
※ 하기 내용은 class101 비전공자도 쉽게 배워 바로 써먹는 실무 활용 SQL을 정리한 내용입니다.
Chapter 1. 데이터 모델의 이해
- 데이터 모델이란?
- 단계별 데이터 모델링
- 데이터 모델링의 요소들
- ERD 표기법
- 정규화와 반정규화
- 관계형 데이터베이스
DB 관련 기본 용어

DBMS는 소프트웨어이고, Database는 (좁은 의미의)저장소이다.
- DBMS : Data Base Management System의 약자. DB 관리 SW를 말함. (Ex. Oracle, MySQL, DB2, MS-SQL, SQL-Server),
- 요청은 SQL로 하고, DBMS가 결과를 DB에서 꺼내서 데이터(집합)로 출력함.
1. 데이터 모델이란?
데이터 모델(Data Model)
- 건축물로 비유하면 설계도면에 해당됨.
- 현실 세계를 Database로 구축할 수 있도록 추상화한 것
- 복잡한 현실 세계를 약속된 표기법에 의해 단순화시켜 표현함
- Database에 저장하기 위해 애매모호함을 제거하고 명확화하여 기술
데이터 모델링(Data Modeling)
- 현실 세계를 약속된 표기법에 의해 표현하는 과정
- 데이터베이스를 구축하기 위한 분석/설계의 과정(비지니스를 분석, AS-IS_현재 DB를 분석 -> 현재 데이터의 형태 파악 -> TO-BE DB 설계)
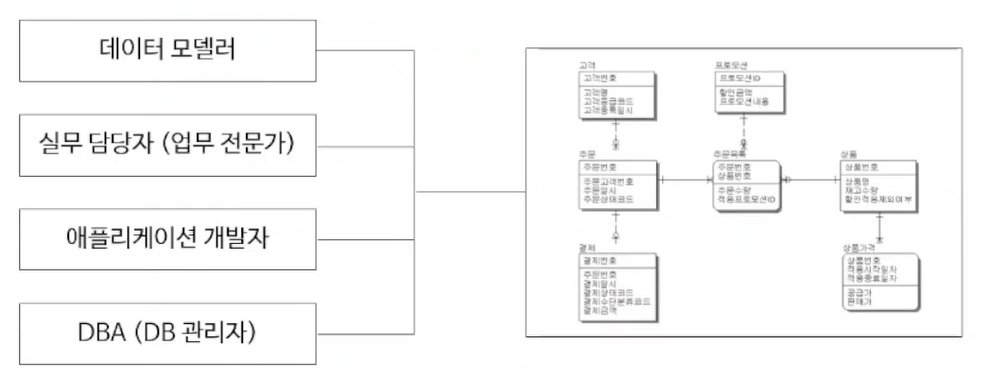
데이터 모델링 이해 관계자(=참여자)
- 데이터 모델러
- 실무 담당자(=me! 실무를 잘 아는 사람)
- 애플리케이션 개발자 (DB기반으로 IT 시스템을 만드는 사람 = SQL 가장 많이 사용함)
- DBA(DB관리자)
2. 단계별 데이터 모델링
데이터 모델링의 3단계
-
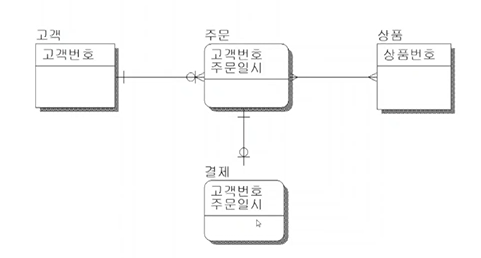
개념적 데이터 모델링 (실무에서 생략하기도함)
- 현실 세계에 있는 데이터를 요구 사항에 의해 컴퓨터의 세계로 매핑하는 과정이며 데이터의 중복을 줄이고 무결성을 유지하기 위해 설계하는 과정
- 핵심 엔터티와 핵심 엔터티들 간의 관계를 정의하는 과정
- 추상화 수준이 높고(= 간략화-> 중요한건만뽑는), 업무 중심적이고 포괄적인 수준의 모델링
-
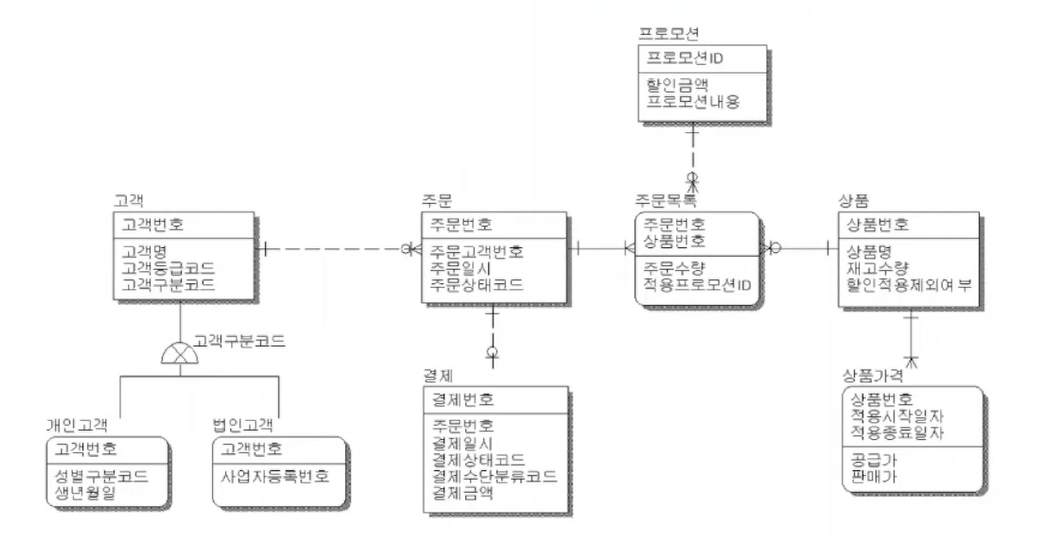
논리적 데이터 모델링 (본격 설계)
- 모든 업무 요구사항을 충족시키기 위해 엔터티, 속성, 관계, 식별자(=DB 요소들) 등을 정의함으로써 데이터의 구조를 논리적으로 구체화하는 과정
- 전체 비즈니스가 드러나야함
- 표기법을 알면 모든 상태를 파악할 수 있는 정도
-
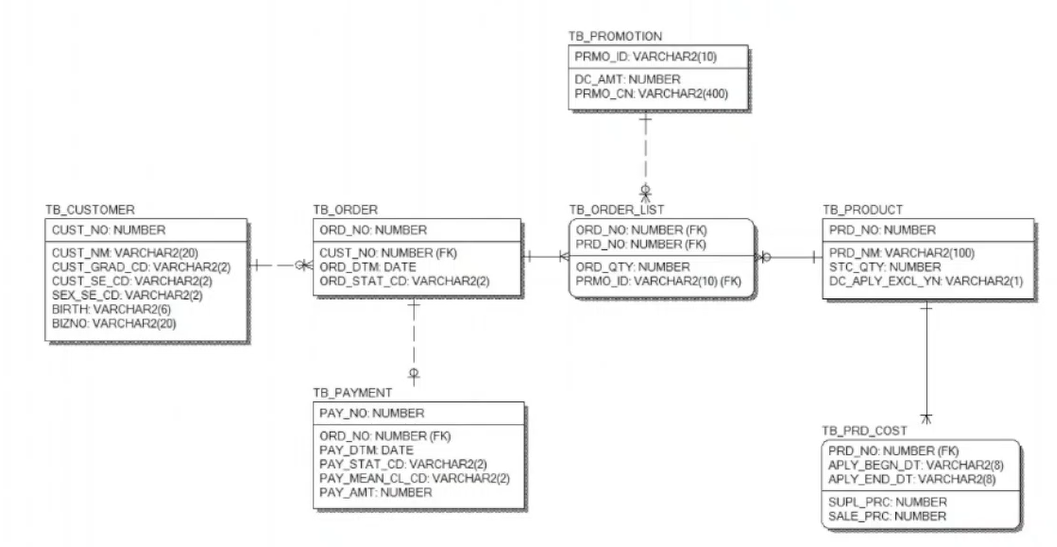
물리적 데이터 모델링
- 실제로 데이터베이스에 이식할 수 있도록 성능, 저장 등 물리적인 성격을 고려하여 데이터베이스 저장 구조로 변환하는 과정
- DB 타입/특성 결정 -> 이걸 보고 RDB 구축함
3.데이터 모델링의 요소들(엔터티, 속성, 관계)
엔터티(Entity)
- Database에 정보로서 저장될 수 있는 사람, 사물, 개념(ex.조직도,프로모션 등), 행위 등

