오늘의 키워드!
합성곱 계층(Convolutional layer)
풀링 계층(Pooling layer)
패딩(Padding)
스트라이드(Stride)
특징 맵(Feature map)
최대 풀링(Max pooling)
평균 풀링(Average pooling)
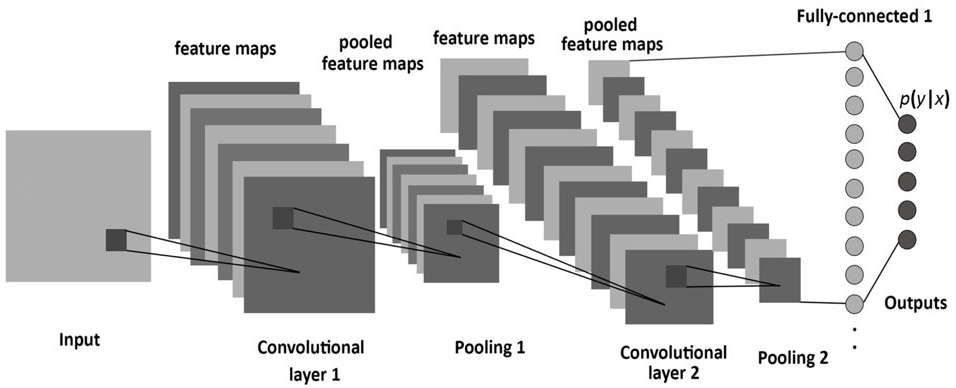
CHAPTER 7 합성곱 신경망(CNN)
7.1 전체 구조
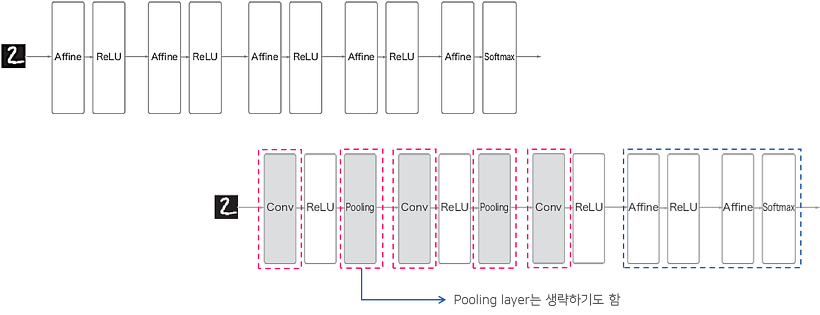
- 기존 : fully connected, Affine 계층으로 구현
CNN : Conv계층, Pooling 계층이 더해져서 'Afiine - Relu' -> 'Conv -> Relu -> (pooling)'으로 바뀜.
7.2 합성곱 계층
- 각 계층 사이에 3차원 데이터 같이 입체적인 데이터가 흐른다는 차이가 있음
7.3 완전 연결 계층의 문제점
-
완전 연결 계층의 문제점 : 데이터의 형상이 무시됨
-
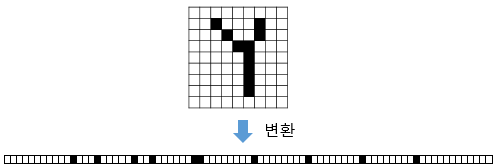
MNIST 데이터셋에서 (1,28,28)인 이미지를 1줄로 세운 784개의 데이터를 입력하다보면, 위치 값이 없어짐 -> 3차원 속에서 의미를 갖는 패턴을 무시하고 동등한 뉴런으로 처리하여 형상의 정보를 살릴 수 없음
-
CNN은 이미지처럼 형상을 가진 데이터를 제대로 이해할 수 있음
-
입출력 데이터 : Feature Map(특징맵)이라고 함
-
합성곱 연산을 통해 필터 연산을 처리함.
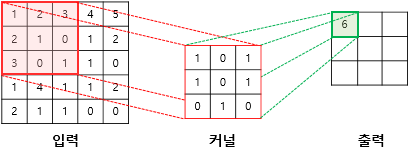
(1 x 1) + (2 X 0) + (3 x 1) + ... = 6 -
책에서 제공한 CS231n.github.io/convolutional-networks 사이트
CS231n Convolutional Neural Networks for Visual Recognition
- 번역된 사이트
CS231n Convolutional Neural Networks for Visual Recognition
7.3 풀링 계층
- Max Pooling(최대풀링) - 최댓값 뽑기
- Average Pooling(평균풀링) - 평균값 뽑기
- Min Pooling(최소풀링) - 최솟값 뽑기
https://www.notion.so/modulabs/12-35ba8c1cc6a746909c5100c9a04a9382#a791f34dcde14d37ae134122992e25c3
🙌 👀그 외 참고 자료들
- 다양한 Convolution 기법 [Deep Learning] 딥러닝에서 사용되는 다양한 Convolution 기법들
- CNN 쉽게 이해하기 [딥러닝/머신러닝] CNN(Convolutional Neural Networks) 쉽게 이해하기
- 자연어 처리를 위한 1D CNN 점프 투 파이썬
⁉️오늘의 질문과 게임!
