
딥러닝이란?
우선 머신러닝 알고리즘이란 아주 짧게 말하자면 입력 데이터를 어떤 의미있는 출력 데이터로 변환한다고 할 수 있다. 딥러닝은 머신러닝이라는 틀안에 있는 특정한 한 분야로 연속된 층에서 점진적으로 의미있는 표현을 학습하는 방식이라고 한다. 연속된 층으로 학습을 한다는 것은 층이 곧 깊이를 의미하게 된다. 즉, 층 기반 표현 학습, 혹은 계층적 표현 학습 이라고 불리우기도 한다. 또한 딥러닝은 인공 신경망과 거의 동일하게 사용되는 경우가 많다. Deep Neural Network라고도 불리우며 심층 신경망은 여러개의 층을 가진 신경망을 의미한다.
인공신경망
다시 한번 말하지만 딥러닝과 인공신경망(ANN)을 거의 비슷한 의미로써 쓰인다. 인공 신경망은 보통 이미지를 분류하는 문제에 잘 맞는다. 그렇다면 인공 신경망은 어떻게 구성되어 있을까? 우선, 인공 신경망에는 입력층과 출력층이라는 것이 존재한다. 예를 들어 10개의 클래스 중 하나를 예측해야하는 문제에 대한 인공신경망이 있다고 하면, 총 10개의 클래스 중 하나를 예측해야하는 신경망 이기 때문에 출력층은 총 10개의 뉴런으로 구성되어있을 것이다.
반대로 입력층의 경우, 만약 이 신경망이 사진을 입력값으로 받아 분석을 한고, 사진 하나를 픽셀 별로 전부 쪼개고 한줄로 쭈욱 세웠을때 총 크기가 784인 배열이 나온다고 가정해보자. 입력값인 사진이 총 784개의 픽셀로 이루어져 있으므로 이 사진을 받기 위해 입력층은 784개로 구성되어 있을 것이다. 출력층에서 뉴런이라는 단어를 사용하였는데, 다른말로는 유닛이라고도 부르며 z 를 계산하는 단위를 의미한다.
매우 설명이 잘되어 있는 링크가 있어서 거기에 있는 자료를 통해 인공 신경망에 대한 정리를 해보고자 한다. 우선 아래의 그림을 보자!
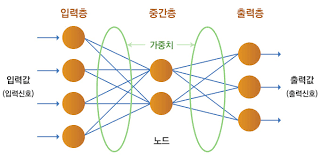
출력층의 값(z)을 만들기 위해 입력층의 값들에 가중치가 붙게 되고 절편이 붙어 z값을 형성하게 되는데, 이때 절편은 뉴런 마다 하나씩 있다. 이거를 좀더 가시성이 좋게 표현을 하자면 다음의 사진과 같을 것이다.

여기에서 활성화 함수라는 것이 나오는데, 활성화 함수는 무엇일까? 활성화 함수는 인공신경망 내부에서 입력 받은 데이터를 근거로 다음 계층으로 출력할 값을 결정하는 기능을 수행한다. 즉 활성화 함수는 종류가 정말 다양하고 , 어떤 종류의 활성화 함수를 이용하냐에 따라가서 모델의 성능에도 많은 변화가 생길 것이다. 우선 대표적인 몇개의 활성화 함수 종류들에 대해 살펴보자면 다음과 같다.
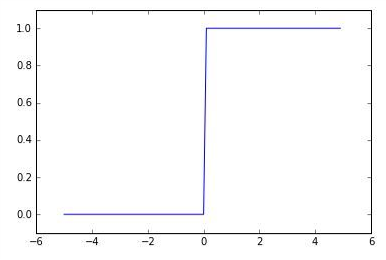
- 계단 함수: 활성화 함수의 가장 간단한 예시이며, 0또는 1의 결과를 출력한다. 하지만 x=0인 구간에서 미분이 불가능하여 가중치의 업데이트 과정에서 문제가 발생한다. 그래서 다일 퍼셉트론 활성화 함수로만 사용된다.
