
눈으로 보는 것과 직접 풀어보는 것은 다르다.
복습한다고, 한번 풀었다고 눈으로만 보지 말고
공책이든 문제든 꼭 다시 한번 풀어보기!
- 소수점 첫번째 자리에서 버림
FLOOR(AVG(속성명)) AS 별칭
- CEIL 첫번째 자리에서 올림
-
DATE_FORMAT(속성명,'%Y-%m-%d') AS 별칭
이렇게 해야 시간이 안나옴 -
온라인 오프라인 판매데이터 통합하기 문제
SELECT DATE_FORMAT(SALES_DATE,'%Y-%m-%d') AS SALES_DATE, PRODUCT_ID, USER_ID,SALES_AMOUNT FROM ONLINE_SALE WHERE SALES_DATE LIKE '2022-03-%' UNION SELECT DATE_FORMAT(SALES_DATE,'%Y-%m-%d') AS SALES_DATE, PRODUCT_ID, NULL AS USER_ID,SALES_AMOUNT FROM OFFLINE_SALE WHERE SALES_DATE LIKE '2022-03-%' ORDER BY SALES_DATE, PRODUCT_ID, USER_ID;중요한 것은 OFFLINE_SALE 테이블에는 USER_ID가 없기 때문에 그냥 검색하기 오류가 뜬다 따라서 NULL로 채운다는 NULL AS USER_ID를 써주자
그리고 두번째는 ORDER BY를 마지막에 써주기 마지막 SELECT에 써주자
세번째는 2022년 3월을 특정하는 다른 방법이다.
SELECT DATE_FORMAT(SALES_DATE,'%Y-%m-%d') AS SALES_DATE, PRODUCT_ID, USER_ID,SALES_AMOUNT FROM ONLINE_SALE WHERE SALES_DATE BETWEEN DATE("2022-03-01") AND DATE("2022-03-31") -
JOIN 사용법

전체 틀은 파란색으로 먼저 잡고
초록색으로 그룹화 같은 ID끼리 모이게 해놓고
노란색으로 같은 그룹에 대한 집계를 진행한다.
그리고 마지막에 보라색으로 정렬한다.+) 두 테이블간 같은 이름의 속성이 있을 경우

테이블.같은속성명
으로 명시할것 저 위에 파란색 SELECT의 REST_ID는 잘못된 표현 -
소수점 세번째 자리에서 반올림 하시오.
ROUND(속성명,2) AS 별칭
-
이때 전화번호가 없는 경우, 'NONE'으로 출력

IFNULL(TLNO,"NONE") AS TLNO
-
FORM 테이블1 JOIN 테이블2 USING (괄호 안에 속성명)
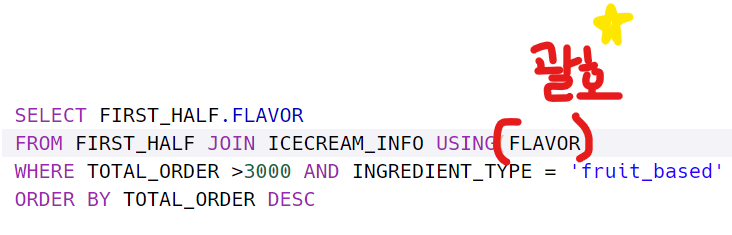
-
GROUP BY에 대한
USER_ID가 같은 부분만 캡처했다.

GROUP BY USER_ID를 했더니 USER_ID가 같은 부분이 합쳐진다.
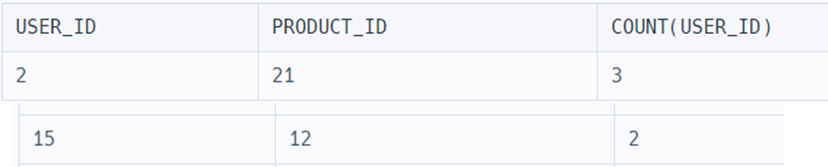
COUNT(USER_ID)를 해보면 각각 같은 USER_ID끼리 묶은 것들 즉 USER_ID를 기준으로 했을 때 각 그룹에 대한 개수가 나온다!
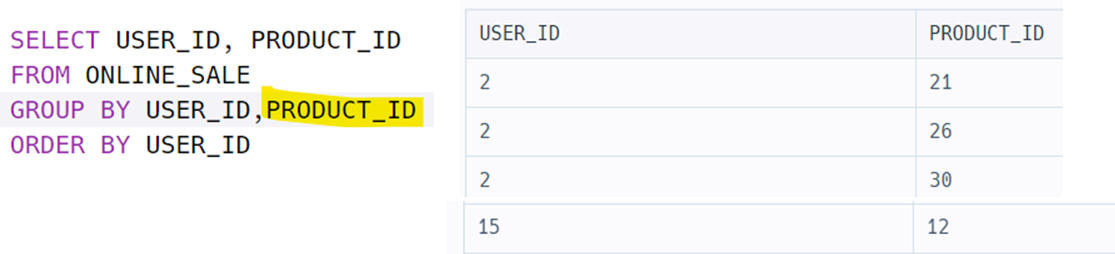
GROUP BY USER_ID, PRODUCT_ID를 했다 하나의 조건을 더 추가한다. 동일한 USER_ID의 그룹 안에 하나의 조건이 더 추가되어 그룹을 또 만든다. 따라서 USER_ID가 2였던 것들이 같은 그룹이었다가 PRODUCT_ID에 대한 조건이 추가되어 그룹이 쪼개진다.
-
어떤 조건이 아닌 경우 NOT LIKE 'Aged' 혹은 <>
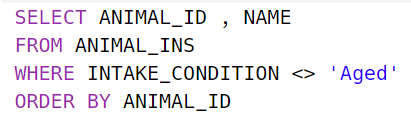
-
상위 1개의 데이터 가져오기