- 왜 일반적으로 제로 패딩을 사용할까!? 제로 패딩의 장점!?
-> 곱해준 가중치 값이 0이되어 출력값에 영향을 주지 않는다. - CNN에서 튜닝 가능한 하이퍼 파라미터는 어떤 것이 있을까?
-> 커널 갯수, 커널 크키(W,H), padding 크기, 스트라이드(stride = 보폭), 편향, activation funtion - 동일한 Task에 스트라이드(stride = 보폭) 값을 변경하면 어떤 결과가 나올까요?
-> 스트라이드 늘리면, 더 크게 읽으면서 속도가 빠르고, 러프하게 위치를 알 수 있다는 장점. 하지만 그만큼 위치 정보를 많이 손실함.
-> 스트라이드 줄이면 반대로 더 촘촘하게 읽으면서 정보를 더 많이 뽑아낼 수 있고, 그만큼 속도가 느릴 수 있음. - Convolution Layer를 많이 쌓으면 어떤 장단점이 있을까요?
-> 쓰는 이유? 이미지에서 특징을 찾아내겟다는 것. 많이 쌓았는것은 특징을 많이 찾았다. 세밀한 특징까지 찾을 수 있음.
-> 너무 세밀하면 나무를 보다 숲을 못보는 효과 -> 적절한 값을 찾는 것도 하이퍼 파라미터를 조절. - Pooling을 하는 이유와 pooling을 하지 않았을 때 어떤 결과가 나올까요?
-> 값들이 너무 크게 벌어져서 처리하기 힘듦..?
-> 이유? 특징을 단순화해서 표현할 수 있음. 풀링 자체가 먁스풀링은 이미지의 크기가 줄어드는 의미도 있지만, 연산이 빨리 결과를 얻을 수 있다. 이미지가 작아지면 그 특징을 더 강하게 잡는 것이기 때문에. 이미지가 적어짐 -> 연산량이 줄어ㄷ름 -> 계산할 픽셀수 적음 -> CPU일 덜해도됨.
-> 하지 않았을 때, 이미지크기를 그대로쓰니 막대한 연산리소스필요 -> 속도 오래걸림. 같은 결과라도 속도가 늦음. 학습시 막대한 연산을 하니까 오래걸림. - Fully-connected를 하지 않고 최종 값을 출력할 수는 없을까요?
-> 풀리 커넥트 : 완전히 연결 -> 한층의 모든 윤련이 다ㄹ음픙 뉴런으로 다 이어짐-> 차원 줄어듬
-> 하지않으면 최종값 출력할 수 없을 것 같음. 최종값을 출력하는게 소프트맥스 -> 차원축소가 일어나지 않는다면 소프트 맥스에 넣을 수 없을 것.
-> 풀리 쓰느느 이유? 컨볼르션고가 풀링의 결과를 라벨로 분류하는데 사용함
1)특징으로 얻은 것을 2차원 배열의 형태를 1차원으로 축서
2) 활성화 함수에 넣기위해!(1차원만 넣을 수 있음) 넣고 뉴런에 활성화
3) 분류기(소프트맥스)를 통해 분류
개인 질문
-
필터 세개쓰는 이유? 각 알지비에 알맞은 필터를 써야한다. -> 아 r g b 분리하면 한 그림이라도 다른 그림으로 나옴. 우리 단어외울때 빨간색 필터 씌우면 다르게 나오는것처럼.
-
새로운 필터를 쓰는 이유?
: 크기가 크면 진행하는 속도도 느리고, 그림의 크기가 크면 인접한 부분들의 값들도 거의 비슷하게 나올 것이기 때문에,
: 좁은 범위 볼 때, 넓은 범위를 볼 때 등 각각의 역할이 다름. 넓게보는게 장점이지만 손실되는 값들이 많은게 단점(사각형 드문드문 있는 것)
부분적으로 뽑아서 넓게 한번 보는 식으로 다각도로 적용해보겠음,.====filter 바꾸는 경우는 크게 2가지 =======
- 특징맵 더 많이 생성하고싶거나
- 특징맵의 해상도를 조절하고 싶거나
