사용할 프로그램
Anaconda3
분석을 도와줄 패키지 매니징 플랫폼. 개발에 필요한 기본적인 도구들을 모아 놓은 곳으로 수많은 라이브러리가 미리 설치되어 있음.(파이썬도 기본으로 설치되어 있어 파이썬을 사용할 것임)
jupyter notebook
command console이 아닌 웹 상에서 코딩 결과를 바로 볼 수 있는 프로그램
파이썬 기초 문법(1)
1) 변수 & 기본연산
a = 3 # 3을 a에 넣는다
print(a)b = a # a를 b에 넣는다
print(b)a = a + 1 # a+1을 다시 a에 넣는다
print(a)num1 = a * b # a*b의 값을 num1이라는 변수에 넣는다
print(num1)2) 자료형
- 숫자, 문자열, 참거짓
num = 12 # 숫자가 들어갈 수도 있고,
print(num)name = 'Harry' # 변수에는 문자열이 들어갈 수도 있고,
print(name)number_status = True # True 또는 False -> "Boole" 형이 들어갈 수도 있습니다.
print(number_status)- 리스트형
waiting_list = [] # 비어있는 리스트 만들기
waiting_list.append('땡땡땡') # 리스트에 문자열 데이터를 넣는다
print(waiting_list)waiting_list.append('김마미') # 리스트에 '김마미'라는 문자열을 하나 더 넣는다
print(waiting_list)waiting_list.append(['고영희','황철수']) # 리스트에는 또 다른 리스트가 추가될 수 있다# waiting_list의 값은? ['땡땡땡', '김마미', ['고영희', '황철수']]
# waiting_list[0]의 값은? '땡땡땡'
# waiting_list[2]의 값은? ['고영희', '황철수']
# waiting_list[2][0]의 값은? '고영희'- Dictionary 형
eng_kor_dict = {} # 비어있는 딕셔너리 만들기
eng_kor_dict = {'apple': '사과', 'pear': '배'}
eng_kor_dict['apple'] #출력값 : '사과'# 딕셔너리에 추가하고 싶을 때
eng_kor_dict['banana'] = '바나나'
eng_kor_dict
print(eng_kor_dict['banana']) #출력값 : 바나나# print 로 값 확인해보기
# eng_kor_dic의 값은? {'apple': '사과', 'pear': '배', 'banana': '바나나'}
# eng_kor_dic['apple']의 값은? '사과'
# eng_kor_dic['pear']의 값은? '배'
# eng_kor_dict['banana']의 값은? '바나나'- Set 형
group1 = set([1, 2, 3, 4, 2, 1])
group2 = set([1, 2, 3, 1, 6])
print(group1) # {1, 2, 3, 4} -> 중복된 수는 안나옴
print(group2) # {1, 2, 3, 6} -> 중복된 수는 안나옴# 교집합
print(group1 & group2) # {1, 2, 3}
# 합집합
print(group1 | group2) # {1, 2, 3, 4, 6}
- 리스트에 있는 데이터에 접근할 때 list_name[0] 와 같은 방법으로 접근함.
- 딕셔너레이 있는 데이터에 접근할 때는 dictionary_name["키값"] 의 방법을 이용함.
- 셋은 리스트를 ()로 감싸주어 사용함.
파이썬 기초 문법(2)
1) 조건문
# 조건을 여러 개 사용하고 싶을 때
age = 65
if age > 80:
print('아직 정정하시군요')
elif age > 60:
print('인생은 60부터!')
else:
print('아직어려요!')
# 결과: 인생은 60부터!
# age = 20 으로 하면 → 결과 : 아직어려요!파이썬은 들여쓰기(indent)로 코드의 블록(시작과 끝) 단위를 나누기 때문에 들여쓰기를 잘못하면 들여쓰기 에러(indentation error) 가 발생함. 따라서 들여쓰기가 매우 중요함.
