.png)
Stack , Queue
- Stack : 후입선출(Last-In-First-Out, LIFO)
- Queue : 선입선출(First-In-First-Out, FIFO)
Stack (Last-In-First-Out, LIFO)
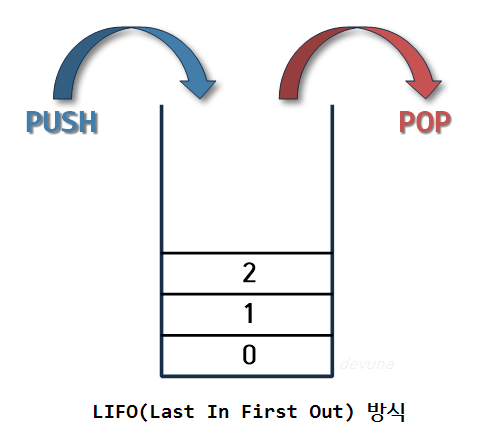
스택은 데이터가 차곡차곡 위로 쌓이고, 가장 최근의 데이터는 top에 위치하게 된다.
새로 push(삽입)되는 데이터는 전에 있던 top위에 쌓이게 된다.
스택에서 pop(삭제)을 할때도 top을 통해서만 가능하다
따라서 스택은 시간 순서에 따라 자료가 쌓여서 가장 마지막에 삽입된 자료가
가장 먼저 삭제된다는 구조적 특징을 가지게 된다.
이러한 스택의 구조를 후입선출(LIFO , Last-In-First-Out)구조라고 부른다.
그리고 비어있는 스택에서 원소를 추출하려고 할 때 stack underflow라고 하며,
스택이 넘치는 경우 stack overflow라고 한다.
Queue (First-In-First-Out, FIFO)
.png)
정해진 한 곳(top)을 통해서 삽입, 삭제가 이루어지는 스택과는 달리
큐는 한쪽 끝에서 삽입 작업이, 다른 쪽 끝에서 삭제 작업이 양쪽으로 이루어진다.
enQueue , deQueue
이때 삭제연산만 수행되는 곳을 프론트(front), 삽입연산만 이루어지는 곳을 리어(rear)로 정하여
각각의 연산작업만 수행된다.
이때, 큐의 리어에서 이루어지는 삽입연산을 인큐(enQueue)
프론트에서 이루어지는 삭제연산을 디큐(dnQueue)라고 부른다.
정리
큐는 들어올 때 rear로 들어오지만 나올때는 front부터 빠지는 특성을 가지고 있다.
가장 먼저 들어온 데이터가 가장 먼저 삭제가 된다.
따라서 Queue의 구조를 선입선출(First-In-First-Out, FIFO)구조 라고 한다.
unshfit , shift 는 push , pop보다 성능이 좋지 않다
shift 와 unshift 이 둘은 앞에서 데이터를 추가하던지, 삭제하는 메서드이다.
이것들을 실행시킨다고, 맨 앞 요소가 그냥 지워지고 , 생기고 하지 않음
어떠한 과정을 거쳐서 실행이 되는데, 이 과정이 push, pop보다 많고, 오래걸린다.
이유는 ?
shift를 예로 들어보자
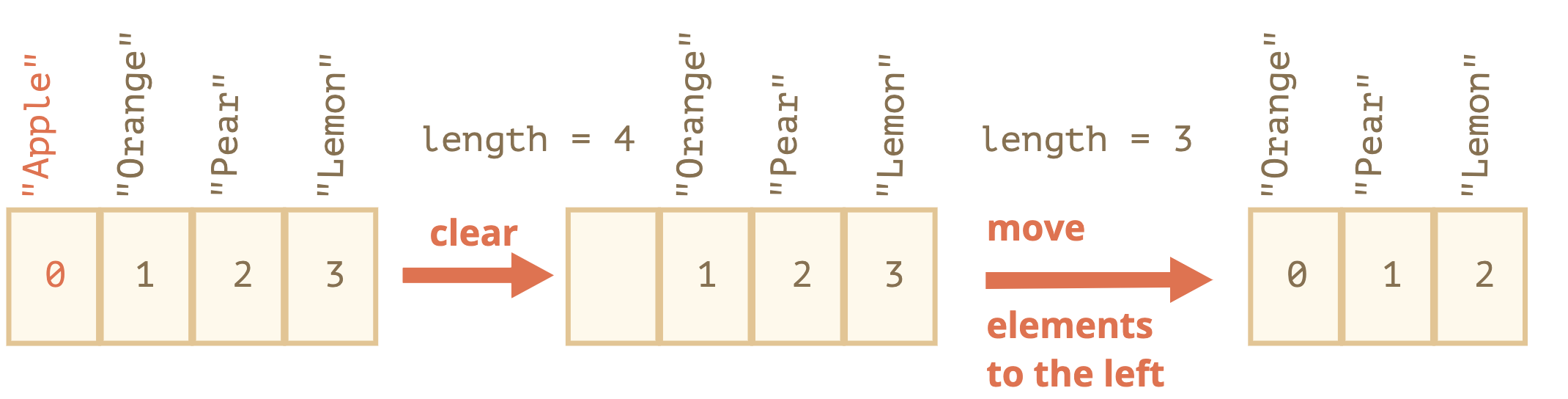
- 인덱스가 0인 요소를 제거한다.