-
복수 정답

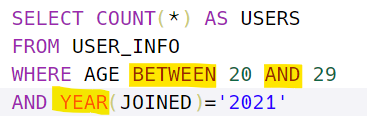
-
COUNT에서 NULL제거 방법


-
HAVING GROUP PY에 대한 집계함수의 결과에 조건을 부여하는 하는 역할
SELECT station_name
,boarding_time
,gubun
,MIN(passenger_number) min_value
,MAX(passenger_number) max_value
,SUM(passenger_number) sum_value
FROM subway_statistics
GROUP BY station_name, boarding_time, gubun
HAVING SUM(passenger_number) BETWEEN 15000 AND 16000
ORDER BY 6 DESC;-
그룹 안에서 집계함수 없이 조건을 뽑아내는 방법->
하위 SQL 사용

-
문제 제대로 읽기

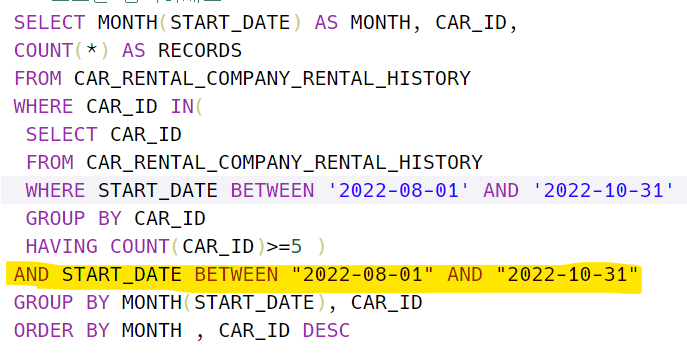
노란색 형광펜 줄을 넣지 않아서 틀렸다. -
'CASE WHEN THEN ELSE END'에 대해서-> 어떤 조건에 의해서 칼럼을 하나더 추가하는 기능
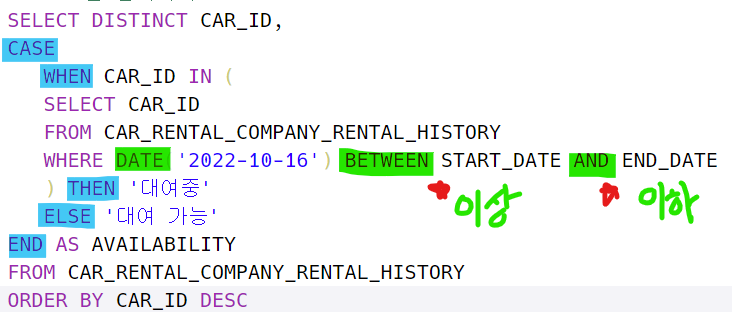
https://school.programmers.co.kr/learn/courses/30/lessons/157340#qna
위 문제 다시 풀어보기
-
REGEXP ('통풍시트|열선시트|가죽시트')
정규표현식을 활용하여 기본 연산자보다 복잡한 문자열 조건을 걸어 데이터를 검색

저 열선시트, 가죽시트, 통풍시트가 포함된 데이터를 찾고 싶을 때!

