
Connector?
Kafka Connect에서
데이터를 소스나 대상 시스템으로 이동시키는 특정 데이터 소스 또는 대상 시스템과의 통합을 담당하는 모듈
Connector 설치 및 Connect 생성
다음 명령어를 입력하면 생성된다.
$CONFLUENT_HOME/bin/connect-distributed $CONFLUENT_HOME/etc/kafka/connect-distributed.properties물론, 그 전에
생성할 Connector를 특정 디렉터리에 설치한 후에 실행해야 한다.
그리고, Zookeeper, Kafka가 실행된 상태여야 한다.
Connect-distribute.properties
Kafka의 Kafka Connect 분산 모드를 설정하는 데 사용되는 속성 파일
Kafka Connect를 설정하고 실행할 때 중요한 역할을 하며, 분산 모드에서 여러 워커를 사용하여 대규모 데이터 파이프라인을 구축하는 데 사용됩니다.
# 이 파일은 Kafka Connect 분산 워커의 일부 구성을 포함하고 있습니다.
# 이 파일은 예제와 함께 사용되도록 되어 있으며 일부 설정은 프로덕션 시스템에서 사용되는 것과 다를 수 있습니다,
# 특히 `bootstrap.servers` 및 복제 요인을 지정하는 것과 관련된 것들입니다.
# 초기 Kafka 클러스터 연결을 설정하는 데 사용할 호스트/포트 쌍의 목록입니다.
bootstrap.servers=localhost:9092
# Connect 클러스터 그룹을 형성할 때 사용되는 클러스터의 고유한 이름입니다.
# 이는 소비자 그룹 ID와 충돌하지 않아야 합니다.
group.id=connect-cluster
# 컨버터는 Kafka의 데이터 형식과 Connect 데이터로의 변환 방법을 지정합니다.
# 모든 Connect 사용자는 Kafka에서로드하거나 저장할 데이터의 형식을 기반으로 이를 구성해야 합니다.
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
# 컨버터별 설정은 해당 컨버터의 설정을 적용하려는 컨버터를 접두사로 붙여 전달할 수 있습니다.
key.converter.schemas.enable=true
value.converter.schemas.enable=true
# 오프셋을 저장하는 데 사용할 토픽입니다. 이 토픽은 많은 파티션을 가져야 하며 복제되고 압축되어야 합니다.
# Kafka Connect는 필요할 때 토픽을 자동으로 생성하려고 시도할 것입니다만, 필요한 경우
# Kafka Connect를 시작하기 전에 특정 토픽 구성이 필요한 경우 토픽을 수동으로 생성할 수 있습니다.
# 대부분의 사용자는 내장된 기본 복제 요인 3을 사용하거나 경우에 따라 더 큰 값을 지정할 것입니다.
# 이는 최대 복제 요인과 동일한 수의 브로커가 있어야 함을 의미하므로 이 예제를 단일 브로커 클러스터에서 실행할 수 있기를 원합니다.
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1
#offset.storage.partitions=25
# 커넥터 및 태스크 구성을 저장하는 데 사용할 토픽입니다. 이는 단일 파티션, 고도로 복제되고 압축되어야 하는 토픽이어야 합니다.
# Kafka Connect는 필요할 때 토픽을 자동으로 생성하려고 시도할 것입니다만,
# 필요한 경우 Kafka Connect를 시작하기 전에 특정 토픽 구성이 필요한 경우 토픽을 수동으로 생성할 수 있습니다.
# 대부분의 사용자는 내장된 기본 복제 요인 3을 사용하거나 경우에 따라 더 큰 값을 지정할 것입니다.
# 이는 최대 복제 요인과 동일한 수의 브로커가 있어야 함을 의미하므로 이 예제를 단일 브로커 클러스터에서 실행할 수 있기를 원합니다.
config.storage.topic=connect-configs
config.storage.replication.factor=1
# 상태를 저장하는 데 사용할 토픽입니다. 이 토픽은 여러 파티션을 가질 수 있으며 복제되고 압축되어야 합니다.
# Kafka Connect는 필요할 때 토픽을 자동으로 생성하려고 시도할 것입니다만, 필요한 경우
# Kafka Connect를 시작하기 전에 특정 토픽 구성이 필요한 경우 토픽을 수동으로 생성할 수 있습니다.
# 대부분의 사용자는 내장된 기본 복제 요인 3을 사용하거나 경우에 따라 더 큰 값을 지정할 것입니다.
# 이는 최대 복제 요인과 동일한 수의 브로커가 있어야 함을 의미하므로 이 예제를 단일 브로커 클러스터에서 실행할 수 있기를 원합니다.
status.storage.topic=connect-status
