
한 눈에 읽기
Topic은 Partition으로 구성된
일련의 로그 파일
- RDBMS의 Table과 유사한 기능
- Partitioned Table
- Key - Value 기반의 메시지 구조
- Value로 어떤 타입의 메시지도 가능
(문자열, 숫자값, 객체, Json, Avro, Protobuf등등)
- 로그 파일과 같이, 연속적으로 추가되는 발생하는 데이터를 저장하는 구조
- Topic은 시간의 흐름에 따라 메시지가
순차적으로물리적인 파일에 Write된다.
Topic은 1개 이상의 파티션을 가질 수 있다.
Topic과 Partition은 Kafka의
병렬 성능과가용성 기능의 핵심 요소이며, 메시지는 병렬 성능과 가용성을 고려한 개별 파티션에 분산 저장된다.
- 개별 파티션은 정렬되고, 변경할 수 없는 일련의 레코드로 구성된 로그 메시지
- 개별 레코드는 Offset으로 불리는 일련 번호를 할당 받는다.
- 개별 파티션은 다른 파티션과 완전 독립
- 개별 파티션내에서 정렬되고 Offset이 할당된다.
- Topic의 파티션들은 단일 카프카 브로커 뿐만 아니라 여러 개의 카프카 브로커들에 분산 저장 된다.
Kafka Topic
Kafka의 정수이자 사용하는 이유
Topic을 생성하면서Pipeline이 만들어진다.
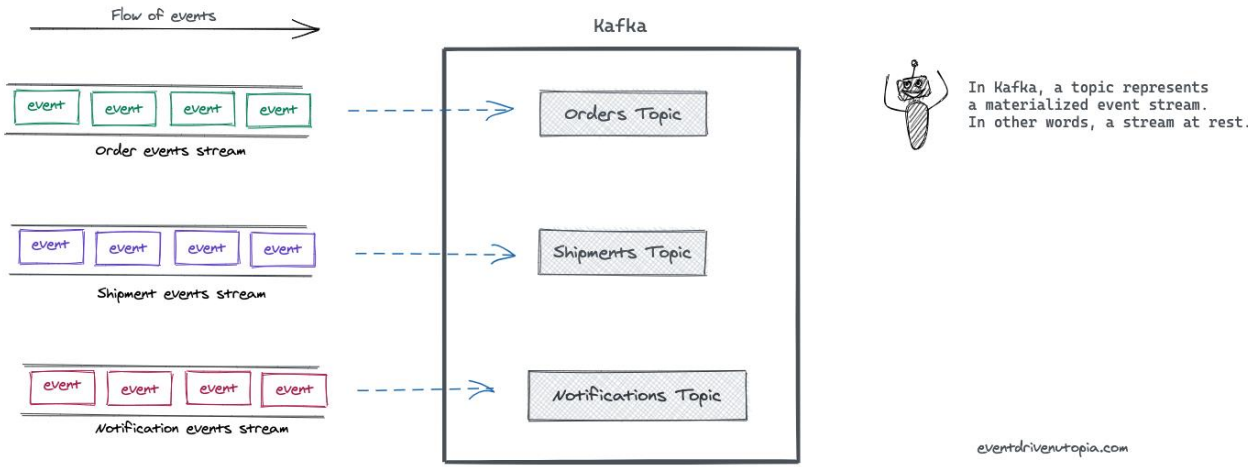
Kafka에서데이터를 구분하는 단위
"구체화된 이벤트 스트림"
- Event
- 어떤 일어난 일
- 시스템 사이를 오고 가는
불변 데이터또는레코드또는메시지
- Streams
- 관련된 이벤트들 (순서 함유)
- Topic
- 연관 이벤트들을 묶어 영속화한 것
Kafka Partitions

