
⚡ 빅 데이터 추천 시스템
👉 빅 데이터 도메인 학습을 위한 프로젝트로, 일주일 간 진행 예정
📌 프로젝트 개요
영화 평점 빅 데이터를 이용하여 추천 시스템의 방법 중의 하나인 협업 필터링(Collaborative Filtering) 알고리즘들을 Python 언어를 몇가지 구현하여 실제 회사에 취업 시에 필요한 지식과 코딩 능력을 배양한다.
📌 프로젝트 목표
✅ 영화 추천 시스템에 대한 이해
✅ 추천에 이용되는 Collaborative Filtering 주요 알고리즘 이해
K-nearest neighbor (KNN)알고리즘Matrix factorization알고리즘Matrix factorization+PLSI알고리즘
✅ 빅 데이터마이닝 에서 많이 쓰이는 기술인 Probabilistic Modeling 기술을 습득
✅ 영화 평점과 영화에 대한 다른 텍스트 정보도 이용하는 알고리즘 구현
✅ 오픈 소스기반의 웹 어플리케이션 프레임워크인 Django를 이용하여 UI를 구현
✅ Python을 사용하여 빅 데이터 처리에 효율적인 코딩 실습
Sparse matrix (희소 행열)형태의 데이터를 array에 zero 값을까지 그대로 저장하면 메모리도 많이 필요하고 수행 시간도 오래 걸림- Python의
numpy라이브러리의 행렬 연산과scipy라이브러리의sparse matrix format을 사용하면서reshape과broadcasting기법을 이용하여 효율적으로 코딩
이 연습 프로젝트에서는 개념 습득을 위해 Tiny data만을 이용한다. 실전 프로젝트로 넘어가면
Sparse matrix형태의 데이터를 본격적으로 다룰 예정.
📌 프로젝트 탬플릿 설치
1. Python 수행을 위한 Anaconda 설치
- 무료 오픈소스로서 좋은 패키지들이 함께 install 되기 때문에 사용
- 다운로드 링크
2. Django 설치
-
Anaconda Prompt실행 -
명령어 수행
pip install Django==3.1.5
3. Python 환경을 위한 virtualenvwrapper 설치
pip install virtualenvwrapper4. 프로젝트 디렉토리에 들어가서 명령어 수행
- migrate
python manage.py migrate - 웹 서버 구동
python manage.py runserver

localhost:8000번 포트로 웹 서버가 구동되었다.
5. 'Train Model' 클릭 시
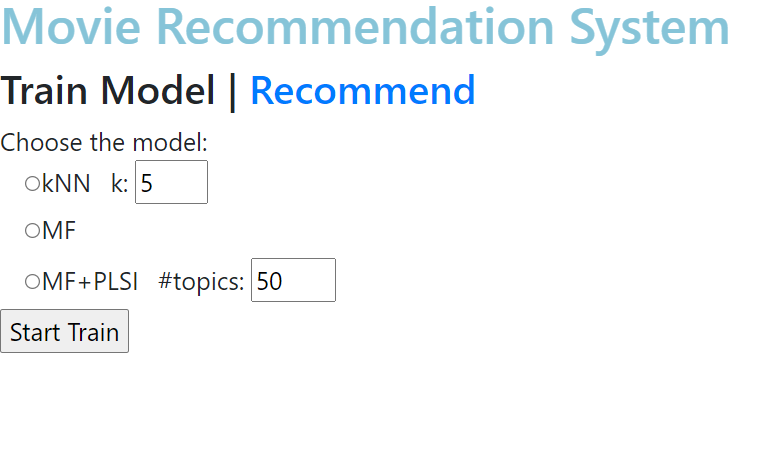
아까 언급한 알고리즘들이 있으며 라디오버튼을 통해 어떤 알고리즘을 사용할지 결정할 수 있다.
👉 kNN의 경우
k: 가장 가까운 이웃을 몇 개까지 볼 것이냐?