-
그룹함수 중 SUM에 대한 표현 익히기

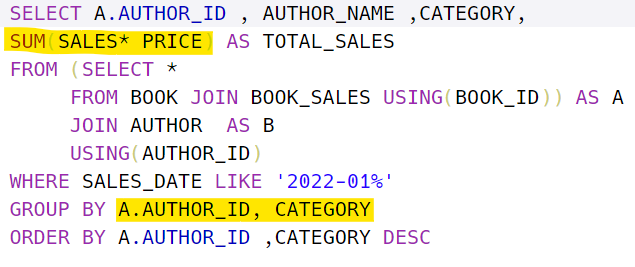
저렇게 표현된다.
처음에 SUM(SALES) *PRICE라는 다소 이상한 표현으로 접근하였지만 잘못됨 그룹 안에서 곱하는 것이 알맞음
또한 3개의 테이블을 조인해야 하는 문제인데
아래와 같이 표현해도 무방하다.

-
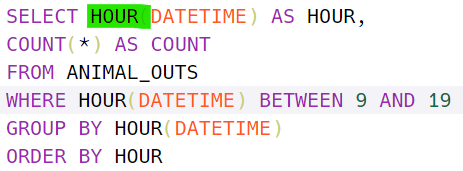
년,월,일 및 시,분,초 추출
DATE='2022-01-21 17:24:50'SELECT YEAR(DATE) -> 2022
SELECT MONTH(DATE) -> 1
SELECT DAY(DATE) ->21
SELECT TIME(DATE) -> 17
SELECT HOUR(DATE) -> 17
SELECT MINUTE(DATE) -> 24
SELECT SECOND(DATE) -> 50
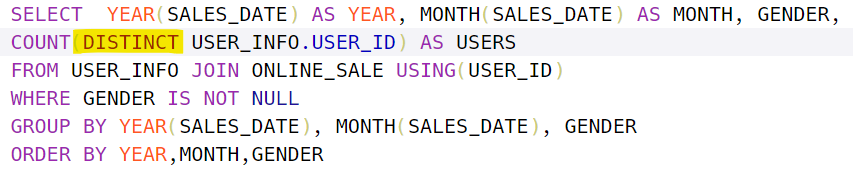
- DISTINCT 잊어버리지 말자
중복된 회원 수가 아니가 같은 년,월,성별에 구매한 회원들의 수다!!
- WITH문과 RECURSIVE
테이블 상에 존재하지 않지만 결과조회를 위해 임시테이블이 필요할 때 WITH문 통해서 이를 실현한다. 그 중에서 WITH문과 RECURSIVE를 같이 사용하여 마치 재귀함수처럼 임시테이블을 형성할 수 있는 방법이 존재한다.
