(데이터분석 커리어UP) AWS SageMaker

Amazon SageMaker 소개
Amazon SageMaker는 데이터 과학자 및 개발자가 모든 규모의 기계 학습 모델을 간편하게 빌드, 학습 및 배포할 수 있도록 하는 완전 관리형 서비스입니다.
쉽게 말해서 우리가 기존에 쓰는 Jupyter Notebook에 필요한 라이브러리가 다 설치되어 있고, 평소에 우리가 하던 모델을 코딩하여 구축하되 배포까지 알아서 다해주는 서비스라고 생각하면 된다.
Amazon SageMaker를 반드시 써야하는 이유
- 개발 낭비 시간 최소화
- 분석 타겟으로 하는 프로젝트의 개발 세팅(도커 이미지 탑재화)이 이미 되어있어 빠르게 적용 가능
- 비용적 측면 이득
- 비싼 물리적 서버를 사용할 필요 없이, 원하는 사양의 서버 인스턴스를 골라서 쓰고 반납 가능
- 모델 빌드부터 배포까지 올인원 서비스
- 우리가 ML/DL 모델링을 하는 최종의 목표는 비즈니스 도입인데 SageMaker는 모델링과 동시에 배포까지 한방에 끝.
- 데이터 파이프라인 제공
- 모델링 전 반드시 데이터 가공 작업이 필수인데, SageMaker는 데이터 ETL 기능을 제공하기 때문에 메뉴얼한 데이터 전처리 공수 작업 소거
- 모델 버전 관리 시스템
- 데이터가 지속적으로 쌓임에 따라, 지속적인 모델 학습이 필요한데, 모델 학습에 따른 버전 관리가 되기 때문에 적재적소에 원하는 성능의 모델 사용 가능
- 빠른 프로토타입 모델 도출
- SageMaker에서는 최신화 모델의 코드 수준의 정보를 제공하여, 사용자가 빠르게 POC 형태의 프로토타입 모델을 도출하여 기본 베이스라인 모델로 잡을 수 있다.
SageMaker 기본 내장 서비스 소개
Amazon SageMaker GroundTruth

레이블 지정 작업에 대해 이미지 분류, 객체 탐지, 의미 체계 세분화 등으로 구성된 매우 정확한 교육 데이터 세트를 구축할 수 있고, Amazon SageMaker Ground Truth를 사용하면 레이블링 작업자에게 간편하게 액세스할 수 있고 내장형 또는 맞춤 구성 워크플로와 통상적인 레이블 지정 작업의 인터페이스를 사용할 수 있다.
ML/DL 모델링에 반드시 필요한 것들 중 하나는 데이터 레이블링이다.
데이터 모델링에 쏟는 시간보다, 보통 완벽한 데이터 세트 갖추는데 시간이 더 소모되는데,
Amazon SageMaker GroundTruth 기능을 통해서 데이터 세트를 생성하는 시간 및 노력을 줄이는 데 도움이 될 수 있다.
구체적인 방법은 해당 링크를 통해서 확인하길 바란다.
Amazon SageMaker Data Wrangler

"데이터 사이언티스트"에게 ML 문제를 연구하는데 얼마나 많은 시간을 할애하는지에 대해서 물어보면, 단체로 한숨을 쉬면서 "운이 좋으면 20%"라 답하고 "나머지 80%는 데이터 세트 준비 시간"이라고 답한다.
하지만 이러한 문제 상황을 약간 반대적 시각으로 보면, 데이터 세트를 준비하는 것이 모델링 준비하는 것 만큼이나 중요하다는 것을 의미한다.
이번에 소개할 Data Wrangler는 ML을 위한 완전관리형 통합 개발 환경(IDE)인 Amazon SageMaker Studio에 통합되어 있으며, 몇 번의 클릭만으로 데이터 원본에 연결하고 데이터를 탐색 및 시각화하며 기본 제공 변환 및 고유한 변환을 적용하고 결과 코드를 자동 생성된 스크립트로 내보내며 이를 관리형 인프라에서 실행할 수 있다.
쉽게 말해서 Data Wrangler를 사용하게 되면 복잡한 데이터 파이프라인을 몇 번의 클릭만으로 쉽게 GUI 상의 데이터 파이프라인을 구축할 수 있게 된다.
Amazon SageMaker Processing

Python 스크립트 또는 사용자 지정 컨테이너를 사용하여 사전 처리, 사후 처리 및 모델 평가에 경험이 있는 데이터사이언티스트를 위해 Amazon SageMaker Processing은 데이터 전처리 로 직 스크립트를 통해 Amazon S3의 데이터를 입력으로 데이터를 Amazon S3에 출력으로 저장할 수 있게 한다.
쉽게 말해서 앞서 설명드린 Data Wrangler와 비교하여 파이썬 코드가 조금 더 편한 사람은 해당 기능이 훨씬 편할 수 있다.
Amazon SageMaker Feature Store

