
유튜브 크롤링 영상을 참고하면서 웹페이지를 크롤링하기위해 파이썬 라이브러리중 Selenium이라는 라이브러리와 Chrome driver라는 프로그램을 같이 사용해서 크롬 환경에서 웹에 접근해 데이터를 가져오는 연습을 해봤다.(mac 환경)
jupyter Notebook에서는 코드를 파이썬 코드를 실행하면 바로바로 결과를 보면서 하기 좋기에 이 환경에서 연습하였다.
selenium을 사용하는 이유
다른 방식인 requests와 Beautifulsoup를 사용하는 방식은
- 로그인이 필요한 경우 어렵게 해야하고
- 동적(웹 사이트의 정보가 바뀔 때 전체를 바꾸는게 아니라 해당 부분만 바꾸는 것)으로 html을 만드는 경우 어렵다
- cmd -> pip install selenium
- 내 pc 크롬 버전에 맞는 크롬 드라이버 설치
- 크롬 드라이버를 jupyter notebook에서 만든 파이썬 스크립트 폴더에 위치
- jupyter notebook 실행 후
from selenium import webdriver로webdriver함수를 불러온 후 사용하려고 하면 에러가 나서pip install webdriver-manager와from webdriver_manager.chrome import ChromeDriverManager추가
초기 설정 결론:
pip install webdriver-manager
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager이후에
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://emart.ssg.com/') #get 이라는 함수를 이용해서 특정 사이트에 들어간다
driver.find_element('xpath','//*[@id="e_gnb"]/div/div[1]/div[2]/ul[1]/li[9]/a').click()참고로
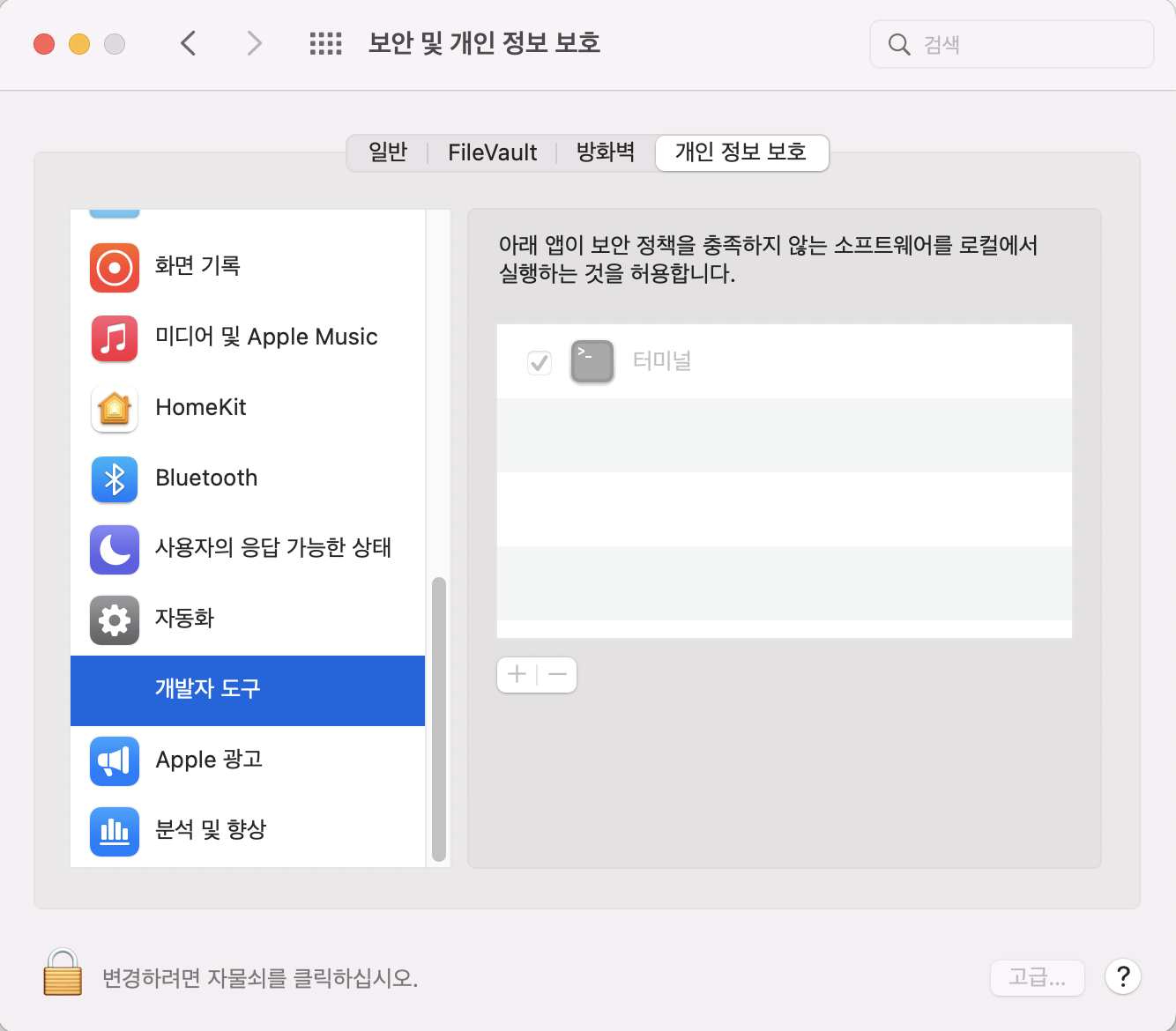
mac에서 위처럼 복잡하게 안하고 일반적인 방식으로 쉽게 할 수 있는 방법을 알아냈다.
시스템 환경설정 -> 보안 및 개인 정보 보호 ->개발자 도구 에서 터미널이 체크가 안되어 있는 경우 위의 방식대로 다소 복잡한 코드를 짜야 하지만 터미널에 체크를 하면from selenium import webdriver driver = webdriver.Chrome('/Users/pdj/Desktop/Untitled Folder/chromedriver') driver.get('https://emart.ssg.com/')만으로도 크롬드라이버를 실행시킬 수 있다
