1. 개요
파일을 인덱싱하고 키워드 검색으로 파일을 찾을 수 있는 검색엔진을 검토했다.
Elasticsearch와 Solr가 검토대상이며, 나는 Solr를 맡아 진행했다.
실행 환경/버전은 다음과 같다.
CPU: 8Core
MEM: 8GB
Solr Version: 9.4
Arch: Apple Silicon M1
2. 확인 및 검증사항
- PDF 파일 인덱싱 소요시간
- 키워드 존재 여부에 따른 검색속도 차이
- 언어별 검색 속도 차이(한국어, 영어, 한국어+영어)
3. 설치 및 실행
3.1 Solr 홈페이지에서 다운로드/실행
홈페이지를 통해 다운로드 받아 설치/실행시킬 수 있다.
https://solr.apache.org/guide/solr/latest/getting-started/tutorial-five-minutes.html
3.2 도커로 다운로드/실행
간단하게 도커파일을 작성하여 실행시킬 수 있다.
# docker-compose.yml
version: "3"
services:
solr:
image: solr:9.4
ports:
- "8983:8983"
volumes:
- ./data:/var/solr
environment:
- SOLR_OPTS=-Dsolr.modules=extraction
command:
- solr-precreate
- mycore$ docker-compose up -d3.3 파일 업로드 enable
PDF, Word등 파일을 이용한 색인이 필요할 경우, 해당 기능을 사용하겠다는 설정이 필요하다.