WITH RECURSIVE TB AS(
SELECT 0 AS HOUR
UNION ALL
SELECT HOUR+1 FROM TB
WHERE HOUR<23
)
SELECT * FROM TB처음에 0으로 선언되고 union all을 통해서 그 값에 1을 더한 값이 아래에 추가된다.
저게 계속 반복되다가 23이 될 때 멈춘다.
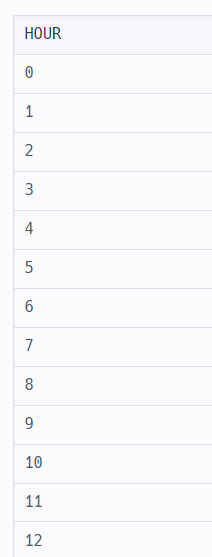
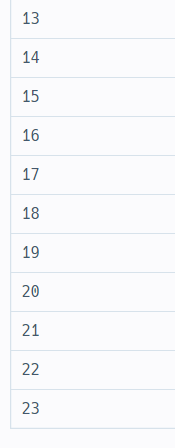
위와 같이 임시테이블이 생성된다.
관련된 문제를 풀어보았다.
1) 모든 데이터가 다 나와야 하는 쪽에 OUTER JOIN을 한다.
임시테이블의 데이터는 모두 나와야 한다. 0부터 23까지 그에 해당하는 다른 테이블의 데이터가 없다면 아래와 같이 NULL로 나온다.
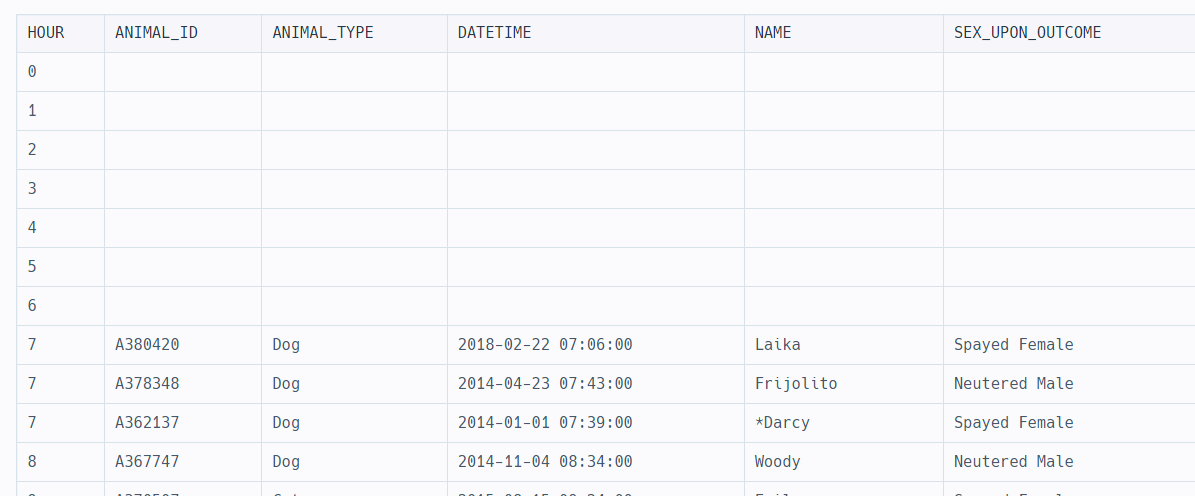
따라서
FROM TB LEFT JOIN ANIMAL_OUTS ON TB.HOUR = HOUR(ANIMAL_OUTS.DATETIME)이 된다.
2) 이제 그룹화를 진행해야 한다.
GROUP BY TB.HOUR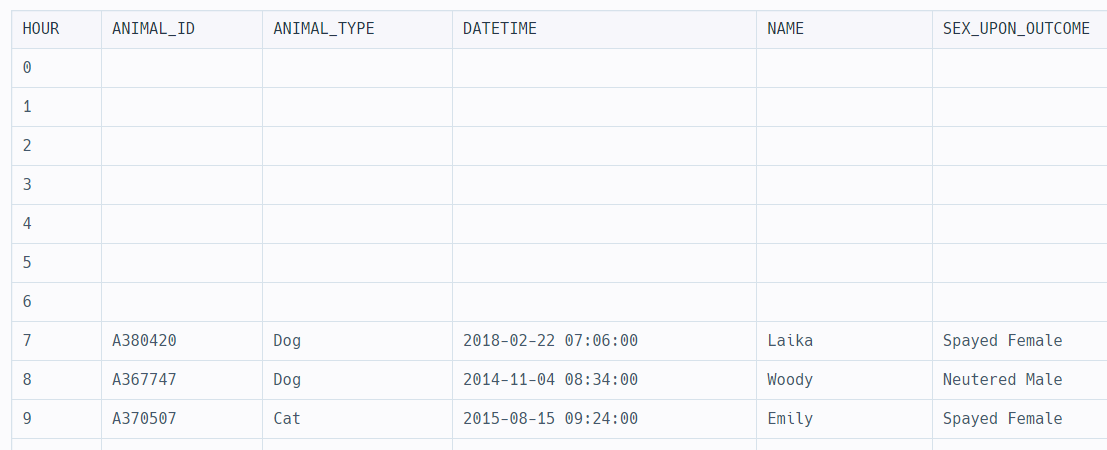
