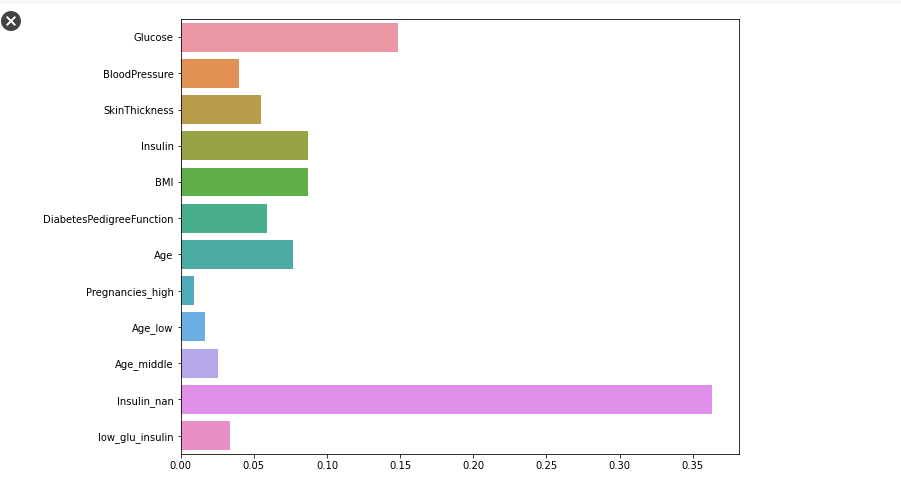
- 인슐린 수치, 글루코스가 순으로 영향을 많이 준다.
- 대부분의 트리 알고리즘에선 feature_importances를 알 수 있음
- linear model에선 coef으로 importance 파악!
4.2.2 그래디언트 부스팅 알고리즘
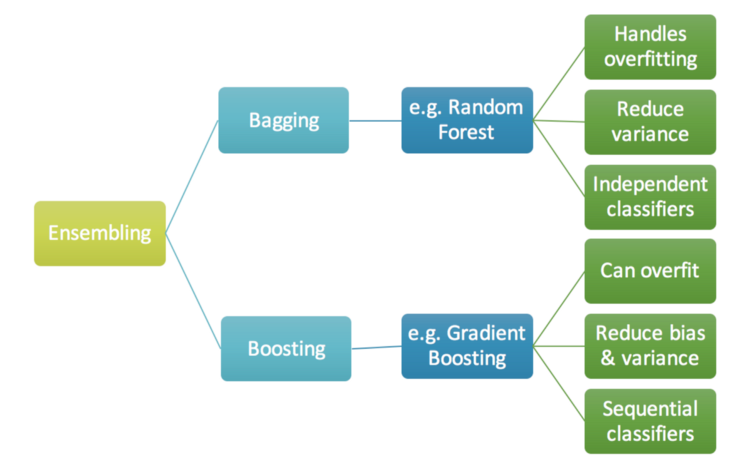
- Boosting: 약한 분류기를 만들어 sequential하게 결합하며 강한 분류기를 만드는 알고리즘
- Tree를 결합해 나가면서 성능이 좋은 분류기를 만들어 줌
- 결합하는 과정에서 과적합 방지를 위해 learning rate를 곱해줘 결과를 결합해 감
- RandomForest 처럼 다양한 트리를 사용하는 건 동일함
- RF는 여러개의 트리의 결과를 합해서 사용하고, Boosting은 기본 트리로 시작해서 생성한 개수만큼 반복하면서 결합해 나감. Gradient Boosting은 learning_rate를 곱해줘서 결과들을 결합해 나가고 마지막 트리까지. 최종 결과를 도출
- Gradient Boosting은 경사하강법이라 생각하면 됨. 최소 loss를 찾기 위해 조금씩 이동하면서 줄여가는 알고리즘이라 생각
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(random_state = 42)
model
- hyper-params!!
