
카프카가 고성능, 고가용성 메시징 애플리케이션으로 발전한 데는 토픽과 파티션이라는 데이터 모델의 역할이 있기 때문입니다.
토픽은 메시지를 받을 수 있도록 논리적으로 묶은 개념이고, 파티션은 토픽을 구성하는 데이터 저장소로서 수평 확장이 가능한 단위입니다.
1. 토픽 (Topic) 💻
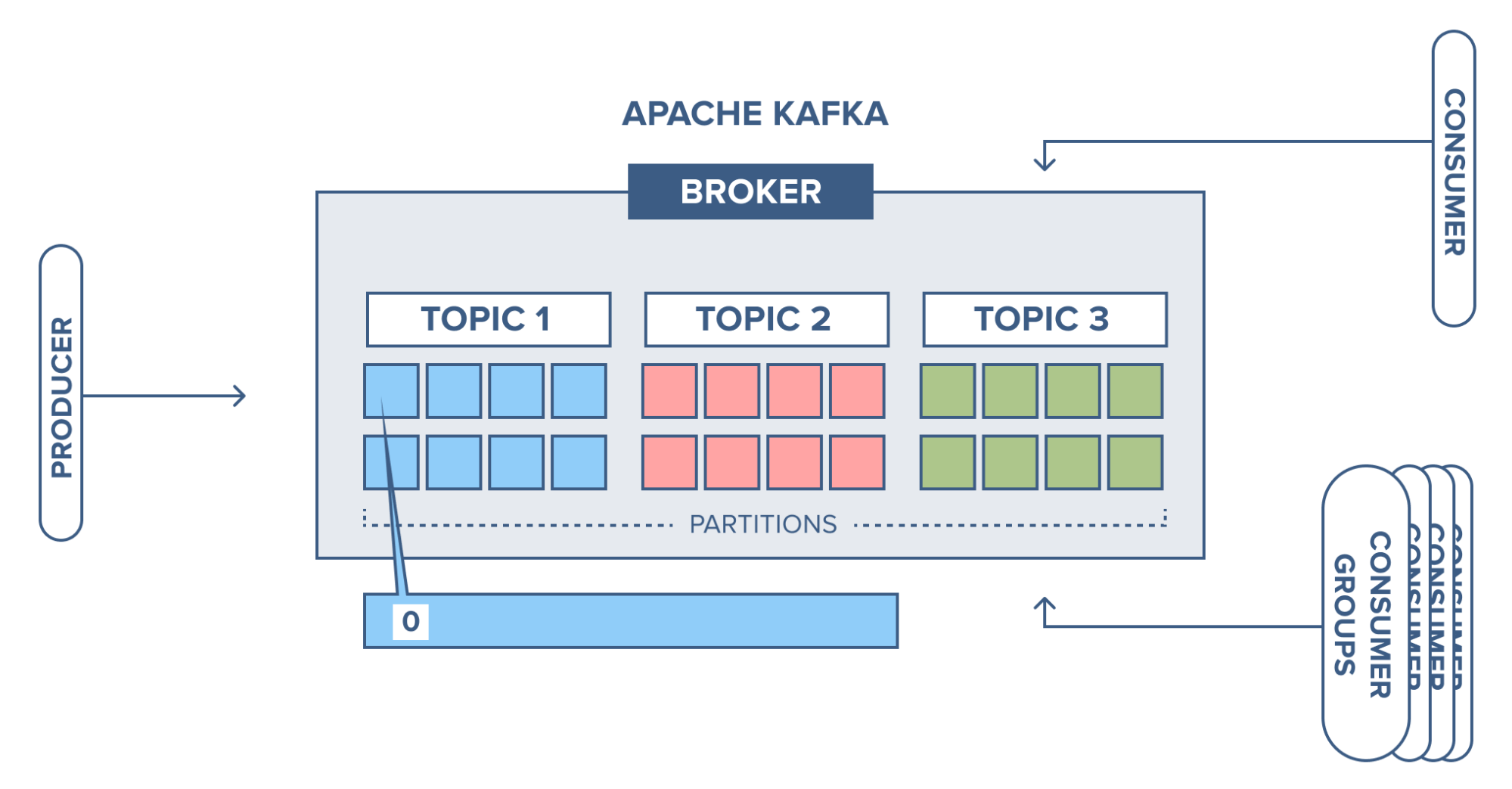
토픽은 메시지를 받을 수 있도록 논리적으로 묶은 개념이며 예를 들면 이메일 주소라고 생각하면 됩니다. 카프카의 토픽을 이해하기 위해서 예를 들어 보겠습니다. 예를 들어 뉴스 토픽, 동영상 토픽, 이미지 토픽이 있다면, 뉴스와 관련된 프로듀서들은 카프카의 뉴스 토픽으로만 메시지를 보내고, 동영상과 관련된 프로듀서들은 카프카의 동영상 토픽으로만 메시지를 보냅니다. 반대로 뉴스의 내용만 가져오고 싶다면, 뉴스 토픽에 컨슈머를 연결해 뉴스 토픽의 메시지만 가져올 수 있습니다.
