
실제 데이터를 보고
가설을 세우고
데이터에 기반해서 문제를 해결해 보기
[1]
1) 수강 데이터 불러오기
import pandas as pd
enroll = pd.read_csv('./data/enrolleds_detail.csv')
enroll
enroll_detail = enroll.groupby('lecture_id')['user_id'].count()
enroll_detail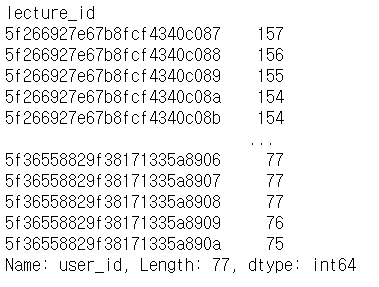
2) 어려운 지점 파악하기
그래프 그리기
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'malgun gothic'
plt.figure(figsize=(22,5))
plt.bar(enroll_detail.index, enroll_detail)
plt.title('강의에 따른 수강완료 수의 합계')
plt.xticks(rotation=90)
plt.show()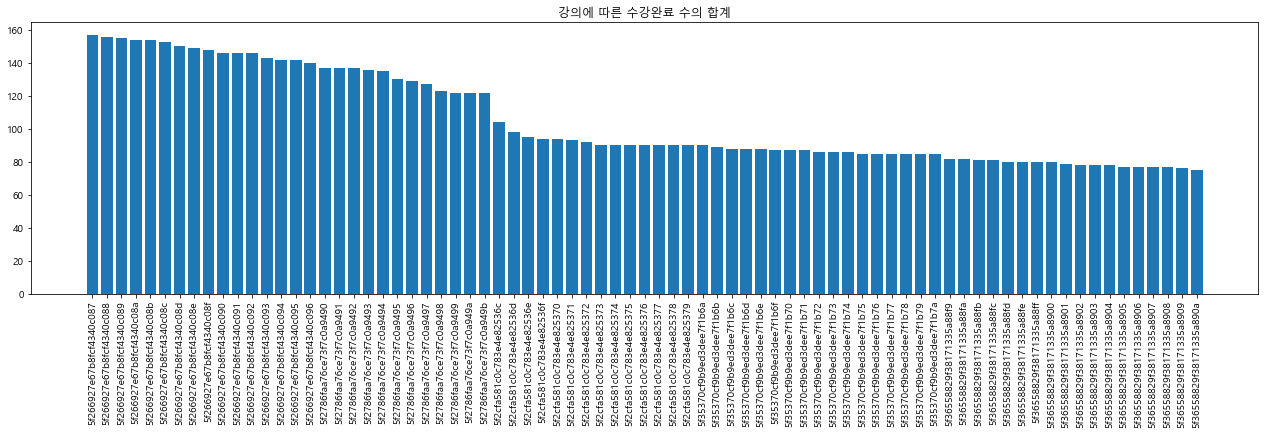
바 그래프에서 수강 완료 수가 급격히 떨어지는 지점이 보임.
해당 강의 아이디가 어떤 강의 명인지 파악할 필요가 있음.
강의 제목 불러오기
lectures=pd.read_csv('./data/lectures.csv')
lectures
위에서 데이터를 추출한 enroll_detail(강의 아이디에 따른 수강 완료 인원)과 lectures를 매치시켜 하나로 만들면 한눈에 비교할 수 있다.
join 시키기 위해 enroll_detail를 데이터 프레임 형식으로 만들면
lecture_count = pd.DataFrame(enroll_detail)
lecture_count
우선 enroll_detail에 있는 index 값을 다시 지정해줄 필요가 있음.
lecture_count = lecture_count.reset_index()
lecture_count
하지만 user_id칼럼에 있는 값이 유저 id가 아니라 유저 수 이기 때문에 user_id라고 되어있는 칼럼 명을 바꿔줘야함.