- learning_rate을 크게 주면 너무 크게 움직이면서 최적을 지나가고
- 작게주면 너무 조금씩 움직여 최적에 도달 못함
- 둘의 Trade-Off를 고려해서 값을 주기. 보통 0.1, 0.01, 0.001로 하긴 함
model.fit(X_train, y_train)
print('GradientBoosting Classifier: {}'.format(model.score(X_test, y_test)))
- GBC의 성능은 86%. RF보다 2%가량 성능이 좋지 않음
plt.figure(figsize = (10, 8))
sns.barplot(x = model.feature_importances_, y = X_train.columns)
plt.show()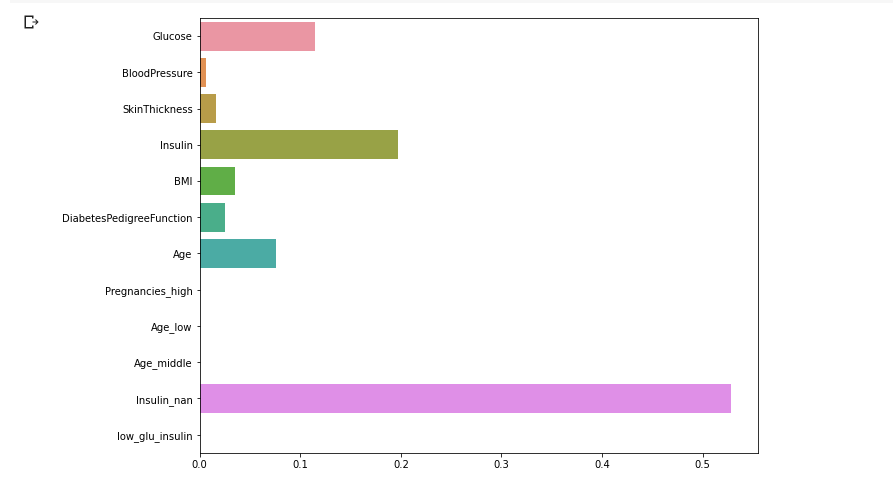
- RF와 동일하게 인슐린 수치가 영향을 많이 미침
- But, 아예 중요도가 0인 변수도 생겨남.
- 모델에 따라 학습 알고리즘이 다르므로 중요한 변수가 다르게 될 수도 있는 것
보통 RF보다 GB가 더 성능이 좋다고 말하는 사람도 있지만, 이 예제의 결과에선 RF가 더 좋다.
이렇듯, 모든 경우에서 최고의 모델은 없다.
따라서 최대한 많은 모델을 이용해서 성능을 비교해보고 최적 모델로 선정해야 한다.
4.2.3 RandomSearchCV로 최적 하이퍼 파라미터 찾기
기본 트리로 RandomSearch
max_depth = np.random.randint(2, 20, 10)
max_features = np.random.uniform(0.3, 1., 10)
param_distributions = {'max_depth': max_depth, 'max_features': max_features}
estimator = DecisionTreeClassifier(random_state = 42)
clf = RandomizedSearchCV(estimator, param_distributions = param_distributions, n_iter = 100, scoring = 'accuracy', n_jobs = -1, cv = 5, verbose = 2)
clf.fit(X_train, y_train)
print(clf.best_params_)
print(clf.best_score_)
- n_jobs = -1 이면 가용 가능한 모든 자원을 사용하겠단 뜻
- max_features = 0.917..., max_depth = 4. 이때의 score = 0.89!
DT, RF, GB 세 가지 알고리즘을 동시에 사용
estimators = [DecisionTreeClassifier(random_state = 42), RandomForestClassifier(random_state = 42), GradientBoostingClassifier(random_state = 42)]
estimators
4.2.4 RandomSearch CV로 최적 하이퍼파라미터 찾기
여러개의 알고리즘에 대해 RandomSearch CV를 진행해서 최적 모델을 찾음
- 한 번에 하나의 모델만 가능하므로 for문을 이용해서 모델을 바꿔가며 넣어줌
- Hyper params까지 최적인 것!!