👉 MF+PLSI의 경우
topics: PLSI에서 필요로 하는 토픽의 개수
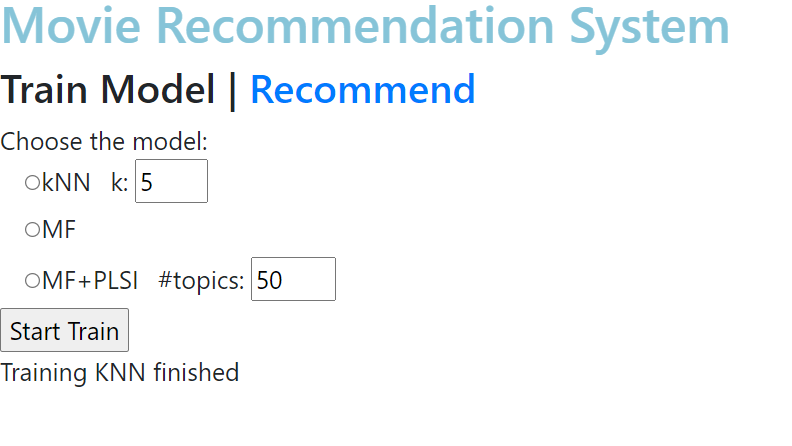
6. kNN 선택 후 Start Train 클릭 시
7. Recommend 클릭 시
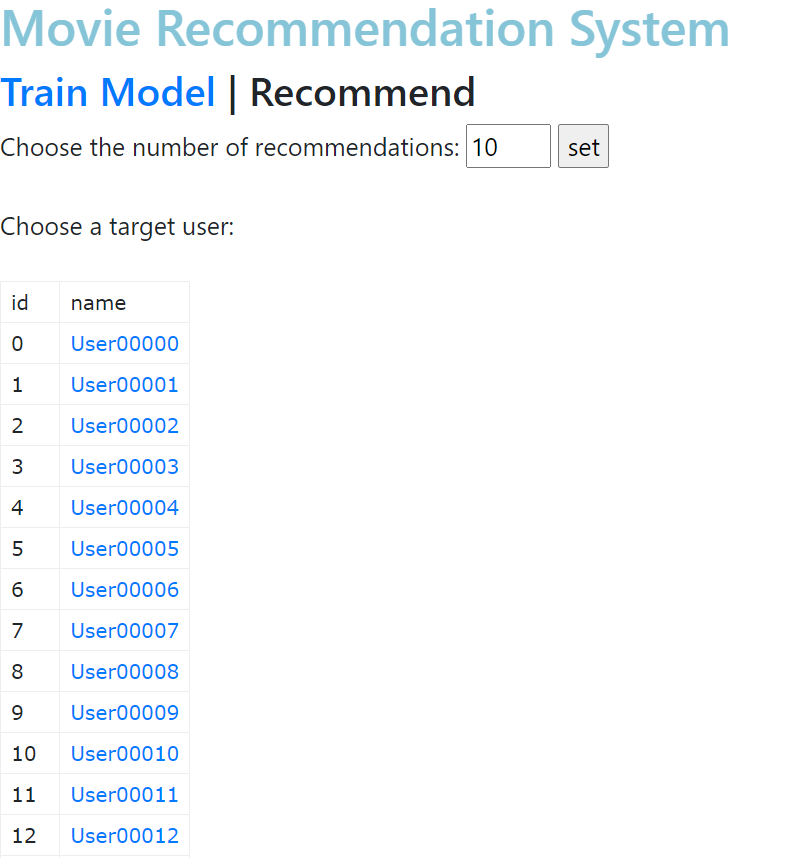
8. User00000 클릭 시(추천 10개 설정)
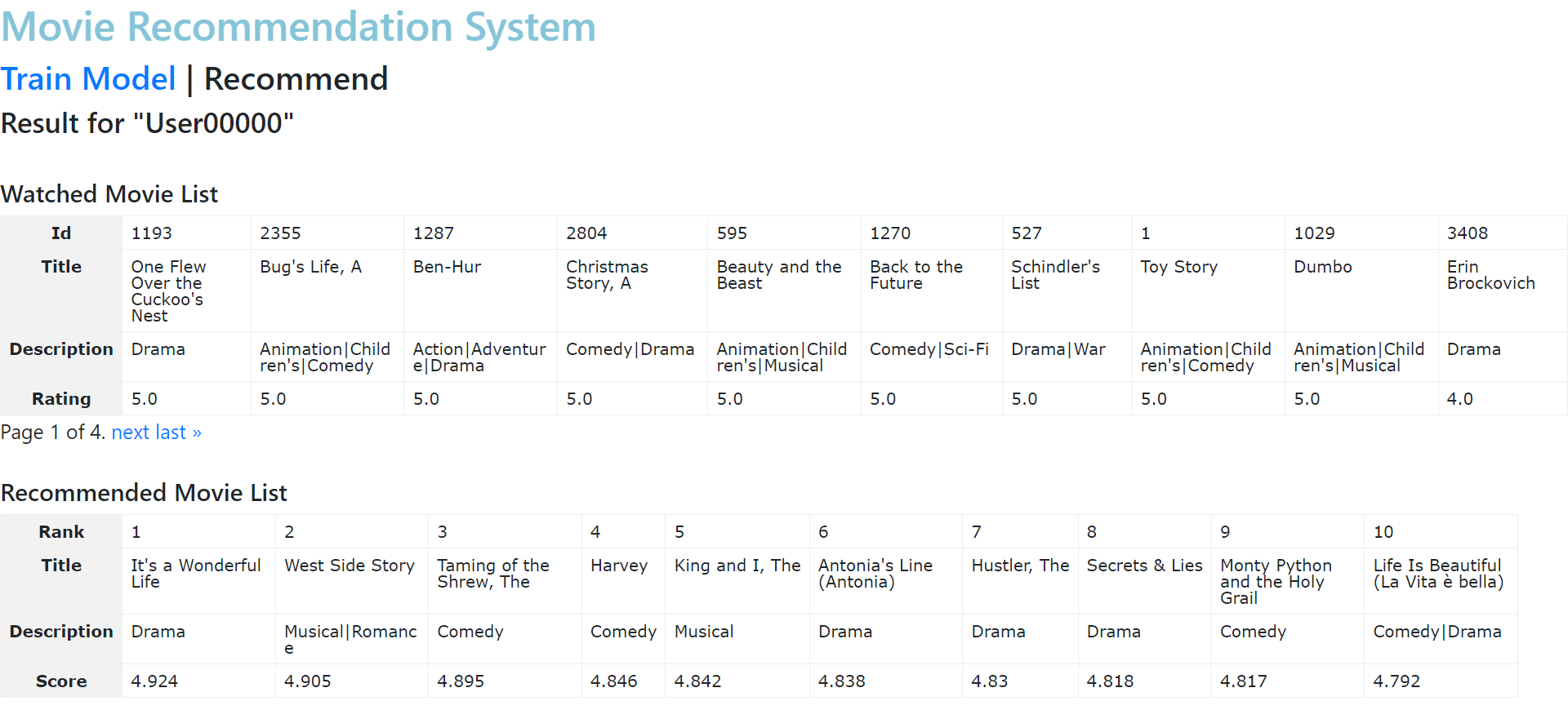
- 위의 테이블은 이미 시청한 영화들의 리스트
- 아래 테이블은 추천하는 10개의 영화 리스트
📌 Django
🔷 2005년부터 시작된 Python의 오픈 소스 웹 프레임워크이자 풀 스택 프레임워크
🔷 프로젝트 내 Django 흐름
- 클라이언트의 요청은 django 프로젝트 디렉토리 안의 urls.py에 전달됨
- urls.py에서 요청을 views.py로 보내고 저장되어 있는 데이터가 필요하면 models.py에서 가져와 templates로 보내면 클라이언트에게 응답
❗ 보안 규정 상 자세한 코드 및 흐름도 노출이 불가하다는 점은 양해바랍니다.
🔷 train_model()
- 선택된 모델을 호출하는 함수
def train_model():
model = request.POST.get('model')
if model == 'KNN': run_kNN(request)
elif model == 'MF': run_MF(request)
elif model == 'MF_PLSI': run_MF_PLSI(request)
request.POST = {}
return render(request, 'movieRec/train.html', {'train finished': True, 'model':model})🔷 run_kNN()
request.POST함수를 이용하여 kNN에서 사용할 이웃 고객 인원수 파라미터 k 값을 가져옴- train.py 이라는 python 코드를 수행
💡 train.py의 입력 파라미터
-i: 데이터 파일 디렉토리-o: 결과 파일 디렉토리-a: 0(kNN 학습 알고리즘)
def run_kNN(request):
k = request.POST.get('param_k')
os.system('cd matrixfactorization& python train.py -i data/tiny -o result/tiny -a 0 -k %s'%k)
load_result('matrixfactorization')🔷 load_result()
- 파일을 읽어 들여
SQLite3데이터베이스에 사용
def load_result(model_home):
conn= sqlite3.connect('./db.sqlite3')
cur = conn.cursor()
print("LOAD MOVIEDATA")
load_movies(cur)
print("LOAD VIEWED DATA")
load_viewed(cur, model_home)
print("LOAD RECOMM DATA")
load_recomm(cur, model_home)
print("load_result IS FINISHED")
conn.commit()
conn.close()