기존에 Sequel Pro 에 이어 Sequel Ace 를 사용하며 데이터 마이그레이션 작업을 불편함없이 해왔었는데, 사이드 프로젝트에서 PostgreSQL 을 채택하면서 DataGrip 으로 GUI 툴을 변경하게 되었습니다.
하지만 로컬 개발 환경에서 빈번하게 일어나는 DB Scheme 및 데이터 마이그레이션 작업을 dump 를 통해 DataGrip 에서 수행하려니 불편한 점이 많았습니다.
먼저, DataGrip 에는 기본적으로 DB Structure 와 데이터 모두를 dump 하는 기능이 빌트인으로 제공되지 않기 때문에 MySQL Workbench 의 mysqldump 나 PostgreSQL 의 pg_dump 파일을 별도로 설치하여 dump 파일을 생성하여야 합니다.
이 때문에 로컬에 PostgreSQL DB 설치없이 psql 이나 pg_dump 를 설치하는 방법에 대해 별도로 포스팅하였습니다.
또한, MySQL dump 파일을 생성해 새로운 DB 에 적용하는 과정에서 기존에는 만나볼 수 없었던 이슈를 마주치기도 했습니다.
이는 MySQL Workbench 에서 dump 파일을 생성하는 방식때문에 발생하는 오류로, 생성된 dump 파일을 열어 문제가 발생하는 쿼리를 주석 처리 혹은 제거함으로서 해결할 수 있었습니다.
따라서 이번 포스팅에서는 DataGrip 에서 sqldump 파일을 활용하여 DB Scheme 과 데이터를 모두 마이그레이션 하는 방법에 대해 간략히 정리하고, 발생했던 오류를 해결했던 과정에 대해 작성해보겠습니다.
1. Export sqldump
sqldump 백업은 .sql 파일을 생성하여 실행하는 방식으로 이루어지게 되며, 파일 내부는 테이블의 Structure 를 생성하는 DDL, 존재하는 데이터를 모두 Insert 하는 DML 로 구성되어 있습니다.
다시 말해 sqldump 파일에는 대상 테이블의 구조와 데이터가 모두 SQL 로 작성되어있기 때문에, 이관 대상 DB 나 Scheme 에서 해당 SQL 파일을 실행하여 동일한 테이블 구조와 데이터를 생성하는 방식으로 마이그레이션이 이루어지게 되는 것입니다.
이러한 백업 방식은 DB 의 버전이나 환경에 큰 제약을 받지 않고 수행이 가능하다는 장점이 있으며, .sql 파일의 내용으로 테이블 구조를 직접 확인하거나 수정할 수 있어, 작은 크기의 DB 마이그레이션에 자주 활용되는 방식입니다.
1) 먼저, DataGrip 의 사이드 바에서 백업 대상 DB 혹은 Scheme 을 우클릭합니다.
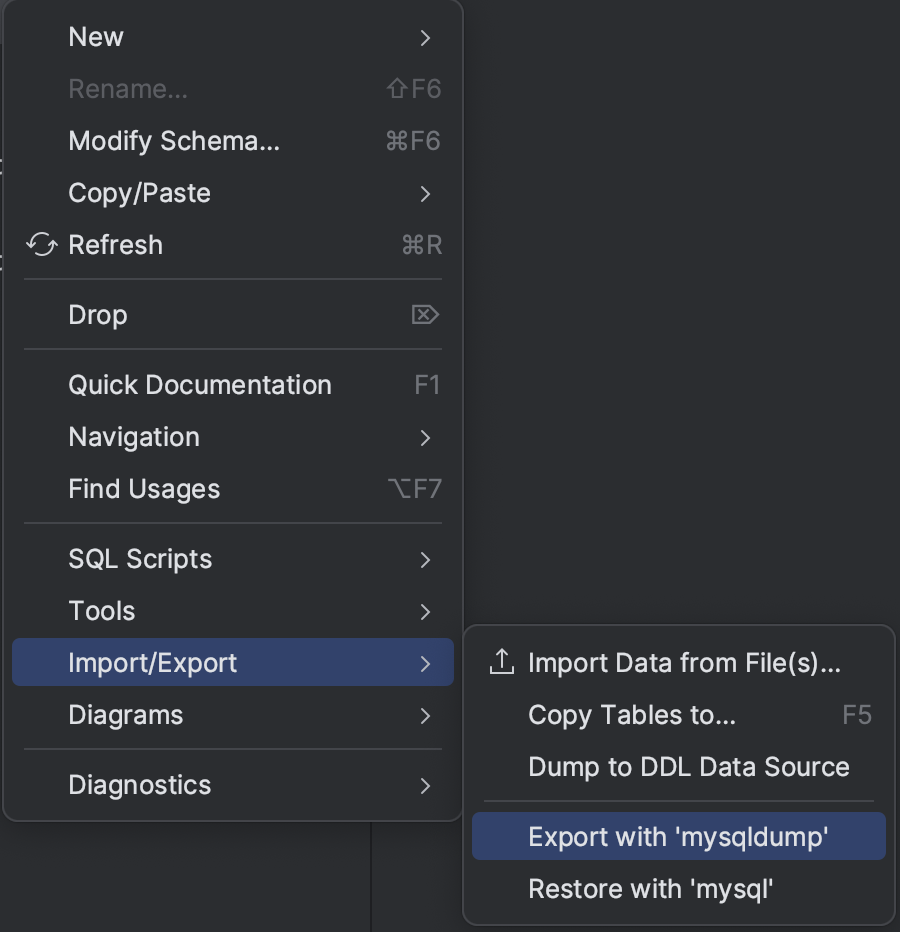
- 사용하는 DBMS 에 따라 'mysqldump' 혹은 'pg_dump' 등의 옵션명은 다를 수 있으며, 리스트의 Export 버튼을 선택합니다.