TB.HOUR이 같은 그룹끼리 묶였고
이제 각 그룹에 몇개의 데이터가 있는지 세어보아야 한다.
3) 각 그룹에 대해서 셀 때 간과할 수 있는 부분이 있는데 저기 NULL로 들어가 있는 부분도 데이터이다. 다라서 HOUR이 0인 그룹에 들어있는 데이터의 개수는 1로 나온다.
SELECT TB.HOUR, ANIMAL_ID, ANIMAL_TYPE,
COUNT(*) AS COUNT
FROM TB LEFT JOIN ANIMAL_OUTS ON TB.HOUR = HOUR(ANIMAL_OUTS.DATETIME)
GROUP BY TB.HOUR
그러나 우리가 원하는 것은 1이 아닌 0이 나오는 것 따라서 0이 나올 수 있도록 저 합쳐진 데이블에서 각 그룹에서 무엇을 기준으로 더할것인가 결정해야 한다.
TB테이블이 기준이 아닌 ANIMAL_OUTS에 있는 속성을 기준으로 더하기로 한다.
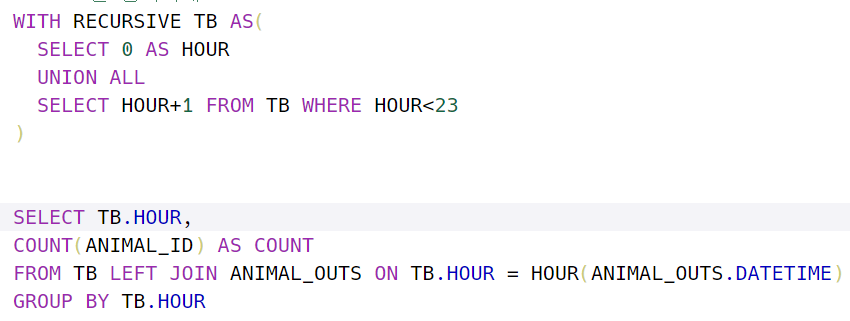
따라서 위가 최종 답이 된다.
- 필드에 들어있는 데이터를 교체하는 방법
https://school.programmers.co.kr/learn/courses/30/lessons/131530#qna
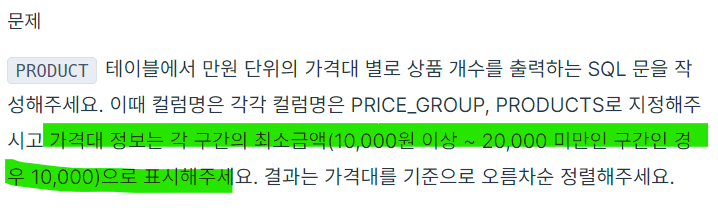
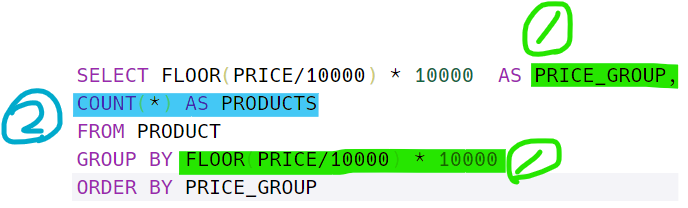