아.. 근데 또 주피터 말고 다른 프로그램으로 하니까 안되네..
제목 크롤링 테스트
driver.find_element('xpath','//*//*[@id="ty_thmb_view"]/ul/li['+str(i)+']/div[2]/div[2]/div/a/em[1]').text가격 크롤링 테스트
driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li[1]/div[2]/div[3]/div[1]/em').textfor문은 활용해 제목과 가격 크롤링
for i in range(1,81):
product_name = driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li['+str(i)+']/div[2]/div[2]/div/a/em[1]') # i를 문자 형태로 가져와서 사이에 넣는다, +는 문자열 연결을 위해 사용
price = driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li['+str(i)+']/div[2]/div[3]/div/em')
print(product_name.text)
print(price.text+'원')pandas를 활용해 하나의 표 형태로 만들기
#하나의 데이터 프레임으로 만들기 위해 list형태로 만듬
product_list = []
price_list = []
for i in range(1,81):
product_name = driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li['+str(i)+']/div[2]/div[2]/div/a/em[1]') # i를 문자 형태로 가져와서 사이에 넣는다, +는 문자열 연결을 위해 사용
price = driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li['+str(i)+']/div[2]/div[3]/div/em')
product_list.append(product_name.text)
price_list.append(price.text)이후에
import pandas as pd #pandas를 불러오고그리고
pd.DataFrame({'상품명':product_list,'가격':price_list})
