
M1 환경에서 ORACLE을 돌리기가 쉽지 않아 ORACLE Live SQL을 이용하기로 했다.
웹 환경에서 ORACLE을 돌리게 해주는 것 같다.
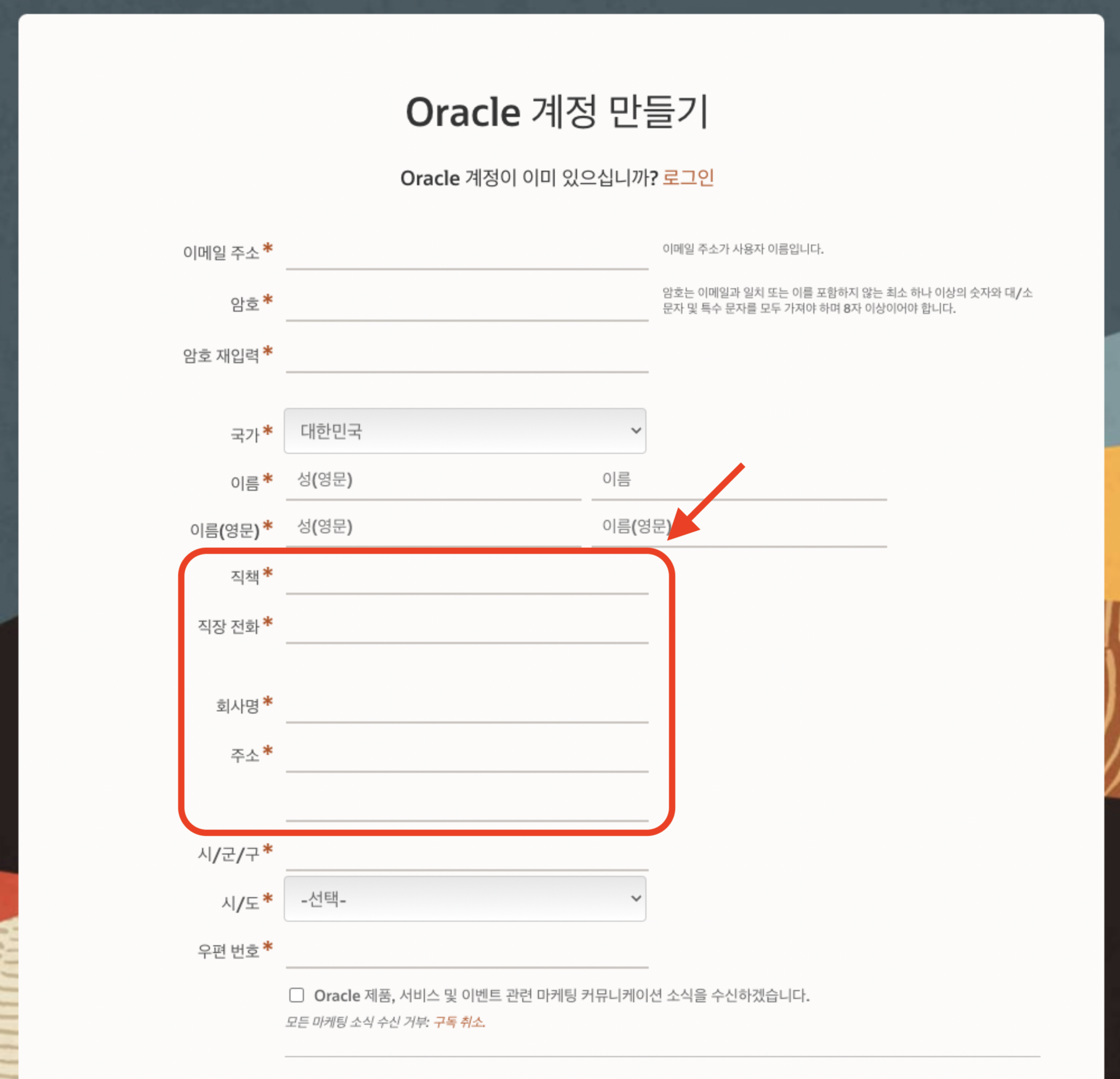
이걸 쓰려면 회원가입을 해야하는데
여름이라 그런지 각막에 습도가 상당히 높아진 느낌이었다.
- 직책: 무직
- 직장 전화: 내 휴대폰 번호
- 회사명: 무직
- 주소: 무직
이렇게 적었더니 통과되었다.