2) sqldump 옵션을 구성하고 파일을 생성합니다.

-
Path to mysqldump에는 mysqldump 파일의 경로를 입력합니다.
MySQL Workbench 를 설치하였을 경우, macOS 기준 기본 경로는 아래와 같습니다.
/Applications/MySQLWorkbench.app/Contents/MacOS/mysqldump -
Statements에는--complete-insert옵션의 사용 여부를 지정하며,
Insert with columns를 선택할 경우, 생성하는 모든 INSERT 구문에 컬럼명을 포함하여 작성됩니다. -
Multiple rows inserts에는--extended-insert옵션의 사용 여부를 지정하며,
체크할 경우 여러 데이터 로우의 추가 행위를 하나의 INSERT 문으로 작성합니다. -
Add drop table에는--add-drop-table옵션의 사용 여부를 지정하며,
체크할 경우 CREATE TABLE 구문 전에 DROP TABLE 구문을 추가합니다. -
Disable keys에는--disable-keys옵션의 사용 여부를 지정하며,
체크할 경우 데이터 로드 시에 외부 키 제약사항 체크를 무효화하여 더욱 빠르게 로드할 수 있습니다. -
Delayed inserts에는--delayed-inserts옵션의 사용 여부를 지정하며,
체크할 경우 INSERT 대신 INSERT_DELAYED 구문을 사용하게 됩니다.
MyISAM 과 같이 트랜잭션을 지원하지 않는 스토리지 엔진에서 사용됩니다. -
Exports schema without data에는--no-data옵션의 사용 여부를 지정하며,
체크할 경우 데이터를 입력하지 않습니다. -
MySQL create table options에는--create-options옵션의 사용여부를 지정하며,
체크할 경우 CREATE TABLE 구문 내에 모든 테이블 제약사항 옵션을 추가하여 작성합니다. -
Lock tables에는--lock-tables옵션의 사용여부를 지정하며,
체크할 경우 각각의 테이블에 대한 dump 수행 전 해당 테이블에 READ Lock 을 걸게 됩니다.
하지만 각각의 테이블에 READ Lock 을 수행하기 때문에 DB 내 모든 테이블에 대한 일관성을 보장할 수는 없습니다. 즉, 각각의 테이블은 서로 다른 시점에서 dump 될 수 있습니다.
트랜잭션을 지원하지 않는 MyISAM 테이블에서 사용하는 옵션입니다. -
추가적으로, 트랜잭션을 지원하는 InnoDB 테이블의 경우
--single-transaction옵션을 사용하여야 합니다.