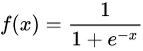
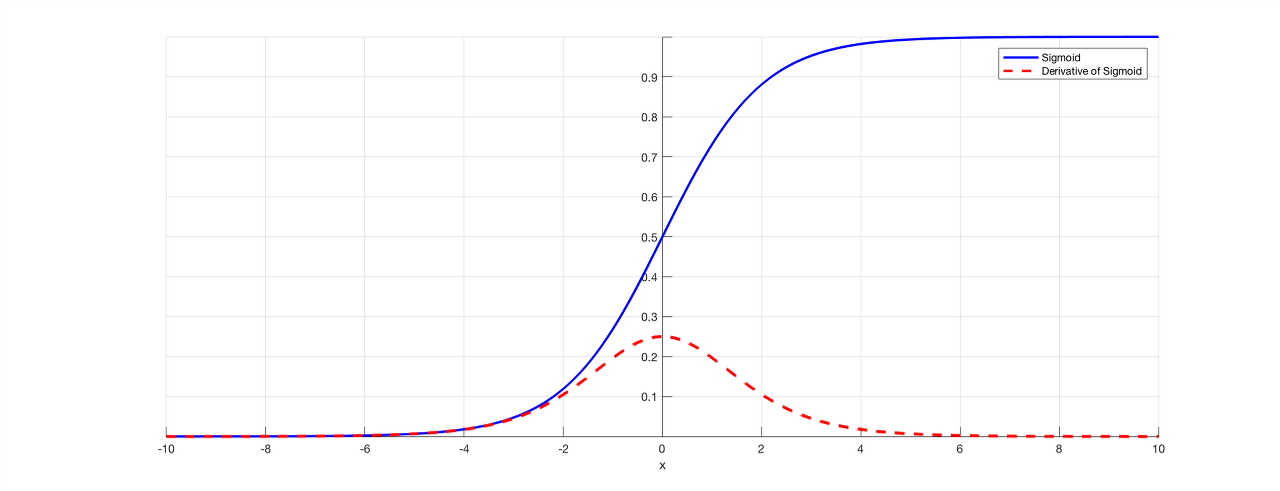
- 시그모이드 함수(Sigmoid): 시그모이드의 그래프를 보면 S자 형태를 가지고 있다는 것을 알 수 있다. 시그모이드 함수의 정의역은 실수 전체이지만 유한한 구간의 한정된 값을 반환한다. 시그모이드 함수에서는 정의여의 절대값이 커질 수록 미분 값이 0으로 수렴하고 이로 인해 가중치가 업데이트 되지 않는 기울기 소실 문제가 발생할 수 있으므로 은닉층의 활성화 함수로 사용하는 것은 별로 좋지 못하다.
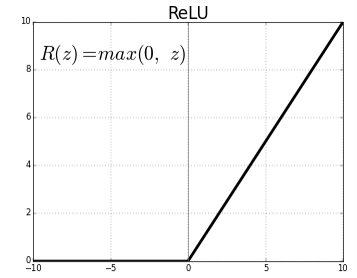
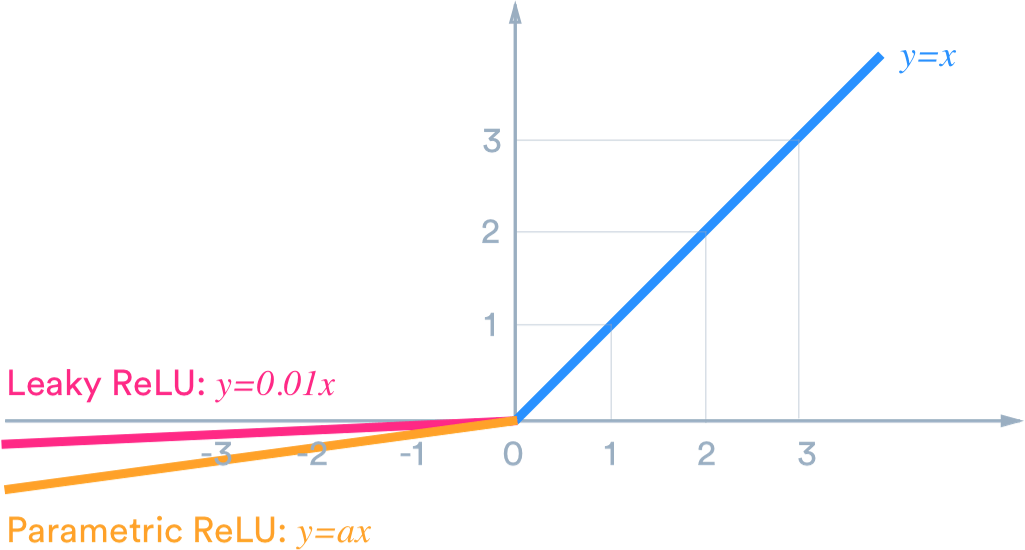
- ReLU: Rectified Linear Unit 의 줄임말로 입력값이 0보다 작으면 0 그렇지 않으면 입력값 그대로를 출력하는 함수이다. 시그모이드는 기울기 소실이라는 아주 치명적인 단점이 있는데 ReLU는 그러한 점을 보완하면서 매우 단순하지만서도 성능은 좋아서 아주 많이 사용된다. 하지만 가중합이 음수인 노드들은 다시 활성화되지 않는 dying Relu(dead neuron) 현상이 발생하기도 한다. 이를 보완하기 위한 0 이하의 값에서도 기울기를 가지는 LeakyReLu 같은 함수들도 존재한다.
