코루틴 관련 기술서적 스터디를 시작하게 되었다 📚
이 글은 스터디 후기는 아니고, 앞으로 책을 읽으며 정리한 내용과 스터디를 진행하며 추가적으로 알게된 내용을 기록하고자 한다 !
넥스터즈 라는 동아리를 작년 여름 17기부터 현재까지 해오고 있다. ( 개인적으로 참 많은 걸 배우고 성장하고 자극받을 수 있었다고 생각해서 강추 ! )
이번 7-8월에 진행되는 19기 활동도 참여하고 있는데, 이번 기수에 '코틀린 동시성 프로그래밍' 이라는 기술 서적 스터디가 개설되었다 ! 사실 그 동안 나는 Rx보다 오히려 코루틴을 더 많이 사용해왔고, 그 과정에서 Kotlin, Android 공식 문서나 그 외의 레퍼런스도 많이 읽고 공부를 했지만 같이 프로젝트를 진행하는 팀원이 코루틴이 처음이라고 설명해달라고 하자 명확하게 설명을 할 수가 없었다.🤯 그래서 이 기회에 확실하게 코루틴을 알아보자는 마음에서 스터디에 참여하게 되었다.
책이 약간 번역이 어색한 부분은 당연히 있지만 공식문서나 공식문서를 번역한 타 블로그들보다 설명이 자세히 이해하기 쉽게 되어있었고, 그럼에도 명확하게 이해가 안되고 그림이 그려지지 않는 설명은 스터디를 진행하며 질문도하고 다른 스터디원의 질문에 대답도 하며 조금씩 더 그림이 그려지는 것 같았기 때문이다 ! 완독했을 때 코루틴을 완전하게 이해할 나를 기대하며 🤓
간단히 이 포스팅이 시작된 얘기를 해보았다. 이제부터 작성할 내용은 1장에 대한 내용이다. 1장에서는 동시성을 논하기 위한 개념 정리 그리고 코틀린이 동시성을 다루는 방법에 대한 개요를 담고있다.
프로세스와 스레드, 그리고 코루틴
-
프로세스 : 실행중인 애플리케이션의 인스턴스
- 프로세스는 스레드를 가지며 내부의 스레드들은 프로세스의 상태에 접근 가능
멀티 프로세스는 이 책에서 다루지 않음. 즉 멀티 스레드 환경만을 다룬다는 이야기
-
스레드 : 프로세스 내의 명령 실행 단위
- 프로세스는 최소 하나의 스레드를 가진다. 이는 Main Thread로 어플리케이션의 엔트리 포인트가 된다. 이는 당연하게도 프로세스의 라이프사이클과 밀접하다.
- 스레드 내에서는 한 번에 한 명령씩 실행된다. 그러므로 UI thread 블로킹하면 안돼 !
-
코루틴 : 경량 스레드 (lightweight thread)
- 코루틴은 스레드 내에서 실행된다. 따라서 한 스레드에 여러 코루틴이 존재할 수 있지만, 실제로는 한 번에 하나의 코루틴만 실행된다.
- 스레드 vs 코루틴 : 코루틴이 빠르게 적은비용(적은자원)으로 생성할 수 있다.
- 코틀린은 고정된 크기의 스레드 풀을 사용하고 코루틴을 스레드들에 배포한다.
- 코루틴이 특정 스레드 안에서 실행되더라도 스레드와 묶이지 않는다. 즉 실행 가능한 쓰레드로 코루틴을 이동시킨다.
- 그치만 개발자가 코루틴을 실행할 스레드 지정할 수 있고, 해당 스레드로만 제한할 수도 있다.
코루틴을 lightweight thread라고 하는 것이 별로 좋지않은 것 같다는 스터디원의 의견이 있었다.
코루틴이 실제로는 object이기 때문에 혼란을 줄 수 있는 워딩이기 때문이라고 설명해주었다.
동시성이 뭔데 ?