이 옵션을 사용하면, REPEATABLE READ 레벨에서 dump 를 수행하게 되어 동시성을 보장할 수 있습니다.
주의할 점은--single-transaction을 사용한 dump 수행 시, 다른 연결에서는 DDL 을 수행해서는 안된다는 것입니다. 일관성있는 dump 를 위해서는 다른 연결로부터 테이블 레벨 Lock 을 허용해서는 안됩니다.
또한--lock-tables와--single-transaction옵션은 서로 배타적이기 때문에 함께 사용할 수 없습니다. -
Add locks는--add-locks옵션의 사용 여부를 지정하며,
체크할 경우 dump 파일 테이블의 앞뒤로 LOCK TABLES 와 UNLOCK TABLES 구문을 삽입합니다. 이렇게 하면 dump 파일을 다시 로드할 때 삽입 속도를 향상시킬 수 있습니다. -
Add drop trigger는--add-drop-trigger옵션의 사용 여부를 지정하며,
체크할 경우 트리거 생성 구문 작성 전에 DROP TRIGGER 구문을 삽입합니다. -
Our path에는 생성된.sql파일이 저장될 위치를 지정합니다.
DataSource 와 Database name, TimeStamp 를 파일명으로 지정하였으며, 확장자인.sql까지 작성해주어야 합니다. -
모두 설정되었다면, Run 버튼을 클릭하여 dump 파일 생성을 시작합니다.
2. Import sqldump
이제 새로운 DB 혹은 Scheme 에서 생성된 dump 파일을 실행합니다.
1) 새로운 DB 혹은 Scheme 을 생성합니다.
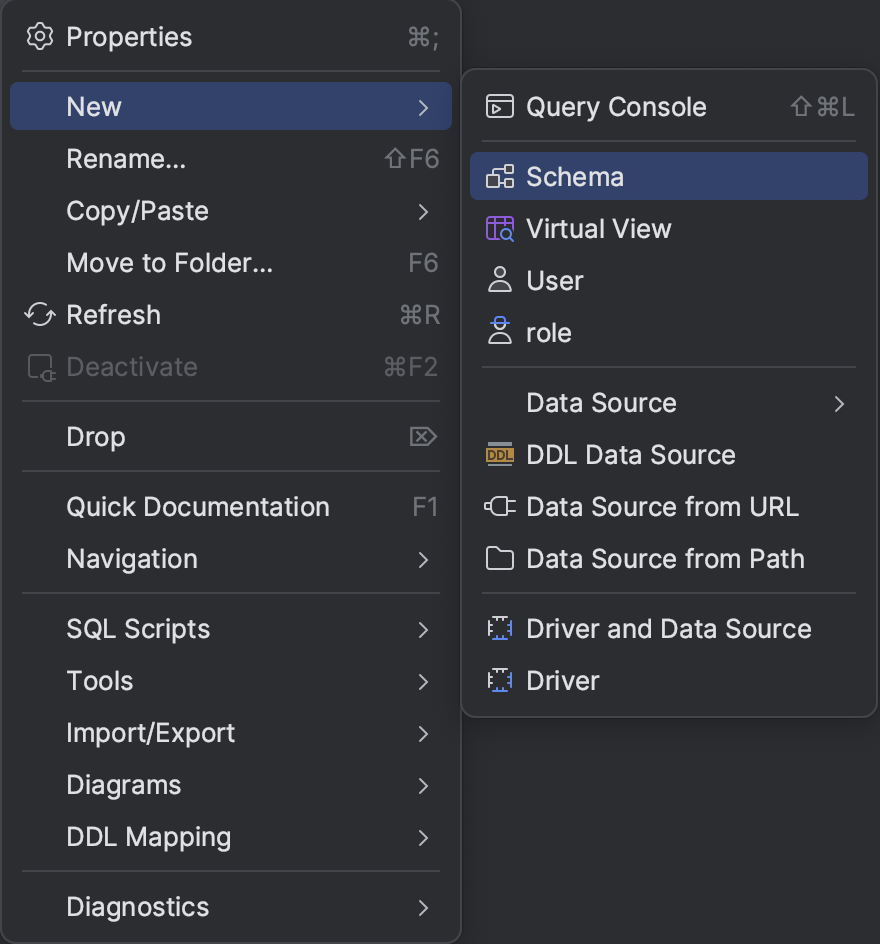
- DB 를 우클릭한 뒤, 새로운 Scheme 을 생성합니다.
