
SELECT
[,그룹함수(속성명)][AS 별칭]
[.WINDOW 함수 OVER (PARTITION BY 속성명1, 속성명2, ...
ORDER BY 속성명3, 속성명4, ..)[AS 별칭]]
FROM 테이블명
[WHERE 조건]
[GROUP BY 속성명,..]
[HAVING 조건]
[ORDER BY 속성명 [ASC|DESC]]
위 문법의 순서를 기억하는 것도 중요합니다.
1차 밑그림에서는 전체를
2차 밑그림에서는 그룹으로 묶었을 때의 밑그림이 진행됩니다.
1차 밑그림
SELECT
[,그룹함수(속성명)][AS 별칭]
[.WINDOW 함수 OVER (PARTITION BY 속성명1, 속성명2, ...
ORDER BY 속성명3, 속성명4, ..)[AS 별칭]]
FROM 테이블명
[WHERE 조건]
[GROUP BY 속성명,..][HAVING 조건]
[ORDER BY 속성명 [ASC|DESC]]
-
SELECT
✅PREDICATE : 불러올 튜플의 수를 제한- ALL : 모두, 주로 생략
- DISTINCT : 중복된 튜플 중에 하나만
- DISTINCTROW : 중복된 튜플을 제거하고 한개만 검색, 선택된 속성의 값이 아닌 튜플 전체를 대상
-
FROM
-
WHERE
✅하위 질의//취미가 댄스인 사원의 이름과 주소를 검색하시오 SELECT 이름,주소 FROM 사원 WHERE 이름 = (SELECT 이름 FROM 여가활동 WHERE 취미='댄스'); //취미 활동을 하지 않는 사원들을 검색하시오 SELECT * FROM 사원 WHERE 이름 NOT IN (SELECT 이름 FROM 여가활동); //취미 활동을 하는 사원들의 부서를 검색하시오 SELECT 부서 FROM 사원 WHERE EXISTS (SELECT 이름 FROM 여가활동 WHERE 사원.이름=여가활동.이름);✅ IS NULL과 IS NOT NULL
✅LIKE- '%' : 모든 문자를 대표
- '-' : 문자 하나를 대표
- '#' : 숫자 하나를 대표
- 날짜 데이터는 숫자로 취급하지만 ##나 ''로 묶어줍니다.
SELECT * FROM 사원 WHERE 생일 BETWEEN #01/01/69# AND #12/31/73#
-
ODER BY
기본이 ASC 오름차순으로 생략가능, DESC는 내림차순으로 명시해야 합니다.
2차 밑그림
더 세부적으로 들어갑니다.
SELECT
[,그룹함수(속성명)][AS 별칭]
[.WINDOW 함수 OVER (PARTITION BY 속성명1, 속성명2, ...
ORDER BY 속성명3, 속성명4, ..)[AS 별칭]]
FROM 테이블명
[WHERE 조건]
[GROUP BY 속성명,..]
[HAVING 조건]
[ORDER BY 속성명 [ASC|DESC]]
-
그룹함수
GROUP BY절에 지정된 그룹별로 속성의 값을 집계할 함수를 기술합니다.- COUNT
- SUM
- AVG
- MAX
- MIN
- STDDEV
- VARLANCE
- ROLLUP(속성명, 속성명,..)
인수로 주어진 속성명을 대상으로 그룹별 소계를 구하는 함수
속성의 개수가 N개이면 N+1 레벨까지, 하위 레벨에서 상위 레벨 순으로 데이터가 집계됩니다. - CUBE(속성명, 속성명, ...)
ROLLUP과 유사한 형태이나 CUBE는 인수로 주어진 속성을 대상으로 모든 조합의 그룹별 소계를 구합니다.
속성의 개수가 N개이면 2의 N승레벨까지, 상위 레벨에서 하위 레벨 순으로 데이터가 집계됩니다.
-
WINDOW 함수
GROUP BY절을 이용하지 않고 속성의 값을 집계할 함수를 기술합니다,- PARTITON BY : WINDOW 함수가 적용할 범위로 사용할 속성을 지정합니다.
- ORDER BY : PARTITON 안에서 정렬 기준으로 사용할 속성을 지정합니다.