- Topic을 이루고 있는 단위
- Topic이 속한 레코드를 실제 저장소에 저장하는 가장 작은 단위
- Append Only로 저장되는 Log File
- Producer가 보낸 데이터들이 파티션에 들어가 저장되고 이 데이터를 레코드라고 부른다.
- Queue와 비슷한 FIFO 구조, But 처리 및 삭제 X
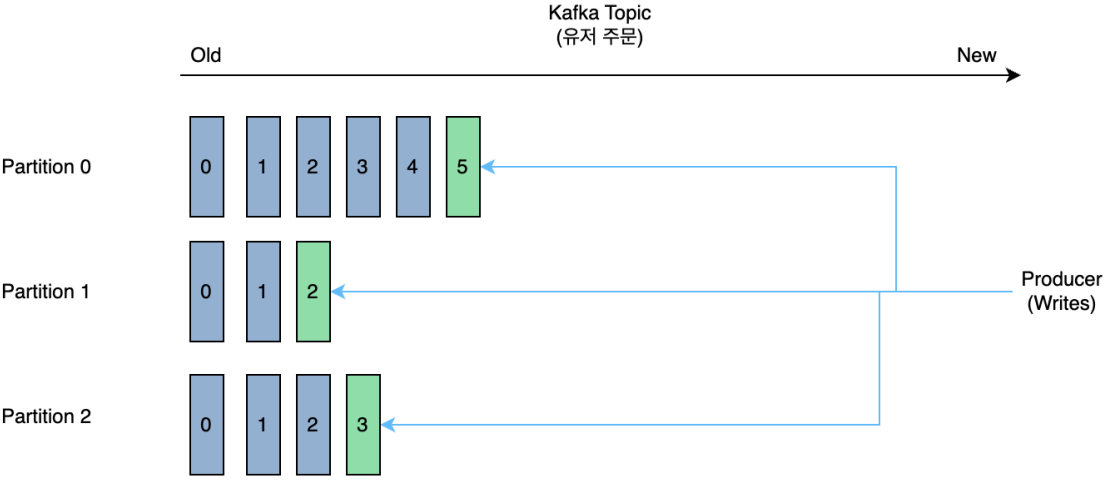
파티션의 각 레코드에는 Offset이라는 식별자가 붙는다.
-
Kafka에서 유지 관리하는 증분 및 변경 불가능한 숫자
-
레코드가 파티션에 기록되면
다음 순차 오프셋을 할당하여 로그 끝에 추가한다. -
파티션 내의 메시지는 순서가 정해져 있지만
Topic 전체의 메시지는 순서가 보장되지 않는다.
효과
Topic의 Partitions을 여러 Broker에 분산
- 수평적 확장
- 병렬적 사용
- 매우 높은 메시지 처리량
Partitions은 Kafka가 복제하는 방식
- 여러 브로커에 동일한 파티션의 복제본을 2개 이상 갖는다.
- 브로커가 다운되면,
다운된 브로커가 갖고 있는 파티션의 복제본을 사용한다.
파티셔닝 방법
Producer는 레코드를 특정 Partition에 보내야한다.
- 1. Partition Key
- 파티션 키로 사용할 데이터 선정(_id)
- Hashing 함수를 통해 전달
- 동일 키로 생성한 모든 레코드는 동일 파티션에 저장
- 정확한 순서가 보장될 수 있다.
- Key가 잘 분산되지 않을 수 있다.
-
2. Kafka가 결정
-
3. 사용자가 결정
레코드 읽기

- Consumer가 Broker Partiton에 연결하고 순서대로 메시지를 읽는다.
Offset이 Consumer의 Cursor 역할
- Consumer는 Offset을 트래킹하면서 사용한 메시지 추적하고
메시지를 읽고 다음 Offset으로 이동한다.
- 각 파티션에 마지막으로 소비된 메시지의 Offset을 기억한다.
- 즉, 어떤 시점에 파티션에 들어가더라도
Offset위치에서 작업을 재개할 수 있다.
- 각 Consumer는 각 Partitions에 대해 어디까지 읽었는지 자신만의 기록을 가지게 된다.
- 이를 통해 충돌이 나지 않게 된다.
Partition은 많으면 좋을까?
Partition은 늘린 다음에 줄일 수 없으므로,
원하는 목표 처리량의 기준이 요구된다.

클라우드, 데이터, DevOps 엔지니어 지향 || 글보단 사진 지향