2) 앞서 생성한 dump 파일을 DataGrip 으로 Drag & Drop 합니다.
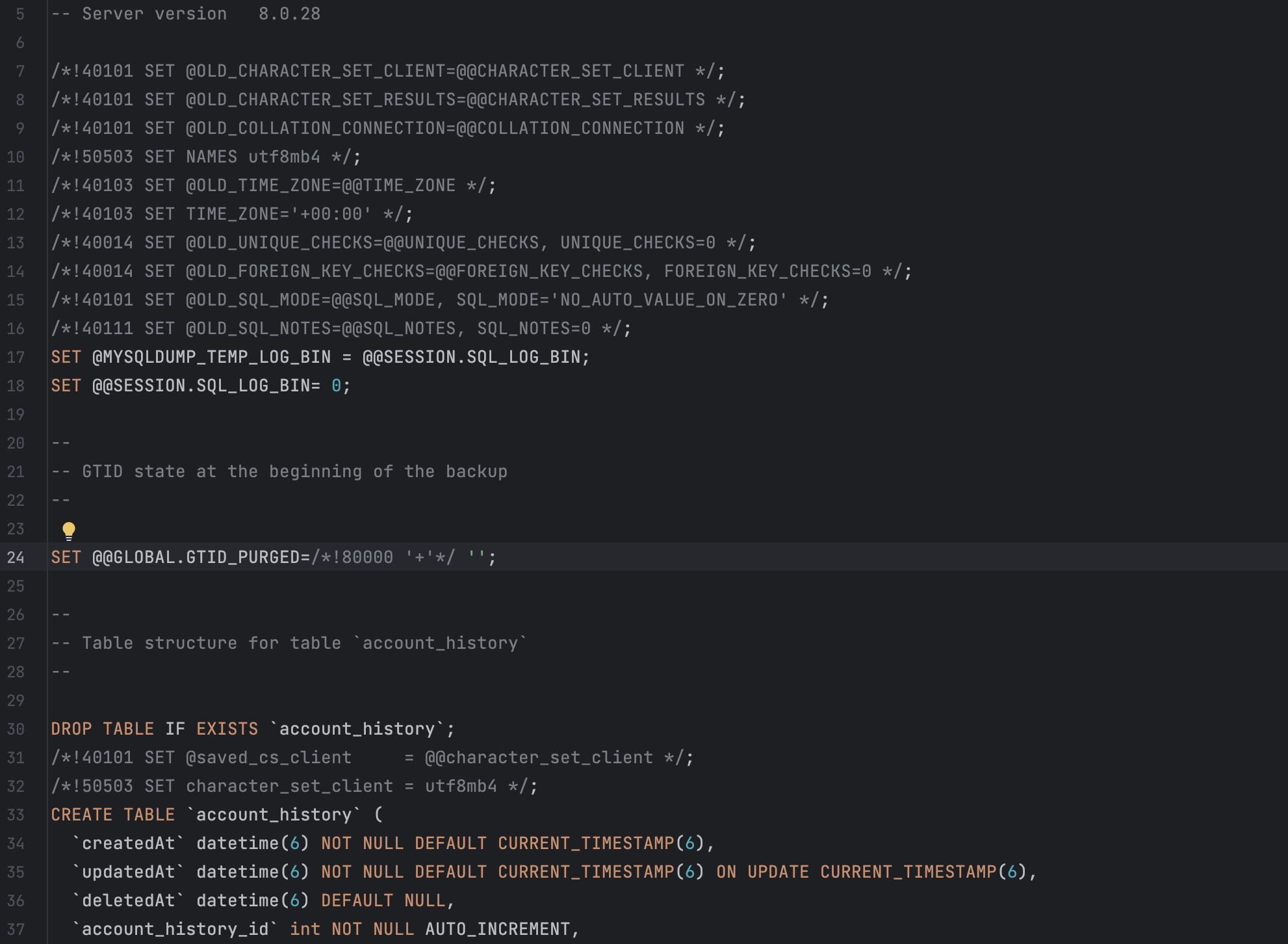
- 생성된 dump 파일 내 작성된 SQL 을 확인할 수 있습니다.
