3주차 배운 것
- 이번 주차는 새로 배우기보다는 써먹기에 가까웠는데, 결국 스크래핑이나 크롤링하는 것이 어떤 클래스에 속한 정보를 가져오는 것인지에 대해서 좀 감을 잡은 것 같다. 몇가지 주제를 더 해본다면 도움이 더 될 것 같다는 생각이 들었다.
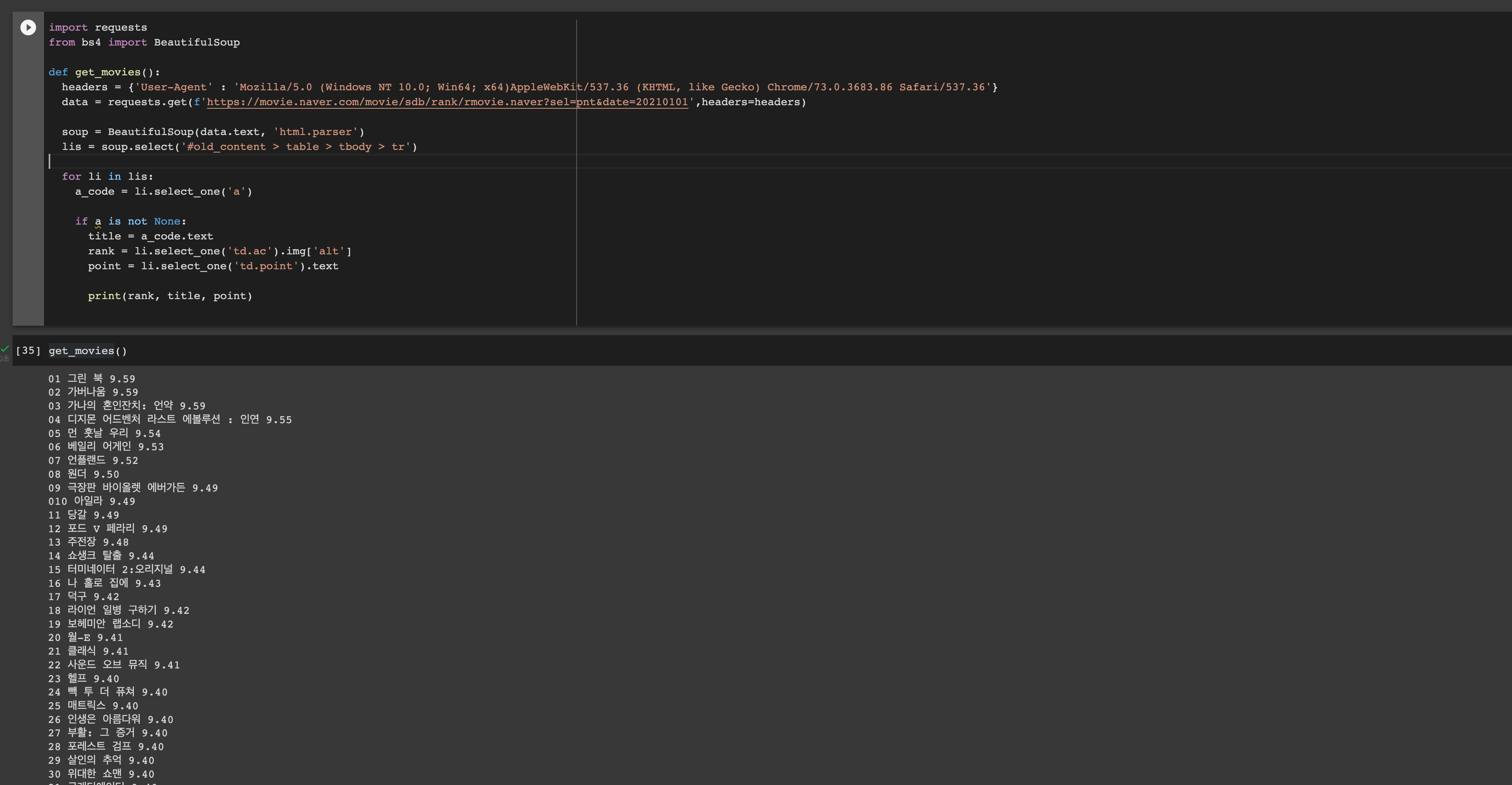
이번에 작업한 코드
import requests
from bs4 import BeautifulSoup
def get_movies():
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210101',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#old_content > table > tbody > tr')
for li in lis:
a_code = li.select_one('a')
if a is not None:
title = a_code.text
rank = li.select_one('td.ac').img['alt']
point = li.select_one('td.point').text
print(rank, title, point)
이 코드에서 조금 난감했던 것은 html 코드(태그?) 상에 있는 a 코드를 가져오는 것이었는데..처음 시작할 때까지 a코드 상의 정보를 어떻게 가져오는 것인지에 대해서 감이 계속 안 잡혀서 좀 혼이 났던 것 같다. rank 정보도 분명히 이렇게 하면 들어올 것 같았는데, 왜 안 들어오지 하다가 "."도 찍어보고, 배열도 생각해보면서 이래저래 해보다 보니 되었던 것 같다.
뭔가 실력이 느는 느낌보다는 한주한주 따라가는 느낌이라서 여전히 불안한 것은 있긴한데..(이게 69,000원을 매달 결제할 가치가 있는 활동일지) 3개월 정도는 죽이 되든 밥이 되든 해보려고 해서..일단 잘 버텨보자 싶다. :)

Agile & Product