Hash index
해시 테이블은 데이터 요소의 주소/인덱스 값이 해시 함수에서 생성되는 데이터 구조 유형이다. 인덱스 값이 데이터 값에 대한 키로 동작하므로 매우 빠른 데이터 액세스가 가능하다.
해시 테이블은 키-값 쌍을 저장하지만 키는 해싱 함수를 통해 생성된다. 따라서 키 값 자체가 데이터를 저장하는 배열의 인덱스가 되기 때문에 데이터 요소의 검색 및 삽입 기능이 훨씬 빨라진다. 조회하는 동안 키가 해시되고 결과 해시는 해당 값이 저장된 위치를 나타낸다.
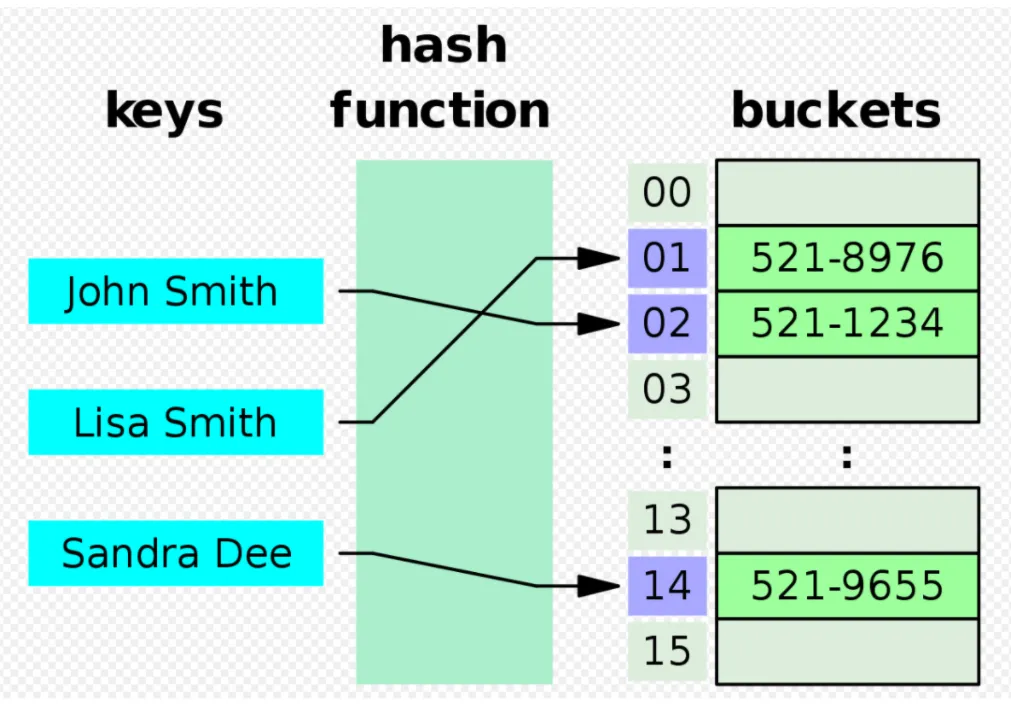
해싱의 개념은 버킷 배열에 항목(키/값 쌍)을 배포하는 것이다. 키가 주어지면 알고리즘은 항목을 찾을 수 있는 위치를 제안하는 인덱스를 계산한다.
B-tree index
최대 2개의 자식 노드만을 가지는 이진탐색트리(BST)를 일반화하여 2개 이상의 자식 노드를 가질 수 있도록 확장한 균형 트리이다.
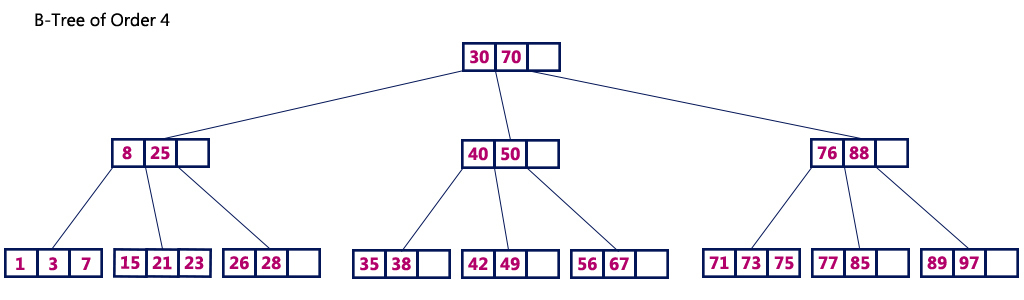
자녀 노드의 최대 개수를 원하는대로 결정해서 사용할 수 있다.