머신 러닝(ML) 개발 프로세스는 종종 ML 모델을 훈련하기 위해 데이터에서 특징이라고도 하는 데이터 신호를 추출하는 것으로 시작하는데, Amazon SageMaker Feature Store를 사용하면 데이터 사이언티스트, 기계 학습 엔지니어 및 일반 실무자가 기계 학습(ML) 개발을 위한 기능을 쉽게 생성, 공유 및 관리할 수 있다.
특히 Amazon SageMaker Feature Store는 원시 데이터를 ML 알고리즘 학습을 위한 기능으로 변환하는 데 필요한 반복적인 데이터 처리 작업을 줄여 모델링 프로세스를 가속화합니다.
쉽게 다시 말하면, 데이터 모델링의 Input 데이터로 쓰기 위한 Feature을 한 곳에 모아두었다고 생각하면 된다.
이렇게 해야지 원하는 Data Feature들을 가공 고민 없이 바로 쓸 수 있기 때문이다.
Amazon SageMaker Notebook
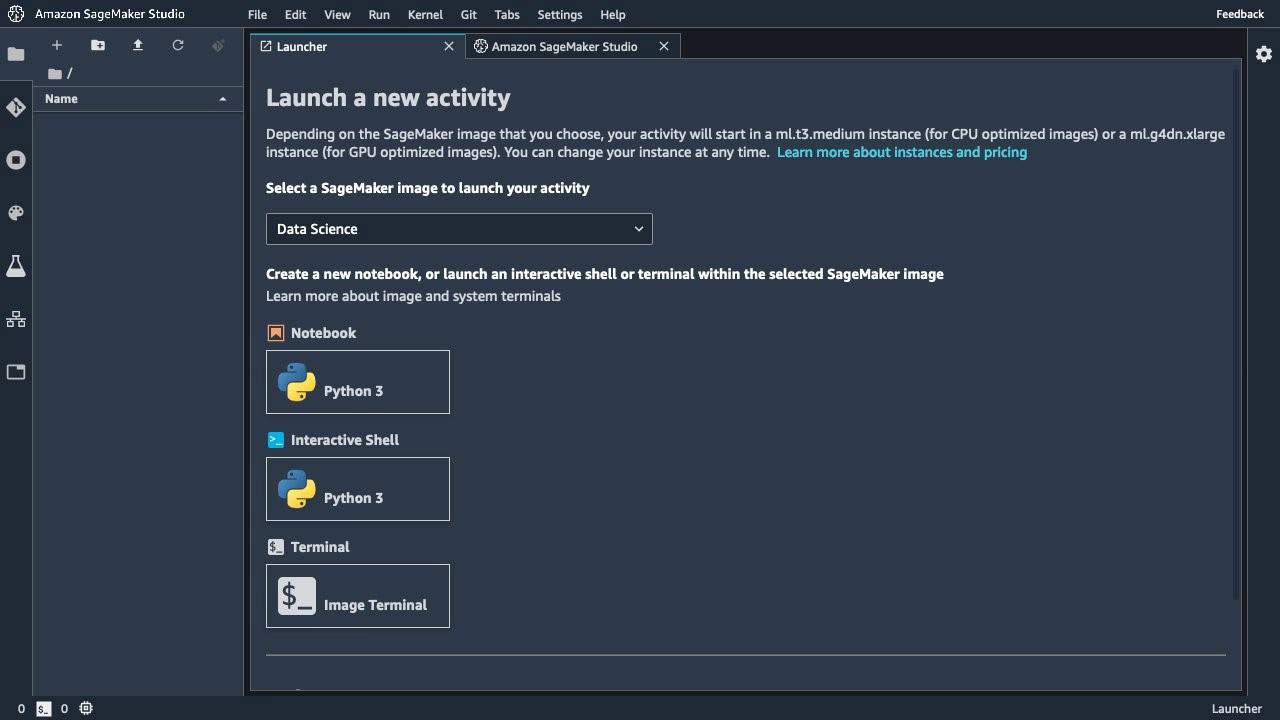
Amazon SageMaker Jupyter Notebook은 앱을 실행하는 완전 관리형 기계 학습(ML) Amazon Elastic Compute Cloud(Amazon EC2) 컴퓨팅 인스턴스입니다. 노트북 인스턴스를 사용하여 데이터를 사전 처리하고 기계 학습 모델을 교육 및 배포하기 위한 Jupyter 노트북을 생성 및 관리한다.
쉽게 말해서 우리가 Google에서 사용한 "Colab"과 매우 유사하다고 생각하면 되고, 그 주피터 노트북 안에서 평소에 우리가 ML/DL 모델 학습 해왔던 것처럼 똑같은 환경을 제공한다고 생각하면 된다.
구체적인 Amazon SageMaker Jupyter Notebook 사용 방법은 아래의 링크를 통해 참고 바란다.
https://docs.aws.amazon.com/sagemaker/latest/dg/gs-setup-working-env.html
글을 마치며
일단 인공지능을 비즈니스 단계로 들어오게 되면, 더 이상 우리는 인공지능을 단순 학제적 산유물로 두어서는 안된다.
"어떻게 더 좋은 알고리즘 및 하이퍼파라미터 조정을 통해서 성능을 0.001% 더 올렸니, 마니"
실제 비즈니스에서는 이러한 노력과 시간 보다는, 빠르게 인공지능을 빌드하여 배포하고 서비스를 운영하면서 빠르게 수익내는 것이 중요하다.
그렇기 때문에 우리는 On-Premise 환경에서 처음부터 쌓아가는 인공지능 모델이 아니라,
누구보다 빠르게 인공지능 모델을 구축해서 평가하고 실전에 투입하는 것을 더욱 목표로 한다.
이러한 목표를 달성하기 위해 우리는 "AWS SageMaker"를 반드시 현업에 사용할 필요성을 느낀다.