- ROW_NUMBER() : 윈도우별로 각 레코드에 대한 일련 번호 반환
- RANK() : 윈도우별로 순위를 반환하며, 공동 순위로 반영
- DENSE_RANK() : 윈도우별로 순위를 반환하며, 공동 순위를 무시하고 순위를 부여
//상여금 테이블에서 상여내역별로 상여금에 대한 일려번호를 구하시오. //(단, 순서는 내리마순이며 속성명은 'NO'로 할 것 SELECT 상여내역, 상여금, ROW_NUMBER() OVER(PARTITION BY 상여내역 ORDER BY 상여금 DESC) AS NO FROM 상여금; //상여금 테이블에서 상여내역별로 상여금에 대한 순위를 구하시오 //(단, 순서는 내림차순이며, 속성명은 '상여금 순위'로 하고 RANK()함수를 이용할 것) SELECT 상여내역, 상여금, RANK() OVER(PARTITION BY 상여내역 ORDER BY 상여금 DESC) AS 상여금 순위 FROM 상여금
-
GROUP BY
특정 속성을 기준으로 그룹화하여 검색할 때 사용합니다.
일반적으로 GROUP BY절은 그룹함수와 함께 사용합니다.//1. 상여금 테이블에서 부서별 상여금의 평균을 구하시오 SELECT 부서, AVG(상여금) AS 평균 FROM 상여금 GROUP BY 부서 // 2. 상여금 테이블에서 부서별 튜플 수를 구하시오 SELECT 부서 , COUNT(*) AS 사원수 FROM 상여금 GROUP BY 부서 // 3. 상여금 테이블에서 상여금이 100이상인 사원이 2명 이상인 부서의 튜플 수를 구하시오 SELECT 부서 , COUNT(*) AS 사원수 FROM 상여금 WHERE 상여금 > = 100 GROUP BY 부서 HAVING COUNT(*) >=2;3번 문제에서 중요한 부분이 등장합니다.
처음에 저는 밑그림 작업을 했습니다.
그 작업이 먼저 일어난다는 것을 기억해야 합니다.
첫 번째 밑그림 작업이 SQL에서 먼저 일어나고
두 번째 밑그림 작업이 첫번째 밑그림 작업 이후에 발생합니다.
따라서 상여금이 100 이상인 사람을 검색하는 일은 첫 번째 밑그림의
WHERE절에서 발생한다는 것을 익혀야 합니다.// 4. 상여금 테이블의 부서, 상여내역 그리고 상여금에 대해 부서별 상여내역별 소계와 합계를 검색하시오 SELECT 부서, 상여내역, SUM(상여금) AS 상여금 합계 FROM 상여금 GROUP BY ROLLUP(부서, 상여내역);4번 문제에 ROLLUP이라는 GROUP BY 함수가 등장합니다.
ROLL UP은 하위 레벨에서 상위 레벨로 나아갑니다.
문제에서는 부서별 상여내역별 소계와 합계라고 했으니

3레벨 : 부서별 상여내역별
2레벨 : 부서별
1레벨 : 전체
만약 상여내역별 부서별 소계와 합계라고 했다면3레벨 : 상여내역별 부서결
2레벨 : 상여내역별
1레벨 : 전체
입니다. 따라서 ROLLUP은 속성의 순서가 중요합니다.//5 상여금 테이블의 부서, 상여내역, //그리고 상여금에 대해 부서별 상여내역별 소계와 전체 합계를 검색하시오 //(단, 속성명은 상여금합계로 하고, CUBE 함수를 사용하시오) SELECT 부서, 상여내역, SUM(상여금) AS 상여금합계 FROM 상여금 GROUP BY CUBE(부서, 상여내역)5번 문제의 경우 ROLLUP가 차이가 있습니다.
CUBE는 레벨이 속성이 N개인 경우 2의 N승까지 올라갑니다.
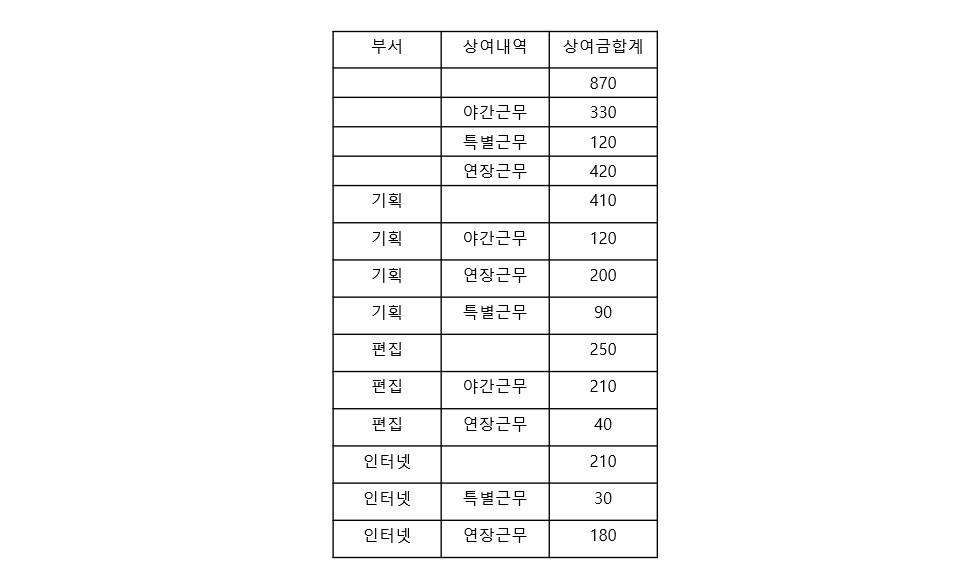
1레벨 : 전체
2레벨 : 상여내역별 상여금
3레벨 : 부서별
4레벨 : 부서별 상여내역별
-
HAVING절 : GROUP BY와 함께 사용되며 그룹에 대한 조건을 지정합니다.
