데브코스에서 진행하는 바우처 2주차 미션을 하며
빋은 코드리뷰들을 정리해보려고 합니다.
혹시나 이상한 내용이나 고칠 부분들이 있다면
자유롭게 댓글로 남겨주세요
❓ @BeforAll과 @Before의 차이는 무엇인가
- @BeforeAll
- 테스트 전체에 한번만 실행되기 원한다면 @BeforeAll를 사용해요.
- 기본적으로 테스트의 각 메소드를 실행할 때마다 테스트 클래스의 새로운 인스턴스를 생성
- 따라서 @BeforeAll이 붙은 메서드는 static이어야 해요.
- 단, @TestInstance(Lifecycle.PER_CLASS)는 하나의 인스턴스를 각 메서드마다 재사용하기 때문에
@BeforeAll에 static이 붙이지 않아도 됩니다.
- @BeforeEach
- 이 어노테이션이 붙은 메서드는 각 테스트 메서드가 진행될 때마다 실행해요
- @TestInstance(Lifecycle.PER_CLASS)의 경우 하나의 인스턴스를 재사용하기 때문에 인스턴스에 있는 인스턴스 변수를 초기화하는 과정에서 사용될 수도 있어요
❓LifeCycle_PER_CLASS는 어떤 설정인가요
@SpringJUnitConfig
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestInstance(TestInstance.Lifecycle.PER_CLASS)원래 디폴트(LifeCycle.PER_METHOD)는 각 테스트 메소드마다 테스트 클래스의 인스턴스를 새롭게 생성하는데 LifeCycle.PER_CLASS는 새로운 인스턴스를 만들지 않고
하나만 만들어서 각 테스트 메소드마다 같은 인스턴스를 사용해요
위 테스트 코드의 경우
데이터 소스를 읽어서 접근하는데 그 비용이 많이 들기 때문에 한 번만 생성하기 위해서 위 조건을 걸었어요
하지만 뒤태 지존님의 깃허브에 dev-tip에 따라
다시 생각해보니 DB의 읽기만 하는 것이 아니라 데이터를 insert하는 테스트 메서드가 있어서 데이터가 오염될 수 있는 상황을 고려하지 못한 것 같아요
- 추가 물음 🕵️♀️
- 하나의 인스턴스를 공유한다는 전제하에 @Order를 통해 순서를 부여해서 뭔가 이야기처럼 연결되도록 구성하였는데
혹시 이 방법이 잘못된 방법인 걸까요?
- 하나의 인스턴스를 공유한다는 전제하에 @Order를 통해 순서를 부여해서 뭔가 이야기처럼 연결되도록 구성하였는데
- 답변
- 단위 테스트는 독립적이어야 한다 따라서 @Order 사용은 꼭 필요한 경우에 사용해야 한다.
- 필요한 경우의 예시
- 주문이라고 가정하면 결제 -> 주문 등 순차적으로 시나오리식 테스트를 할 때 유용하다.
- 정리
제 코드는 그냥 데이터의 단순 CRUD 작업이었기 때문에 꼭 필요한 경우가 아니었어요
추가적으로 멘토님께서 F.I.R.S.T 원칙에 대해서 찾아보시라고 해서 다음과 같이 정리해보았습니다.
❓F.I.R.S.T란 무엇일까?
- Fast : 유닛테스트는 빨라야 한다
일이 하는 단위가 작아야 한다
또한 빠른 테스트를 위해서 실제 서버나 데이터 베이스를 이용하지 않고 가짜 데이터를 만들어서 테스트를 진행해야 한다. - Isolated : 다른 테스트에 종속적인 테스트는 절대적으로 작성하지 않는다
그 자체만으로 실행되어 한다. - Repeatable: 테스트는 실행할 때마다 같은 결과를 만들어야 한다.
- Self-validating : 테스트는 스스로 결과물이 옳은지 그른지 판단할 수 있어야 한다
실패인 것도 아니고 성공한 것도 아닌 테스트를 만들지 말자 - Timely : 테스트는 적시에 작성해야 한다.
