컴퓨터는 0과 1로된 데이터만을 이해하지만 사람은 다르다.
사람은 한글, 영어, 숫자, 특수문자 등 다양한 표현법에 따른 데이터를 이해한다.
컴퓨터가 이해할 수 있는 데이터를 표현하는 방법과
0과 1로 표현된 데이터가 어떻게 사람이 이해할 수 있는 정보로 바뀌게 되는지 그 과정을 정리한다.
0과 1로 숫자를 표현하는 방법
-
0과 1로 표현하는 가장 작은 정보의 단위는 비트이다.
8개의 비트가 모여 byte가 된다.
1byte 1000개가 모여 1kB(킬로바이트)가 된다.
1kB 1000개가 모여 1MB(메가바이트)가 된다.
1MB 1000개가 모여 1GB(기가바이트)가 된다.
1GB 1000개가 모여 1TB(테라바이트)가 된다. -
워드는 CPU가 한번에 처리할 수 있는 데이터의 크기
이진법
- 이진수를 표현할 때
0b1000
1000(2) - 이진수의 음수는 2의 보수로 표현된다.
2의 보수= 어떤 수를 그보다 큰 2의 n승에서 뺀 값 = 0과 1을 뒤집고 거기에 1을 더한값
하지만 여기 한계가 존재한다. 0과 2의 n승으로 표현되는 숫자는 표현할 수 없다는 것
십육진법
이진법을 통해 표현하는 것은 길이가 너무 길기 때문에 이를 보완하기 위해 십육진법도 사용한다. 다른 큰 진법도 있는데 왜 십육진법일까?
그 이유는 이진수를 십육진수로 변환하거나 십육진수를 이진수로 변환하는 과정이 다른 진수에 비해서 편리하기 때문이다.
- 십육진수를 표현할 때
0x15
15(16) - 0~9, A~F
0과 1을 문자로 표현하는 방법
여기는 코딩할 때 자주 등장하는 문제이다.
한글이 깨지는 문제
"뷁 꿝"이런 문자가 등장할 때이다.
이는 인코딩을 잘못하거나 디코딩이 잘못되었거나 혹은 그 둘다 이상하거나 할 때 발생한다.
또는 컴퓨터가 인식하고 표현할 수 있는 문자 집합이 있는데 그 문자 집합에 포함되지 않은 단어가 인코딩이나 디코딩되는 과정에서 발생하는 문제일지도 모른다.
여기서 인코딩은 "문자집합에 속한 문자를 컴퓨터가 이해하는 0과 1로 된 데이터로 변환하는 과정"을 말한다.
디코딩은 "0과 1로 표현된 컴퓨터의 언어를 사람이 이해할 수 있는 문자로 변환하는 과정"을 말한다.
문자집합은 여러가지가 있는데 그 종류를 살펴보자
아스키 코드
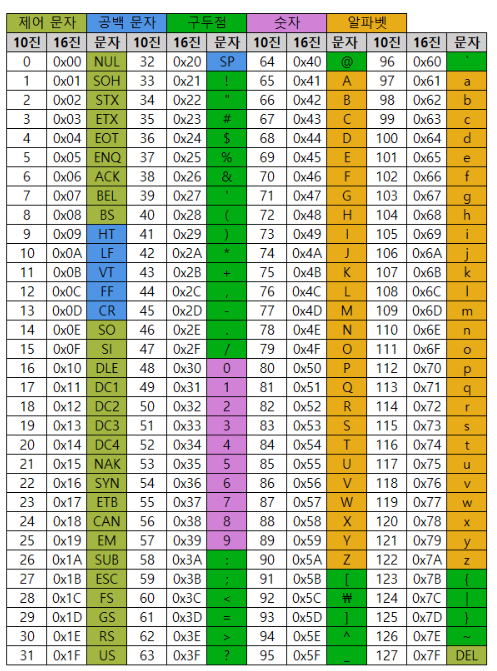
아스키 코드는 여러 문자집합 중의 하나이다.
초창기 문자 집합이며 7비트로 표현되기 때문에 2의 7승인 128개까지만 표현된다. 그 종류가 다양하지 않기 때문에 8비트로 표현되는 확장된 아스키가 등장했다.
아스키 코드 = 영어 알파벳 + 아라비아 숫자 + 일부 특수문자
그러나 굵은 글씨와 같이 한글과 같이 영어권 이외 나라의 언어를 표현할 수 없다.
그래서 등장한 것이 EUC-KR로 한글 인코딩 방식이다.
한글 인코딩 : EUC - KR

한글은 영어 달리 한글자에 초성, 중성, 종성으로 이루어져 있는데 이를 나눠서 표현하는 방법인 조합형 인코딩 방식과
한번에 한글자 전체를 표현하는 완성형 인코딩 방식이 있다.
EUC-KR의 경우는 완성형 인코딩 방식으로 한글 한글자에 2바이트 크기의 코드를 부여한다.
하지만 한글 전체를 표현하기에는 그 수가 부족하기 때문에 이보다 더 다양한 마이크로소프트의 CP949가 있다.
다국어 인코딩 : 유니코드
나라마다 인코딩 방식이 다르다면
개발할 때 모든 나라의 인코딩 방식을 적용하기에는 불편하기 때문에 다국어를 지원하는 인코딩인 유니코드가 등장했다.
모든 나라의 문자집합과 인코딩 방식이 통일된 것이 유니코드이다.
유니코드는 아스키코드나 EUC-KR과 다르게 글자에 부여된 고유의 값인 코드 포인트를 그대로 사용하지 않고 다양한 인코딩 방식을 가지고 있다.
많이 보았던 UTF-8도 유니코드의 다양한 인코딩 방식 중의 하나이다. 이 외에도 UTF-16, UTF-32 등이 있다.
