Let’s take a closer look at the difference:
차이점을 자세히 살펴보겠습니다.

However, there is a problem on the TCP side.
그러나 이것은 TCP 측면에서 문제가 있습니다.
You see, because TCP is a much older protocol and not made for just loading web pages, it doesn’t know about A, B, or C.
TCP는 매우 오래된 프로토콜이고 단지 웹페이지 로딩을 위해 만들어지지 않았기 때문에, 그것은 A, B 또는 C에 관하여 알지 못합니다.
Internally, TCP thinks it’s transporting just a single file, X, and it doesn’t care that what it views as XXXXXXXXXXXX is actually AABBCCAABBCC at the HTTP level.
내부적으로 TCP는 하나의 파일 X만 전송하고 있다고 생각하며, 실제로는 HTTP 수준에서 AABBCCAABBCC로 본다는 사실을 신경쓰지 않습니다.
(In most situations), this /doesn’t matter/ (and it actually makes TCP quite flexible!), but that changes (when there is, for example, packet loss on the network).
이러한 상황은 네트워크에서 패킷 손실이 발생할 때 변합니다. 대부분의 상황에서는 이것이 문제가 되지 않습니다(사실, TCP를 상당히 유연하게 만듭니다!)
Suppose the third TCP packet is lost (the one containing the first data for file B), but all of the other data are delivered.
세 번째 TCP 패킷이 손실되었지만(파일 B의 첫 번째 데이터를 포함하는 것), 다른 모든 데이터는 전송되었습니다.
TCP /deals/ with this loss by retransmitting a new copy of the lost data in a new packet.
TCP는 손실된 데이터의 새 복사본을 새 패킷으로 재전송함으로써 이 손실을 처리합니다.
This retransmission can, however, take a while to arrive (at least one RTT).
그러나, 이 재전송은 도착하는데 시간이 걸릴 수 있습니다(최소 하나의 RTT).
You might think that’s not a big problem, as we see there is no loss for resources A and C.
자원 A와 C에 손실이 없다는 것을 알 수 있기 때문에 큰 문제가 아니라고 생각할 수도 있습니다.
As such, we can start processing them while waiting for the missing data for B, right?
따라서 B에 대한 누락된 데이터를 기다리는 동안 처리를 시작할 수 있죠?
Sadly, (that’s not the case), because the retransmission logic/ happens/ at the TCP layer, and TCP/ does not know/ about A, B, and C!
안타깝게도 재전송 로직이 TCP 계층에서 발생하고 TCP는 A, B, C에 대해 알지 못하기 때문에 그렇지 않습니다!
TCP/ instead thinks/ (that a part of the single X file has been lost), and thus it feels (it has to keep the rest of X’s data from being processed) until (the hole is filled).
TCP는 대신에 X 파일의 일부가 손실되었다고 생각하기 때문에 구멍이 메워질 때까지 X의 나머지 데이터가 처리되지 않도록 해야 한다고 생각합니다.
Put differently, while at the HTTP/2 level, we know that we could already process A and C, TCP/ does not know/ this, causing things to be slower than they potentially could be.
달리 말하면, HTTP/2 수준에서는 이미 A와 C를 처리할 수 있다는 것을 알고 있지만, TCP는 이를 알지 못해 잠재적인 것보다 작업 속도가 느려집니다.
This inefficiency is an example of the “head-of-line (HoL) blocking” problem.
이러한 비효율성은 "Head-of-line(HoL) 차단" 문제의 한 예입니다.
Solving HoL blocking at the transport layer was one of the main goals of QUIC.
전송 계층에서의 HoL 차단을 해결하는 것이 QUIC의 주요 목표 중 하나였습니다.
Unlike TCP, QUIC is intimately aware that it is multiplexing multiple, independent byte streams.
TCP와 달리 QUIC는 독립적인 여러 바이트 스트림을 다중화하고 있다는 것을 밀접하게 인식하고 있습니다.