2) 반복문
반복문은, 리스트나 문자열의 요소들을 하나씩 꺼내쓰는 형태. 즉, 임의의 열(sequense, 리스트나 문자열처럼)의 항목들을 그 순서대로 꺼내어 반복함.
fruits = ['사과', '배', '감', '귤']
for fruit in fruits: # fruit 은 임의로 지어준 이름.
print(fruit) # 사과, 배, 감, 귤 하나씩 꺼내어 출력.fruits = ['사과', '배', '귤', '감', '수박', '귤', '딸기', '사과', '배', '수박']
count = 0
for fruit in fruits:
if fruit == '사과':
count = count + 1
# for문을 도는동안 fruit가 사과이면 count가 1씩 추가됨.
# 사과의 갯수를 출력합니다.
print(count)Quiz
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] total = 0 for number in data: total = total + number print(total) # 출력값 : 55
3) 함수
def sum(a, b): # sum() 이라는 함수를 정의함
return a + b
print(sum(3,5)) # 결과 : 7def print_name(name): #print_name()이라는 함수를 정의함
print("반갑습니다 " +name+ " 님")
print_name("레넥톤") # 결과 : 반갑습니다 레넥톤 님Quiz
# 데이터 부분 data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] data2 = {"첫번째값" : 4, "두번째값" : 10} # 함수 정의 def sum(a, b): return a + b
print(sum(1, 4)) # 무엇이 출력될까요? 5 print(sum[0, 2]) # 무엇이 출력될까요? 오류(함수는 소괄호만 써야되서 오류뜸) print(sum(data[0], data[3])) # 무엇이 출력될까요? 5 print(sum(data(3), data(5))) # 무엇이 출력될까요? 오류(데이터는 리스트이기때문에 대괄호를 써야함) print(sum(data2["첫번째값"], data2["두번째값"])) # 무엇이 출력될까요? 14
Pandas
파이썬에서 사용되는 데이터 분석 라이브러리. 관계형 데이터를 행과 열로 구성된 객체로 만들어 준다.
판다스 불러오기
import pandas as pd #pandas를 pd로 부르겠다데이터 불러오기
pd.read_csv('파일의경로+파일의이름')chicken07 = pd.read_csv('./data/chicken_07.csv')./는 현재 디렉토리를 의미. 그러니까 ./data/chicken_07.csv 는 현재 디렉토리(내 노트북)의 하위에 data라는 디렉토리에 있는 chicken_07.csv 파일을 가리킴.
데이터 살펴보기
가장 마지막 데이터 5개
chicken07.tail(5)
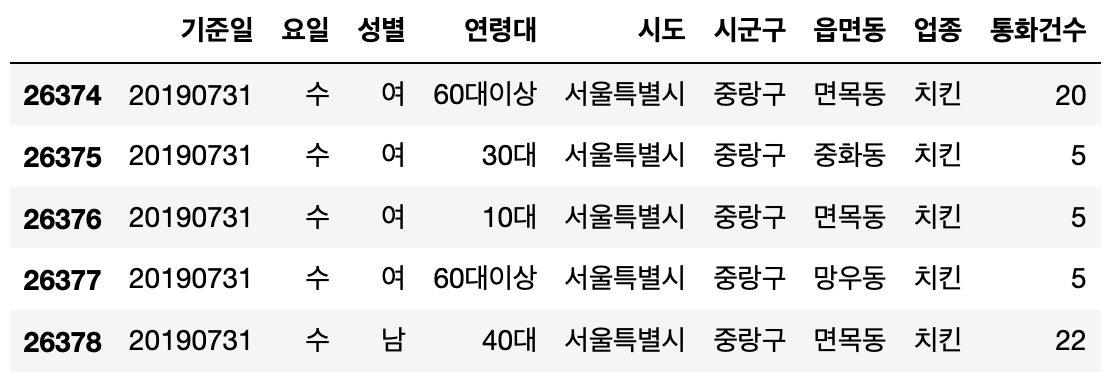
데이터 기본 통계치
chicken07.describe()
count: 갯수mean: 평균std: 표준편차min: 최솟값max: 최댓값
범위 데이터가 기준일과 통화건수 두 개 뿐이라, 이 두 개에 대해서만 나옴. (여기에서 연령대, 성별 등 이런 데이터는 최댓값, 최솟값 없음)
pandas 연습하기
데이터 살펴보기
chicken07['성별'] #데이터에 있는 모든 성별 값이 다나옴(중복되서)
set(chicken07['성별'] #데이터를 집합으로 만들면 중복값이 제거됨 → 남, 여 2개만 나옴
len(set(chicken07['성별']) # 구성요소들의 갯수를 세어줄 때는 `len()`ex)
gender_range = set(chicken07['성별']) print(gender_range, len(gender_range)) # {'남', '여'} 2
데이터 합치기(세로로 합치기) contact 함수 사용
chicken07 = pd.read_csv('./data/chicken_07.csv')
chicken08 = pd.read_csv('./data/chicken_08.csv')
chicken09 = pd.read_csv('./data/chicken_09.csv')
# 3분기 데이터
chicken_data = pd.concat([chicken07, chicken08, chicken09])
chicken_data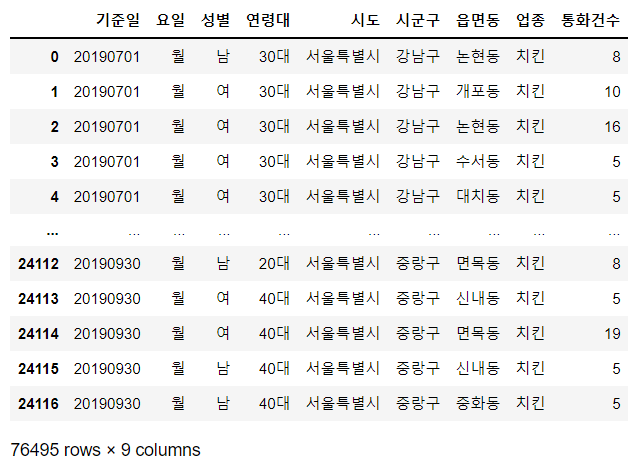 맨 앞에있는 인덱스가 이상함.