- 업무 상 필요하고 관리하고자 하는 대상으로서, 그 대상들 간에 동질성을 지닌 개체 집합이나 그들이 행하는 행위의 집합
- 동질성은 집합의 범위를 어디까지로 한정할 것인지에 따라 달라질 수 있다.
ex. '고객'이라는 집합을 '상품 구매 이력이 있는 개인이나 법인'으로 정의한다면, 잠재고객이나 단체 등은 고객이 될 수 없다.
- 동질성은 집합의 범위를 어디까지로 한정할 것인지에 따라 달라질 수 있다.
슈퍼타입/서브타입 엔터티
- 슈퍼타입 엔터티 : 개체들에 대한 일반화 과정에서 생성되는 상위 집합
- 서브타입 엔터티 : 특정 기준에 따라 상세화된 개체들의 부분 집합
(슈퍼타입의 모든 공통속성을 상속하며, 자신의 개별 속성을 가질 수 있다)

관계(Relationship)
- 엔터티와 엔터티 간의 논리적인 상호 연관성
- 실제론 엔터티 내에 있는 개체간의 논리적인 연관성이라고 할 수 있다.

- 위와 같은 경우, 설계 단계에서는 고객이 상품을 구매한다는 것 설정
- 실제론 엔터티 내에 있는 개체간의 논리적인 연관성이라고 할 수 있다.
- 관계 차수(Cardinality) : 두 엔터티 간의 관계에서 참여자(개체)의 수를 표현한 것
- 1:1관계, 1:M관계, M:M관계 등 (상기 구매 관계는 M:M관계) - 선택성(Optionality) : 두 엔터티 간의 관계에서 개체들의 필수/선택 참여 여부를 표현한 것
- 필수 참여, 선택 참여
속성(Attribute)
- 개체 집합이 가지고 있는 특징이나 성질
- 엔터티에 표현되는 구체적인 정보 항목

- 엔터티에 표현되는 구체적인 정보 항목
- 의미적으로 더 이상 분리되지 않는 최소 데이터 단위 (비지니스마다 달라질 수 있음)
- 공공기관 행정 DB : 시도, 시군구, 읍면동
- 온라인 쇼핑몰 DB : 우편번호, 상세주소
식별자(Identifier)
-
엔터티의 각 개체를 유일하게 식별할 수 있는 속성들의 조합 (하나하나 구분할 수 있는 속성들)
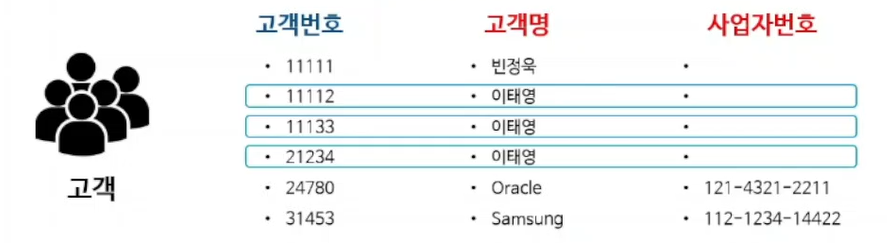
-
식별자의 특징 : 유일성(하나하나 식별할 수 있는 것), 최소성(속성을 여러개해서 구분할 수 있는 것_아래 주문번호,주문일자~), 불변성(, 존재성
-
식별자의 분류
- 주/보조 식별자(고객번호/주민등록번호), 단일/복합 식별자(고객번호/주문일자+고객번호), 본질/인조 식별자(항상 쓰이는 값/단순히 구별하기위한 index값)
ex. 주문번호 vs 주문일자 + 고객번호 + 주문순서
- 주/보조 식별자(고객번호/주민등록번호), 단일/복합 식별자(고객번호/주문일자+고객번호), 본질/인조 식별자(항상 쓰이는 값/단순히 구별하기위한 index값)
식별관계 vs 비식별 관계
- 식별 관계 : 부모 엔터티의 식별자 속성을 자식 엔터티의 식별자 속성으로 가지는 관계

- 부모 엔터티와 자식엔터티가 밀접한 관계를 가진다
- 엔터티 간의 업무적인 연관성이 잘 드러난다
- 비식별 관계 : 부모 엔터티의 식별자 속성을 자식 엔터티의 일반 속성으로 가지는 관계

- 부모 엔터티와 자식 엔티티가 느슨한 관계를 가진다.