status.storage.replication.factor=1
#status.storage.partitions=5
# 플러시 간격을 기본보다 훨씬 빠르게 설정합니다. 이는 테스트/디버깅에 유용합니다.
offset.flush.interval.ms=10000
# REST API가 청취할 쉼표로 구분된 URI 목록입니다. 지원되는 프로토콜은 HTTP 및 HTTPS입니다.
# 호스트 이름을 0.0.0.0으로 지정하여 모든 인터페이스에 바인딩합니다.
# 기본 인터페이스에 바인딩하려면 호스트 이름을 비워 두세요.
# 합법적인 청취자 목록 예시: HTTP://myhost:8083,HTTPS://myhost:8084"
#listeners=HTTP://:8083
# 다른 워커가 연결하는 데 사용할 호스트명 및 포트입니다. 즉, 다른 서버에서 라우팅 가능한 URL입니다.
# 설정된 경우 "listeners"의 값을 사용합니다.
#rest.advertised.host.name=
#rest.advertised.port=
#rest.advertised.listener=
# 플러그인의 클래스 로딩 격리를 활성화하려면 쉼표(,)로 구분된 파일 시스템 경로 목록을 설정하세요.
# (커넥터, 컨버터, 변환) 플러그인과 그 종속성을 포함하는 최상위 디렉터리로 구성되어야 합니다.
# 목록은 다음의 조합을 포함해야 합니다:
# a) 플러그인과 그 종속성을 포함하는 jar를 직접 포함하는 디렉터리
# b) 플러그인과 그 종속성을 포함하는 uber-jars
# c) 플러그인과 그 종속성의 클래스의 패키지 디렉터리 구조를 직접 포함하는 디렉터리
# 예시:
# plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors,
plugin.path=/home/chan-kaf/connector_plugins
세부 정리
bootstrap.servers=localhost:9092초기 Kafka 클러스터 연결을 설정하는 데 사용할 호스트/포트 쌍의 목록
group.id=connect-clusterConnect 클러스터 그룹을 형성할 때 사용되는 클러스터의 고유한 이름
Consumer Group ID와 충돌 X
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=trueKafka의 데이터 형식과 Connect 데이터로의 변환 방법을 지정
컨버터별 설정은 해당 컨버터의 설정을 적용하려는 컨버터를 접두사로 붙여 전달할 수 있습니다.
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1
#offset.storage.partitions=25오프셋을 저장하는 데 사용할 토픽
config.storage.topic=connect-configs
config.storage.replication.factor=1커넥터 및 태스크 구성을 저장하는 데 사용할 토픽
status.storage.topic=connect-status
status.storage.replication.factor=1
#status.storage.partitions=5상태를 저장하는 데 사용할 토픽
offset.flush.interval.ms=10000플러시 간격을 기본보다 훨씬 빠르게 설정합니다. 이는 테스트/디버깅에 유용합니다.
#listeners=HTTP://:8083REST API가 청취할 쉼표로 구분된 URI 목록
#rest.advertised.host.name=
#rest.advertised.port=
#rest.advertised.listener=다른 워커가 연결하는 데 사용할 호스트명 및 포트입니다.
즉, 다른 서버에서 라우팅 가능한 URL입니다.
# plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors,
plugin.path=/home/chan-kaf/connector_pluginsConnector 설치 경로

(Connector, Convertor, Transform)
플러그인과 그 종속성을 포함하는 최상위 디렉터리로 구성a).