results = []
for estimator in estimators:
result = []
result.append(estimator.__class__.__name__)
results.append(result)
results
- results에 각 모델의 이름을 담아줌
from sklearn.model_selection import RandomizedSearchCV
max_depth = np.random.randint(2, 20, 10)
max_features = np.random.uniform(0.3, 1., 10)
param_distributions = {'max_depth': max_depth, 'max_features': max_features}
results = []
for estimator in estimators:
result = []
if estimator.__class__.__name__ != 'DecisionTreeClassifier':
param_distributions['n_estimators'] = np.random.randint(100, 200, 10)
clf = RandomizedSearchCV(estimator, param_distributions, n_iter = 100, scoring = 'accuracy', n_jobs = -1, cv = 5, verbose = 2)
clf.fit(X_train, y_train)
result.append(estimator.__class__.__name__)
result.append(clf.best_params_)
result.append(clf.best_score_)
result.append(clf.score(X_test, y_test))
result.append(clf.cv_results_)
results.append(result)3개 모델에 대해 100번씩 5 fold cv라 시간이 꽤 걸림
df = pd.DataFrame(results,
columns=["estimator", "best_params", "train_score", "test_score", "cv_result"])
df
- RF가 best model.
pd.DataFrame(df.loc[1, "cv_result"]).sort_values(by="rank_test_score").head()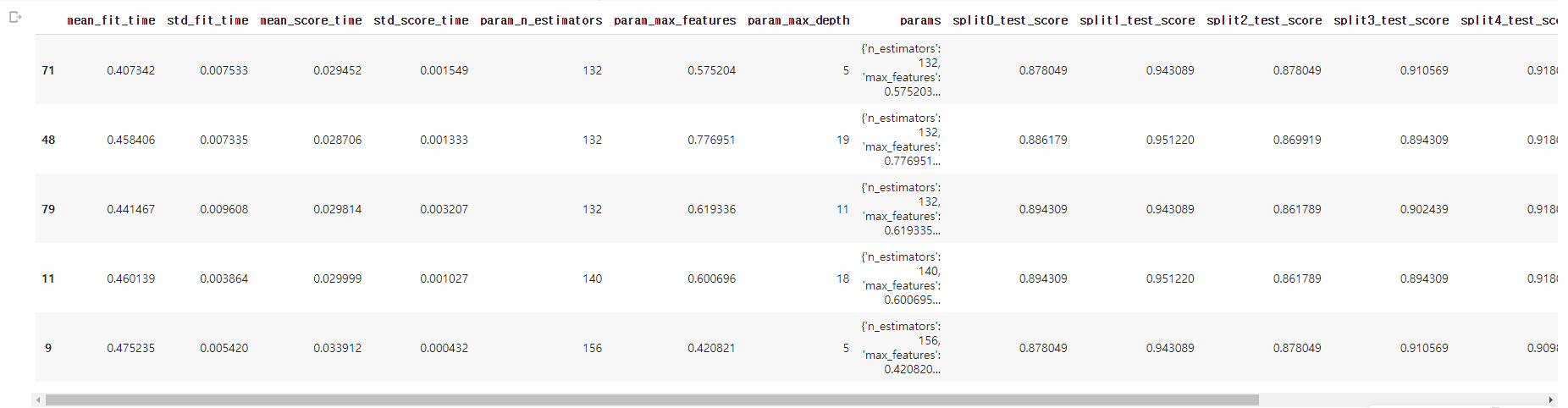
- RF의 cv_result를 rank 순으로 정렬하고 상위 5개 경우를 출력
- 모델에 각각 접근하여 상위에 있는 모델 순서대로 보거나 정확한 parameter 설정 수치를 볼수있음
- 좋은 성능이 나오는 구간으로 좁혀가며 계속 iteration을 돌릴 필요가 있음
- 하이퍼 파라미터 튜닝을 여러 번 할수록 좋은 성능을 얻을 수 있음
- 최적은 어딘가에 존재하기 때문에 모든 가능한 경우에 대해 돌려볼 필요가 있긴 하지만 너무 많은 시간이 소요되므로 RandomizedSearch와 같은 걸 쓰는 것. 아니면 몇 개 추려서 GridSearch..
- 둘 다 최적을 보장하진 않음!! 그리디한 선택을 하는 것이지.

Data science