4. ERD(Entity Relationship Diagram)표기법(= 데이터 모델 표기법)
엔터티, 속성 표기법
- 여러가지 표기법이 있지만 I/E(Information/Engineering) 표기법, Barker 표기법(casemathod)이 주 표기법이다.
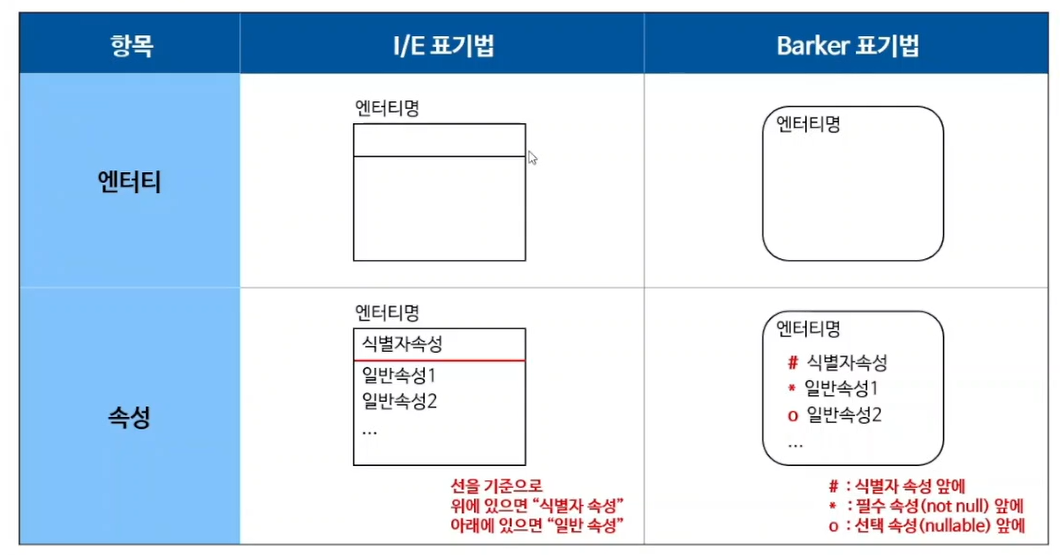
- I/E 표기법에는 필수선택/선택속성 등이 나타나지 않음(지원하지않는 것. 표기법엔 표시되지 않으나 설계툴에서 지원함)
슈퍼타입/서브타입 표기법(상위/하위)
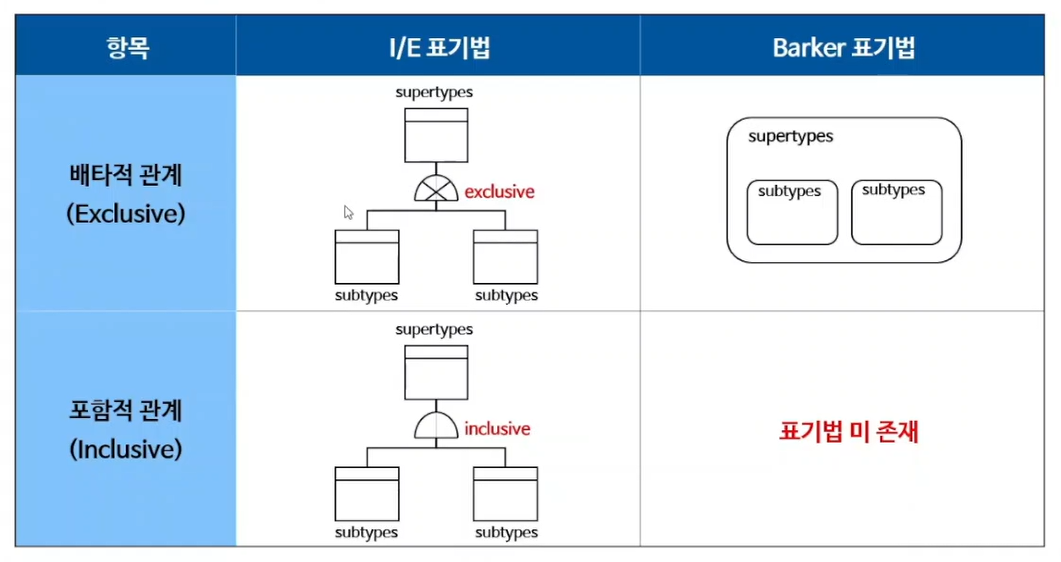
- 배타적 관계 : 서로 겹치는 것이 없는 관계. 대부분 배타적 관계임.