플러그인과 그 종속성을 포함하는 jar를 직접 포함하는 디렉터리
b).플러그인과 그 종속성을 포함하는 우버-자르
c).플러그인과 그 종속성의 클래스의 패키지 디렉터리 구조를 직접 포함하는 디렉터리
Connect 실행
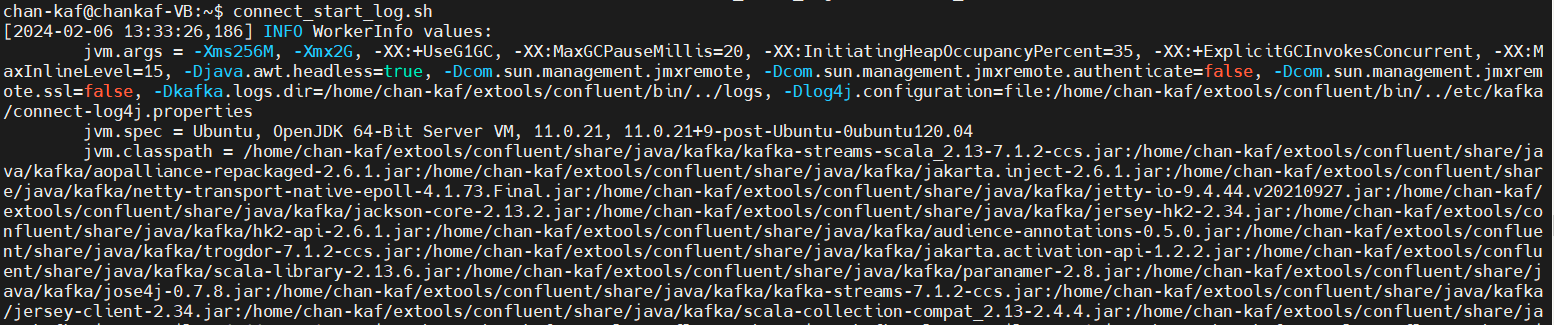
여기서 정상 확인이 어렵기 때문에, (순식간에 지나감...)
chan-kaf@chankaf-VB:~$ http GET http://localhost:8083/connectors
HTTP/1.1 200 OK
Content-Length: 2
Content-Type: application/json
Date: Tue, 06 Feb 2024 05:34:40 GMT
Server: Jetty(9.4.44.v20210927)
[]
해당 명령어로 Connect 정상 가동을 확인한다.
Connect 관리
위에서 확인했듯이 Connector는
Connector 이름,Connector 클래스 이름,Connector 고유 환경 설정등을
REST API를 통해 Kafka Connect에 전달하여 새롭게 생성한다.
Shell CLI를 통해 REST API로 여러 설정들을 보내기에는 매우 복잡하므로,
Json 파일로 여러 설정들을 미리 작성한 후
curl 또는 httpie를 통해 REST API 전송한다.
EXAMPLE (Spool Dir Source Connector)
spooldir_source.json 파일
{ "name": "csv_spooldir_source", "config": { "tasks.max": "3", "connector.class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirCsvSourceConnector", "input.path": "/home/min/spool_test_dir", "input.file.pattern": "^.*\\.csv", "error.path": "/home/min/spool_test_dir/error", "finished.path": "/home/min/spool_test_dir/finished", "empty.poll.wait.ms": 30000, "halt.on.error": "false", "topic": "spooldir-test-topic", "csv.first.row.as.header": "true", "schema.generation.enabled": "true" } }
curl -X POST -H "Content-Type: application/json" http://localhost:8083/connectors --data @spooldir_source.json위와 같이 REST API로 전송하면,
HTTP/1.1 201 Created
Content-Length: 849
Content-Type: application/json
Date: Tue, 06 Feb 2024 05:36:47 GMT
Location: http://localhost:8083/connectors/csv_spooldir_source
Server: Jetty(9.4.44.v20210927)
{
"config": {
"tasks.max": "3",
"connector.class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirCsvSourceConnector",
"input.path": "/home/min/spool_test_dir",
"input.file.pattern": "^.*\\.csv",
"error.path": "/home/min/spool_test_dir/error",
"finished.path": "/home/min/spool_test_dir/finished",
"empty.poll.wait.ms": 30000,
"halt.on.error": "false",
"topic": "spooldir-test-topic",
"csv.first.row.as.header": "true",
"schema.generation.enabled": "true"
}
"name": "csv_spooldir_source",
"tasks": [],
"type": "source"
}위의 결과를 얻으며 Connector가 정상 실행됨을 확인한다.
결론.
Kafka를 실행하고 Connect까지 동작을 확인했다.
이후에 Connect가 데이터를 정상적으로 받아들이고 내보내는 데 까지 확인했다.
Connector마다 REST API를 보내는 설정이 제각각이므로 이후에 과정은 필요할 때 마다 그때그떄 찾아보는 식으로 익혀야할 것 같다.
즉, 해당 글은 공통 부분에 대해서만 작성함