집합연산자
집합연산자는 두개 이상의 테이블의 데이터를 하나로 통합합니다.
집합 연산자의 특징은 위 아래 에서 합치는 것이기 때문에
세로로 길어진다고 생각하면 편합니다.
집합연산자 = 세로
따라서 두 개의 SELECT문은 속성의 개수와 유형이 동일해야 합니다.
SELECT 속성명1, 속성명2,...
FROM 테이블명
UNION | UNION ALL | INTERSECT | EXCEPT
SELECT 속성명1, 속성명2,...
FROM 테이블명
ORDER BY 속성명 [DESC|ASC]UNION : 두 SELECT 문의 조회 결과를 모두 출력, 중복된 행은 한번만
UNION ALL : UNION과 같으나 중복된 행도 모두 그대로 출력
나머지는 우리가 알고 있는 집합의 개념과 같습니다.
INTERSECT는 공통
EXCEPT는 차집합입니다.
DML - JOIN
이 JOIN이라는 개념은 매우 중요합니다.
두개의 테이블에서 유용한 정보를 만들어낸다고 생각하면 됩니다.
집합연산자는 세로로 길어지는 것이라면
JOIN은 가로로 길어진다고 생각하면 됩니다.
JOIN = 가로
앞서
"두개의 테이블에서 유용한 정보를 만들어낸다고 생각하면 됩니다."
결국 이를 하나의 새로운 릴레이션을 반환한다라고 말합니다.
JOIN에는 크게 2가지의 JOIN이 있습니다.
INNER JOIN과 OUTTER JOIN입니다.
INNER JOIN
INNER JOIN은 일반적으로 EQUI JOIN과 NON-EQUI JOIN으로 구분됩니다.
-
EQUI JOIN
공통 속성을 기준으로 '=' 비교에 의해 같은 값을 가지는 행을 연결하는 결과를 생성하는 JOIN입니다.
연결고리가 되는 공통 속성 = JOIN 속성
이라고 부릅니다.표현할 수 있는 3가지 방법이 있습니다.
//1. WHERE 절을 이용한 SELECT 테이블명1.속성명, 테이블명2.속성명,.. FROM 테이블1, 테이블2,... WHERE 테이블1.속성명 = 테이블2.속성명; //2. NATURAL JOIN을 이용한 SELECT 테이블명1.속성명, 테이블2.속성명,... FROM 테이블1 NATURAL JOIN 테이블2; //3. JOIN ~UGING SELECT 테이블명1.속성명, 테이블2.속성명,... FROM 테이블1 JOIN 테이블2 UGING 속성명; -
NON-EQUI JOIN
'='이 아닌 나머지 비교연산자를 사용하는 JOIN 방법입니다.
공통속성을 이용하지 않습니다.
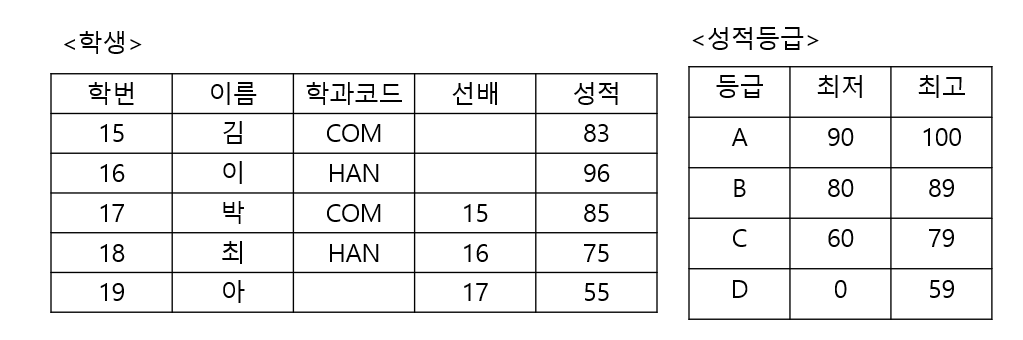
위와 같이 테이블이 주어졌을 때
// 학생테이블과 성적등급 테이블을 JOIN하여 //각 학생의 학번, 이름, 성적, 등급을 출력하는 SQL문을 작성하시오 SELECT 학번, 이름, 성적, 등급 FROM 학생, 성적등급 WHERE 학생.성적 BETWEEN 성적등급.최저 AND 성적등급.최고;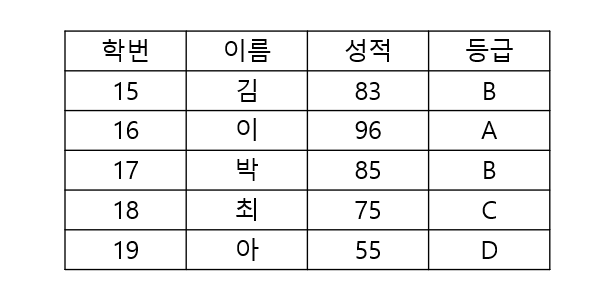
위와 같은 결과가 나옵니다.