동시성은 어플리케이션이 동시에 하나 이상의 스레드에서 실행될 때 발생된다. 즉 동시성이 발생하려면 두 개 이상의 스레드가 생성되어야 한다. 또한 동시성 상황에서 스레드간의 통신 및 동기화는 필수적이다 !
동시성이란 입력에 대해서 늘 최종적으로 같은 결과를 내놓지만 그 과정의 실행순서는 유연성이 있는 것을 의미한다
동시성을 사용하는 이유 ? 성능 !!!! 효율성 !!!! 속도든 자원이든 !!!!
동시성 VS 병렬성
동시성은 두 개 이상의 실행이 겹쳐질 때 발생한다. 두 개 이상의 실행 스레드가 필요하다. 하지만 단일 코어에서 실행되면 실제로 병렬적으로 실행될 수는 없다. 단지 스레드들의 실행이 효율적이도록 교차 배치하는 것이다.
병렬은 두 개 이상의 실행이 같은 시점에 실행되는 것이다. 즉 두 개 이상의 스레드가 필요할 뿐만 아니라 두 개 이상의 코어도 필요하다.
CPU 바운드 그리고 I/O 바운드 알고리즘
1. CPU바운드 : CPU 연산 작업을 중심으로 이루어진 알고리즘은 CPU 성능에 의존적
- 단일 코어에서 동시성을 구현하는 경우 context swtiching에 의해 오버헤드 발생으로 오히려 성능 저하 가능성이 있다.
- 반면 세 개의 쓰레드로 동작하는 알고리즘에 대해서 멀티 코어 머신에서 병렬성으로 구현한다면 약 3분의 1로 실행 성능 향상될 수 있다.
- CPU 바운드 알고리즘의 경우 코어수를 기준으로 적절한 스레드를 생성해야 함
( kotlin common pool : 코어수 -1 )
2. I/O 바운드 : read/write 같은 입출력 연산으로 이루어진 알고리즘은 외부 시스템이나 장치에 의존적
( 하드드라이브에 저장되었는지 SSD에 저장되었는지, 네트워킹이나 주변기기로 입력을 받는 경우 등 )
- I/O 바운드 알고리즘은 대기가 많이 발생하기 때문에 대기 시간을 활용할 수 있도록 단일 코어에서 동시성 구현에도 성능 개선이 있음 !
동시성이 어려운 이유
1. 레이스 컨디션 : 동시성으로 작성한 코드가 항상 특정한 순서로 동작할 것이라고 가정하면 발생하는 문제로 동시성 코드 일부가 제대로 작동하기 위해 일정한 순서로 완료돼야 할 때 발생한다.
( 이것은 동시성 코드를 구현하는 올바른 방법이 아니다 ! )
- 예제처럼 초기화가 안된 것 뿐 아니라, 동기화 문제도 발생 가능
data class UserInfo(val name : String, val lastName : String, val id : Int)
lateinit val user : Userinfo
fun main(args : Array<String>){
asyncGetUserInfo(1)
// Do some other operation
delay(1000)
println("User ${user.id} is ${user.name}")
}
fun asyncGetUserInfo(id : Int){
user = UserInfo(id = id, name = "Susan", lastName = "Calvin")
}위의 예시 코드는 유저 정보를 할당하는 코드가 프린트보다 먼저 수행되는 것이 보장돼야만 하는 코이다. delay(1000)으로 문제 없이 동작하는 것 처럼 보이지만, 만일 아래와 같이 함수를 수정한다면 문제가 발생할 것이다.
fun asyncGetUserInfo(id : Int){
delay(1100)
user = UserInfo(id = id, name = "Susan", lastName = "Calvin")
}2. 원자성 위반
- 원자성 작업 : 작업이 사용하는 데이터를 간섭없이 접근할 수 있음.
- 단일 스레드는 순차 진행이므로 모든 작업이 원자이지만, 동시성 작업에서는 객체의 상태가 동시에 수정될 수 있으므로 그렇지 못함을 보장해야 함.
