Introduction
CNN
- 인접한 픽셀간의 correlation 관계를 학습 => 'locality' 성질
- 거리가 먼 픽셀들 간의 연관성 학습이 어려움 (long-range dependency)
Transformer의 self-attention
-
입력값 간의 연관성을 계산
(if. 이미지 : 이미지를 구성하는 patch간의 연관성을 계산)
=> 효과적으로 거리가 먼 정보들간이 연관성 학습 가능 -
self-attetnion 연산은 입력 사이즈에 quadratic한 복잡도를 지님

-
Swin Transformer
- 이미지를 local window로 나눠, local window 내에서만 self-attention 진행
- local window : MxM개의 patch가 들어간 영역 (M은 항상 fixed) - self-attention을 window안에서만 진행 => 연산량은 이미지 크기에 Linear하게 증가
- 이미지를 local window로 나눠, local window 내에서만 self-attention 진행
-
Swin Transformer Block

-
Window based MSA(W-MSA) : local window 내에서 self-attention 수행
- 겹치지 않게 window 단위로 이미지 나누기
- 각 window별 self-attention 수행 => 연산량 감소 => 복잡도 감소
(기존 transformer - 전체 patches에 대해 self-attention 수행)'
- 단점 : 다른 window에 있는 patch간의 연관성을 학습할 수 없음

-
Shifted Window based MSA(SW-MSA) : widow간의 self-attention
- 핵심은 patch를 밀어서, window에 기존과 다른 patch를 넣어주기
=> cyclic shift 적용 - 재배치가 끝난 feature들을 가지고 다시 window별 self-attention 수핼
- 주의할 점 : 원해 서로 인접한 영역이 아닌 부분을 조심
=> mask : 인접하지 않은 영역간의 attention을 구하는 부분에 아주 작은 음수 값 mask 적용
- 주의할 점 : 원해 서로 인접한 영역이 아닌 부분을 조심
- 모든 window에 대해, masked self-attention이 끝나면 reverse cyclic shift 진행 => 이전으로 돌려주기
- 핵심은 patch를 밀어서, window에 기존과 다른 patch를 넣어주기
-
Method
Model Architecture
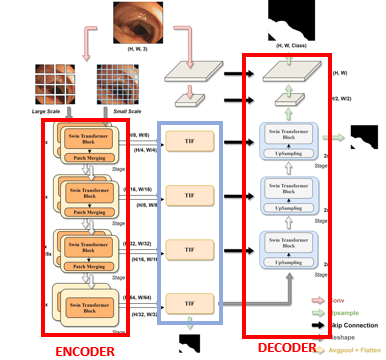
U-Net 구조
-
Encoder
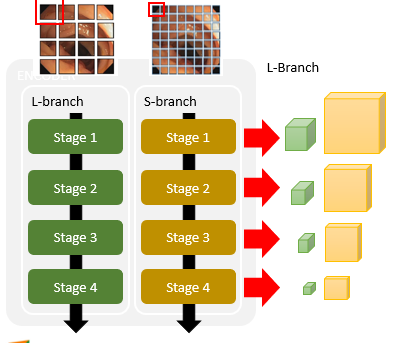
- Dual-Branch Encoder
- Swin Transformer Block 사용
-
Decoder
- Swin Transformer Block 사용
-
TIF(Transformer Interactive Fusion) module
: multi-scale feature ⇒ 하나의 feature
Encoder