공통 속성 없이 WHERE절에 있는 조건문을 통해서 새로은 릴레이션을 반환했습니다.
OUTER JOIN
OUTER JOIN은 JOIN조건에 만족하지 않은 튜플도 결과로 출력하기 위한 JOIN방법입니다.
- LEFT OUTER JOIN
이름에서 볼 수 있듯이 왼쪽에게 좀 더 권한을 준다고 생각하면 될거 같습니다. INNER JOIN을 한 후에 우측 항의 어떤 튜플과도 맞지 않는 좌측 항의 튜플에 NULL 값을 붙여서 INNER JOIN 결과를 반환합니다.
즉 왼쪽 테이블 모두 + 오른쪽 테이블은 관련 있는 것만
//1. LEFT OUTER JOIN
SELECT 테이블명1.속성명, 테이블명2.속성명,...
FROM 테이블명1 LEFT OUTER JOIN 테이블명2
ON 테이블1.속성명 = 테이블2. 속성명
//2. WHERE절을 이용한
SELECT 테이블명1. 속성명 , 테이블명2.속성명,...
FROM 테이블명1, 테이블명2
WHERE 테이블명1.속성명 = 테이블명2.속성명(+);- RIGHT OUTER JOIN
왼쪽 테이블은 관련 있는 것만 + 오른쪽 테이블 모두
//1. LEFT OUTER JOIN
SELECT 테이블명1.속성명, 테이블명2.속성명,...
FROM 테이블명1 RIGHT OUTER JOIN 테이블명2
ON 테이블1.속성명 = 테이블2. 속성명
//2. WHERE절을 이용한
SELECT 테이블명1. 속성명 , 테이블명2.속성명,...
FROM 테이블명1, 테이블명2
WHERE 테이블명1.속성명(+) = 테이블명2.속성명;- FULL OUTER JOIN
LEFT + RIGHT 모두
양측의 NULL값을 모두 표현
SELECT 테이블명1.속성명, 테이블명2.속성명,...
FROM 테이블명1 FULL OUTER JOIN 테이블명2
ON 테이블1.속성명 = 테이블2. 속성명SELF JOIN
같은 테이블에서 2개의 속성을 연결해서 EQUI JOIN하는 것
//1. JOIN
SELECT [별칭1.]속성명, [별칭1.]속성명,...
FROM 테이블명1 [AS] 별칭1 , 테이블명2 [AS] 별칭2
ON 별칭1.속성명 = 별칭2.속성명;
//2. WHERE절을 이용한
SELECT [별칭1].속성명, [별칭1].속성명,...
FROM 테이블명1 [AS] 별칭1 , 테이블명2 [AS] 별칭2
WHERE 별칭1.속성명 = 별칭2. 속성명;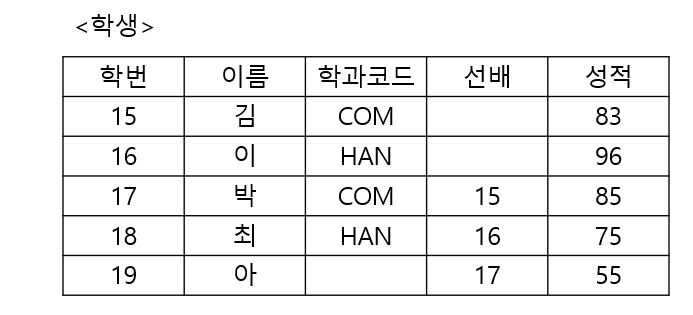
// 학생 테이블을 SELF JOIN하여 선배가 있는 학생과 선배의 이름을 표시하는
//SQL문을 작성하시오.
SELECT A.학번, A.이름, B.이름 AS 선배
FROM 학생 A JOIN 학생 B
ON A.선배 = B.학번