- 모든 요소를 왼쪽으로 이동시킨다. 이때 인덱스 1은 0, 2는 1로 변함.
- length 프로퍼티 값을 갱신한다.
반대로 shift보다 성능이 좋은 pop의 프로세스를 보고 비교해보자
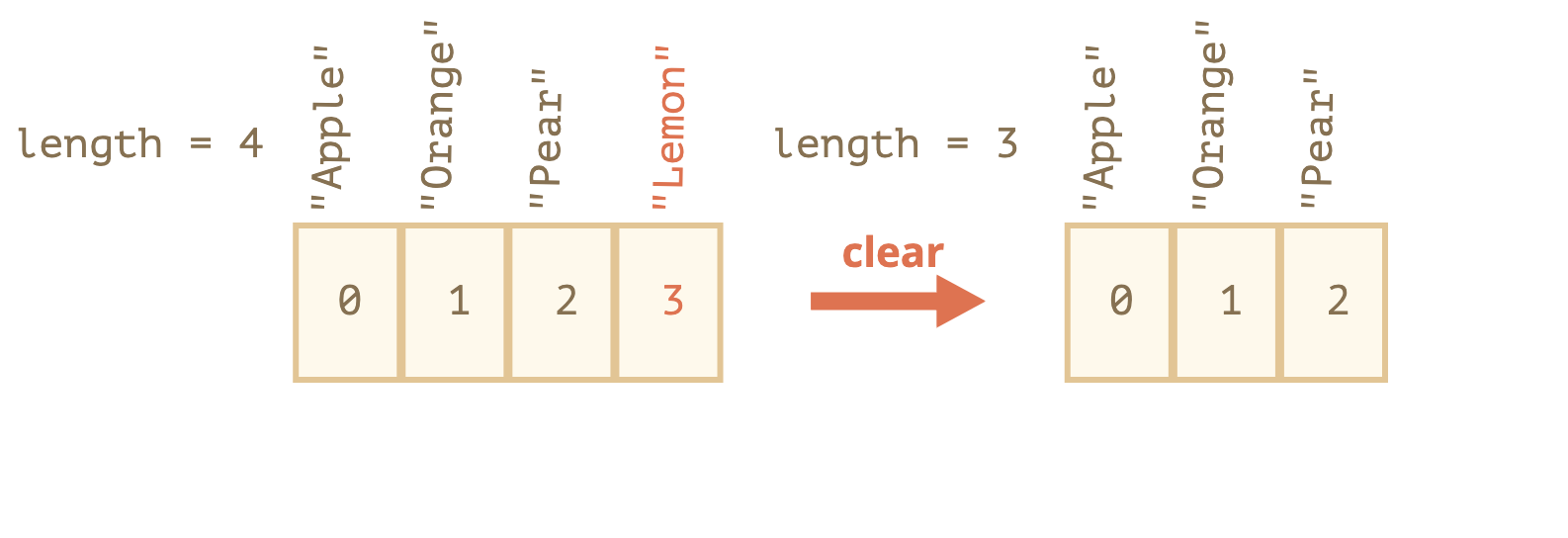
shift보다 과정이 간단한걸 볼 수 있음.