lecture_count = lecture_count.rename(columns={'user_id':'count'})
lecture_count
lectures과 lecture_count에서 lecture_id가 공통되기에 이걸로 합칠거여서 lectures에서 lecture_id를 index로 설정
lectures = lectures.set_index('lecture_id')
lectures
join을 사용해서 두 데이터를 합쳐줌
full_lecture = lecture_count.join(lectures, on='lecture_id')
full_lecture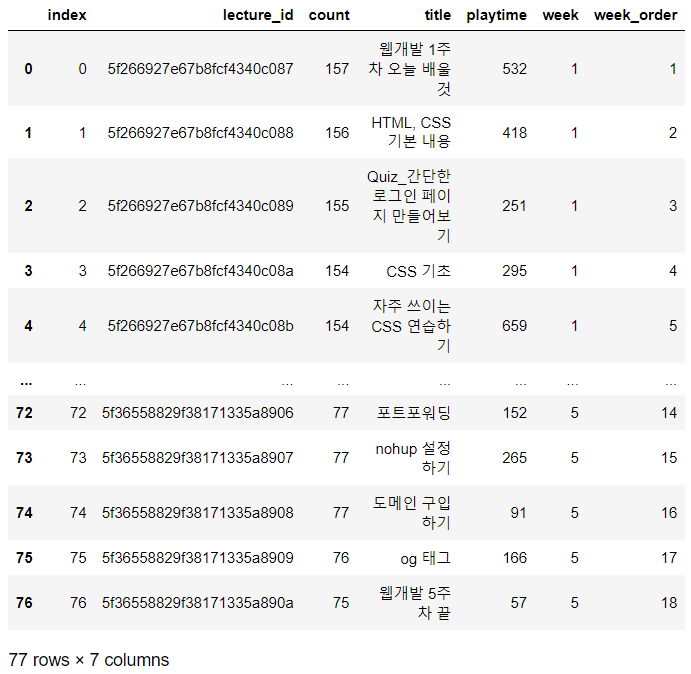
합친 데이터로 그래프 다시 그리기
plt.figure(figsize=(22,5))
plt.bar(full_lecture['title'], full_lecture['count'])
plt.title('강의에 따른 수강완료 수의 합계')
plt.xlabel('강의명')
plt.xticks(rotation=90)
plt.show()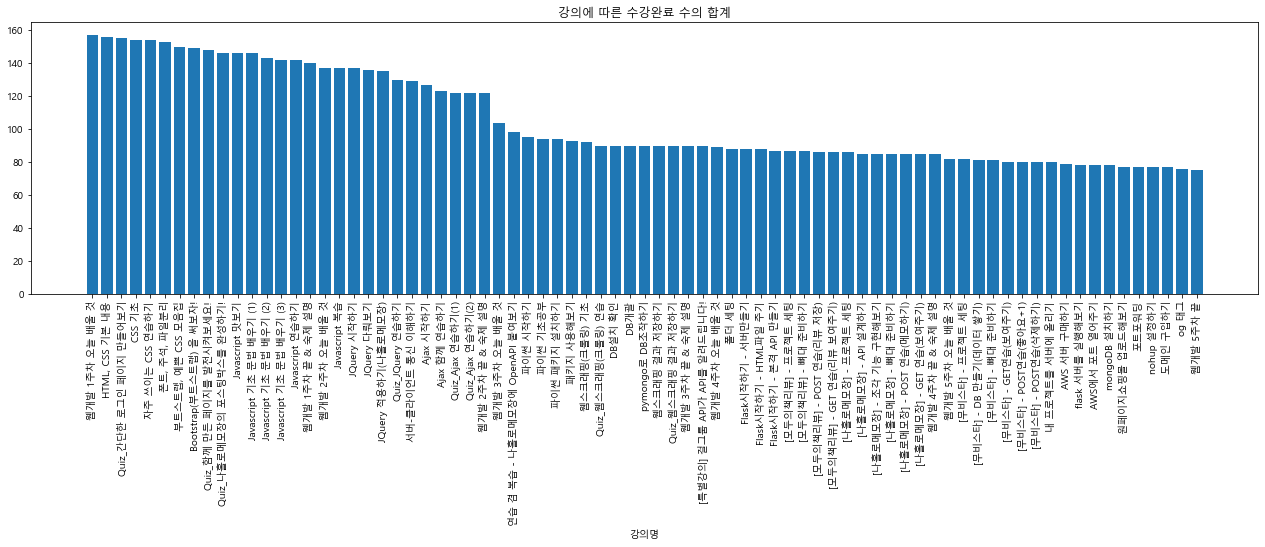
[2] 워드 클라우드 만들기
1) 강의 자막으로 워드 클라우드 만들기
워드클라우드 설치
conda install -c conda-forge wordcloud
라이브러리 불러오기
import numpy as np from PIL import Image from wordcloud import WordCloud import matplotlib.pyplot as plt→ 외울필요 없이 자신들의 라이브러리를 불러오는 방식을 공식문서에서 보고 복사 붙여넣기 하면 됨.
