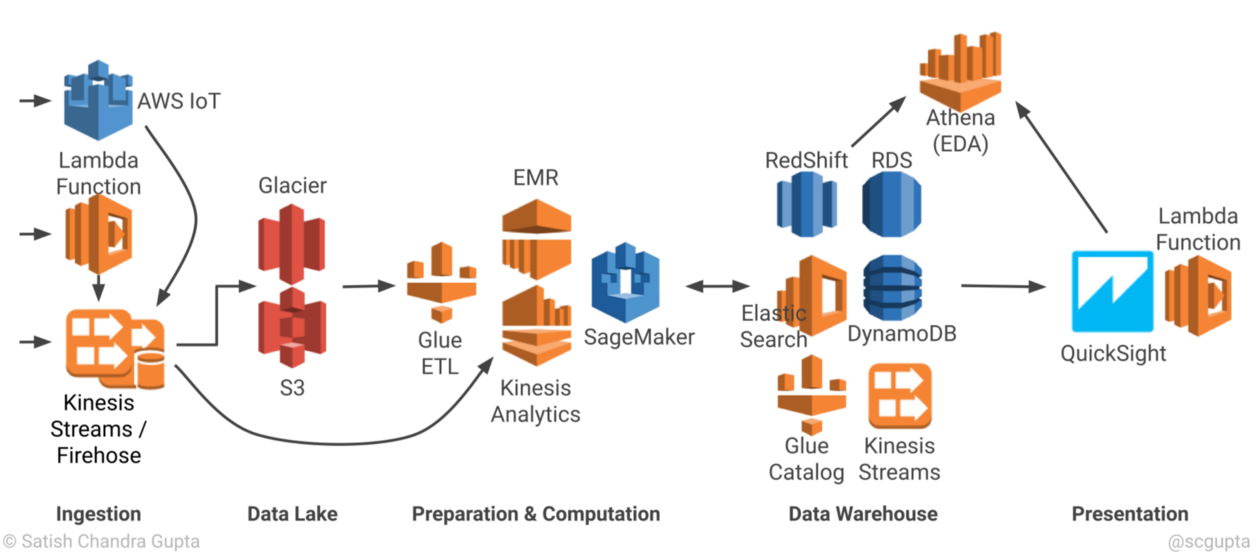
Ingestion
Data 흡수 과정
Lamda Function -> Kinesis Stream / Fire house
lamda function을 통해 불러와진 data를 Kinesis Stream / Fire house를 통해서 data lake로 전송한다.
AWS IoT -> Kinesis Stream / Fire house
IoT에서 실시간으로 들어오는 데이터를 Kinesis stream / Fire house를 통해서 data lake로 전송한다.
api server? -> Kinesis Stream / Fire house
Server에서 발생하는 기타 데이터(로그나 기타 데이터)를 data lake로 전송하고 싶을 때 Kinesis Stream / Fire house를 통해 전송 받는다.
Data Lake
대규모의 다양한 원시 데이터 세트를 기본 형식으로 저장하는 데이터 리포지토리이다.
Data Warehouse와 다르게 정제한 데이터가 아닌 원시 데이터를 저장한다.
모든 데이터(정형 비정형 데이터)를 중앙 집중식 repository 한 곳에 저장할 수 있다. 모든 데이터를 그대로 저장할 수 있기 대문에 스키마 변환이 필요 없다.
참고자료
S3
굉장히 높은 가용성을 자랑하는 Storage 서비스로 모든 AWS 분석 서비스와 연동이 된다. S3는 Data lake의 토대 일 분이지 다른 서비스를 추가하여 업무상 필요에 맞게 Data Lake를 조정하여 구축할 수 있다.
Preparation & Computation
데이터 전처리 및 연산 과정
Glue ETL
Glue를 통해 데이터 구조와 형식을 검색하여 S3(Data lake)로 부터 신속하게 비즈니스 통찰력을 얻을 수 있도록 한다.
기능
- 자동으로 Amazon S3 data를 크롤링 하여 데이터 형식을 식별한 후 다른 AWS 분석 서비스에 사용할 스키마를 제안한다.
- 까다롭고 시간이 많이 소요되는 데이터 검색, 변환, 작업 일정 조정 등과 같은 작업은 간소화 및 자동화하는 종합 관리형 데이터 카탈로그 및 ETL(추출, 변환, 로드) 서비스입니다.
- AWS Glue는 데이터 소스를 크롤링하고 CSV, Apache Parquet, JSON 등을 비롯한 널리 사용되는 데이터 형식과 데이터 유형에 대해 사전 구축된 분류자를 사용하여 데이터 카탈로그를 생성합니다.