- Barker표기법은 포함적 관계를 나타내는 표기법은 없으나 툴을 이용해 나타냄
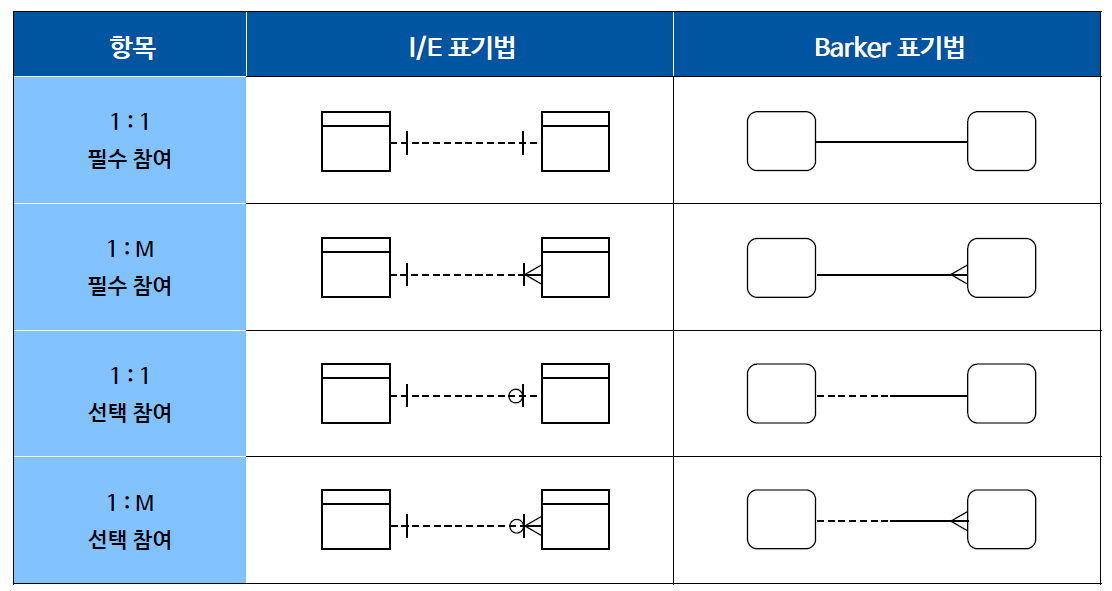
관계 표기법(가장중요!)
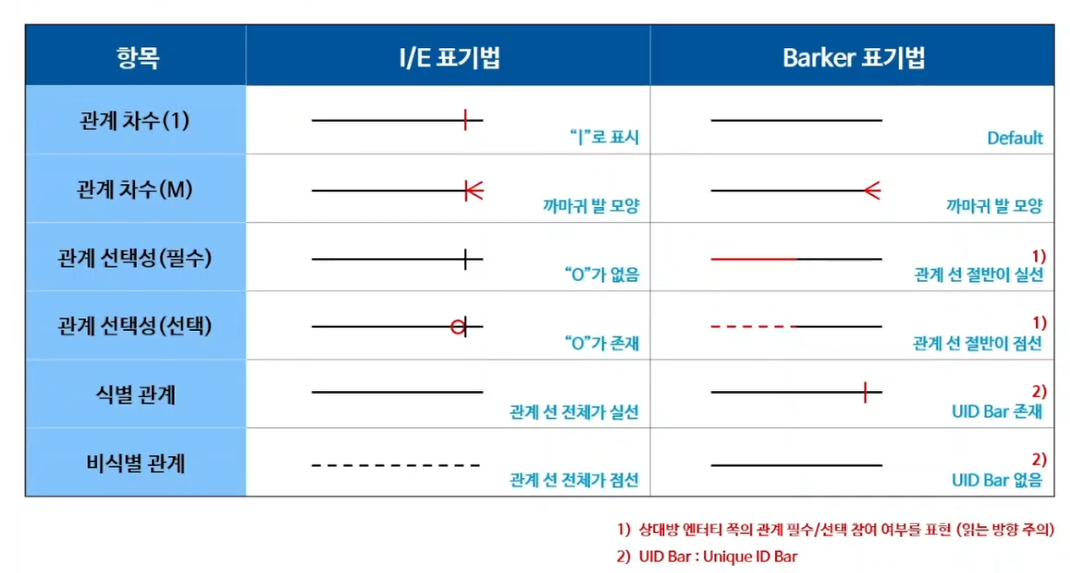
관계 종류(식별관계)
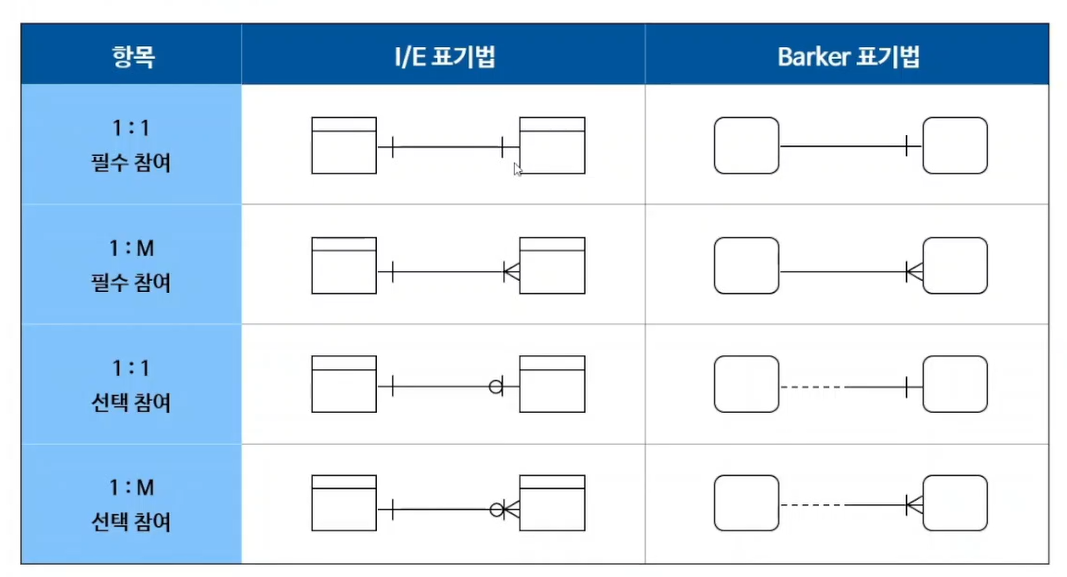
관계 종류(비식별관계)
관계 읽기(I/E표기법)
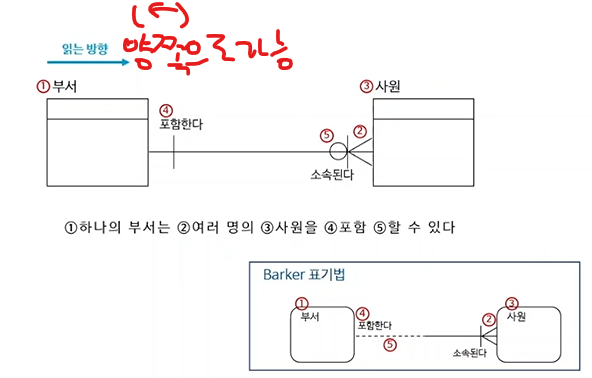
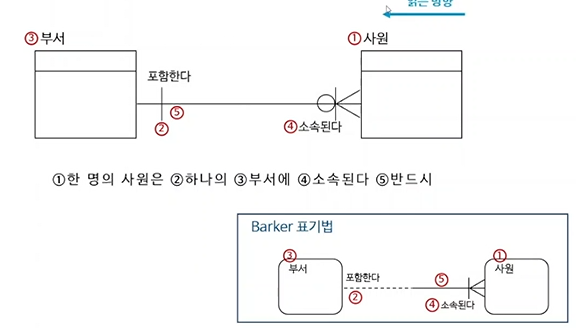
- 외우려기보다, 보고 자연스럽게 읽을 수 있으면됨(연습해봐야한다)
5. 정규화와 반정규화
- 정규화는 RDB의 근간이 되는 정보. 이를 통해 왜 기업이 데이터를 여러 테이블로 나눠서 하는지 이해가 됨
정규화(Normalization)
- 데이터의 중복을 최소화하고 이상현상(Anomaly)이 발생하지 않도록, 함수종속을 기반으로 연관성있는 속성들로만 엔터티를 (재)구성하는 과정
- 하는 이유? 데이터의 중복을 최소화하고 데이터가 이상하게 별질되지 않도록 하기 위함
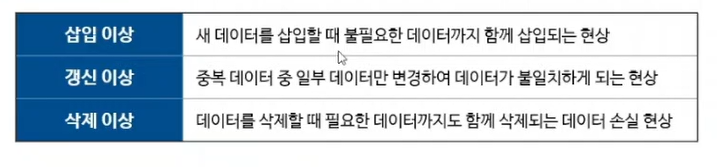
이상현상 : 불필요한 데이터 중복으로 인해 데이터의 삽입/갱신/삭제 시 발생하는 데이터 이상 현상