#DataFrame이라는 함수를 이용해서 표 형태로 표현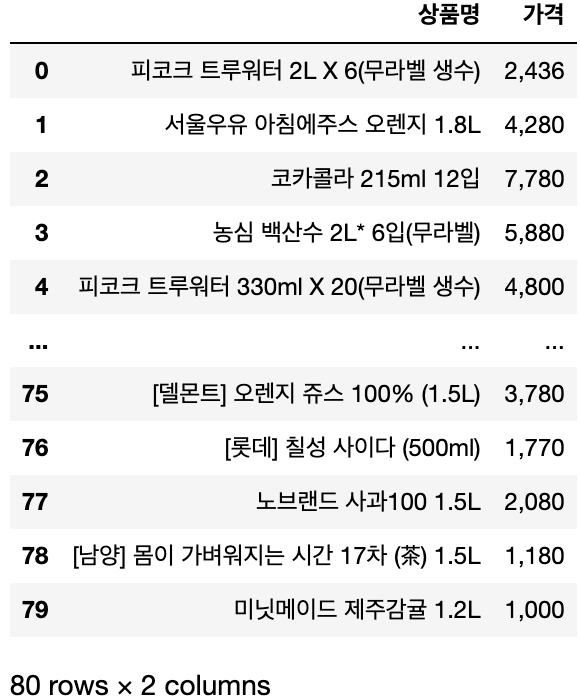
이미지 가져오기
product_image = driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li[1]/div[1]/div[2]/a/img[1]')
img_url = product_image.get_attribute('src')
print(img_url)for문을 활용해 이미지 가져오기
for i in range(1,81):
product_image = driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li['+str(i)+']/div[1]/div[2]/a/img[1]')
img_url = product_image.get_attribute('src')
print(img_url)But 이때 발생하는
NoSuchElementException에러
찾아보니 for문에서 돌린 xpath의 경로가 모든 이미지에 동일하게 적용이 안되다 보니 중간에 예외가 발생해 그 전까지만 이미지를 추출하고 에러가 발생한 것!
그렇기에 예외를 건너뛰게 하는 로직이 필요함!!!

상단에
from selenium.common.exceptions import NoSuchElementException을 넣어주고 마무리 코드
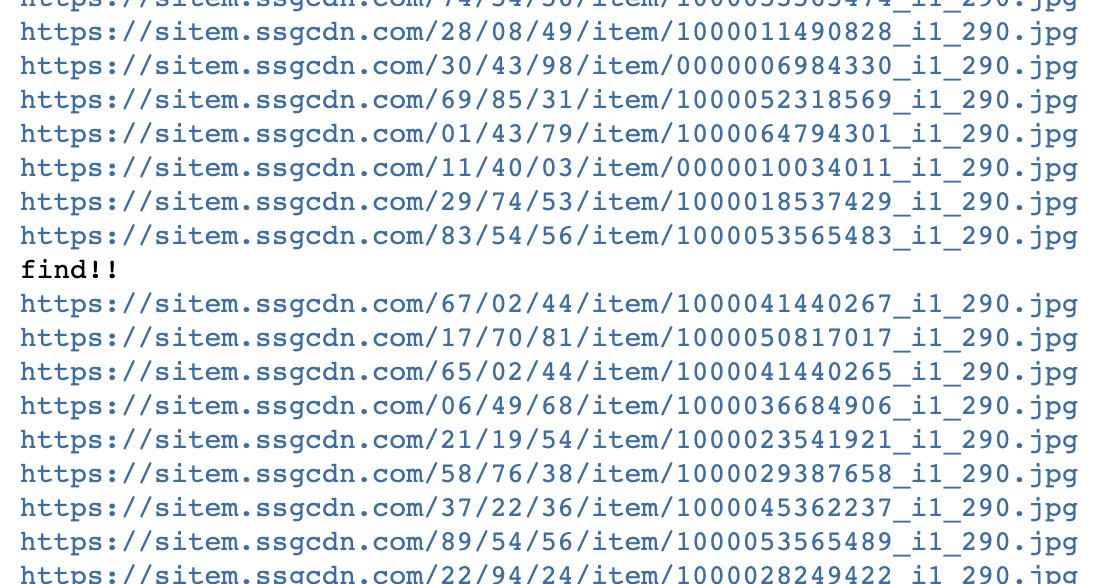
for i in range(1,81):
try:
product_image = driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li['+str(i)+']/div[1]/div[2]/a/img[1]')
img_url = product_image.get_attribute('src')
print(img_url)
except NoSuchElementException:
print('find!!')실행 결과
가져온 이미지를 컴퓨터에 저장하는 법
for i in range(1,81):
try:
product_image = driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li['+str(i)+']/div[1]/div[2]/a/img[1]')
img_url = product_image.get_attribute('src')
print(img_url)
except NoSuchElementException:
print('find!!')