$ curl -X POST -H 'Content-type:application/json' -d '{
"add-requesthandler": {
"name": "/update/extract",
"class": "solr.extraction.ExtractingRequestHandler",
"defaults":{ "lowernames": "true", "captureAttr":"true"}
}
}' 'http://localhost:8983/solr/{your core or collection}/config'- {your core or collection}: solr는 core 혹은 collection이라는 논리적으로 구분된 영역을 사용한다. (github repo처럼)
- docker-compose로 실행시켰을 경우, mycore를 넣어주면 된다.
- 파일 업로드 시 내부적으로는 Apache Tika를 사용함
4. 인덱싱(색인)
curl 'http://localhost:8983/solr/mycore/update/extract?literal.id=doc8&commit=true' -F "myfile=@pdfs/A.pdf"또는
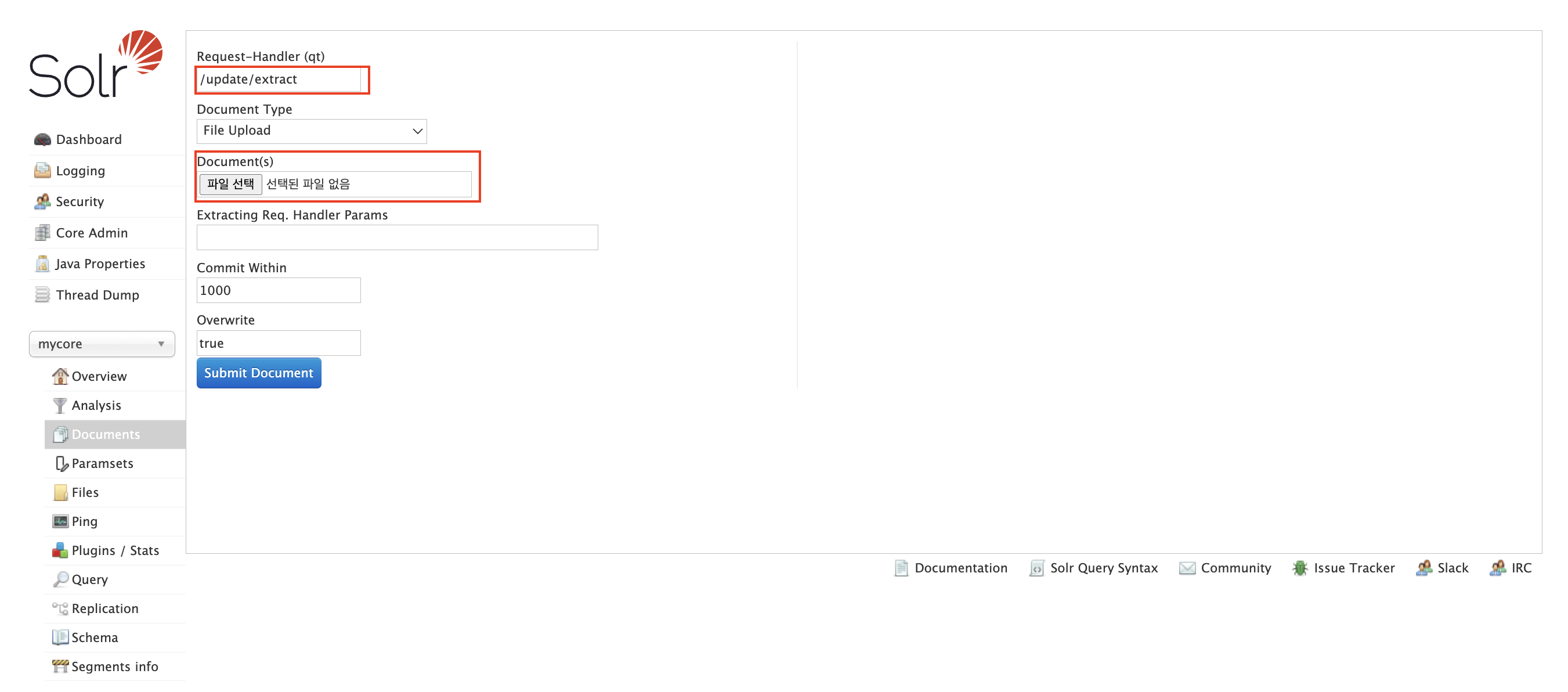
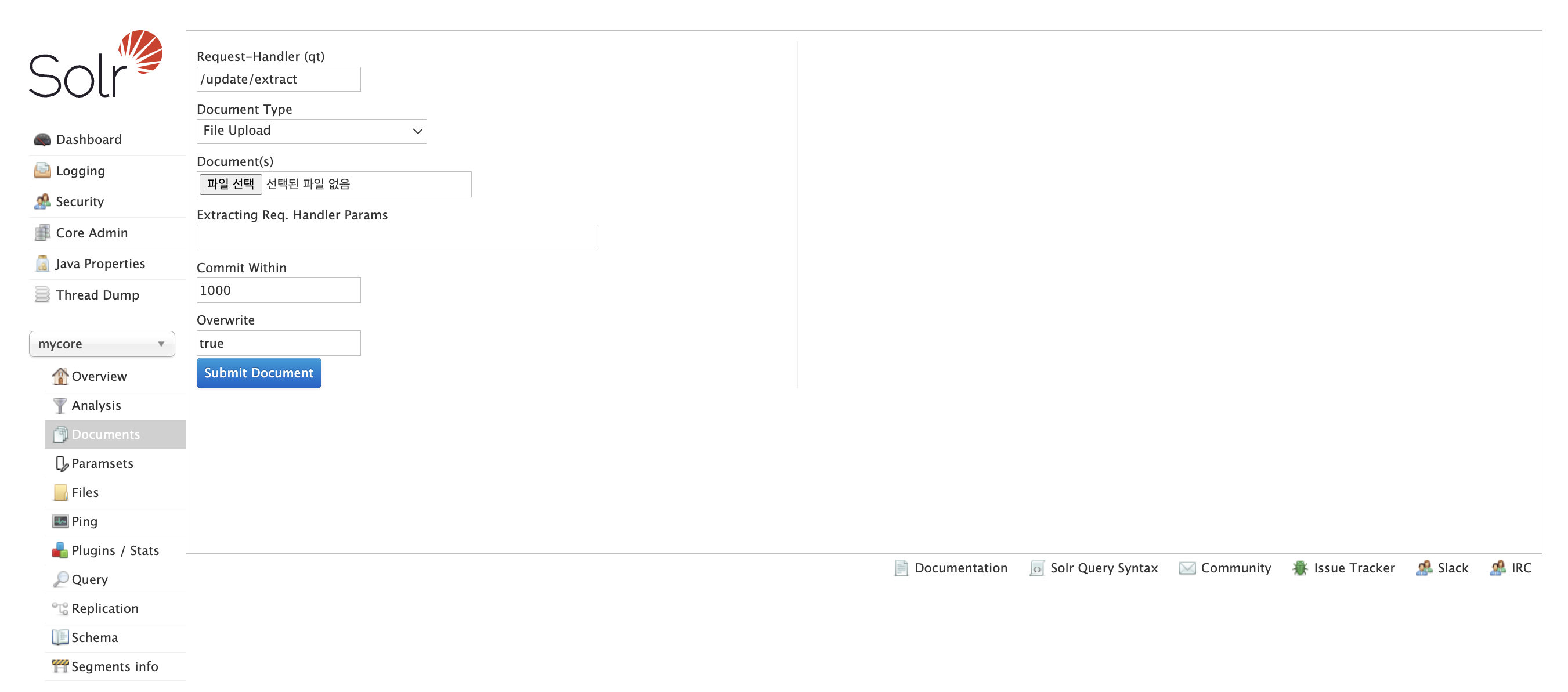
- curl 또는 solr admin ui를 활용하여 파일을 업로드할 수 있다.