문제를 보면 가격대를 만원을 기준으로 자르라고 했다.
따라서 기존의 데이터를 교체해야 한다. 교체하는 방법으로 그룹 화를 진행할 때 그룹화를 하면서 데이터를 교체했다. PRICE를 기 준으로 하되, PRICE의 데이터를 FLOOR(PRICE/10000)*10000으로 하겠다는 것이다.
여기서 FLOOR을 통해서 완전한 정수형으로 만들고 거기에 10000을 곱하는 것이다.
- DATEDIFF에 대한 사용법 및 WITH문을 통해서 임시테이블을 만드는 활용편
https://school.programmers.co.kr/learn/courses/30/lessons/151141
DATEDIFF를 통해서 날짜 사이의 일수를 계산한다.
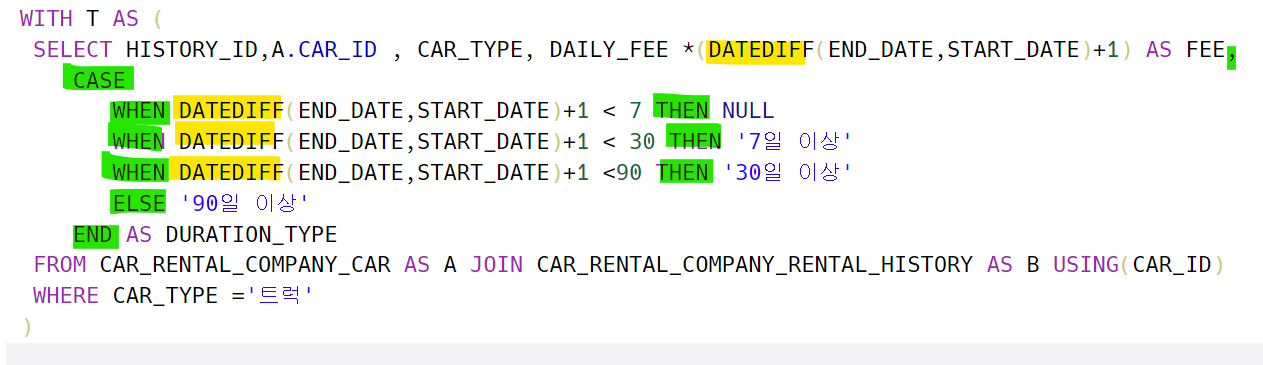
1) 먼저 대여 시작일- 끝나는 날에 대한 차이를 통해서 어떤 할인 정책에 속하는지 TABLE이 필요하다.
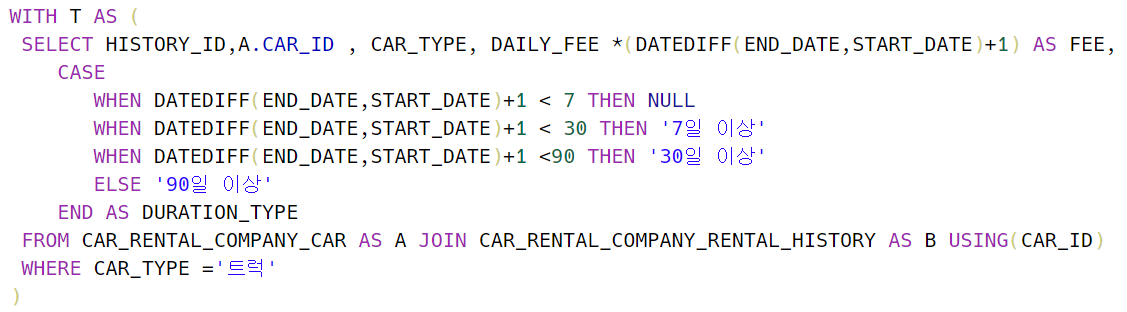
아래와 같이 NULL값이 존재하기 때문에 OUTER JOIN을 할 때 이 임시테이블의 데이터가 모두 나올 수 있도록 해야 한다.
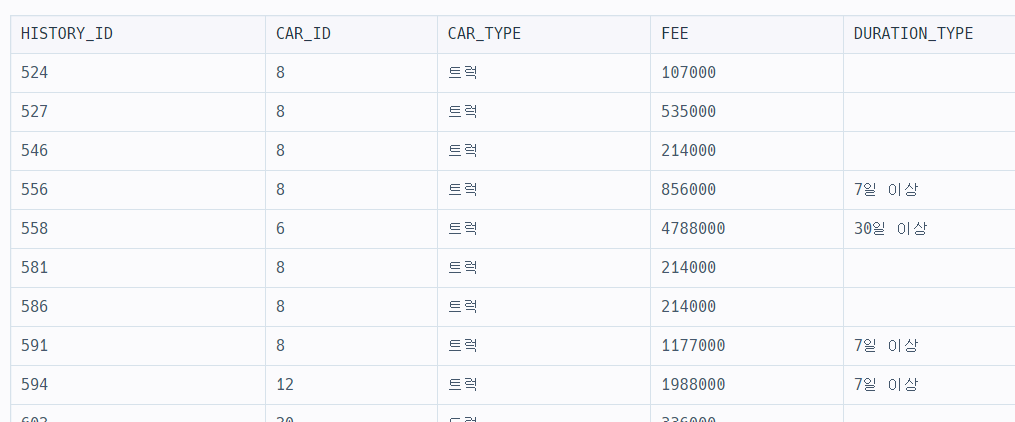
따라서 아래와 T를 중심으로 LEFT JOIN으로 나타낸다.