urllib.request.urlretrieve(img_url,'image_data/image'+str(i)+'.png') #image_data라는 폴터안에 image()로 이미지가 저장됨. 단 image_data라는 폴더를 미리 만들어 놓고페이지를 넘어다니면서 데이터 수집(상품명, 가격)
driver.implicitly_wait(10) #다음 페이지가 띄워질때 까지 최대 10초 까지는 기다려 주겠다이게 중요한 이유!
이걸 먼저 실행시켜주지 않으면
NoSuchElementException 에러가 뜸.
이유는 크롤링이 웹 서버로부터 응답받은 자원에서 자원의 Html안에 있는 데이터를 가져오겠다는 얘기임.
but 다음 페이지로 넘어가는 동작을 하게되면 다음 페이지에 있는 데이터를 띄워주는 데 까지 시간이 걸림.
근데 그 텀 사이에 for문 코드가 실행되버리면 해당 페이지 안에 그 태그가 없다고 에러가 뜸.
그래서 다음 페이지가 뜰때까지 시간을 지연시키는 작업을 해줘야함.
이후에 이 코드를 실행하면 됨
product_list = []
price_list = []
for j in range(1,10):
for i in range(1,81):
product_name = driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li['+str(i)+']/div[2]/div[2]/div/a/em[1]') # i를 문자 형태로 가져와서 사이에 넣는다, +는 문자열 연결을 위해 사용
price = driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li['+str(i)+']/div[2]/div[3]/div/em')
product_list.append(product_name.text)
price_list.append(price.text)
driver.find_element('xpath','//*[@id="area_itemlist"]/div[2]/a['+str(j)+']').click() #위의 80개의 for문이 돌아가고 클릭되서 다음 페이지로 넘어감최종본 - try, except, finally 사용
크롤링을 실행하던 중 데이터가 비어있다면 중간에 오류가 발생하면 코드가 정지되고 더이상 수집되지 않음.(위에서 이미지 추출과 유사하지만 조금 다른 방식 적용할 예정)
그래서 그럴때 쓰는게 try:, except:, finally: 로직
try에 종속되어 있는 구문을 먼저 실행하다가 오류가 발생하면 except에 종속되어 있는 구문을 실행. 그리고 이후에 바로 finally에 종속되어 있는 문장을 실행.
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://emart.ssg.com/')
driver.find_element('xpath','//*[@id="e_gnb"]/div/div[1]/div[2]/ul[1]/li[9]/a').click()
driver.implicitly_wait(10)
product_list = []
price_list = []
for j in range(1,10):
for i in range(1,81):
try:
product_name = driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li['+str(i)+']/div[2]/div[2]/div/a/em[1]') # i를 문자 형태로 가져와서 사이에 넣는다, +는 문자열 연결을 위해 사용
price = driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li['+str(i)+']/div[2]/div[3]/div/em')
product_image = driver.find_element('xpath','//*[@id="ty_thmb_view"]/ul/li['+str(i)+']/div[1]/div[2]/a/img[1]')
img_url = product_image.get_attribute('src')
urllib.request.urlretrieve(img_url,'image_data/'+str(j)+'image'+str(i)+'.png')
product_list.append(product_name.text)
price_list.append(price.text)
except Exception as e: #오류가 발생하면 Exception이라는 오류 메시지를 e라고 표현 하고 출력해라. 만약 i=17이 없는 구문이면 크롤링이 안끝나고 e를 출력한 뒤
print(e)
finally:
pass #그냥 넘김
driver.find_element('xpath','//*[@id="area_itemlist"]/div[2]/a['+str(j)+']').click() #한 페이지의 for문을 돌고 다음 페이지로 이동
print(j, 'page Done')
driver.quit()상품명, 가격 리스트 엑셀파일로 추출
df1=pd.DataFrame({'상품명':product_list,'가격':price_list})
df1.to_excel('result2.xlsx')