- Request-Handler (qt)는 3.3에서 설정한 name과 일치해야한다.
- Extracting Req. Handler Params에
literal.id=doc100처럼 커스텀 필드를 추가할 수 있다.
인덱싱 결과
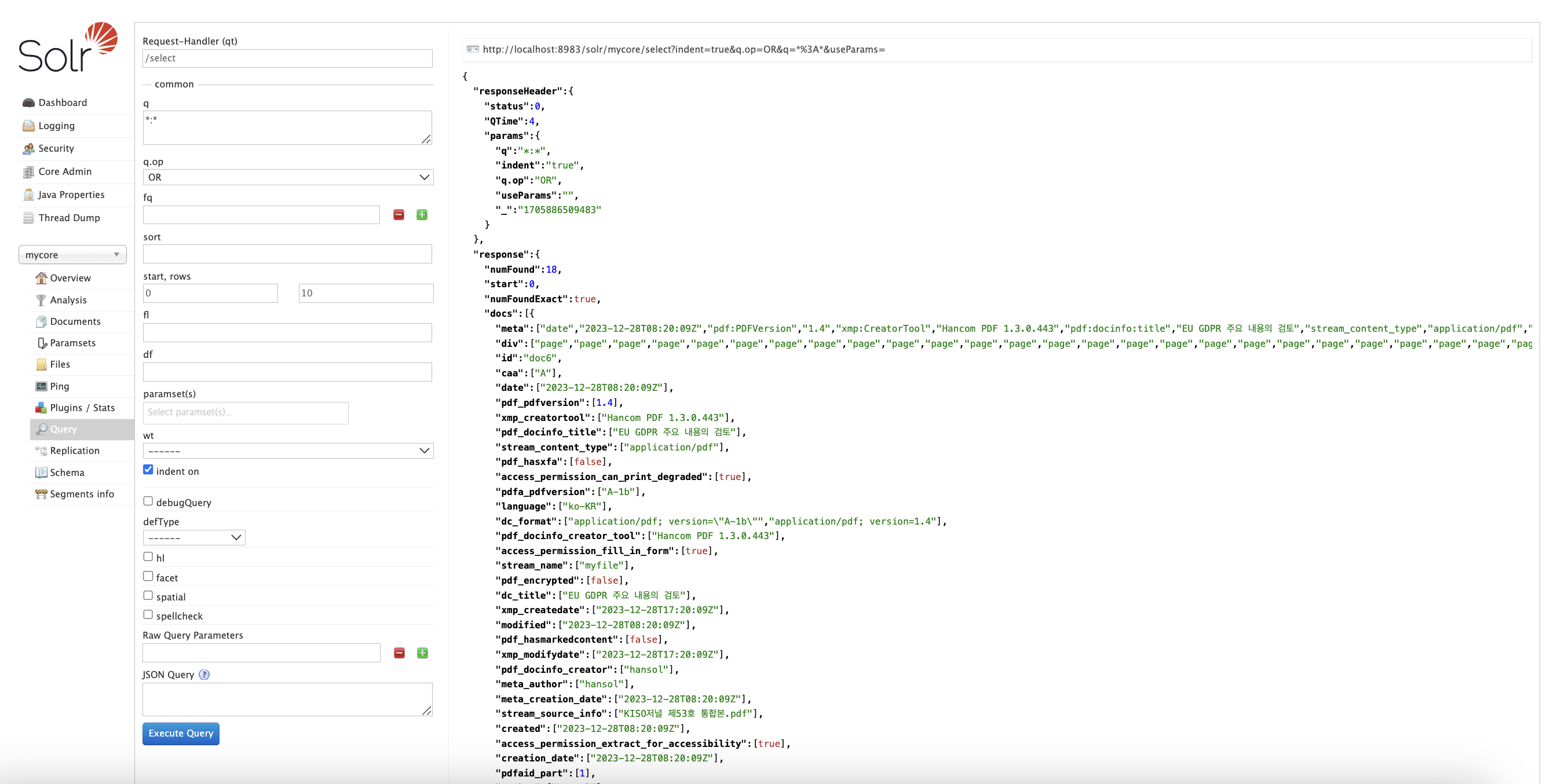
5. 검색
5.1 curl로 검색하기
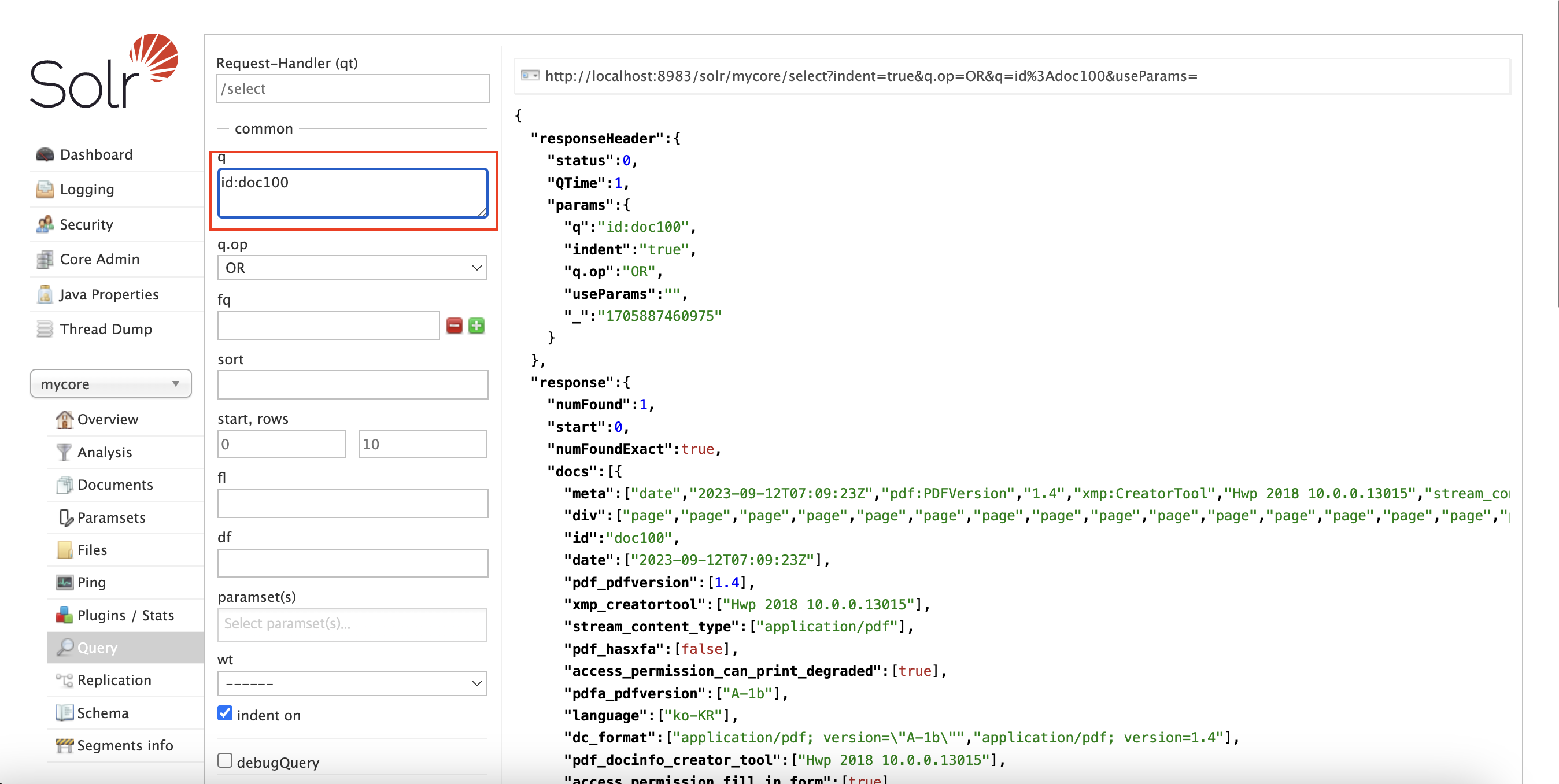
(id = doc100이라는 데이터가 존재한다고 가정)
$ curl 'http://localhost:8983/solr/mycore/select?q=id%3Adoc100'- mycore라는 core에 등록된 Document 중, id가 doc100인 데이터 질의
5.2 Solr admin ui로 검색하기
문장 검색 시
- 문장을 ""로 감싸서 검색 (ex, "CAS latencty")
복합 검색 시
+prefix를 활용하면 반드시 포함으로 조건으로 검색-prefix를 활용하면 포함하지 않는 조건으로 검색- ex) +content:챗봇 -content:10대 => 챗봇은 포함, 10대는 제외하여 검색
검색 파라미터 활용
fi(file list): 응답에 보여줄 필드 설정fq(filter quert): 추가적인 필터 조건, 검색 결과를 좁히는데 사용df(default field: 검색 문자열에 필드가 지정되지 않은 경우, 기본 검색 필드 설정wt(writer type): 결과를 반환할 때 사용하는 출력형식
6. 인덱스/검색 소요시간 측정
6.1 인덱스(색인) 소요시간
| 파일 명 | 용량 | 소요시간(s) |
|---|---|---|