카프카에서는 데이터를 구분하기 위한 단위로 토픽을 사용하는데, 이름은 249자 미만으로 영문, 숫자, '.'_ ', '-'를 조합하여 자유롭게 만들 수 있습니다.
2. 파티션 (Partition) 💻
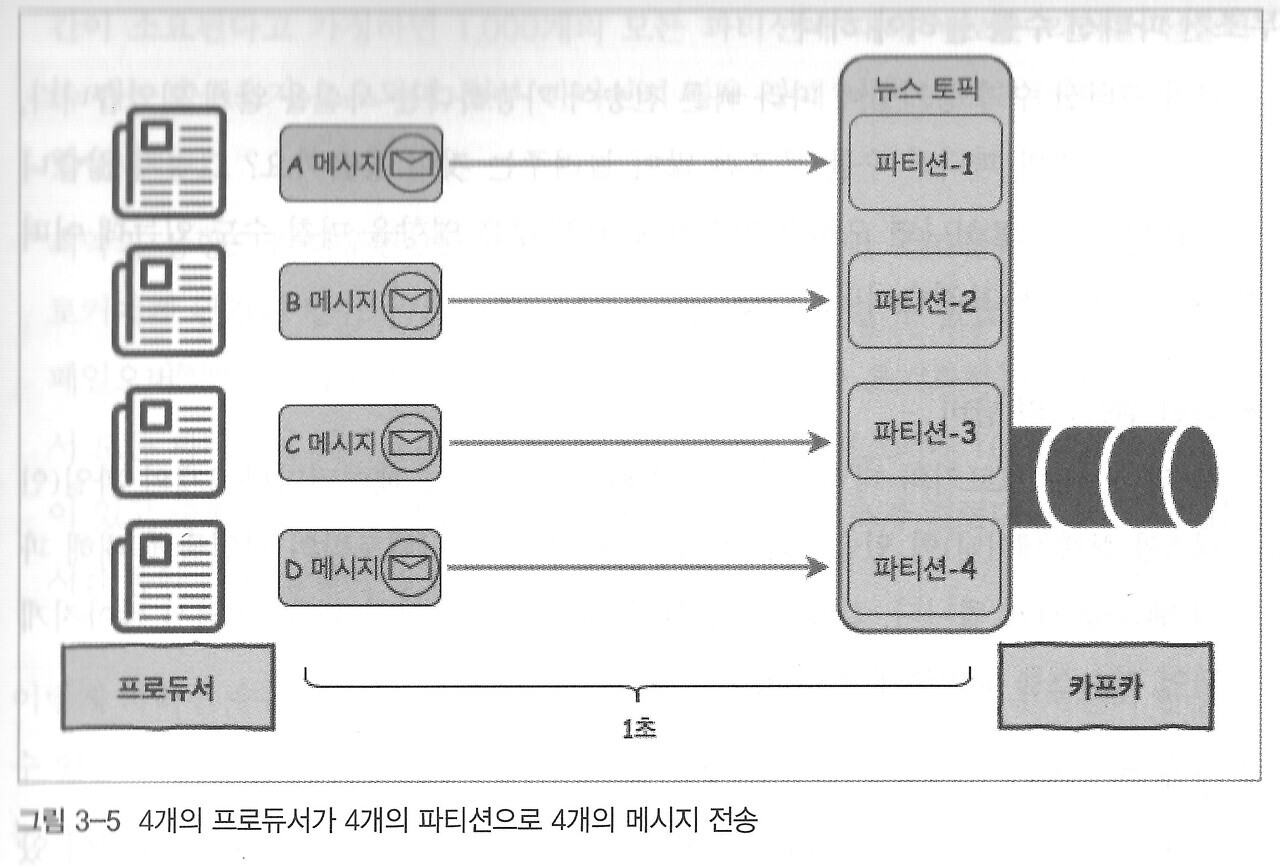
파티션은 토픽을 분할 한것입니다. 왜 하나의 토픽을 파티셔닝 하는 것일까요?