- 예시로 변수의 값을 증가시키더라도 읽고, 더하고, 저장하는 세부 연산들이 있으므로 원자성 보장 필요
val counter = 0
fun main(args : Array<String>){
val workerA = asyncIncrement(2000)
val workerB = asyncIncrement(100)
workerA.await()
workerB.await()
print("counter : $counter ")
}
fun asyncIncrement(by : Int){
for(i in 0 until by){
counter++
}
}위의 결과는 2100이어야 할 것 같지만, 2100보다 작은 값을 출력하기도 한다. 그런 경우는 아래의 그림과 같은 상황으로 원자성이 위반된 경우인 것이다.
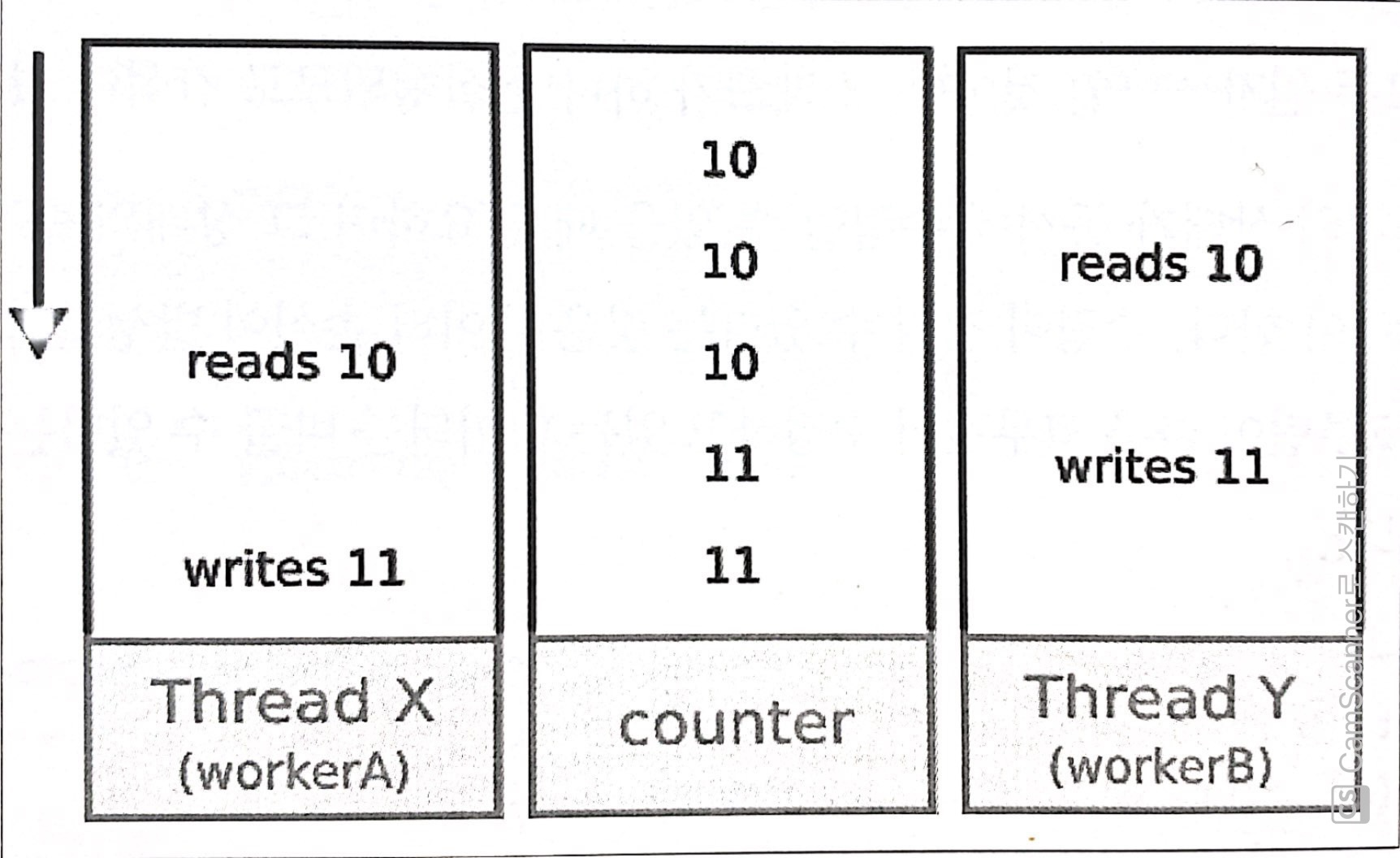
3. 교착 상태 : 동기화를 위해 다른 스레드의 작업이 완료되는 동안 실행을 일시 중단하거나 차단하는 등의 의존이 발생할 때, 순환적 의존이 발생하여 애플리케이션의 실행이 중단되는 상황이 발생할 수 있다.