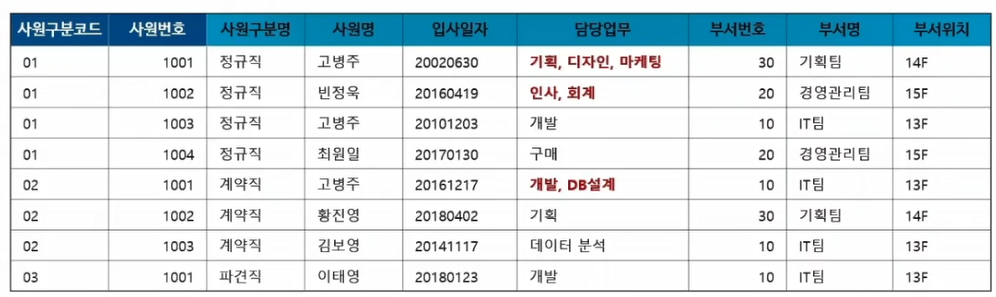
- Ex. 삽입이상 : 상기 테이블에서 부서번호를 늘릴 때, 필요한건 부서번호, 부서명, 부서위치인데, 쓸데없는 그 앞테이블까지 생성하게 되는 경우
- Ex. 갱신이상 : 20번 부서의 부서명이 바뀔 때, 1004 사원의 부서명을 바꾸지 않았을 경우 -> 데이터 불일치
- Ex. 삭제이상 : 경영관리팀 인원이 퇴사하면서 사원을 지우면 경영관리팀 정보를 담고있는게 없어져서 필요한 데이터까지도 삭제되는 경우
함수 종속 : 한 엔터티 내에서 특정 속성(들)의 값을 알게되면 다른 속성ㄷ르의 값이 저절로 결정될 때, 기준이 되는 속성을 결정자 속성이라고 하고, 결정자에 의해 정해지는 속성을 종속자 속성이라 한다.
ex. 고객번호, 고객명, 성별, 생년월일
비정규형
§정규화(정규화 과정) / 정규형(정규화된 결과)
- 비정규형(정규화가 되지 않은) 예시
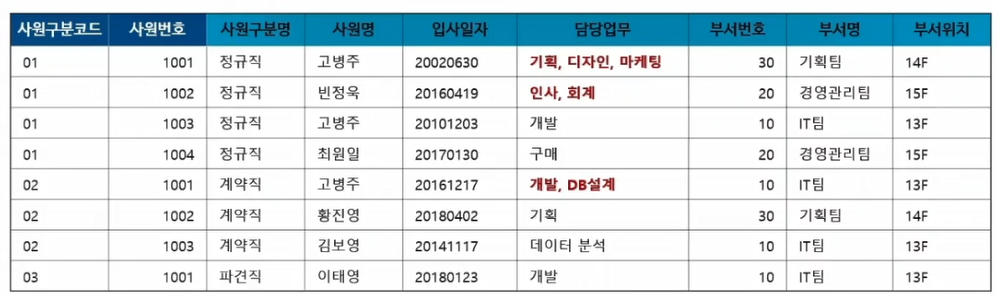
- 사원구분코드, 사원번호 각 하나가지고는 사원을 구분할 수 없음. -> 두개의 조합으로 하나하나 식별하게 됨. (2개가 식별자)
- 가장 큰 문제점 : 속성의 개념을 벗어남. 최소단위의 속성이 되어야함. 담당업무에 3가지의 값이 다 들어가게됨. 다중값은 하나씩 들어가게 바꿔줘야함.