맨 앞에있는 인덱스가 이상함.
전체 76495개 인데 결과 값에는 기존의 9월 데이터가 갖고 있던 인덱스 값이 그대로 적용되어 있음.
chicken_data = chicken_data.reset_index(drop = True)
chicken_data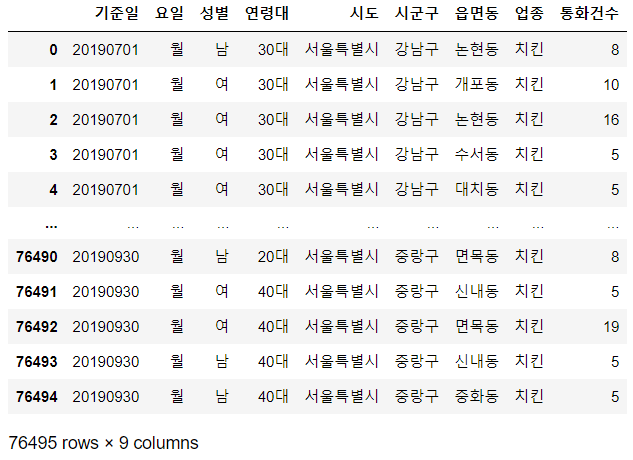
Matplotlib
파이썬에서 사용되는 시각화 라이브러리
Matplotlib 불러오기
import pandas as pd import matplotlib.pyplot as pltmatplotlib가 덩치가 굉장히 큰 라이브러리여서
import matplotlib as plt로 못쓰고 matplotlib.pyplot을 갖다 쓸거다
예제
요일별 총 통화 건수를 살펴보자!
이러한 그래프를 생각했다면..
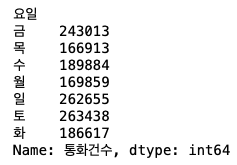
요일별 치킨 데이터는 굉장히 많기에 우선 요일별로 묶어주고 각 요일별 통화 건수를 모두 더하면 됨.sum_of_calls_by_week = chicken_data.groupby('요일')['통화건수'].sum() #요일별로 그룹을 묶어준 뒤 '통화건수'만 추출해서 보겠다(딕셔너리에서 원하는 키 값 추출하는 것 처럼). 그리고 그걸 다 더할거다. sum_of_calls_by_week
이제 이걸 그래프로 만들면plt.figure(figsize=(8,5)) # 그래프의 사이즈 plt.bar(sum_of_calls_by_week.index, sum_of_calls_by_week) # bar 그래프에 x축, y축 값을 넣어줍니다. index는 위에 sum_of_calls_by_week의 결과에서 그룹으로 묶어줬던 요일임. plt.title('요일에 따른 치킨 주문량 합계') # 그래프의 제목 plt.show() # 그래프 그리기
폰트를 설정해주지 않아 한글이 깨지는 현상이 발생함.
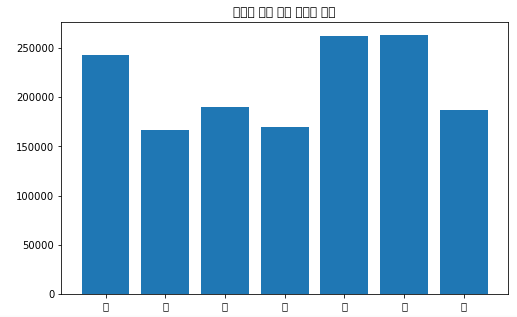
한글을 지원하는 폰트를 설정해서 그래프를 그려보자!