- 레이스 컨디션과 같이 자주 발생함 ( 순서 / 의존 )
lateinit val jobA : Job
lateinit val jobB : Job
fun main(args : Array<String>){
jobA = GlobalScope.launch{
delay(1000)
jobB.join()
}
jobB = GlobalScope.launch{
jobA.join()
}
jobA.join()
println("finished")
}위와 같은 코드를 살펴보면 jobA의 스코프가 실행되고 잠시 delay하는 동안 jobB 스코프가 실행된다. 이 때, jobA는 jobB를 대기하고, jobB는 jobA를 대기하느라 서로 종료되지 못하는 경우가 발생한다. main 역시 jobA를 대기하고 있기 때문에 모든 흐름이 다 종료되지 못하고 무한 대기가 발생하는 것이다.
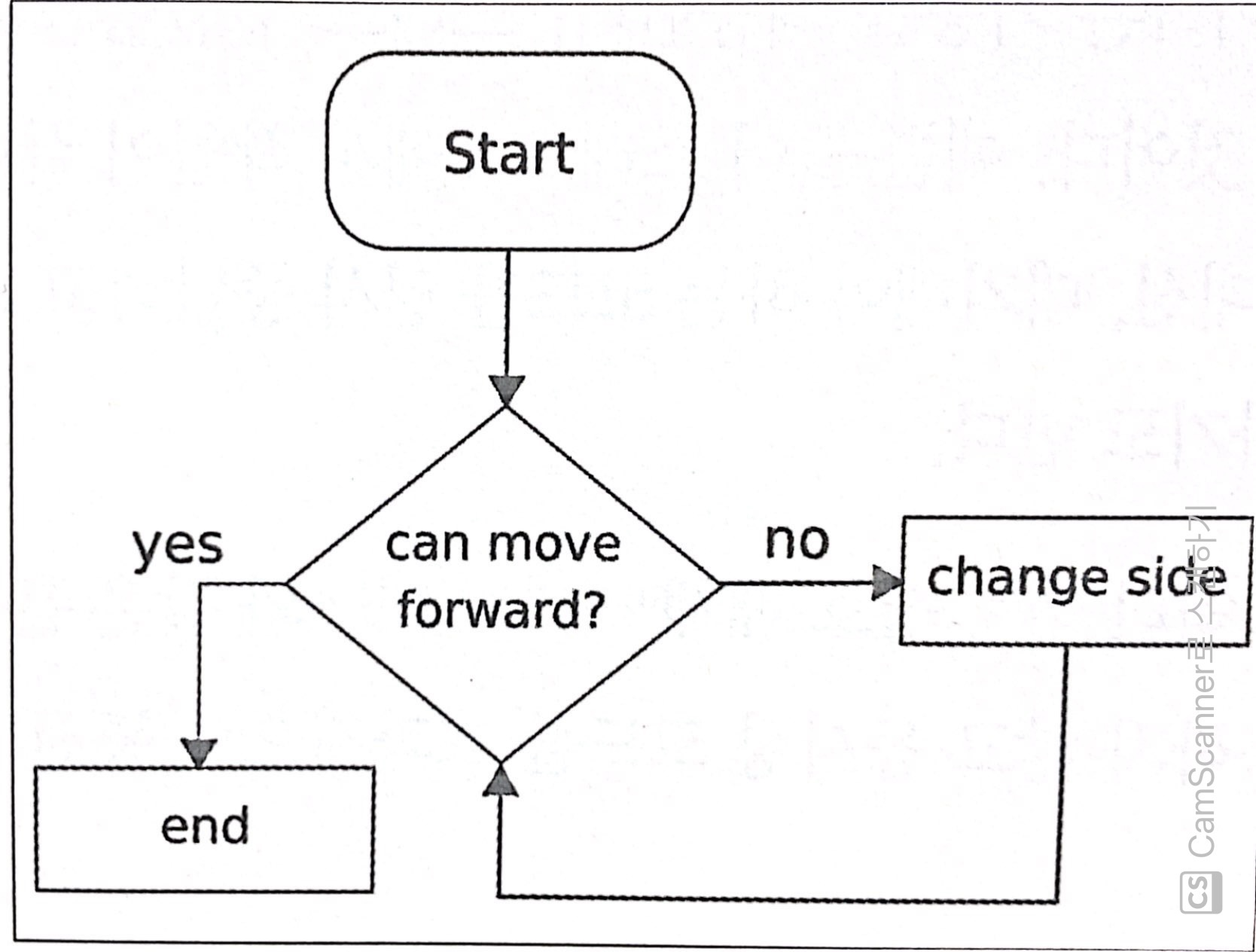
4. 라이브 락 : 애플리케이션의 상태는 지속적으로 변하지만 정상 실행으로 돌아오지는 못하는 교착상태
- 교착상태를 복구하려는 수정이 라이브락을 발생시키는 경우가 많다.
책에서는 라이브 락을 이해하기 쉽게 복도에서 두 사람이 마주쳤을 때, 서로 피하려고 같은 방향으로 계속해서 움직이는 경우의 예를 들고 있다. 이 예시를 흐름도로 보면 아래와 같다.
코틀린에서의 동시성
코틀린에서의 동시성의 특징들은 아래와 같다 ! 특히 논블로킹 특성이 중요하다고 생각한다 !