워드 클라우드에 그려볼 txt 파일을 불러와서 읽기
text = open('./data/Sequence_01.txt', 'r', encoding='utf-8') # 파일 인코딩 형식이 달라 이 파일에 맞는 인코딩 방식을 알려주는 옵션을 추가, 'r'은 읽는다는 의미
text = text.read() # text 형식의 파일을 불러와서 읽는법
text = text.replace('\n', " ") # 이 줄 없애고 출력해서 보면 각 문자들 사이를 구분하기 위해 \n이 있음. 이걸 없애주는 것.
text
text2 = open('./data/Sequence_02.txt', 'r', encoding='utf-8')
text2 = text2.read()
text2 = text2.replace('\n', " ")
text2참고)
파일의 인코딩 방식을 확인해보고 싶다면 chardet 라이브러리를 아래와 같이 이용
conda install -c anaconda chardetimport chardet
with open('./data/Sequence_01.txt', 'rb') as f:
print(chardet.detect(f.read()))결과 : {'encoding': 'UTF-8-SIG', 'confidence': 1.0, 'language': ''}하지만 하나씩 이렇게 다 불러오기 힘들기에 for문 사용
result = ""
# 아래 for 문을 돌리다 보면 Sequence_01, 02, 03 ~~ 전부 text라는 변수명에 들어감. 이렇게 되면 for문이 돌아갈 때 마다 새로운 값들로 덮어져서 이전 값들이 없어짐.
# 그래서 result라는 빈 변수를 만들어주고 생성될 때 마다 여기에 하나씩 넣어주는 거임.
for number in range(1,15): #1부터 15미만 즉 1부터 14까지 진행됨
index = '{:02}'.format(number)
# 외우지 말고 이렇게 쓰는구나 이해하고 쓰기만 하면됨. 검색해서 찾아서 쓰는것. {:0N} → N은 원하는 자릿수
# 파일 이름이 Sequence01 02 03 ~~~ 이런식으로 2자리 수로 되어있으므로 '숫자 두자리로 만드는법 파이썬' 이런식으로 검색해서 찾아보면 됨.
filename = "Sequence_" + index + ".txt"
text = open('./data/'+filename, 'r', encoding='utf-8-sig') #utf-8-sig 방법으로 읽어줘(r). txt 문서 맨 앞에ufeff 이런게 인코딩 방식인데 이런게 있으면 인코딩이 되어있다고 생각하고 이런 방식으로 쓰면 됨.
result += text.read().replace("\n", " ") #자기 자신을 더해줄 땐 이렇게 줄여 쓸 수 있음. 정석은 → result = result + text.read().replace("\n", " ")
result 깨끗한 워드 클라우드를 위해 특수문자 제거
#워드클라우드 안에는 특수기호가 들어가면 안됨. 그래서 특수기호를 빼야함
# 꼭 안해도 되지만 깨끗한 워드클라우드를 만들기 위해 하는거임.
import re #정규식을 사용하기 위한 re라는 라이브러리를 가져옴
pattern = '[^\w\s]' #특수기호 제거 패턴
text = re.sub(pattern=pattern, repl='', string=result) #특수 기호는 지워줌, 위에서 불러왔던 re(result)를 넣어서 특수기호가 보이면 지워줌
text2) 나만의 워드 클라우드 만들기
한글설정
→ 여기에서 나오는 결과 값 중 하나를 한글 폰트 설정 경로로 해주면 됨.