단위테스트는 테스트 하려는 실제 코드를 구현하기 직전에 구현해야 한다.
❓ @JdbcTest를 도입해 보는걸 어떨까
@SpringJUnitConfig
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
class JdbcCustomerRepositoryTest {
@Configuration
@ComponentScan(
basePackages = {"com.prgrms.repository.customer"}
)
static class Config {
@Bean
public DataSource dataSource() {
return DataSourceBuilder.create()
.url("jdbc:mysql://localhost/order_byeol")
.username("root")
.password("****")
.type(HikariDataSource.class)
.build();
}
@Bean
public JdbcTemplate jdbcTemplate(DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
@Bean
public NamedParameterJdbcTemplate namedParameterJdbcTemplate(JdbcTemplate jdbcTemplate) {
return new NamedParameterJdbcTemplate(jdbcTemplate);
}
}기존의 코드입니다.
보시면 제가 직접 데이터 소스 관련 빈들을 만들어서 관계를 만들어서 주입하고 있어요
멘토님께서 이 부분에 대해서
jdbc만을 테스트 하고싶다면
@ JdbcTest 라는 어노테이션에 대해 알아보셔도 좋습니다.
라는 피드백을 주셔서 @JdbcTest에 대해서 찾아보게 되었어요
@JdbcTest는 무엇인가?
이 어노테이션은 오직 Jdbc 관련 컴포넌트들에 초점이 맞춰있어요
그래서 전체 auto-configuration 사용이 불가능합니다.
또한 이 어노테이션이 붙은 클래스의 각 테스트마다 transcational과 롤백을 지원된다고 합니다.
그래서 스프링 컨테이너에 제가 등록한 빈을 가져오기 위해서 @Import을 사용했어요
그리고 마지막으로 임베디드 메모리 데이터 베이스를 사용합니다. 그래서 저의 경우 임베디드 데이터 베이스를 사용하지 않았기 때문에 @AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)을 붙여서 외부 데이터 베이스를 연결했어요
그래서 개선된 코드는 아래와 같아요
개선된 코드
@JdbcTest
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
@Import({JdbcCustomerRepository.class, DataRowMapper.class})
class JdbcCustomerRepositoryTest {
private final String TEST_USER_NAME = "test-user";
private final String TEST_USER_EMAIL = "test1-user@gmail.com";
private final int CUSTOMERS_SIZE = 4;
private final int ID = 10;
@Autowired
private JdbcCustomerRepository jdbcCustomerRepository;❓ select의 *보다 구체적으로 필드명을 명시해보는 건 어떨까
*을 사용하면 코드를 입력하는 저의 입장에서는 편할지 몰라고 다른 개발자가 저의 코드를 볼 때 어떤 데이터가 들어오는지 다시 한번 데이터 베이스를 살펴봐야 하고
또한 필요없는 속성도 같이 들어오기 때문에 좋지 않은 방법이라고 해요
❓ Exist와 Count의 성능 차이는 무엇일까
@Override
public int count() {
return jdbcTemplate.queryForObject("select count(*) from customers", Collections.emptyMap(), Integer.class);count 쿼리의 경우 where 조건문이 매우 중요하다는 피드백을 받았어요
또한 멘토님께서 항상 테이블에 데이터가 많으면 어떻게 해야할까라는 고민을 가지고 데이터 베이스를 공부하라고 하셨어요
그래서 count에 대해서 찾아보니 전체 데이터를 읽기 때문에 조건절이 중요하며
데이터의 존재 유무를 판단하기 위해서는 count 대신
조건을 만족하는 데이터가 하나라도 있으면 스캔을 종료하는 exist를 사용하는게 좋다고 해요
그래서 아래와 같이 만들어 보았습니다.