- 역활 : 이미지의 특징 추출
Dual-Branch Encoder사용- 사용 이유 : multi-scale feature를 뽑기 위해
patch단위의 self-attention 수행
=> 각 patch. 내부의 pixel 단위의 정보간의 연관성 학습이 불가 => shallow feature을 잃음 L-Branch: 큰 크기의 patch를 다룸 => coarse-grained feature 잘 포착S-Branch: 작은 크기의 patch를 다룸 => fine-grained feature 잘 포착
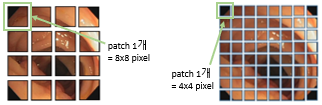
- 사용 이유 : multi-scale feature를 뽑기 위해
- 총 4개의 stage로 구성
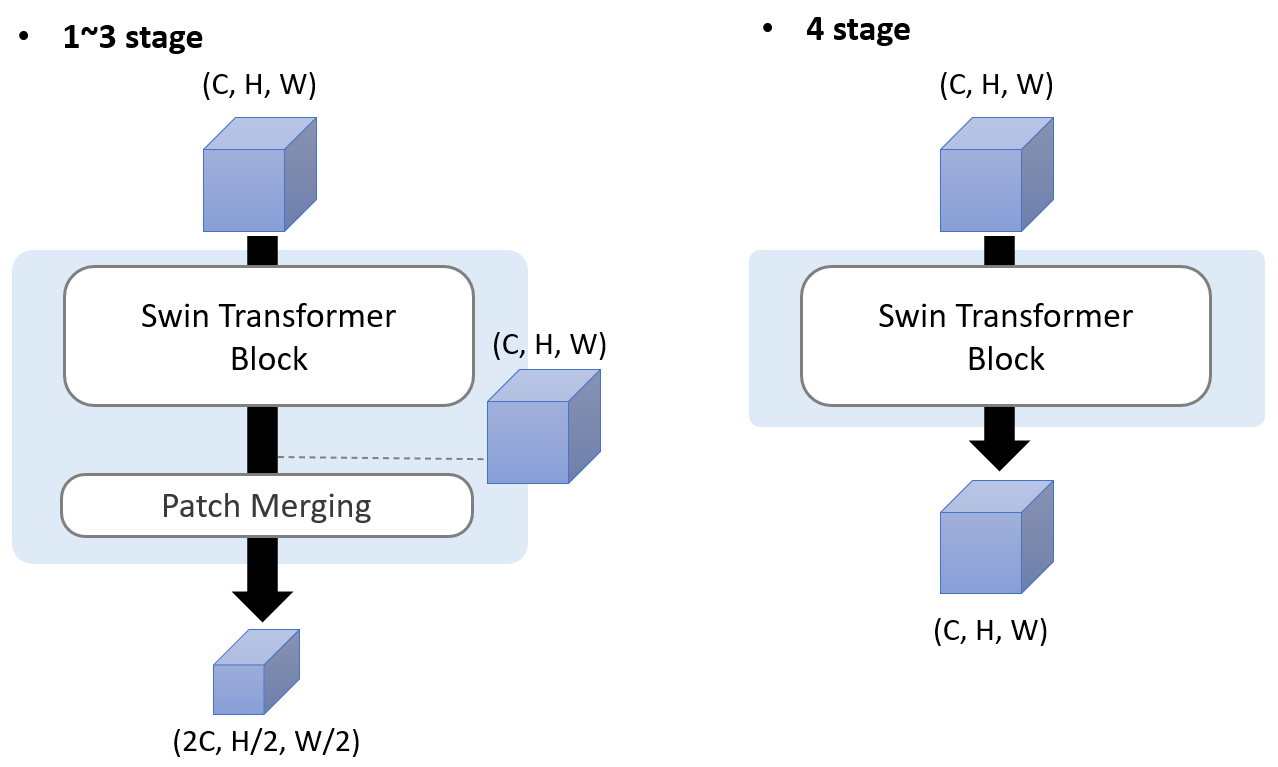
-patch merging: patch 개수 줄이기
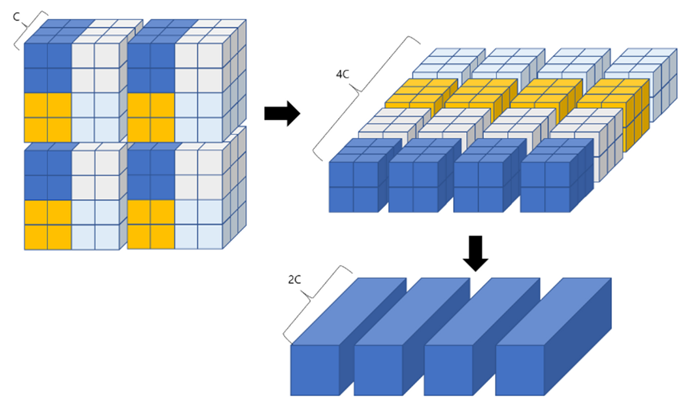
1. 2x2의 이웃하는 patches 끼리 concat(차원 기준)
2. linear layer를 통해 차원 축소 - 최종적으로 Encoder의 각 stage를 거칠 때마다 2개의 feature map를 뽑아냄
Transformer Interactive Fusion(TIF) module
- 역활 : multi-scale features를 효과적으로 합치기
- IF. 간단하게 convolution 연산을 통해 두 feature를 fusion
=> 전체적인 patch간의 연관성 포착에 힘듬 - 두 feature를 가지고, self-attention 연산 수행
=> 다른 크기의 feature간의 연관성 파악 가능 - 구조
2개의 feature => [TIF모듈 - fusion] => 1개의 feature
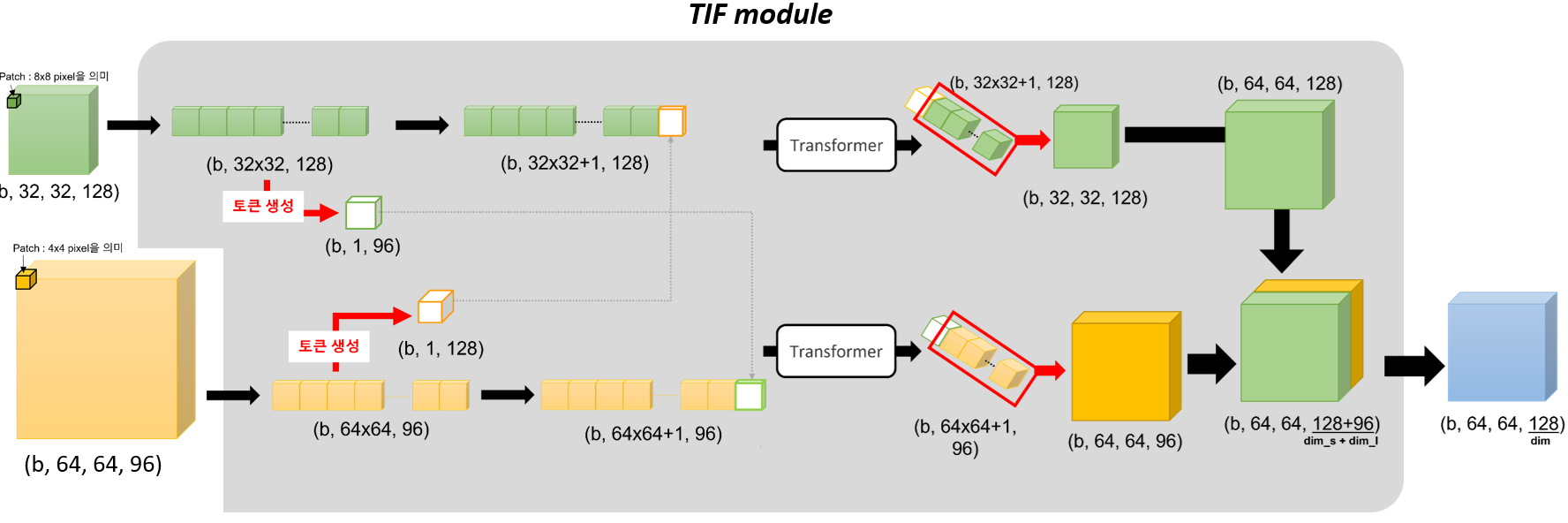
1. 모듈에 들어온 두개의 feature를 flatten
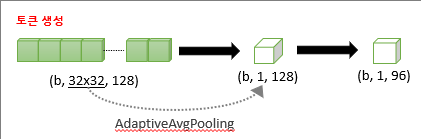
2. 그 다음, 각각 자신을 대표할 token 생성
Token 생성 과정
3. 생성된 token을 상대 feature에 붙이기
- patch 개수는 (원래 patch 개수 + 1)이 된다.
4. feature를 self-attention을 수행
- 붙여진 token과 기존 feature 간의 연관성을 새로 구축
5. 필요 없어진 token은 떼버리고, 차원 기준으로 concat
- 두 feature의 크기가 맞지 않으므로 -> 작은 feature에 2xUpSampling 수행한 뒤 concat
6. feature의 차원을 지정한 차원으로 맞춰주기
Token으로 압축시켜주는 이유
내 생각에는 두 feature를 가지고 self-attention을 적용시키고 싶은데,
두 feature를 그냥 붙여서 transformer에 넣을 시, 연산량이 너무 많아지니까, 각 feature를 대표하는 token으로 압축시켜서, 연산량을 줄이고자 한게 아닐까?????
Decoder
- Up-Sampling 과정을 거쳐, mask를 예측하는 과정
- 총 3개의 stage로 구성
- 각 stage -
Swin Tranformer Block, UpSampling, Skip-connection 수행 - decoder에도 Transformer를 적용 => Up-Sampling과정 중, long-range dependency 구축