-
17번에 내용을 추가한다.
아래 내용이 17번 내용이다.
아래 연산이 정답이었던 이유는 앞 뒤 어떤 말이 붙어도 저 말이 들어가면 정답이었기 때문이다.
만약에 데이터에 '네비게이션, 통풍시트' 이렇게 같이 있어도 검색이 된다. 문제에서도 저 단어가 포함된 OPTION을 모두 검색하라고 했다.
REGEXP ('통풍시트|열선시트|가죽시트')정규표현식을 활용하여 기본 연산자보다 복잡한 문자열 조건을 걸어 데이터를 검색
저 열선시트, 가죽시트, 통풍시트가 포함된 데이터를 찾고 싶을 때!
하지만 아래 문제는 좀 다르다.

필드 값에 Lucy 또는 Ella 등의 이름만 들어가야한다.
이름이 ImaLucy여서도 안된다.

정규식을 저렇게 표현하면 imLucy나 evElla도 검색해버린다.
따라서 아래와 같이 고친다.

- LIMIT 속성 및 ALIAS 지정 오류
꼭 FROM절에 하위 질의를 넣을 경우 AS를 넣어 ALIAS를 지정하자.

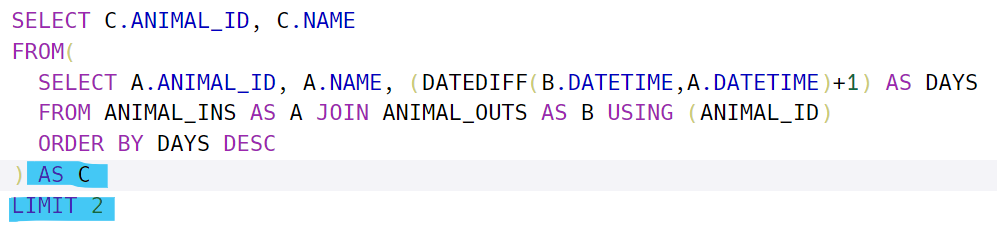
- 앞에 몇 글자만 가져올 때
오른쪽부터는 RIGHT
MID(문자, 시작 위치, 가져올 갯수);
-- 또는 SUBSTR(문자, 시작 위치, 가져올 갯수);
-- 또는 SUBSTRING(문자, 시작 위치, 가져올 갯수);
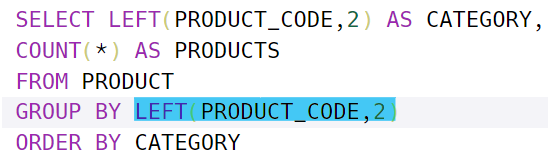
- WHERE절에서 하위 질의를 할 때 서로 대응되는 칼럼의 수가 같아야 한다.
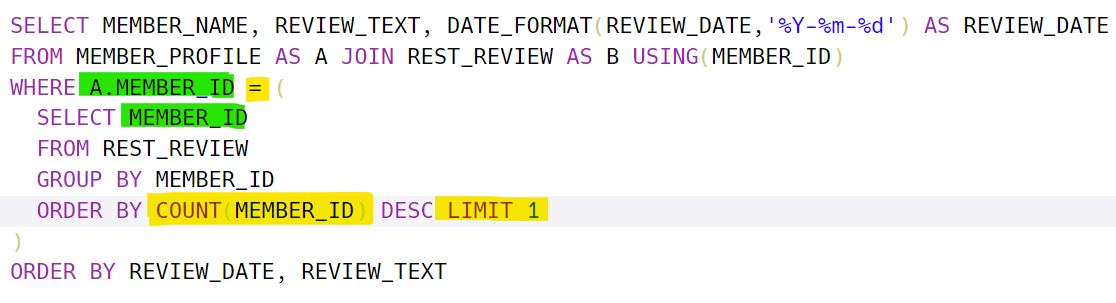
또한 그룹화가 된 테이블에 대해서 무언가 셀 때 무조건 속성으로 만들어서 셀 필요는 없다. ORDER BY에 규칙을 넣을 수도 있다는 점 명심하자!
또한 하위질의에 LIMIT 1을 사용하는 경우 WHERE 속성명 IN(하위질의)가 아니라 WHERE 속성명 = (하위질의)이 와야한다!
+) 추가적으로 그룹화가 된 테이블에서 적용되는 또 하나의 예시