import matplotlib.font_manager as fm
# 고딕을 가지고 있는 폰트들의 리스트. fontmanager의 문서를 보면 알 수 있기에 외울필요 없음.
for f in fm.fontManager.ttflist:
if 'Gothic' in f.name:
print(f.fname)워드클라우드 생성
font_path = 'C:\WINDOWS\Fonts\malgunbd.ttf'
wc = WordCloud(font_path=font_path, background_color="white") #폰트 뭐쓸래? : font_path
wc.generate(text) #우리가 만들었던 텍스트를 워드클라우드에 넣어줌
plt.figure(figsize=(50,50))
plt.axis("off") #축은 없음
plt.imshow(wc)
plt.show()
- 참고링크 : https://amueller.github.io/word_cloud/generated/wordcloud.WordCloud.html
font_path: 한글 폰트 설정 경로background_color: 배경색상
워드 클라우드 모양내서 그리기
# Generate a word cloud image
mask = np.array(Image.open('./data/sparta.png')) #np.array : 행렬을 하나 만들어서 있으면 있다, 없으면 없다고 마스킹 하는 것. 어떤 모양이던지 간에 흑백으로 본이 떠짐. './data/sparta.png' 이미지를 본 떠서 마스킹 한거임.
wc = WordCloud(font_path=font_path, background_color="white", mask=mask)
wc.generate(text)
f = plt.figure(figsize=(50,50))
f.add_subplot(1,2, 1) #그래프1, 그래프를 2개 그릴때 하는 방법
plt.imshow(mask, cmap=plt.cm.gray) #이미지show에 마스크를 넣어줌.
plt.title('Original Stencil', size=40)
plt.axis("off")
f.add_subplot(1,2, 2) #그래프2
plt.imshow(wc, interpolation='bilinear') #bilinear라는 색
plt.title('Sparta Cloud', size=40)
plt.axis("off")
plt.show()왼쪽이 마스킹 하는 원래 이미지

워드 클라우드 이미지로 저장하기
mask = np.array(Image.open('./data/sparta.png'))
wc = WordCloud(font_path=font_path, background_color='white', mask=mask)
wc.generate(text)
f = plt.figure(figsize=(50,50))
plt.imshow(wc, interpolation='bilinear')
plt.title('나만의 워드 클라우드', size = 40)
plt.axis('off')
plt.show()
f.savefig('./data/myWordCloud.png') #내가 원하는 곳에 저장함.3) Q.적절한 즉문즉답 시간은 언제일까?
라이브러리 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = "Malgun Gothic"분석할 데이터 불러오고 살피기
sparta_data = pd.read_csv('./data/enrolleds_detail.csv')
sparta_data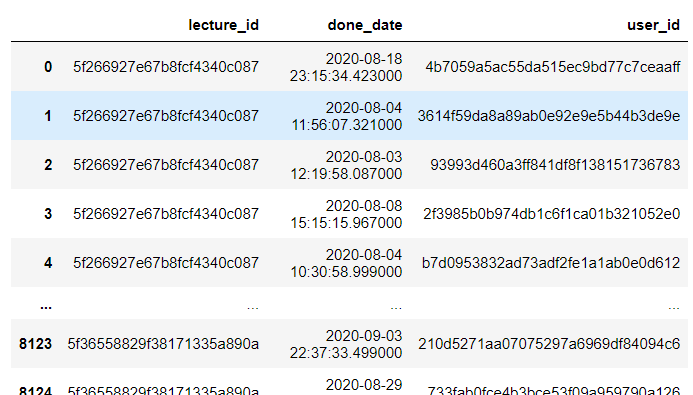
무슨 요일 몇시에 수강생들이 강의를 듣는지를 알아야 문제를 해결할 수 있으므로 요일별, 시간 데이터가 필요함.