- 잘못된 사례 1
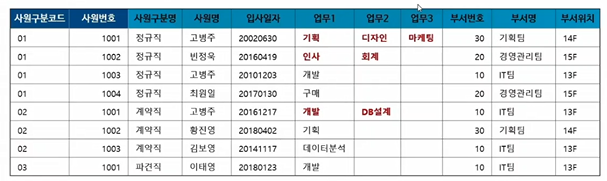
: 유연성이 떨어짐. 업무가 늘어나면 DB구조가 변하게 됨. - 잘못된 사례 2
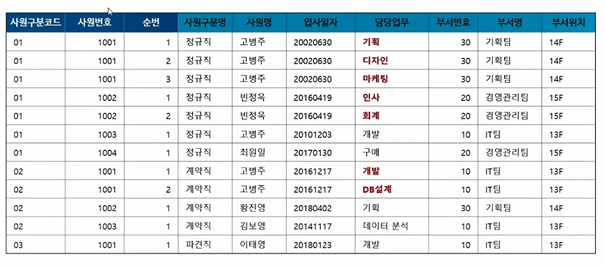
: 업무가 늘어가면 행이 늘어나게 하면 되는데, 이는 중복되는 행이 많아짐. 만약 이름이 바뀔 때, 잘 안바꿔주면 갱신이상이 됨.
제 1 정규형 (1차 정규화)
- 모든 속성의 값이 원자값(atomic value)로만 구성되어 있음
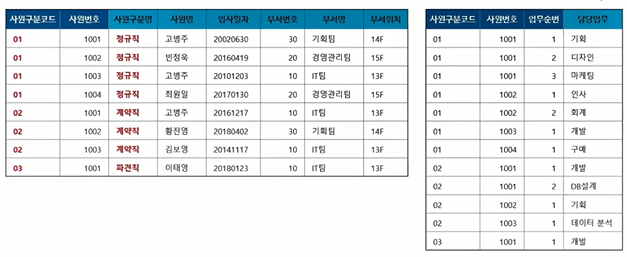
- 테이블을 분리해서 식별자를 통해 다른 테이블로 가서 담당업무를 찾을 수 있음
- 데이터는 쪼개서 관리하고 필요할 때 찾아가서 가져오는 형태로 관리함
- 근데 저 테이블에서도 사원구분코드와 사원구분명이 동일한 내용이니 바꿔줘야함
제 2 정규형 (2차 정규화)
- 주식별자가 아닌 모든 속성이 주식별자 속성에 완전 함수 종속 된다 -> 중복제거!

- 구분코드에 따른 구분명이 바뀌면 저 테이블 하나만 바꿔주면 되니까 이상현상이 발생되지 않음
- 근데 부서관련 내용은 주식별자와 상관없음. 부서번호에 따라 결정되니까 또 갱신이상이 생길 수 있음
제 3 정규형 (3차 정규화)
- 일반 속성들 간에 함수 종속이 존재하지 않는다.
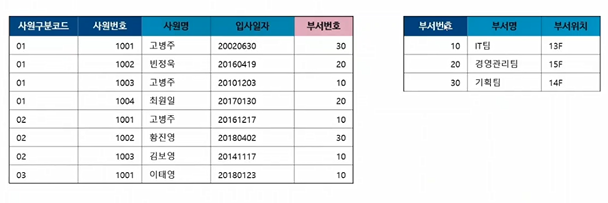
정규화된 데이터 모델

- 이 형태에서 필요한 정보를 SQL로 불러와 조회/추출할 수 있다
Ex. SQL로 동일하게 추출한 것
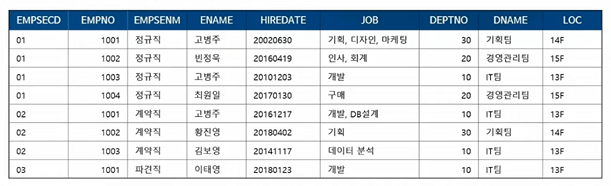
정규화 정리!!!

반정규화(De-Normalization)
- 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발 운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링의 기법 (특정상황에만 사용, 정규화가 일반적)
- 엔터티(테이블) 반정규화, 속성(칼럼) 반정규화(주로사용), 관계 반정규화
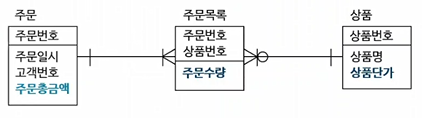
Ex. 주문총금액은 주문수량, 상품단가를 통해 알 수 있지만, 속도가 느려지니까 그냥 넣는 경우임
- 엔터티(테이블) 반정규화, 속성(칼럼) 반정규화(주로사용), 관계 반정규화
- 반정규화를 남용하게되면 시스템 전반적으로 데이터 무결성이 깨질 위험이 있으므로, 꼭 필요한 경우에만 적용해야하며, 데이터 정합성을 지키기위한 별도의 방안을 마련해야한다.