1. 논블로킹 💡
: 코틀린에서는 suspendable computation을 통해 스레드의 실행은 블로킹하지 않으면서 실행을 잠시 중단할 수 있다.
- 즉, 스레드 X가 스레드 Y의 작업이 끝나길 기다리려면 스레드 X를 블로킹하지 않고 대기하며, 스레드 X를 다른 연산에 사용하는 것
- 코틀린은 channels, actors, mutual exclusions와 같은 것을 제공하여 스레드를 블로킹하지 않고 동시성 코드를 효과적으로 동기화하는 메커니즘을 제공 ( 뒤의 장에서 자세히 다룬다고 합니다 ~ )
- suspend는 다른 스레드에서 실행할 메소드를 호출한 뒤 정보를 처리하기 전에 완료를 기다림. 그치만 스레드는 블로킹되지 않고 다른 실행에 활용됨.
2. 기본형 활용
코틀린에서는 동시성 코드를 쉽게 구현할 수 있는 고급 함수와 기본형을 제공한다.
- 스레드 생성 : newSingleThreadContext(thread_name)
- 스레드 풀 : newFixedThreadPoolContext(size, thread_pool_name)
- common pool : CPU 바운드 작업에 최적인 쓰레드 풀, 최대값은 (코어의 수 - 1)
- 코루틴을 다른 스레드로 이동시키는 것은 런타임이 담당
이 외에도 유연하게 동시성을 사용하게끔 도와주는 기본형들이 존재하는데, 앞으로 책에서 다룰 주제들이라고 생각하면 좋을 것 같다.