It/, (of course), doesn’t know/ (that it’s transporting CSS, JavaScript, and images); it/ (just) knows/ (that the streams are separate).
물론 CSS, 자바스크립트 및 이미지를 전송한다는 것은 알 수 없지만 스트림이 별개라는 것만 알 수 있습니다.
(As such), QUIC/ can perform/ packet loss detection and recovery logic (/on a per-stream basis).
따라서 QUIC는 스트림 단위로 패킷 손실 감지 및 복구 로직을 수행할 수 있습니다.
(In the scenario above), it/ would only hold back/ the data for stream B, and unlike TCP,/ it would deliver any data for A and C to the HTTP/3 layer as soon as possible.
위의 시나리오에서는 스트림 B에 대한 데이터만 보류하고 TCP와는 달리 A와 C에 대한 모든 데이터를 가능한 한 빨리 HTTP/3 계층으로 전달합니다.
(This is illustrated below.)
(아래 그림에 나와 있습니다.)
In theory, this could lead to performance improvements.
이론적으로 이는 성능 향상으로 이어질 수 있습니다.
In practice, however, the story is much more nuanced, as we’ll discuss in part 2.
그러나 실제로는 2부에서 논의할 것이기 때문에 이야기가 훨씬 더 미묘합니다.
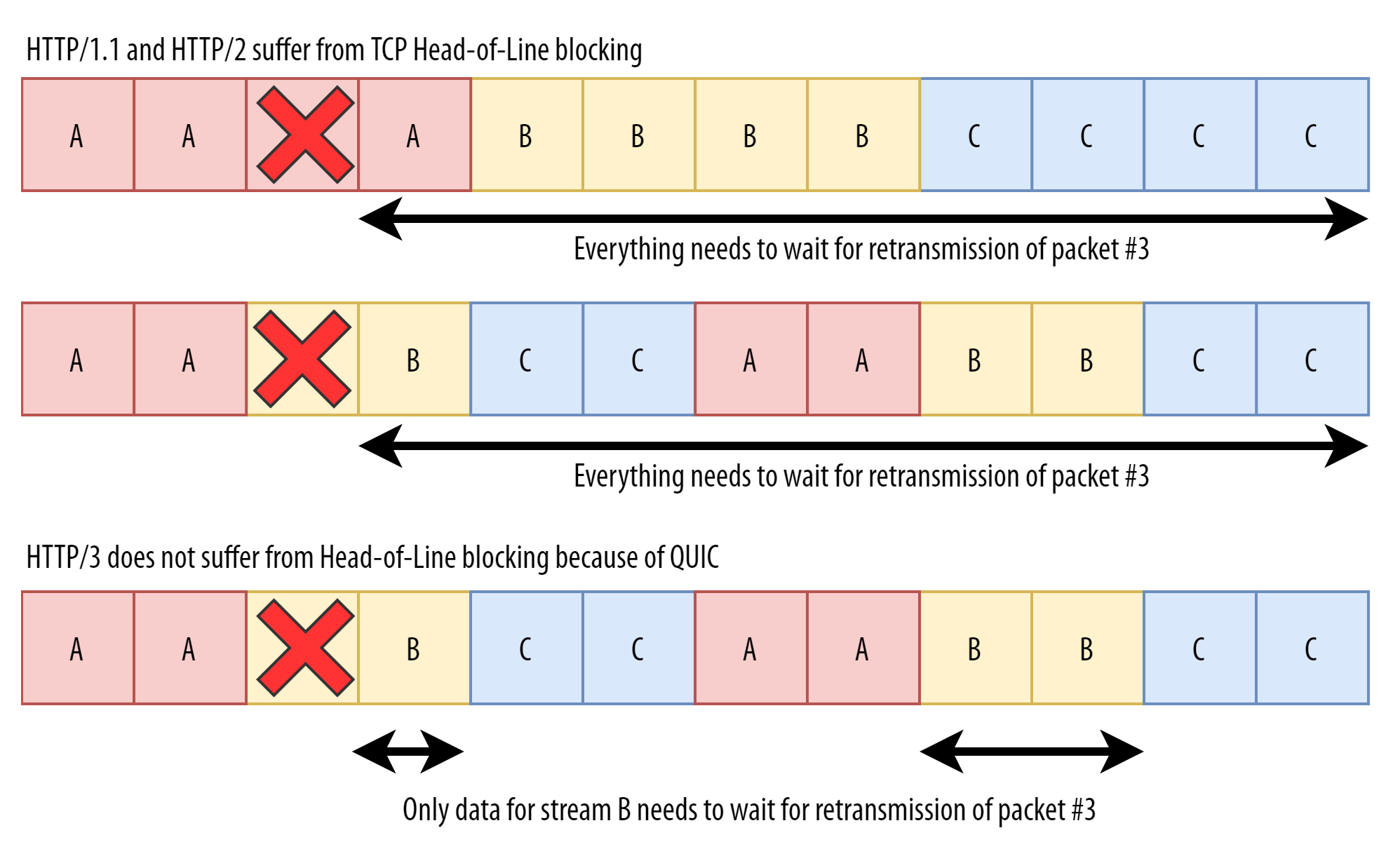
We can see that we now have a fundamental difference between TCP and QUIC.
우리는 이제 TCP와 QUIC 사이에 근본적인 차이가 있음을 알 수 있습니다.
This is, incidentally, also one of the main reasons why we can’t just run HTTP/2 as is over QUIC.
이것은 부수적으로, 우리가 QUIC를 통해 HTTP/2를 그냥 실행할 수 없는 주요한 이유 중 하나이기도 합니다.
As we said, HTTP/2/ also includes/ a concept of running multiple streams over a single (TCP) connection.
앞서 말한 바와 같이, HTTP/2는 또한 단일(TCP) 연결을 통해 여러 개의 스트림을 실행하는 개념을 포함합니다.
As such, HTTP/2-over-QUIC would have two different and competing stream abstractions on top of one another.