3) dump 파일을 실행합니다.
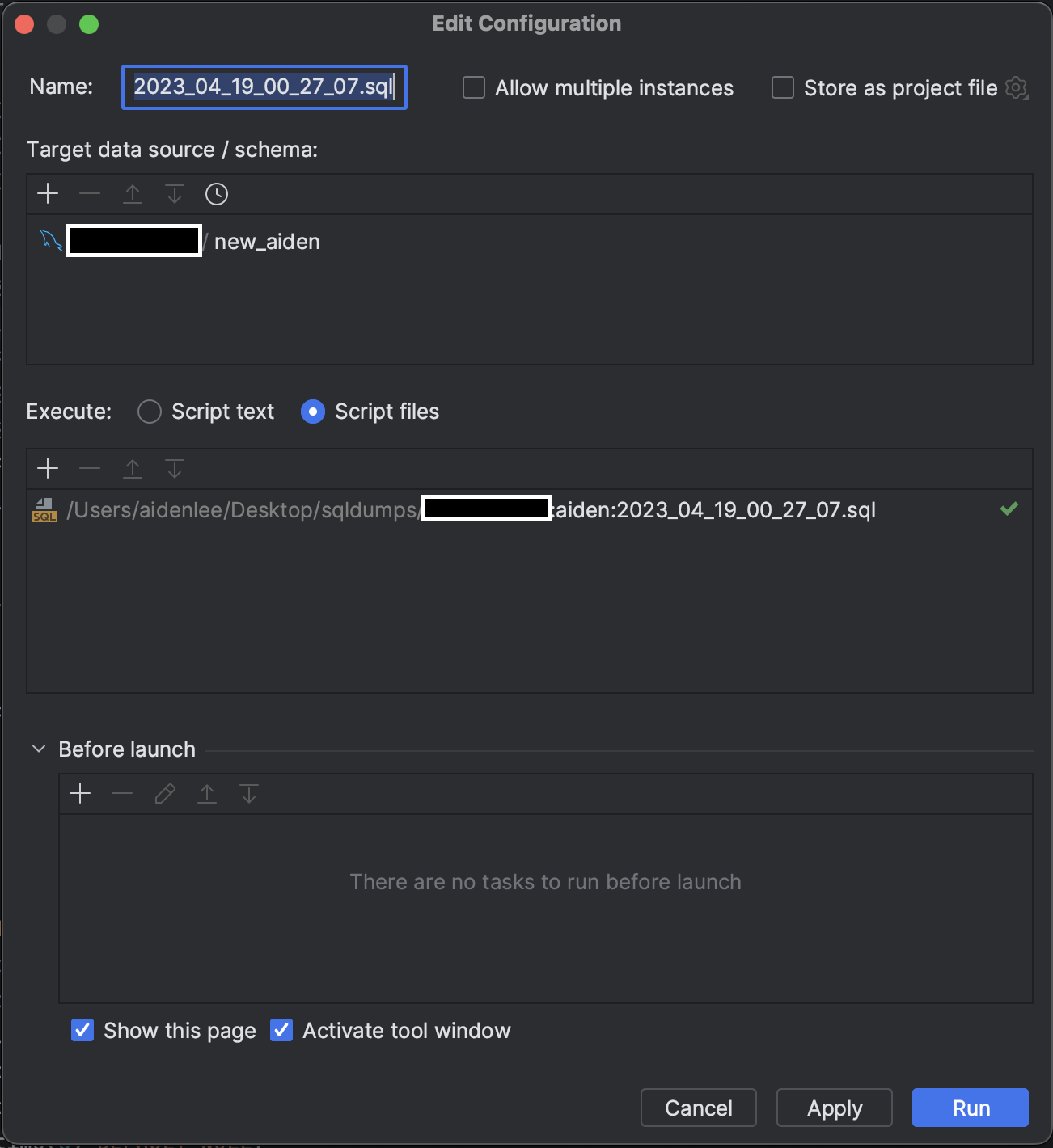
- 화면 우클릭 후 나타난 리스트에서 'Run ...' 버튼을 선택합니다.