최대 m 개의 자녀를 가질 수 있는 B-tree를 m 차 B-tree 라고 한다.
m : 각 노드의 최대 자녀 노드 수
m - 1 : 각 노드의 최대 key 수
m / 2 (올림) : 각 노드의 최소 자녀 노드 수
m / 2 (올림) - 1 : 각 노드의 최소 key 수속성
-
모든 리프 노드는 동일한 수준에 있어야 한다.
-
루트를 제외한 모든 노드에는 최소 [m/2]-1개의 키와 최대 m-1개의 키가 있어야 한다.
-
루트를 제외한 모든 비 리프 노드(즉, 모든 내부 노드)에는 최소 m/2개의 자식이 있어야 한다.
-
루트 노드가 리프 노드가 아닌 경우 최소 2개의 자식이 있어야 한다.
-
n-1 개의 키가 있는 비 리프 노드에는 n개의 자식이 있어야 한다.
-
노드의 모든 키 값은 오름차순 이어야 한다.
차이점
1. 검색 방법
-
Hash 인덱스 : 해시 함수를 사용하여 키를 해싱하고, 해시 테이블에 저장한다. 해시 테이블은 해시 값과 해당하는 데이터 레코드의 포인터를 저장한다. 따라서 검색 시 해시 값을 계산하여 해당하는 위치로 바로 이동하여 데이터를 찾는다. 이는 일반적으로 O(1)의 시간 복잡도를 가진다.
-
B-Tree 인덱스 : B-Tree 는 이진 트리의 확장된 형태로, 노드당 여러 키를 가질 수 있다. 이진 탐색 트리와는 달리 균형을 유지하며, 각 노드의 자식은 키 값에 대한 범위를 가진다. 따라서 검색 시 루트부터 시작하여 트리를 탐색하며 원하는 키를 찾는다. 이는 일반적으로 O(log n)의 시간 복잡도를 가진다.
2. 범위 검색
-
Hash 인덱스 : 해시 함수를 사용하기 때문에 키의 범위 검색이 어렵다. 범위 검색을 하려면 모든 해시 값에 대해 순차적으로 탐색해야 한다.
-
B-Tree 인덱스 : B-Tree는 범위 검색에 효과적이다. 각 노드가 키 값에 대한 범위를 가지기 때문에 범위 검색 시에도 효율적으로 데이터를 찾을 수 있다.
3. 데이터 정렬
-
Hash 인덱스 : 해시 함수를 사용하기 때문에 데이터가 해시 값에 따라 무작위로 배치된다.
-
B-Tree 인덱스 : B-Tree는 키 값에 따라 정렬된 상태로 데이터가 저장된다.
4. 인덱스 크기
-
Hash 인덱스 : 일반적으로 B-Tree 인덱스보다 작은 크기를 가진다. 하지만 해시 충돌이 발생할 경우 공간 효율성이 저하될 수 있다.
-
B-Tree 인덱스 : Hash 인덱스보다 큰 크기를 가질 수 있다.
5. 적용 가능성
-
Hash 인덱스 : 등 값이 정확히 일치해야 하는 경우에 유용하다. 예를 들어 고유한 식별자를 가진 테이블에 매우 적합하다.
-
B-Tree 인덱스 : 범위 검색이나 정렬된 데이터에 대한 검색이 필요한 경우에 유용하다. 대다수의 상황에서 일반적으로 사용된다.
정리
Hash table 은 O(1)으로 탐색시간이 빠르지만 이는 단 하나의 데이터를 탐색하기 때문이다. 또한 저장되는 값들은 정렬되어 있지 않기 때문에 특정 값보다 크거나 작은 값을 찾을 수 없다. 그리고 해시 충돌이 발생할 경우, 성능 저하의 문제와 탐색에 걸리는 시간이 증가 할 수 있다.
반면에 B-Tree를 사용할 경우 평균적으로 O(logN)이라는 빠른 성능으로 탐색, 삽입, 수정, 삭제할 수 있으며, 정렬이 되어 있기 때문에 >,< 과 같은 범위탐색에 효율적으로 접근할 수 있다. 또한 노드마다 배열로 구현되어 있기 때문에 참조포인터를 RB-Tree 에 비해 조금 사용하여 방대한 데이터 접근에 더 적합하다.
따라서 DataBase 의 여러 고려사항을 따졌을 때 B-Tree 가 가장 적합한 자료구조로 채택이 된다.
출처