6. 관계형 데이터베이스
관계형 데이터베이스(Realational Database)
- 초기에는 파일 시스템으로 데이터를 관리했지만, 데이터가 증가함에 따라 데이터를 효율적으로 관리할 수 있는 체계가 필요해짐
- 1970년 에드거F.커드(E.F.Codd)박사의 논문에서 처음 소개된 관계형 모델을 채택한 데이터베이스임
- 관계형 데이터베이스는 정규화를 기반으로 한 데이터 모델링을 통해 데이터 이상 현상을 제거하고, 데이터의 중복을 최소화 하여 데이터를 저장함. 또한, 상용 DBMS의 발전으로 인해 많은 사용자들이 동시에 데이터를 공유하고 조작할 수 있게 됨
- 현재 대부분의 기업에서는 주요데이터는 RDBS로 관리되고 있으며, 관계형 데이터베이스의 데이터를 다루는 유일한 언어가 바로 SQL임
데이터 모델과 관계형 데이터 베이스
- 데이터 모델링의 결과물인 데이터 모델(ER모델)을 기반으로 관계형 데이터베이스가 구축됨
- 데이터 모델의 각 요소는 관계형 데이터 베이스에서 아래와 같이 구현됨
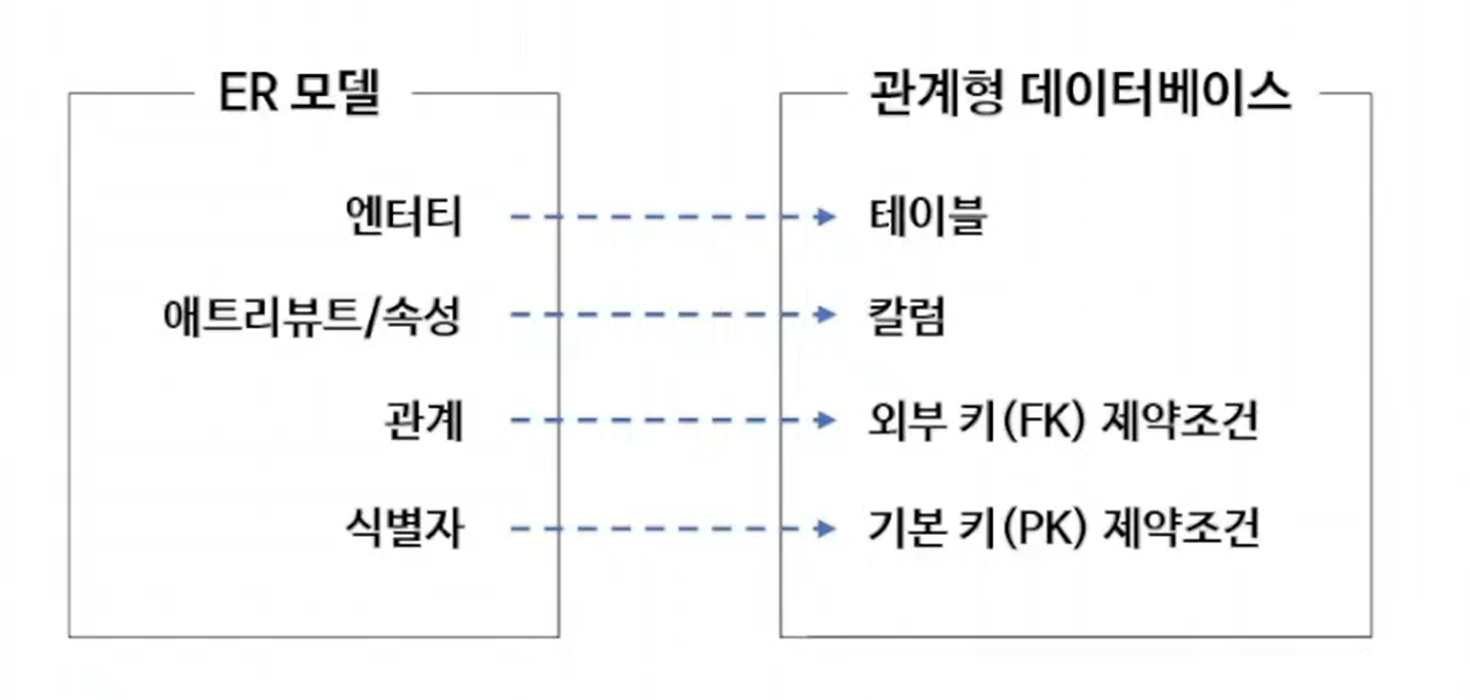
테이블 구조
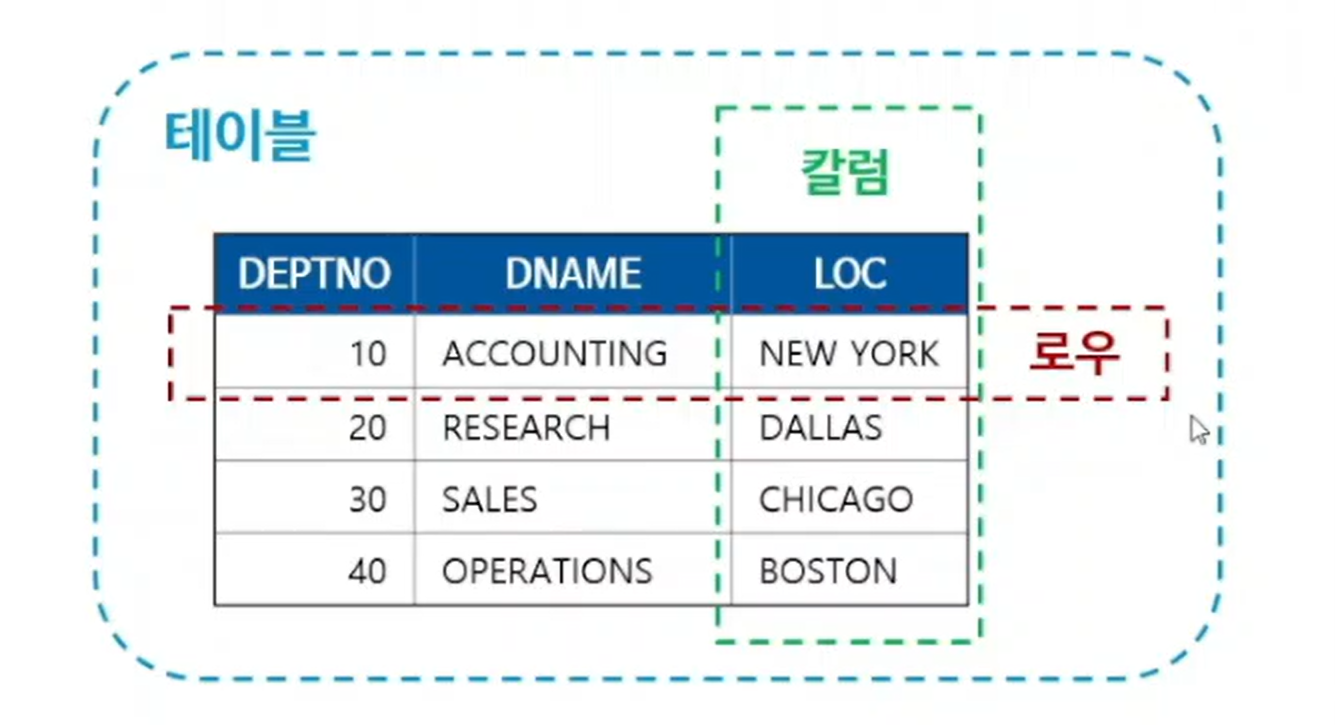
- 테이블(Table)은 데이터를 저장하기 위한 2차원 구조의 객체로, 갈럼과 로우로 이뤄진다
- 엔터티가 물리적으로 구현된 것으로, 관계형 데이터베이스의 가장 기본적인 구성 요소임
- 칼럼 : 속성이 물리적으로 구현된 것, 테이블의 세로
- 로우 : 테이블에 저장된 개별 데이터, 데이터 조회 및 조작의 대상 -> 데이터가 얼마나 있는지 확인 할 수 있음. 내용이 없더라도 행이 있으면 데이터가 있다고 생각함. 언제든지 채워질 수 있으니까.