- 채널 channels : 코루틴간에 데이터를 안전하게 보내고 받는데 사용하는 파이프
- 작업자 풀 worker pools : 많은 스레드에서 연산 집합의 처리를 나눌 수 있는 코루틴의 풀
- 액터 actors : 채널과 코루틴이 사용하는 상태를 감싼 래퍼로 여러 스레드에서 상태를 안전하게 수정할 수 있는 메커니즘 제공
- 뮤텍스 mutexes : critical section을 정의해 한 번에 하나의 스레드만 접근할 수 있도록하는 동기화 메커니즘을 제공. 크리티컬존에 어떤 코루틴이 접근하려 하면 이전 코루틴이 빠져나올 때 까지 일시 정지
- 스레드 한정 thread confinement : 코루틴을 지정된 스레드에서만 실행하도록 하는 것
- 생성자 : 필요에 따라 정보를 생성할 수 있고, 새로운 정보가 필요하지 않을 때 일시 중단될 수 잇는 DataSource
모두 뒤의 장에서 더 자세히 나오고, 1장에서는 간단하게 느낌과 개념만 잡고 넘어가는 ~
코틀린 동시성 관련 개념 및 용어
1. 일시 중단 연산 : 해당 스레드를 차단하지 않고 실행을 일시 중단하는 연산. 해당 스레드는 다른 연산에 할당
- 이는 다른 suspend function이나 코루틴에서만 호출 가능 !
2. 일시 중단 함수 : 함수 형태의 일시 중단 연산. (내부 동작 원리는 뒤에 나옴 ! 9장 !)
- suspend 제어자 사용
suspend fun greetAfter(name : String, delayMillis : Long){
delay(delayMillis)
println("Hello, $name")
}위의 함수는 delay가 호출될 때, 일시 중단된다. 또한 아래에서 볼 수 있듯이 delay를 까보면 이도 suspend function임을 알 수 있다. 그러므로 일시중단되는 동안 스레드는 다른 연산을 수행하는 데에 사용될 수 있으며, delay가 완료되면 greetAfter의 실행이 이어진다.
public suspend fun delay(timeMillis: Long) {
if (timeMillis <= 0) return // don't delay
return suspendCancellableCoroutine sc@ { cont: CancellableContinuation<Unit> ->
cont.context.delay.scheduleResumeAfterDelay(timeMillis, cont)
}
}3. 람다 일시 중단 : 다른 일시 중단 함수를 호출할 수 있고, 자신의 실행을 중단할 수 있는 람다
4. 코루틴 디스패처 : 코루틴을 시작하거나 재개할 스레드를 결정하는 역할
-
CoroutineDispatcher 인터페이스 구현
-
디스패처 종류
1. DefaultDispatcher : 말 그대로 기본 디스패처, 현재는 CommonPool이고 바뀔 수 있음
2. CommonPool : 공유된 백그라운드 스레드풀에서 코루틴을 실행하고 다시 시작한다.
3. Unconfined : 현재 스레드에서 코루틴을 시작하지만 어떤 스레드에서도 코루틴이 재개될 수 있음. -
디스패처와 풀/스레드를 생성하는 빌더
1. newSingleThreadContext() : 단일 스레드로 디스패처 생성, 여기에서 실행되는 코루틴은 항상 같은 스레드에서 시작 및 재개
2. newFixedThreadContext() : 지정된 크기의 스레드풀이 있는 디스패처 생성, 디스패처에서 실행된 코루틴을 시작 및 재개할 스레드 결정은 런타임이
5. 코루틴 빌더 : 코루틴을 생성 및 실행
- async() : 결과 혹은 예외를 담고있는 Defrred를 반환하는 코루틴을 시작
- launch() : 결과를 반환하지 않는 코루틴을 시작. Job을 반환하는데 이는 자기 자신 혹은 자식 코루틴의 실행을 취소하는 데에 사용
- runBlocking() : 코루틴의 실행이 끝날 때까지 현재 스레드 차단, 해당 스레드를 중지시키고 코루틴을 실행시킨다는 것
대표적으로 async의 예제를 살펴보면 아래와 같고, 아래에서 볼 수 있듯이 디스패처를 수동으로 지정할 수도 있다.
val result = GlobalScope.async{
isPalindrome(word = "Sample")
}
result.await()
val result = GlobalScope.async(Dispatchers.Unconfined){
isPalindrome(word = "Sample")
}
result.await()