| 2023년 11월 경제전망보고서(Indigo Book).pdf | 9.7MB | 1.5 |
| 사이코패스 성향과 공감능력 및 공격성의 관계.pdf | 878KB | 0.7 |
| 상온상압 초전도체(LK-99) 개발을 위한 고찰.pdf | 4.2MB | 0.5 |
| 정보 미디어 선택과 편향 동원.pdf | 2.4MB | 0.8 |
| KCI_FI001027705.pdf | 2.0MB | 0.5 |
| KISO저널 제53호 통합본.pdf | 2.2MB | 0.9 |
| MZ 세대 교원의 자기계발에 관한 질적 연구 = A Qualitative Study on the Self-improvement of the MZ Generation Teachers.pdf | 840KB | 0.8 |
| RE-154_2023년 SW산업 10대 이슈전망.pdf | 1.8MB | 1.2 |
| World Public Sector Report 2023.pdf | 7.0MB | 2.0 |
⇒ 평균 2.0초 내로 인덱싱
6.2 키워드 존재 여부에 따른 질의 속도 차이
존재 하는 키워드 질의
| 키워드 | 소요시간(ms) |
|---|---|
| 맥북 | 4 |
| 사기 | 2 |
| 청소년 | 3 |
| 주류 | 3 |
| 논문 | 1 |
| free | 27 |
| money | 2 |
| school | 10 |
존재하지 않는 키워드 질의
| 키워드 | 소요시간(ms) |
|---|---|
| GSFIE | 2 |
| 민호 | 10 |
| 사무실 | 2 |
| 가습기 | 5 |
| 거북이 | 12 |
| elasticsearch | 13 |
| dockercompose | 1 |
| springboot | 9 |