날짜 데이터 전처리하기
시간 데이터 전처리
format = '%Y-%m-%dT%H:%M:%S.%f' #d(일) 다음에 띄어쓰기가 아니라 T(탭)이다. %f는 소수점
sparta_data['done_date_time'] = pd.to_datetime(sparta_data['done_date'], format=format)
sparta_data- %Y는 년도
- %m은 월
- %d는 일
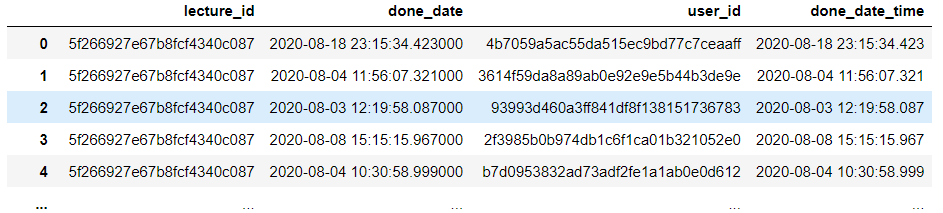
요일 추가하기
sparta_data['done_date_time_weekday'] = sparta_data['done_date_time'].dt.day_name()
#dt.day_name은 데이트 타임(날짜)(dt)의 요일을 나타냄. 8월 18일 같은 날이 몇요일인지 바꿔주는거
sparta_data
제 2의 즉문즉답 시간 알아내기(1)
요일별 수강생 수 전처리
weekdata = sparta_data.groupby('done_date_time_weekday')['user_id'].count()
weekdata
weeks = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekdata = weekdata.agg(weeks) #agg : aggregation 요일별로 데이터를 모아줌
weekdata
바 그래프 그리기
plt.figure(figsize=(8,5))
plt.bar(weekdata.index, weekdata)
plt.title('요일별 수강 완료 수강생 수')
plt.xlabel('요일')
plt.ylabel('수강생(명)')
plt.xticks(rotation=90)
plt.show()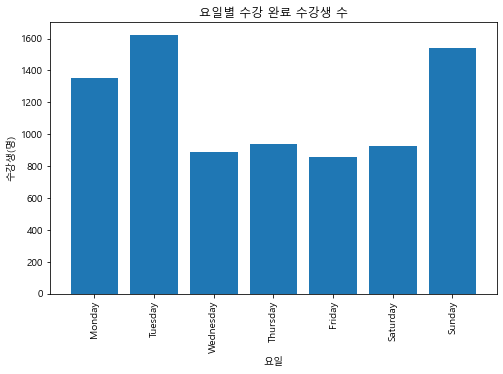
시간 데이터 추출하기
sparta_data['done_date_time_hour'] = sparta_data['done_date_time'].dt.hour
sparta_data
시간별 수강완료 수강생 수 전처리 하기
hourdata = sparta_data.groupby('done_date_time_hour')['user_id'].count()
hourdata = hourdata.sort_index() #시간(숫자)으로 되어있기 때문에 그냥 index로 정렬해도 된다. sort_values()는 값을 기준으로 정렬해주는거.
hourdata시간별 수강완료 수강생 수 라인 그래프 그리기
plt.figure(figsize=(10,5))
plt.plot(hourdata.index, hourdata)
plt.title('시간별 수강 완료 수강생 수')
plt.xlabel('시간')
plt.ylabel('사용자(명)')
plt.xticks(np.arange(24)) #np.arrange 가 없으면 x 축의 시간이 0, 5, 10 이런식으로 전부 안나옴.
#Numpy(넘파이) : 행렬이나 대규모 다차원 배열을 쉽게 처리 할 수 있도록 하는 파이썬의 라이브러리
#plt.xticks(np.arange(24))랑 plt.xticks([0, 1, 2, 3, 4, 5, ~~~, 22, 23])랑 똑같음
plt.show()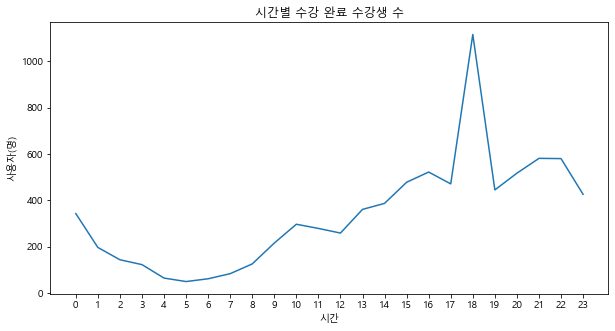
제 2의 즉문즉답 시간 알아내기(2)
요일별 종료시간 살펴보기
피봇 테이블 만드는 법
pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, margins_name='All') data: 분석할 데이터 values: 분석할 수 index: 행 인덱스 columns: 열 인덱스 aggfunc: 분석 방법
sparta_data_pivot_table = pd.pivot_table(sparta_data, values='user_id', aggfunc='count', #aggfunc : 분석 방법
index=['done_date_time_weekday'], #y축
columns=['done_date_time_hour']).agg(weeks) #x축
sparta_data_pivot_table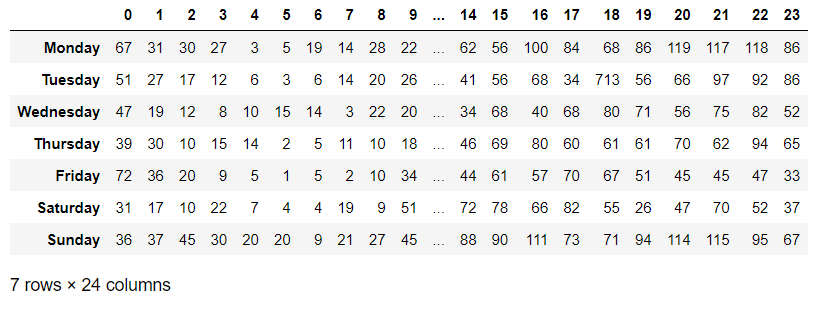
히트맵 그리기
plt.figure(figsize=(14,5))
plt.pcolor(sparta_data_pivot_table) #히트맵 그리기