@Override
public boolean existsById(int voucher_id) {
return jdbcTemplate.queryForObject("SELECT 1 EXISTS(SELECT FROM vouchers WHERE voucher_id = :voucher_id)"
, Collections.singletonMap("voucher_id"
, voucher_id), Boolean.class);
}❓@DisplayName에 관하여
@DisplayName은 각 단위테스트가 무엇을 반환하는지 어떤 걸 위해서 존재하는지 문서화가 되는 부분이라서
구체적으로 작성해야 한다고 해요
저의 경우
@DisplayName("음수인 경우 예외를 던지는지 테스트한다.")위와 같이 사용했는데
맨토님께서 아래의 방법으로 예시로 보여주셨어요
바우처의 고정 할인값이 음수가 들어오면 생성할 수 없다❓테스트 코드가 필요한 경우
테스트 코드가 필요없는데도 작성한 테스트들이 있어서 이에 대해서 생각해보게 되었습니다.
테스트 코드가 언제 필요한가
- 예외 상황 처리
- 핵심 비즈니스 로직
- 분기점이 있는 경우
- 성능 및 부하 테스트가 필요한 경우
❓ var의 장단점은 무엇일까
제가 생각한 var의 장점은 데이터의 자료형이 바뀌어도 수정할 부분이 없다는 것입니다.
하지만 다른 개발자들과 일하게 된다면 사용하는데 조심해야한다고 생각해요
자료형을 판단할 수 없기 때문에 무엇을 반환하는지 알 수 없고 그래서 코드를 다시 찾아봐야 하는 비용이 발생합니다.
따라서 장점보다 단점이 많기 때문에 사용을 지양해야 한다고 생각해요
마지막으로 해결하지 못한 것
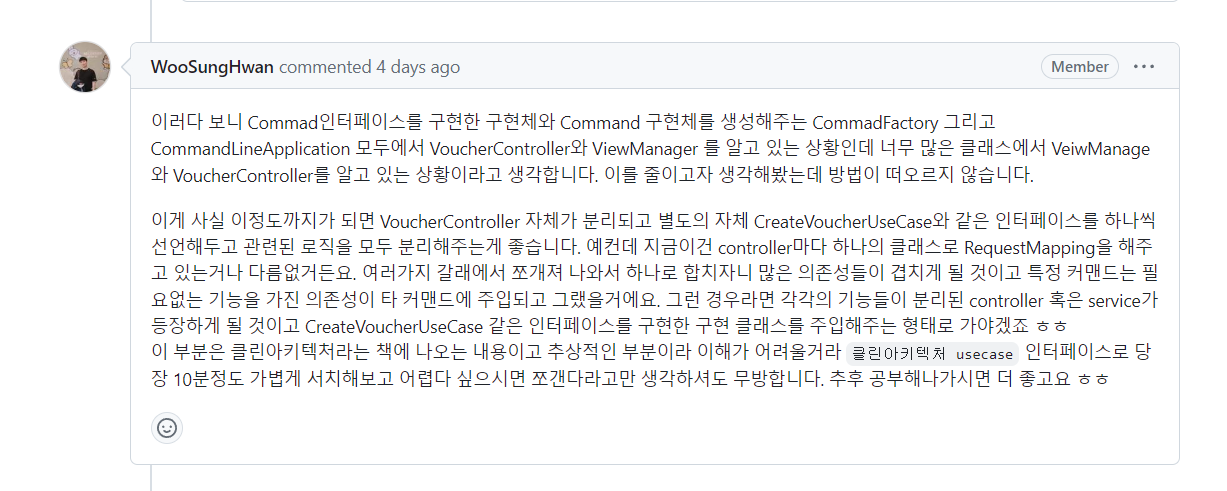
위 세 줄이 저의 질문이었는데요
사실 유즈케이스 인터페이스 아키텍처 관련 영상을 시청하고
관련 예시 코드를 보았을 때
어떤 개념인지 정확하게 와닿지 않아서
조금씩 스며들며 학습하기로 했어요
꾸준하게 학습하면 언젠가
할 수 있는 날이 올거라고 생각해요