6.3 언어별 질의 속도 차이
“사이코/psychopath” 검색
| 언어 | 키워드 | 소요 시간(ms) - 1차 | 소요 시간(ms) - 2차 | 소요 시간(ms) - 3차 |
|---|---|---|---|---|
| 한국어 | 사이코 | 8 | 6 | 0 |
| 영어 | psychopath | 8 | 1 | 0 |
| 한국어+영어 | 사이코패스+psychopath | 59 | 4 | 4 |
“챗봇/data” 검색
| 언어 | 키워드 | 소요 시간(ms) - 1차 | 소요 시간(ms) - 2차 | 소요 시간(ms) - 3차 |
|---|---|---|---|---|
| 한국어 | 챗봇 | 7 | 1 | 6 |
| 영어 | data | 24 | 4 | 0 |
| 한국어+영어 | 챗봇+data | 5 | 8 | 4 |
“산업/SW” 검색
| 언어 | 키워드 | 소요 시간(ms) - 1차 | 소요 시간(ms) - 2차 | 소요 시간(ms) - 3차 |
|---|---|---|---|---|
| 한국어 | 산업 | 14 | 16 | 16 |
| 영어 | SW | 4 | 2 | 1 |
| 한국어+영어 | 산업+SW | 4 | 3 | 1 |
7. 마치며
Solr의 복잡한 설정과 옵션들이 처음에는 어렵게 느껴졌지만,
다양한 커스텀 옵션을 제공하는 점이 인상적이었고, 익숙해진다면 여러 방면으로 사용할 수 있을 것 같다는 생각이 들었다.
튜토리얼을 수준으로 사용해봤지만 업무에서 이를 활용하거나 검색 엔지니어가 되고자 한다면, 흥미롭게 학습하고 사용할 수 있을 것 같다.
Reference

여러 기술을 학습하고 응용하는 것을 좋아합니다. 나무보다 숲을 보려합니다 :)