GCP 빅쿼리 도입 후기에 관한 내용입니다. 특정 서비스를 위한 인프라 관리와 비용에 부담을 느끼던 차에 빅쿼리를 도입하게 되었습니다. 전체적으로 만족하지만 기대와는 달리 주의할 점이 있어 관련 내용을 쓰고자 합니다.
빅쿼리란?
빅쿼리는 Dremel이라는 논문을 근간으로 하는 데이터 웨어하우스 입니다. (링크) RDBMS에서 사용하는 SQL을 지원하기에 데이터 베이스라고 착각했었는데 이 때문에 추후 기능 구현할 때에 큰 차질이 있었습니다.
데이터 웨어하우스와 데이터베이스의 차이를 간단히 설명하자면 데이터베이스는 신속한 CRUD 작업에 최적화되어 있는 반면 데이터 웨어하우스는 여러 개의 대규모 데이터 저장소에 걸쳐 발생하는 소규모의 복잡한 쿼리에 최적화되어 있습니다.
빅쿼리 특징
- 클라우드 서비스로 설치/운영이 필요 없음
- SQL 언어 사용
- 클라우드 스케일의 인프라를 통한 대용량 지원과 빠른 성능
- 데이터 복제를 통한 안정성
- 배치와 스트리밍 모두 지원
비용
- 저장된 데이터 사이즈와 쿼리 시 발생되는 트랜잭션 비용만큼 과금
- 데이터 요금 GB 당 0.02$ 단, 90일 지나서 사용되지 않는 데이터는 자동으로 0.01$
- 트랜잭션 비용은 쿼리 수행 시 스캔되는 데이터 기준으로 TB당 $5 (월 1TB는 무료)
왜 도입했나
특정 서비스를 위해 기존에는 엘라스틱 서치를 사용했습니다. 하지만 엘라스틱 서치를 사용하면서 몇 가지 문제가 있었습니다.
- 어려운 문법 - JSON 스타일의 도메인 전용 언어를 사용하는데 처음 접한 사람들은 수정에 어려움을 겪었습니다. (간단한 SQL도 되기는 합니다)
- 인프라 운영 - EC2에 직접 설치 및 설정. 부하가 큰 중첩 집계 연산을 실행했을 경우 서버가 다운되는 경우가 있었으며 이 때마다 직접 재기동.
- 비용 - EC2 여러 대 (마스터 노드 한 대, 데이터 노드 여러 대)를 고정적으로 사용했기에 상당한 과금
- 속도 - 길게는 요청당 수십초씩 걸리는 처리 속도.
등의 이유 때문에 빅쿼리 도입을 결정했습니다. 무엇보다 인프라 운영을 직접하지 않아도 된다는 것이 가장 결정적이었습니다. 허나 그럼에도 불구하고 빅쿼리에도 고려해야할 이슈가 있었습니다.
이슈
수정, 삭제 불가
만약 insert 후 30분 안에 데이터를 수정, 삭제하려고 하면 다음과 같은 에러를 보게 됩니다. (링크)
Error: UPDATE or DELETE statement over table dataset.events1 would affect rows in the streaming buffer, which is not supported.
스트리밍 중인 데이터는 수정, 삭제가 불가능 한데 애초에 데이터 베이스가 아니라는 걸 감안하면 이해가 갑니다. 실시간 수정, 삭제 기능이 필수적으로 필요했기에 해당 기능은 다른 DB를 사용해서 해결했습니다.

위 이미지의 스트리밍 버퍼 통계 영역의 예상 행 수는 DML 이 불가능한 행입니다.
과금
과금 정책을 보면 트랜잭션 비용에 과금이 있는데 이는 select 시 스캔 되는 데이터양 만큼 과금이 발생을 뜻합니다. 테스트 해본 결과 대량데이터 조회로 과금이 발생되는 것을 보고 비용을 줄이는 방안을 찾아보았습니다.
성능 및 비용 최적화 과정
성능 최적화는 쿼리의 실행 시간이나 비용 또는 이 둘 모두를 줄이기 위해 진행했습니다.
비용측정기 활용
 콘솔창에서 쿼리를 입력하면 우측 상단에서 예상 비용을 대략적으로 확인이 가능합니다. 쿼리를 수정해가며 비용을 줄이는 방법을 찾아봅시다.
콘솔창에서 쿼리를 입력하면 우측 상단에서 예상 비용을 대략적으로 확인이 가능합니다. 쿼리를 수정해가며 비용을 줄이는 방법을 찾아봅시다.
필요 field만 select
SELECT 절로 읽는 필드가 적을수록 읽어야 할 데이터의 양이 줄어듭니다.