구글링해봐도 다들 비슷하게 적는 것 같다.
data 입력
회원가입 및 로그인을 완료했다면 아래와 같은 화면에서 Start Coding Now를 클릭해준다.
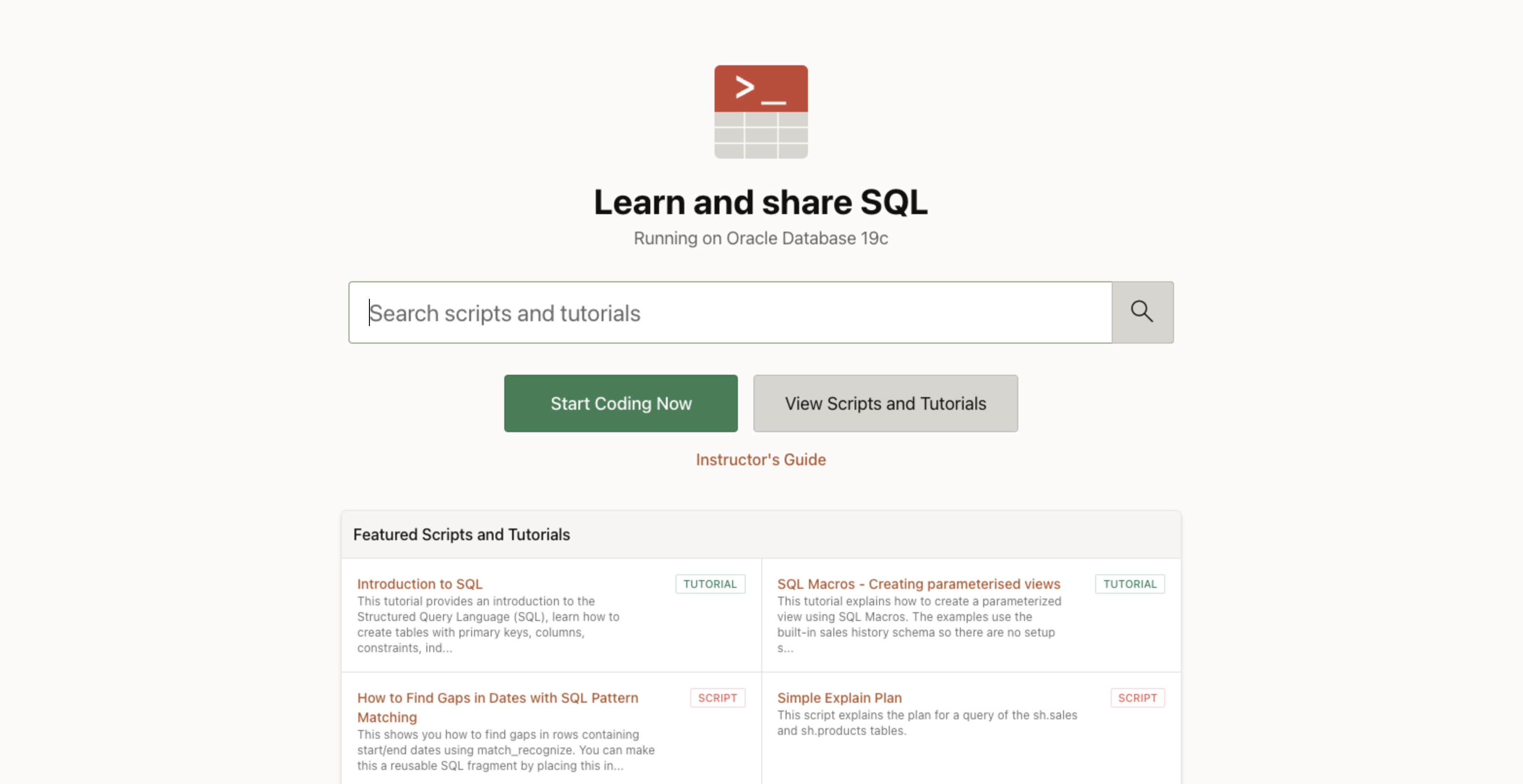
SQL Worksheet 탭으로 진입하고
출판사 공식홈페이지에서 받은 쿼리를 그대로 입력해준다.
Maria에서는 수정이 필요한 쿼리였는데 ORACLE에서는 모두 정상적으로 작동했다.
My Session탭에서 나의 작업내용을 SAVE할 수도 있다.
로그인할 때마다 워크시트가 초기화되는데, 불러오기가 가능하기 때문에 이전 작업을 계속 이어나갈 수 있다.