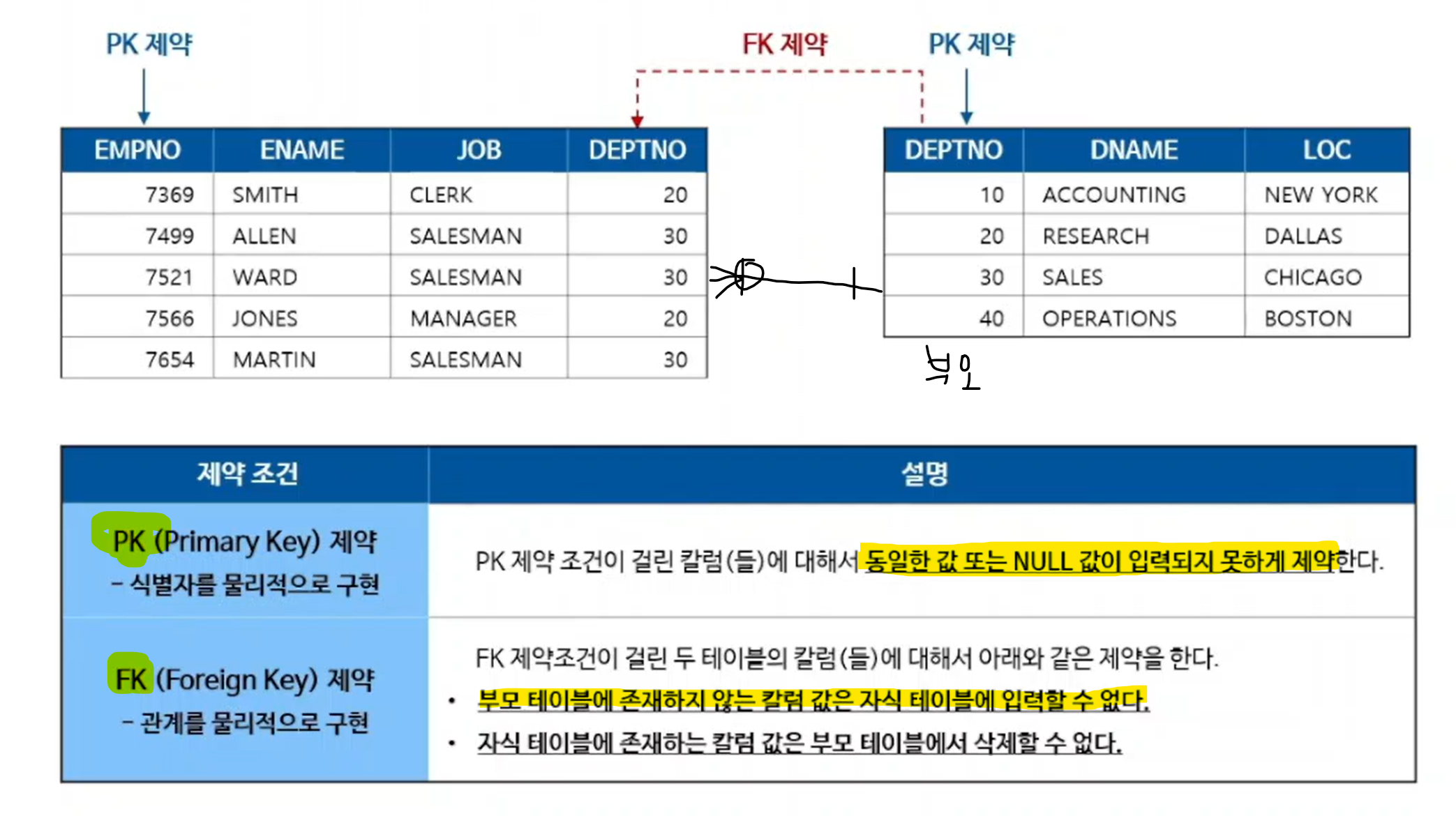
- 식별자와 관계는 관계형 데이터베이스에서 제약 조건으로 구현된다
- 제약조건(Constraint) : 데이터의 품질을 보장하기 위해 특정 조건을 위반하는 데이터가 입력되지 않도록 하는 DBMS의 기능
- PK제약 : 식별자(중복, 빈 데이터를 제약함)
- FK제약 : 관계(칼럼간의 제약 - 부모테이블에 없으면 자식테이블에도 없도록!)
- 자식쪽에 데이터가 있으면 부모쪽 데이터를 없앨 수 없음
- 자식쪽에 데이터가 있으면 부모쪽 데이터를 없앨 수 없음
SQL(Structured Query Language)
- SQL은 관계형 데이터베이스의 표준 언어
- SQL은 구조적(structure), 집합적(set-base), 선언적(declarative)인 언어임
- 원하는 결과 집합을 구조에 맞춰 질의할 뿐, 구체적인 프로세싱 과정은 프로그래밍 하지 않아도 됨
- 자연어에 가까운 언어기때문에, 프로그래머가 아니더라도 쉽게 접근할 수 있음
- 선언적 : SQL로 하는 것은 어떤 데이터를 보고 싶다고 선언만 하는 것! 내부적인 과정은 DBMS에서 처리해줌
- SQL 문의 종류


차보의 Data Engineer 도전기♥ (근데 기록을 곁들인)