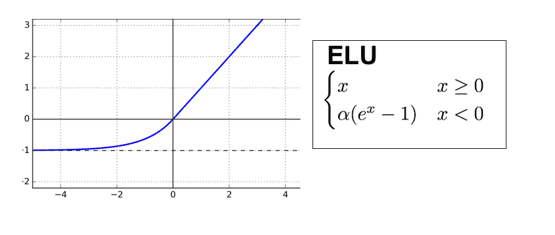
- ELU: Exponential Linear Unit은 Relu와 비슷하지만 입력값이 0인 지점에서도 미분할 수 있으며 0이하 입력의 모든 출력이 0이 아니라 0으로 수렴하는 형태의 함수이다. 그러므로 dying ReLU의 현상은 해결했으면서 ReLu의 장점은 모두 가져 딥러닝에서 자주 사용한다.
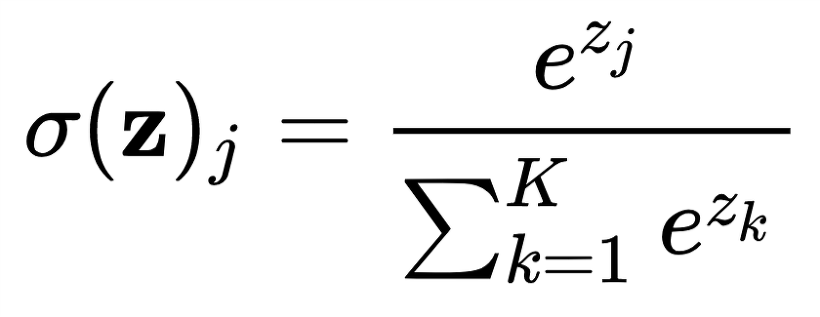
- Softmax: 소프트 맥스는 ,출력값이 0~1 사이로 정규화 되며, 모든 출력 값의 총합이 항상 1이 되는 특성을 가진 함수이다. 주로 인공 신경망의 출력층에서 사용되는데 다중 클래스를 분류하는 목적으로 사용된다.여러개의 클래스에 대해 예측한 결과를 정규화하여 확률값처럼 표현해준다.
텐서플로와 케라스를 이용한 딥러닝 모델 만들기
우선 텐서플로라는 라이브러리 이용하여 딥러닝 모델을 구축한다. 이 라이브러리를 불러오는 코드는 다음과 같다.
import tensorflow as tf텐서플로는 저수준 API와 고수준 API가 있는데 케라스가 바로 텐서플로의 고수준 API이다.
from tensorflow import keras모델을 구축하기 위해서는 기존에 머신러닝에서도 했다시피 데이터셋을 훈련 데이터셋을 검증 세트로 따로 나누어 사용한다. 왜 굳이 검증 데이터 셋을 만들어야 하는걸까? 몇가지 이유가 있는데 보통 머신러잉에서는 validation 데이터 셋을 이용하기도 하였지만, 교차 검증을 하는 경우를 자주 보았다. 교차 검증을 하는 이유에 대해서 생각해보면 대부분 데이터셋의 크기가 충분히 크지 않을 때를 대비하여 하던 것이었는데, 사실 딥러닝 모델의 데이터셋들은 대부분 데이터의 크기가 충분히 크기 때문에 교차 검증을 할 필요가 따로 없을 뿐더러 오히려 시간을 많이 잡아먹는 요인이 될 수 있다. 또한 데이터가 크다는 것은 검증 점수가 안정적으로 나온다는 뜻이기도 하기 때문이다.
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)위의 코드를 이용하면 데이터가 훈련 세트와 검증세트로 충분히 나뉘어지게 된다.
다음으로 수행해야 하는 작업은 입력층을 만드는 것이다. 입력층을 만들때 주의해야할 점은 입력 크기를 넣어줘야 한다는 것이다.