실습을 하는 데는 이걸로도 충분할 것 같다.
2. 4장 혼합 영숫자 데이터 정렬하기
먼저 VIEW부터 만들어볼 것이다
create view V
as
select ename||' '||deptno as data
from emp;
select * from V
>>
DATA
KING 10
BLAKE 30
CLARK 10
JONES 20
SCOTT 20
FORD 20
SMITH 20
ALLEN 30
WARD 30
MARTIN 30
TURNER 30
ADAMS 20
JAMES 30
MILLER 10정상적으로 잘 출력된다.
이 내용은 영문과 숫자가 혼합되어 있다.
Q. DEPTNO 또는 ENAME별로 결과를 정렬하려고 한다
A. REPLACE 및 TRANSLATE 함수를 사용하여 정렬할 문자열을 수정한다
/* DEPTNO로 정렬하기 */
select data
from V
order by replace(data,
replace(
translate(data, '0123456789', '##########'), '#', ''), '')
/* ENAME으로 정렬하기 */
select data
from V
order by replace(
translate(data, '0123456789', '##########'), '#', '')언뜻 보면 굉장히 복잡하므로 일단 함수의 기능부터 알아야겠다.
TRANSLATE(문자열, 문자열 중에 이 '문자'가 존재하면, 이 부분의 '문자'로 각각 변환한다)REPLACE(문자열, 문자열 중에 이 '문자열과 일치하는 부분'이 존재할 때, 이 '문자열'로 변환한다)
어떤 차이가 있을까?
select replace('@@@', '@', '13') as replace from emp where deptno=10;
>>
# @@@중에서 @가 보일 때마다 13으로 한꺼번에 변환했다(1과 3을 붙여서 변환했다)
REPLACE
131313
131313
131313
select replace('@@@', '@@', '20') as replace from emp where deptno=10;
>>
# @@@중에서 @@가 보일 때마다 20으로 한꺼번에 변환했다(@@로 연결되어 있는 것을 20으로 변환했다)
REPLACE
20@
20@
20@
select translate('@@@', '@', '3') as translate from emp where deptno=10;
>>
# @@@에서 @가 보일 때마다 하나씩만 3으로 변환했다
TRANSLATE
333
333
333
select translate('@!@', '@', '4') as translate from emp where deptno=10;
>>
# @!@에서 @가 보일 때마다 하나씩만 4로 변환했다
TRANSLATE
4!4
4!4
4!4
select translate('@!@', '@!', '56') as translate from emp where deptno=10;
>>
# @!@에서 @가 보일 때는 하나씩만 5로 변환했고 / !가 보일 때는 6으로 변환했다
TRANSLATE
565
565
565-
TRANSLATE는문자를 단위로1 대 1치환한다. -
REPLACE는문자열을 단위로한꺼번에치환한다.
문제의 해법을 다시 보겠다.
/* DEPTNO로 정렬하기 */
# 여기서 data는 영문+숫자
select data
from V
# replace: data에서 문자열만 남은 data를 한꺼번에 공백으로 처리한다
order by replace(data,
# replace: '##########'에서 '#'이 보일 때마다 공백으로 처리한다
replace(
# translate: 데이터의 숫자들을 모조리 '#'으로 바꾼다
translate(data, '0123456789', '##########'), '#', ''), '')
# 최종적으로 숫자만 남게 되므로 숫자로 정렬할 수 있게 된다
/* ENAME으로 정렬하기 */
# 여기서 data는 영문+숫자
select data
from V
# replace: '##########' 중에서 '#'이 보일 때마다 공백으로 처리한다
order by replace(
# translate: 데이터에 숫자들을 모조리 '#'으로 바꾼다
translate(data, '0123456789', '##########'), '#', '')
# 최종적으로 숫자들이 사라지므로 이름으로 정렬할 수 있게 된다숫자로 정렬하는 부분을 잘 봐야할 것 같다.
-
첫 번째 translate가 실행되었을 때 데이터의 상태는
ADAMS ##########
ALLEN ##########
...
이런 상태이다.
숫자가 모두 '#'으로 바뀐 상태다. -
여기서
첫 번째 replace가 실행되면서 '#'을 공백으로 바꾸게 되면
ADAMS
ALLEN
...
이런 상태가 된다.
즉, 문자열만 남은 상태다. -
마지막 replace가 실행되면서 data중에 문자열을 모두 공백으로 바꾸면
숫자만 남게 된다.
이렇게 숫자로 정렬할 수 있게 되는 것이다.
놀라운 방법이다...