현재 설정되어 있는 폰트 확인
print('설정 되어 있는 폰트 사이즈 :', plt.rcParams['font.size']) print('설정 되어 있는 폰트 글꼴 :', plt.rcParams['font.family'])한글을 지원하는 폰트로 바꾸기
# Apple은 'AppleGothic', Windows는 'Malgun Gothic'을 추천 plt.rcParams['font.family'] = "Malgun Gothic"다시 그래프 그리기
plt.figure(figsize=(8,5)) # 그래프의 사이즈 plt.bar(sum_of_calls_by_week.index, sum_of_calls_by_week) # bar 그래프에 x축, y축 값을 넣어줍니다. plt.title('요일에 따른 치킨 주문량 합계') # 그래프의 제목 plt.show() # 그래프 그리기
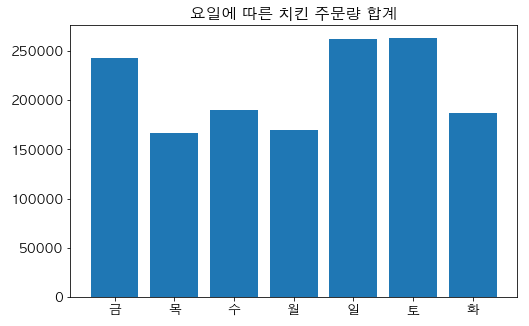
Matplolib 그래프를 정렬해서 그려보기
sum_of_calls_by_week = chicken_data.groupby('요일')['통화건수'].sum()
sum_of_calls_by_week
- 코드가 너무 길죠?
- 체이닝(Chaining)이라고 하는 나열법인데, 익숙하면 편해요. 하지만 지금은 잘라서 살펴보겠습니다.
chicken_data.groupby('요일'):일단 데이터를 요일 별로 그룹을 지어줍니다.- 모든 데이터는 월~일요일을 기준으로 7 덩어리가 되었겠죠?
chicken_data.groupby('요일')['통화건수']: 그 중에서 통화 건수를 선택합니다chicken_data.groupby('요일')['통화건수'].sum(): 요일 별 통화 건수의 총합을sum_of_calls_by_week변수에 저장합니다.
점점 증가하는 그래프 그리기
# 요일 별로 모아주기
groupdata = chicken_data.groupby('요일')
# '통화건수' 열만 떼어보기
call_data = groupdata['통화건수']
# 요일 별로 더해주기
sum_of_calls_by_week = call_data.sum()
sorted_sum_of_calls_by_week = sum_of_calls_by_week.sort_values(ascending=True)
# 점점 증가하는 오름차순으로 정렬
plt.figure(figsize=(8,5)) # 그림의 사이즈
plt.bar(sorted_sum_of_calls_by_week.index, sorted_sum_of_calls_by_week) # 바 그래프
plt.title('요일에 따른 치킨 주문량 합계') # 그래프의 제목
plt.show() # 그래프 그리기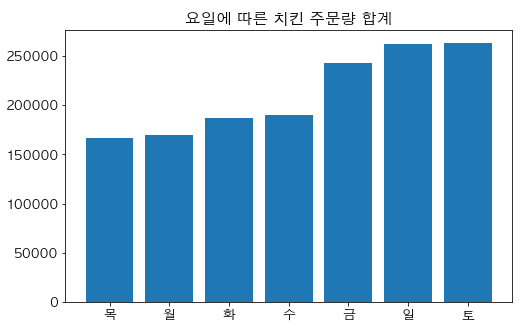
요일 순서대로 그래프 그리기
그릴 그래프의 종류는 같습니다. 데이터도 그대로 입니다. 단지 우리는 요일별로 정렬을 다시 할 뿐입니다. 앞에서 정렬되지 않은 index를 사용했다면, 이번에는 index를 우리가 정한 순서대로 정렬해서 사용해 봅시다.