- 마이그레이션 대상 data source 와 scheme 을 선택합니다.
- 하단의 Run 버튼을 클릭하여 파일을 실행합니다.
Error: Access Denied
제 경우에는 모든 테이블과 데이터는 정상적으로 생성되었지만, 3개의 SQL 구문이 실패하였다는 로그를 확인할 수 있었습니다.

실패한 3개의 SQL 구문을 확인해보면,
SET @@SESSION.SQL_LOG_BIN= 0
[2023-04-19 00:42:17] [42000][1227] Access denied; you need (at least one of) the SUPER, SYSTEM_VARIABLES_ADMIN or SESSION_VARIABLES_ADMIN privilege(s) for this operation
SET @@GLOBAL.GTID_PURGED=/*!80000 '+'*/ ''
[2023-04-19 00:42:17] [42000][1227] Access denied; you need (at least one of) the SUPER or SYSTEM_VARIABLES_ADMIN privilege(s) for this operation
SET @@SESSION.SQL_LOG_BIN = @MYSQLDUMP_TEMP_LOG_BIN
[2023-04-19 00:42:38] [42000][1227] Access denied; you need (at least one of) the SUPER, SYSTEM_VARIABLES_ADMIN or SESSION_VARIABLES_ADMIN privilege(s) for this operation각각 LOG 관련 설정, GTID 관련된 설정임을 확인할 수 있으며
SQL 파일을 실행하는 사용자에게 SUPER 권한이 존재하지 않아 발생한 오류임을 확인할 수 있습니다.
사실 이와 같은 구문이 생성되는 근본적인 원인은 MySQL 의 GTID 에 있습니다.
MySQL 에서는 Replica Set 구성 시 GTID(Global Transaction Identifier) 라는 개념을 선택적으로 사용할 수 있습니다.
GTID 는 MySQL 의 모든 트랜잭션과 1:1 관계를 맺고 있기 때문에 서버의 각 트랜잭션을 구분하는 고유한 식별자로서 사용될 수 있어, master 와 slave 간 복제 시 GTID 만으로 Replica Set 과의 일관성을 확인할 수 있다는 장점이 있습니다.
GTID 를 가지는 트랜잭션이 Commit 되면 binary log 에 정보가 저장되고, 이 binary log 를 기반으로 동일한 GTID 를 가지는 후속 트랜잭션들은 무시됨으로서 결과적으로 Replica Set 과의 일관성을 보장할 수 있는 것입니다.
따라서 GTID 가 적용된 서버에서 mysqldump 를 수행할 경우, dump 작업 로드 시 binary logging 을 사용하지 않도록 설정하여 원본 GTID 를 유지하기 위해 위와 같은 SQL 이 자동으로 생성되는 것입니다.
하지만 위 SQL 실행이 사용자의 SUPER PRIVILEGE 권한을 필요로 하는 것과는 반대로, Amazon RDS 에서는 보안을 위해 SUPER 권한을 가진 사용자 생성을 허용하지 않습니다.
따라서 공식 문서에서는 생성된 dump 파일에 위와 같은 구문이 존재하는지 확인하고, 존재한다면 제거 혹은 주석 처리할 것을 권장하고 있습니다.
저는 Amazon RDS 를 사용하고 있기 때문에 공식 문서에서 설명한 대로 관련한 SQL 구문을 모두 제거해주었습니다.
SET @MYSQLDUMP_TEMP_LOG_BIN = @@SESSION.SQL_LOG_BIN;
SET @@SESSION.SQL_LOG_BIN= 0;
SET @@GLOBAL.GTID_PURGED=/*!80000 '+'*/ '';
SET @@SESSION.SQL_LOG_BIN = @MYSQLDUMP_TEMP_LOG_BIN;관련 로그를 모두 제거한 뒤, 다시 dump 파일을 실행하면 아래와 같이 정상적으로 백업이 완료된 것을 확인할 수 있습니다.