- 각 stage -
- 최종 mask 생성
- decoder output : (H/4, W/4) 해상도의 feature
- IF. 단순하게 4x UpSampling => shallow feature 많이 잃음
=> <2x UpSampling & Skip-Connection> 2번 수행

- 비교 실험

Experiments
- Loss function
최종 mask뿐 아니라 중간 과정에서 추가로 뽑아낸 mask들도 같이 loss function에 적용
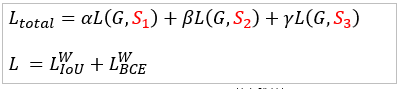
- polyp segmentation task
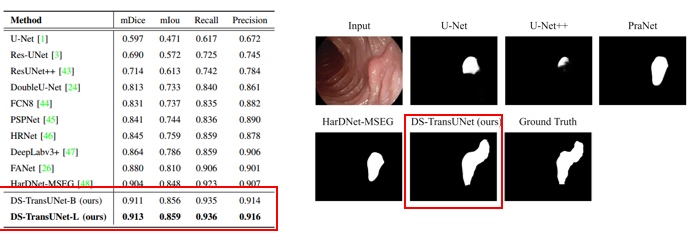
Conclusion
- Dual Swin Transformer U-Net 제안
- Dual-Branch Swin Transformer
- TIF 모듈 설계
- Decoder에 Swin Transformer block 적용
- 개선 방향
- 더 가벼운 transformer 기반의 모델 구축
- pixel 단위의 feature 잘 학습하기

🦴피곤행🦴