weeks = ['월', '화', '수', '목', '금', '토', '일'] # 우리가 정한 순서
sum_of_calls_by_weeks = chicken_data.groupby('요일')['통화건수'].sum().reindex(weeks) # 인덱스 다시 정렬
plt.figure(figsize=(8,5)) # 그림의 사이즈
plt.bar(sum_of_calls_by_weeks.index, sum_of_calls_by_weeks) # 바 그래프
plt.title('요일에 따른 치킨 주문량 합계') # 그래프의 제목
plt.show() # 그래프 그리기Quiz
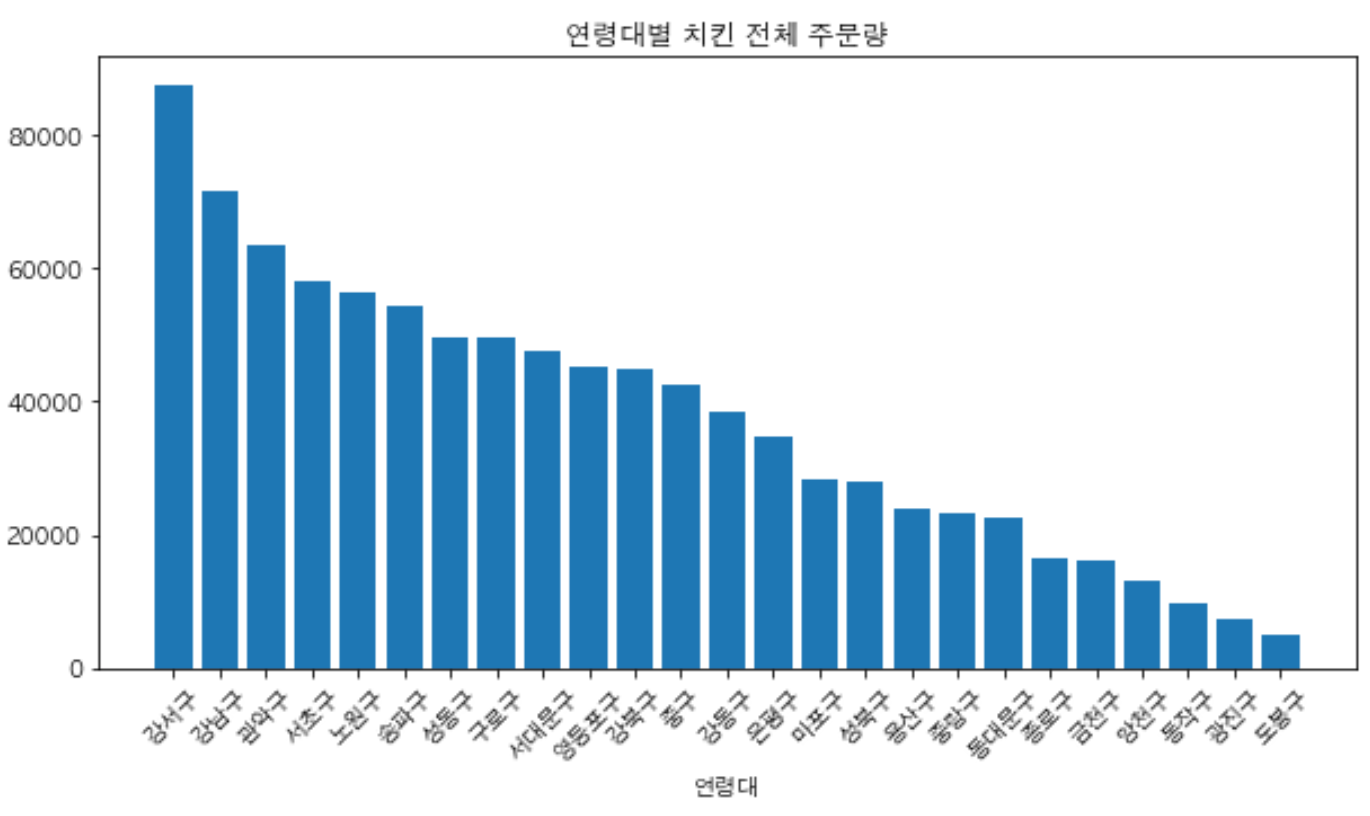
연령대별 치킨 주문량 분석해보기
# 연령대 별로 모아주기 groupdata = chicken_data.groupby('연령대') # '통화건수' 열만 떼어보기 call_data = groupdata['통화건수'] # 요일 별로 더해주기 sum_of_calls_by_age = call_data.sum() # 내림차순으로 데이터 정렬하기 sorted_sum_of_calls_by_age = sum_of_calls_by_age.sort_values(ascending=False) sorted_sum_of_calls_by_ageplt.figure(figsize=(10,5)) plt.bar(sorted_sum_of_calls_by_age.index, sorted_sum_of_calls_by_age) plt.xlabel('연령대') # x축에 