같은 쿼리에서 필드만 지정했는데 비용이 수십배가 감소한 것을 볼 수 있습니다. 이유는 빅쿼리가 컬럼 기반 파일 형식을 사용하기 때문입니다.
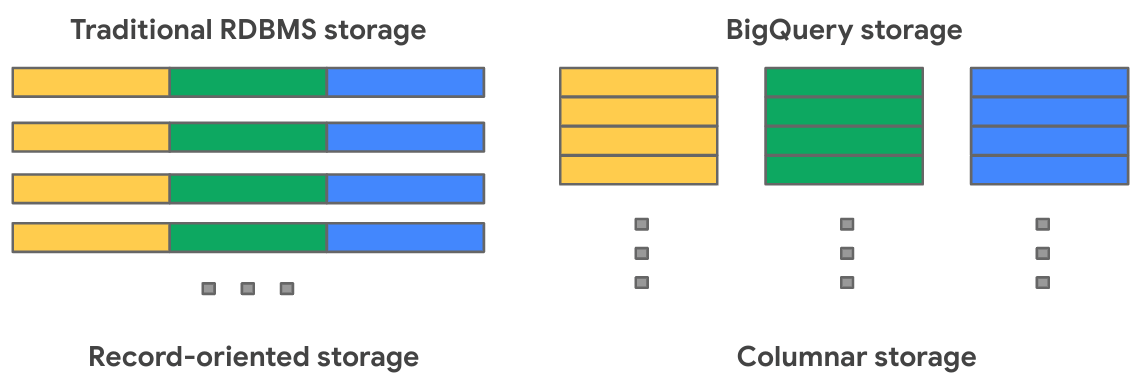 BigQuery가 데이터를 행 단위가 아닌 열 단위로 저장하기에 개별 열을 스캔하는데 효율적입니다. 같은 이유로 LIMIT 를 사용한다고 해서 데이터 양이 줄어들지 않습니다. LIMIT 가 있건 없건 해당 Column 전체를 조회해야 하는건 변하지 않기 때문입니다.
BigQuery가 데이터를 행 단위가 아닌 열 단위로 저장하기에 개별 열을 스캔하는데 효율적입니다. 같은 이유로 LIMIT 를 사용한다고 해서 데이터 양이 줄어들지 않습니다. LIMIT 가 있건 없건 해당 Column 전체를 조회해야 하는건 변하지 않기 때문입니다.
- SELECT * 는 모든 컬럼을 읽으므로 느리고 요금이 많이 나가므로 지양해야 합니다.
- 거의 모든 컬럼이 필요하다면 SELECT * EXCEPT를 사용해서 필요하지 않는 칼럼이라도 빼도록 합시다.
파티셔닝
파티션을 나눈 테이블을 사용하면 데이터를 단일 테이블에 저장하면서도 쿼리 성능을 높일 수 있으며 쿼리에서 읽는 바이트 수를 줄여 비용을 줄일 수 있습니다.
파티셔닝에 기준이 되는 필드는 DATE나 DATETIME 같은 시간 단위 열, 수집 시간, 정수 필드가 가능하며 2개 이상의 파티셔닝은 불가능합니다.
상단의 테이블 정보 이미지를 보면 파티션 기준을 TIMESTAMP, 만료시간을 90일로 설정했기에 90일이 지난 데이터는 삭제됩니다.


where절에 파티션 조건을 사용하니 비용이 수십배가 감소한 것을 볼 수 있습니다.
마치며
소프트웨어 개발에 있어서 Silver Bullet은 없다는 명제를 다시 한번 확인했습니다. 그래도 은탄환은 아니더라도 더 두꺼운 탄환 정도는 됬다고 생각하네요.
참고
https://bcho.tistory.com/1116
https://burning-dba.tistory.com/137?category=1027244

기대 되는 글이네요 빠른 작성 부탁드립니다^^!