밀집층 = keras.layers.Dense(10, activation='softmax', input_shape(784,))위의 코드에서 괄호안의 첫번째 숫자는 뉴런 개수 혹은 unit이라고 불리우는 값이고 두번째는 위에서 설명한 활성화함수들 중 하는 넣은 구간이다. 그 다음으로 넣어야 하는 것이 입력의 크기이고, 자신의 데이터 셋의 입력 크기를 넣어주면 되는 것이다. 위의 밀집층에 대해 살펴보자면 총 784개의 입력 데이터가 들어오게 되고 이는 softmax라는 활성화 함수를 거쳐 뉴런이 출력 될 것인데 총 10개의 뉴런이 출력되는 층이라는 의미라고 생각해 볼 수 있을 것 같다. 이를 가지고 모델을 마저 구축하기 위해 다음의 코드 처럼 레이어를 넣어주면 된다.
model = keras.Sequential(밀집층)이런식으로 모델을 구성하였으면 우리는 컴파일링이라는 작업을 해주어야 한다. 즉 훈련을 하기전에 하나의 단계를 더 거쳐야 하는데, 우선 코드를 살펴보면 다음과 같다.
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])우선 손실함수에 대해 먼저 설명을 간단하게 해보자면, 손실함수는 실제값과 예측값의 차이를 수치화 해주는 함수이다. 오차가 클 수록 손실 함수의 값이 크고 오차가 작을 수록 손실함수의 값이 작다. 몇가지 종류가 있는데 간단하게 알아보면 다음과 같다.
분류 문제의 경우
이진 분류: 'binary_crossentropy' --> 출력층에서 시그모이드를 이용하는 이진 분류의 경우 사용
다중 분류: 'sparse_categorical_crossentropy' --> 출륵층에서 소프트맥스 함수를 사용하는 다중 클래스 분류의 경우 사용
회귀 문제의 경우
MSE: 연속형 변수를 예측할 때 이용
MAE: 동일
그렇다면 optimizer은 뭐하는 녀석일까? 를 생각해보았을 때 손실함수는 도구라고 생각하면 될 거 같다. 무슨 함수를 써서 오차의 값을 최소화 시킬지를 정했으니 이 손실함수를 어떻게 이용할지에 대한 것이 바로 옵티마이저인것이다. 옵티마이저에도 정말 많은 종류가 있는데, 모멘텀, 아다그라드, RMSprop, adam 등이 있다. 상황에 맞춰 적절하게 이용하면 된다.
metrics는 평가지표를 의미하는 것이다.
과정이 매우 길었지만 이제 정말로 모델을 학습 시키면 된다.
model.fit(train_scaled, train_target, epoch=10)여기서 epoch 라는 것은 몇번 돌릴거냐~ 라는 것을 의미한다. 물론 많이 만들면 좋지만 그만큼 시간도 매우 늘어난다. 에포크를 많이 돌린다고 해서 성능이 항상 향상하는 것은 아니다. 그렇다면 시간도 낭비되고 컴퓨터 자원도 낭비되는 상황이 나오게 된다. 그럴때 사용할 수 있는 방법이 Earlystopping이다.
early_stop = EarlyStopping(monitor='val_loss', patience=3)
history = model.fit(train_scaled, epochs=20, validation_data=val_scaled, callbacks=[early_stop])위의 코드의 의미는 validation loss를 기준으로 3번의 에포크를 돌때 개선이 일어나지 않으면 모델을 fitting 끝내라는 의미이다.
이제 드디어 모델 학습이 끝났으므로 결과를 확인하고자 한다. 이는 매우 간단하다.
model.evaluate(val_scaled, val_target)을 실행하면 된다. 좀더 직관적으로 시각화하여 손실과 정확도가 어떤식으로 진행되었는지를 확인하고자 한다면 다음처럼 시각화하는 것도 한 방법이 될 수 있을 것 같다.
df_hist = pd.DataFrame(history.history)
fig, axes = plt.subplots(1,2,figsize = (15,4))
df_hist[['loss','val_loss']].plot(ax=axes[0])
df_hist[['accuracy','val_accuracy']].plot(ax=axes[1])그러면 아주 이쁘게 그래프 형식으로 데이터셋 종류(학습, 검증)별 손실함수와 정확도를 선그래프로 확인해볼 수 있을 것이다.
심층신경망
당연히 레이어를 하나만 만들 수 있는 것은 아니고 여러 층을 만들어 줄 수 있는데 이를 심층 신경망이라고 한다. 층을 추가하는 방법에는 몇가지가 있는데 우선 한가지 방법에 대해 소개를 하자면 다음과 같이 할 수 있을 것이다
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,) , name='출력층'),
keras.layers.Dense(32, activation='relu', name='히든충'),
keras.layers.Dense(10, activation='softmax', input_shape=(784,), name='아웃풋')])안의 레이어와 활성화함수는 원하는 대로 구성하여 모델을 구축할 수 있다.
여기 까지가 딥러닝에 관한 내용이다.