Glue 실습 해보기
EMR
아마존 EMR (MapReduce) 는 다음과 같은 빅 데이터 프레임워크 실행을 간소화하는 관리형 클러스터 플랫폼입니다. Apache Hadoop과 Apache Spark 기반의 EMR이 있다. 이러한 프레임워크와 관련 오픈 소스 프로젝트를 사용하여 분석 목적 및 비즈니스 인텔리전스 워크로드에 맞게 데이터를 처리할 수 있습니다.
Amazon EMR을 사용하면 대량의 데이터를 다른 데이터 내로 또는 외부로 이동할 수 있습니다.
ex) Amazon S3 및 DynamoDB와 같은 data stor와 DB
참고 문헌
Kinesis Analytics
Apache Flink를 기반으로 만들어진 클라우드 서비스로 Apache Flink, Apache Beam, Apache Zeppelin, AWS SDK 및 AWS 서비스 통합도 포함되어 있는 서비스다.
Apache Beam은 여러 실행 엔진에서 실행되는 스트리밍 및 배치 데이터 처리 애플리케이션을 정의하기 위해 통합된 오픈 소스 모델이다.
기능
AWS Glue 스키마 레지스트리와 호환
정확히 한 번 처리
상태 유지 처리
내구성이 뛰어난 애플리케이션 백업
참고 자료
Data Warehouse
Red Shifth
클라우드에서 완벽하게 관리되는 페타바이트급 데이터 웨어하우스 서비스로 데이터를 사용하여 비즈니스 및 고객에 대한 새로운 인사이트를 확보할 수도 있습니다. PostgreSQL을 기반으로 만들어진 서비스로 BI도구로 분석할 수 있다.
기능
- 대용량 병렬처리 Massive Parallel Processing
- columnar data storage(컬럼 기반 데이터 스토리지)
DB에 저장하는 테이블 정보를 행기반이 아닌 컬럼(열) 기반으로 저장한다.
컬럼으로 압축함으로써 데이터를 읽는 크기를 줄여 Disk io를 줄이고, 쿼리 성능을 향상시킬 수 있다.
-> 컬럼기반의 장점은 특정 컬럼만 빨리 찾아 낼 수 있어 Disck IO가 좋고 분석에 최적화 됨
ex) Parquet(파케이), ORC, avro(에이브로)가 있다.
컬럼 기반의 장점
참고 자료
DynamoDB
버리스 기반 Key-Value NoSQL 데이터베이스
높은 성능과 비용적인 측면에서 이점을 가져올 수 있습니다.
Partitioning으로 인한 엄청난 속도
동일한 파티션 키를 지닌 데이터는 물리적으로 가까운 위치에 저장
-> 이경우에 데이터를 구분하기 위하여 정렬 키를 사용
정렬 키를 사용하면 동일한 파티션에 저장된 데이터는 정렬 키를 기준으로 순서대로 저장
파티션 키(Partition Key)
파티션 키는 물리적인 공간인 파티션을 구분하기 위한 키입니다.
스케일이 아무리 커져도 주소를 알고 있어 데이터를 빠르게 가져올 수 있습니다.
때문에 파티션 키로는 일치하는 값만 가져올 수 있고, =, >, < 등과 같은 연산자를 사용하는 범위지정 방식의 검색은 지원하지 않습니다.
정렬 키(Sort Key)
정렬 키는 파티션 안에서 데이터를 정렬하기 위한 키입니다.
DynamoDB에서는 Number, Binary, String 타입을 지원합니다. (String의 경우 utf-8을 기준으로 정렬됩니다.)
단순 정렬이기 때문에 파티션의 사이즈가 커져도 데이터를 빠르게 가져올 수 있습니다.
파티션키와는 달리 범위지정 방식의 검색을 지원합니다. 하지만 정렬 키만 가지고는 검색할 수 없습니다
강력한 장점
모든 데이터 10ms 내에 조회 가능
단점
데이터 간 relation이 없기 때문에 같은 데이터가 여러개 중복되어 들어있을 수도 있고
조회 시 N+1이슈가 발생하기 때문에 까다롭다.
DynamoDB
Glue Data Catalog
영구적 기술 메타데이터 스토어입니다. AWS 클라우드에서 메타데이터를 저장 및 공유하고 주석을 다는 데 사용할 수 있는 관리형 서비스
테이블은 Amazon RDS, Apache Hadoop Distributed File System, Amazon OpenSearch Service 등과 같은 소스에 저장된 정형 또는 반정형 데이터를 표현할 수 있다.
서로 다른 시스템이 데이터 사일로의 데이터를 추적하기 위해 메타데이터를 저장하고 찾을 수 있는 균일한 리포지토리를 제공합니다. 그런 다음 메타데이터를 사용하여 다양한 애플리케이션에서 일관된 방식으로 해당 데이터를 쿼리하고 변환할 수 있습니다.
Kinesis Streams
Athena(EDA)
s3 data storage에 쿼리로 데이터 조회 가능
Presention
Quick Sight + lamda function
BI 시각화 도구