이와 같이 HTTP/2-over-QUIC에는 서로 다른 경쟁 스트림 추상화가 두 개 있습니다.
Making them work together (nicely) would be very complex and error-prone;
이들을 잘 결합시키는 것은 매우 복잡하고 오류가 발생하기 쉽습니다.
so, one of the key differences between HTTP/2 and HTTP/3 is that the latter removes the HTTP stream logic and reuses QUIC streams instead.
따라서 HTTP/2와 HTTP/3의 주요 차이점 중 하나는 후자가 HTTP 스트림 로직을 제거하고 대신 QUIC 스트림을 재사용한다는 것입니다.
(As we’ll see in part 2, though), this/ has/ other repercussions in how features (such as server push, header compression, and prioritization) are implemented.
그러나 파트 2에서 살펴보겠지만, 이는 서버 푸시, 헤더 압축, 우선순위 지정 등과 같은 기능이 어떻게 구현되는지에 따라 다른 영향을 미칩니다.
Takeaway
The key takeaway here is that TCP was never designed to transport multiple, independent files over a single connection.
여기서 중요한 점은 TCP가 단일 연결을 통해 여러 개의 독립적인 파일을 전송하도록 설계된 적이 없다는 것입니다.
Because that is exactly what web browsing requires, this has led to many inefficiencies over the years.
그것이 바로 웹 브라우징에 필요한 것이기 때문에, 이것은 수년 동안 많은 비효율을 초래했습니다.
QUIC/ solves /this by making multiple byte streams a core concept at the transport layer/ and handling packet loss on a per-stream basis.
QUIC는 전송 계층에서 여러 바이트 스트림을 핵심 개념으로 만들고 스트림 단위로 패킷 손실을 처리함으로써 이를 해결합니다.
모르는 단어
intimately: 직접적으로, 상세하게, 친밀히
nuanced: 미묘한
incidentally: 부수적으로, 우연히
latter 후자의 ,나중의, 뒤쪽의
원글: https://www.smashingmagazine.com/2021/08/http3-core-concepts-part1/