plt.xticks(np.arange(0.5,len(sparta_data_pivot_table.columns),1), sparta_data_pivot_table.columns)
plt.yticks(np.arange(0.5,len(sparta_data_pivot_table.index),1), sparta_data_pivot_table.index)
# len()의 개수만큼 숫자를 만든 다음에 sparta_data_pivot_table.columns에 대입해줄거다.
# len()의 개수만큼 숫자를 만든 다음에 sparta_data_pivot_table.index에 대입해줄거다.
# 0.5가 아니라 0부터 시작하면 처음 시작점에 xticks와 yticks 값이 붙어서 표현됨.
plt.title('요일별 종료 시간 히트맵')
plt.xlabel('시간')
plt.ylabel('요일')
plt.colorbar()
plt.show()
Numpy arange
np.arange(배열의 첫 번째 값, 배열의 끝을 정의하는 값(배열에 포함되지 않음), 배열 사이의 간격 ) ex) np.arange(1, 10, 3) → array([1, 4, 7]) 7+3은 10 이지만 10은 배열의 끝을 정의하는 값이므로 배열에 포함되지 않음.위의 식에서는
len(sparta_data_pivot_table.columns)이 배열이 끝나는 값 이므로 24가 끝나는 값임.np.arange(0.5,len(sparta_data_pivot_table.columns),1) array([ 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5, 10.5, 11.5, 12.5, 13.5, 14.5, 15.5, 16.5, 17.5, 18.5, 19.5, 20.5, 21.5, 22.5, 23.5])
연습하기
노래 가사로 워드 클라우드 만들기
import numpy as np
from PIL import Image
from wordcloud import WordCloud
import matplotlib.pyplot as plt
text = open('./data/song1.txt', 'r', encoding='utf-8').read().replace('\n', ' ')
result = " "
for number in range(1,6):
filename = 'song' + str(number) + ".txt"
# 그냥 number 쓰면 문자, 숫자 혼용할 수 없다고 써서 str을 사용해서 문자로 바꿔줌.
# 또 다른 방법 filename = 'song{}.txt'.format(number)
text = open('./data/'+filename, 'r', encoding='utf-8')
result = result + text.read().replace('\n', ' ')
result # 잘 나오는지 한번 확인(확인 안하려면 필요 없음)
font_path = 'C:\WINDOWS\Fonts\malgun.ttf'
mask = np.array(Image.open('./data/mucic note.jpg'))
wc = WordCloud(font_path=font_path, background_color='white', mask=mask )
wc.generate(result)
f = plt.figure(figsize=(50,50))
plt.imshow(wc)
plt.axis('off')
f.savefig('./data/mysongwordcloud.png')
plt.show()
참고) format()함수
#named indexes:
txt1 = "My name is {fname}, I'm {age}".format(fname = "John", age = 36)
#결과 : My name is John, I'm 36
#numbered indexes:
txt2 = "My name is {0}, I'm {1}".format("John",36)
#결과 : My name is John, I'm 36
txt2 = "My name is {1}, I'm {2}".format("John",36,77)
#결과 : My name is 36, I'm 77
#empty placeholders:
txt3 = "My name is {}, I'm {}".format("John",36)
#결과 : My name is John, I'm 36