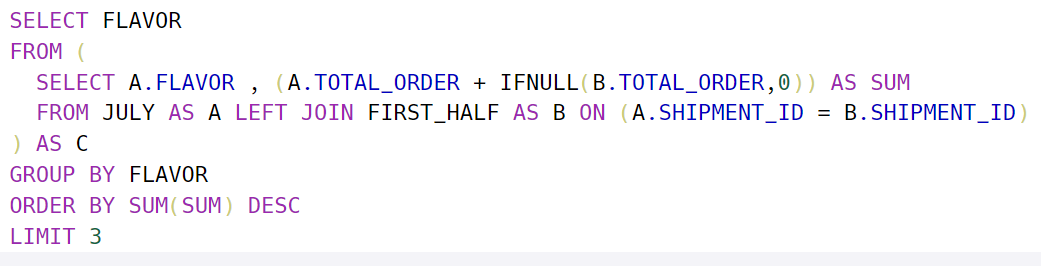
-
문제는 아래와 같다.
https://school.programmers.co.kr/learn/courses/30/lessons/157339
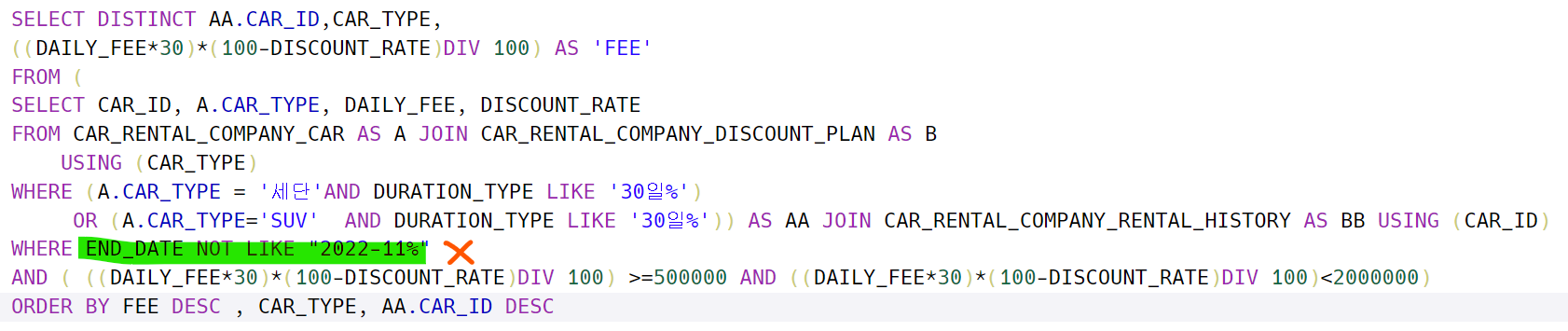
위 방식으로 하면 10월에 시작해서 12월까지 이용하는 자동차도 가지고 와버린다. 따라서 아래와 같이 가장 최신의 END_DATE 중에서 11월 이전에 끝나는 것으로 검색해야 한다. HAVING이라는 것은 그룹화의 조건절이다. WHERE은 그룹화 이전에 데이터에 대한 조건절이기 때문에 그룹화가 진행된 이후부터는 HAVING절을 통해서 조건을 넣는다.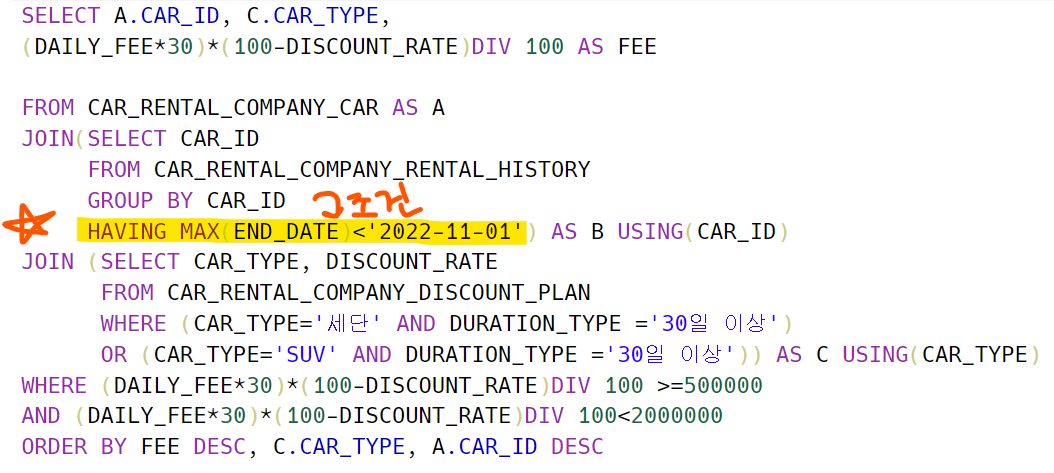
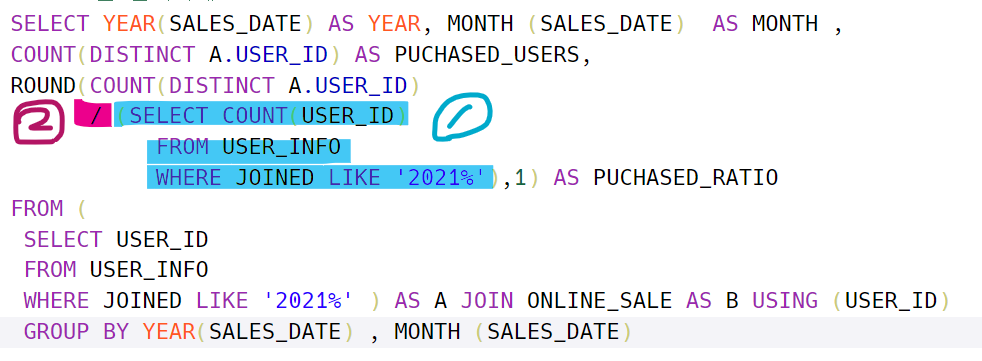
두가지 살펴볼 부분이 있다.
저렇게 SELECT내에도 하위질의를 넣을 수 있다. 저 1번은 2021년에 가입한 총 유저의 수이다. 그걸 그대로 정수로 가지고 오는것이다.
나머지 하나는 DIV와 '/'의 차이이다.
이 두개의 차이를 몰라서 아래 문제에 계속 오답이 나왔다.
DIV는 FLOOR과 나누기의 두가지 역할을 한다. 나누되 결과값을 FLOOR로 가지고 온다. 즉 정수형으로 만든다.
5 DIV 2 결과는 2이다.
그러나 '/'는 소수점까지 가지고 온다!!
이 두개의 차이를 혼동하지 말자.
