
오늘 배운 것
- 자료 구조
- Stack
- Queue
자료 구조
사전적 정의
여러 데이터들의 묶음을 어떻게 저장할 것이고 사용할 것인지 정의한 것
개요
우리는 다양한 자료를 가공하고 저장하고 활용할 수 있다.
다만, 그 자료(data)는 굉장히 다양한 형태로 입력될 수 있고 그 형태에 따라 저장하고 가공하고 활용하는 방법이 모두 다르다.
이 각각의 방안을 모두 모아 자료구조라는 이름이 붙여졌다.
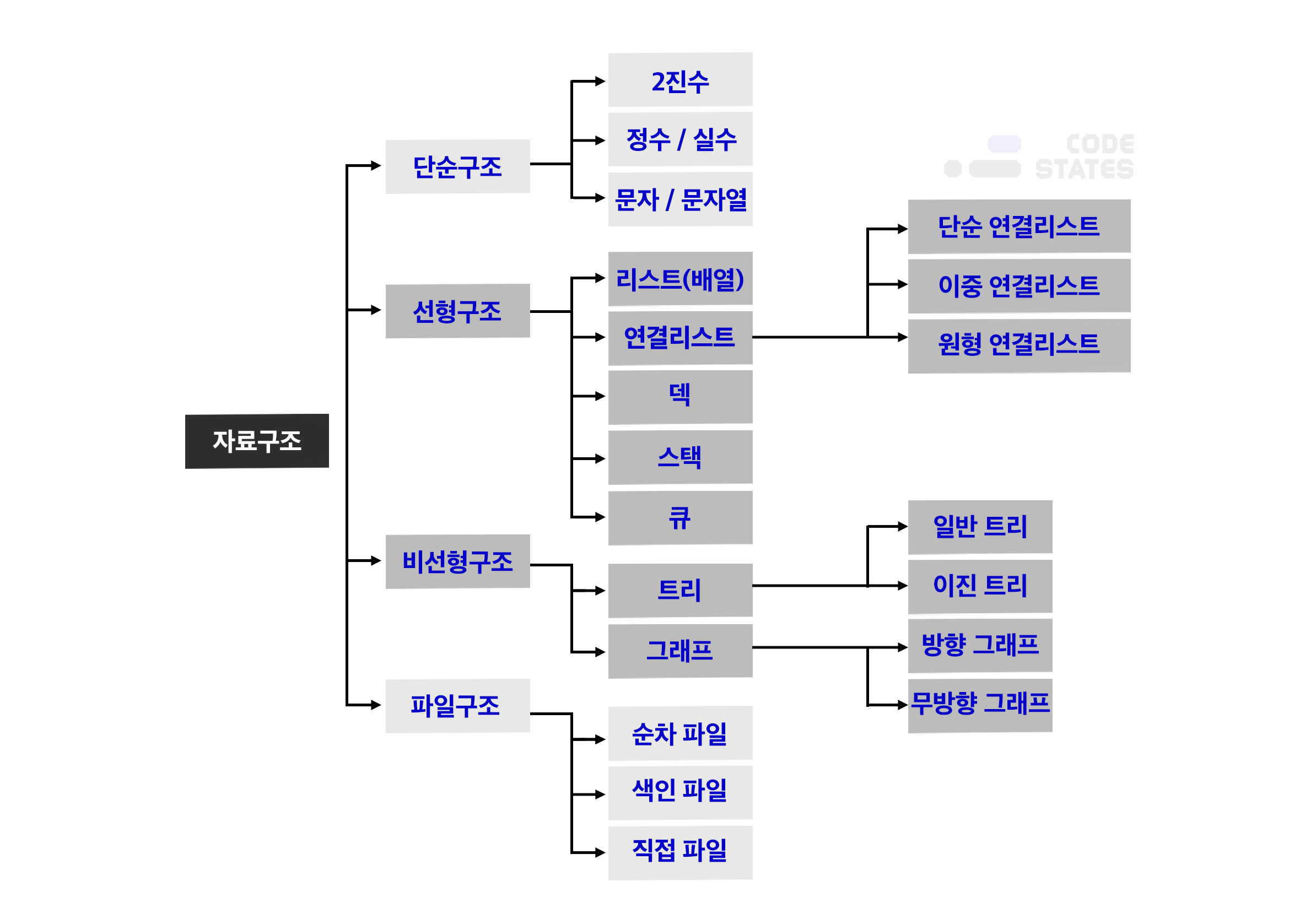
대부분의 자료구조는 특정한 상황에 문제를 해결하는 데 특화되어 있다.
이 때문에, 많은 자료구조를 알아두어야 문제가 발생했을 때 적합한 자료 구조를 사용하여 문제를 해결할 수 있다.
이 방법들 중 실제로 가장 많이 사용되는 것은 stack, queue, tree, graph이다.
Stack
정의
자료를 순서대로 쌓아놓는 구조이다.
특성
막다른 골목에 여러 대의 자동차가 진입한 상태를 생각하면 이해가 쉽다.
가장 나중에 들어간 자동차가 가장 먼저 나올 수 있다.(가장 먼저 들어간 자동차가 가장 나중에 나올 수 있다)
이와 같이 stack 자료 구조는 입출력이 하나인 제한적 접근이 특성이다.
이러한 정책을 LIFO (Last In First Out) 또는 FILO (First In Last Out)이라고 부르기도 한다.
실 사용 예제
가장 가까이서 찾을 수 있는 방법은, 브라우저의 prev,next 기능이다.
- 새로운 페이지로 접속할 때 지금 로드되어있는 페이지를 Prev Stack에 보관
- 뒤로 가기를 눌러 이전 페이지로 돌아갈 때는 지금 로드되어있는 페이지를 Next Stack에 보관, Prev Stack에 가장 나중에 보관된 페이지를 불러옴
- 앞으로 가기를 눌러 앞서 방문한 페이지로 돌아갈 때는 2번의 반대로 작동
Queue
정의
순서대로 진행한다. 음향 할 때 그 큐시트, 큐 리스트와 동일한 의미를 갖고 있다.
특성
별다른 연출자의 요청이 없으면, 연출자가 제공한 큐시트대로 공연이 진행되고,
음악이나 효과음을 playback하려고 미리 작성한 큐 리스트대로 재생이 이루어진다.
이처럼 queue는 자료가 입력된 순서대로 처리해야 할 필요가 있는 상황에서 사용된다.
실 사용 예제
가장 가까이서 찾을 수 있는 방ㅂ버은, 프린터의 작업 목록이다.
- 출력 버튼을 누르면 해당 문서는 인쇄 작업 Queue에 들어간다.
- 프린터는 인쇄 작업 queue에 들어온 순서대로 문서를 인쇄한다.
버퍼
컴퓨터-컴퓨터, 컴퓨터-주변 장치, 서버-컴퓨터 등 여러 장치 사이에서 자료를 주고 받을 때,
각 장치 사이에는 속도의 차이나 시간의 차이가 발생하는데, 이를 극복하기 위한 임시 기억 장치로 queue가 사용된다.
이를 통틀어 버퍼(buffer) 라고 한다.
프린터 풀링이 버퍼에 해당하고, 영상을 재생할 때 뜨는 버퍼링도 이 버퍼를 지칭하는 말이다.