이름을 붙여줍니다 plt.title('연령대별 치킨 전체 주문량') plt.show()
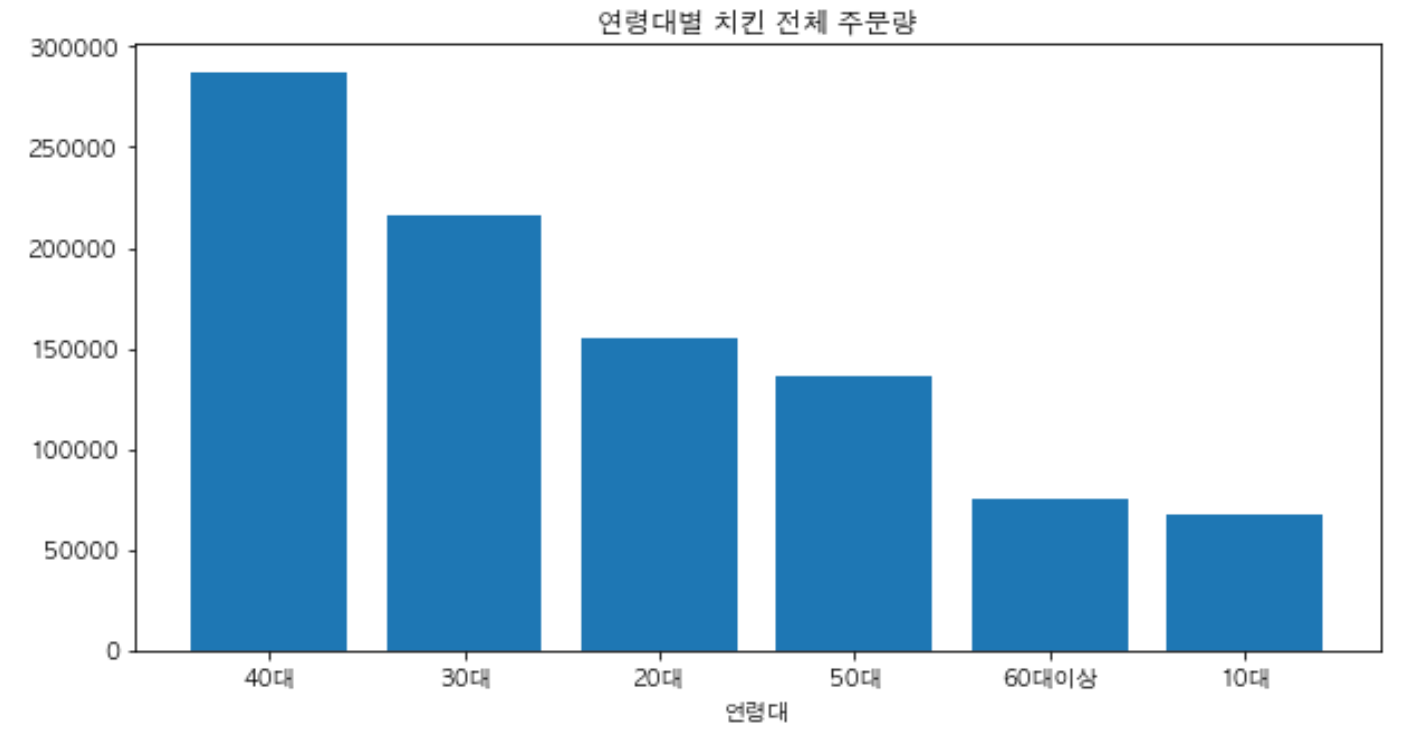
서울에서 치킨은 어디에서 가장 많이 먹을까?
# 시군구 별로 모아주기 groupdata = chicken_data.groupby('시군구') # '통화건수' 열만 떼어보기 call_data = groupdata['통화건수'] # 요일 별로 더해주기 sum_of_calls_by_city = call_data.sum() sorted_sum_of_calls_by_city = sum_of_calls_by_city.sort_values(ascending=False) sorted_sum_of_calls_by_cityplt.figure(figsize=(10,5)) plt.bar(sorted_sum_of_calls_by_city.index, sorted_sum_of_calls_by_city) plt.xlabel('지역별') # x축에 이름을 붙여줍니다 plt.xticks(rotation=45) # x축에 나오는 index값을 45도 기울어지게 표현 plt.title('지역별 치킨 전체 주문량') plt.show()