예를 들어보겠습니다. 하나의 프로듀서가 카프카의 하나토픽에게 4개의 메시지를 전송하게 된다고 가정해봅시다. 메시지 하나를 보내는데 걸리는 시간은 1초일 경우 메시징 큐 시스템의 한 가지 제약 조건으로 인해서 A -> B -> C -> D 순으로 보내야 됩니다. 고로 총 4초의 딜레이가 발생되게 되는 것이죠. 하지만 하나의 토픽을 4개로 파티셔닝을 하고 프로듀서도 4개로 늘렸을 때 아래 사진과 같이 병렬적으로 메시지를 보낼 수 있게 됩니다. 그러면 총 1초의 딜레이만 발생되어 빠른 전송이 됩니다.
무조건 파티션 수를 늘리면 빠른 전송이 되는것이 아닐까? 🧐

하지만 여기서 의문점이 생깁니다.
"무조건 파티션 수를 늘리면 빠른 전송이 되는것이 아닐까"라는 점입니다.
정답을 말하자면 그렇지 않습니다.
(1). 파일 핸들러의 낭비
각 파티션은 브로커의 디렉토리와 매핑되고, 저장되는 데이터마다 2개의 파일(인덱스, 실제 데이터)이 있습니다. 카프카에서는 모든 디렉토리의 파일들에 대해 파일 핸들을 열게 됩니다. 결론적으로 파티션이 많을수록 파일 핸들 수 가 많이 지게 되어 리소스가 낭비하게 됩니다.
(2). 장애 복구 시간 증가
카프카는 높은 가용성을 위해 리플리케이션을 지원합니다. 브로커에는 토픽이 있거, 토픽은 여러 개의 파티션으로 나뉘어 있으므로, 브로커에는 여러 개의 파티션이 존재합니다. 또한 각 파티션마다 리플리케이션이 동작하게 되며, 하나는 파티션의 리더이고 나머지는 파티션의 팔로워가 됩니다.
만약 브로커가 다운되면 해당 브로커에 리더가 있는 파티션은 일시적으로 사용할 수 없게 되므로, 카프카는 리더를 팔로워 중 하나로 이동시켜 클라이언트 요청을 처리할 수 있게 합니다. 이와 같은 장애 처리는 컨트롤러로 지정된 브로커가 수행합니다. 컨트롤러는 카프카 클러스터 내 하나만 존재하고, 만약 컨트롤러 역할을 수행하는 브로커가 다운되면 살아 있는 브로커 중 하나가 자동으로 컨트롤러 역할을 대신 수행합니다.
만약 브로커에 총 1000개의 파티션이 있고 2개의 리플리케이션이 있는 브로커가 갑자기 다운되면, 일시적으로 이 브로커에 있는 1000개의 파티션은 사용할 수 없게 됩니다. 파티션의 리더를 다른 브로커가 있는 곳으로 이동시켜야 사용할 수 있습니다. 만약 컨트롤러가 각 파티션 별로 새로운 리더를 산출하는데 1초의 시간이 소요된다고 가정하면, 모든 파티션에 대한 새로운 리더를 선출하는데 총 5000초가 소요되며, 일부 파티션의 경우 장애시간은 5000초 이상 이어질 수도 있습니다.
최악의 상황으로 다운된 브로커가 컨트롤러인 경우라면, 컨트롤러가 살아있는 브로커에게 완전히 넘어가기 전까지 새로운 리더를 선출할 수 없습니다. 컨트롤러의 페일오버(failover)는 자동으로 동작하지만 새 컨트롤러가 초기화하는 동안 주키퍼에서 모든 파티션의 데이터를 읽어야 합니다.
토픽의 적절한 파티션의 수는? 🧐

그렇다면 토픽의 적절한 파티션의 수는 어떻게 정해야 할까요?
먼저 토픽의 파티션 수를 정할 때 원하는 목표 처리량의 기준을 잡아야 합니다. 프로듀서 입장에서 4개의 프로듀소를 통해 각각 초당 10개의 메시지를 카프카의 토픽으로 보낸다고 하면, 카프카의 토픽에서 초당 40개의 메시지를 받아줘야 합니다. 만약 해당 토픽에서 파티션을 1로 했을 때 초당 10개의 메시지만 받아준다면 파티션을 4로 늘려 목표 처리량을 처리할 수 있도록 변경합니다.
8개의 컨슈머가 있으면 각 초당 5개의 메시지를 카프카의 토픽에서 가져올 수 있다고 한다면, 해당 토픽의 파티션 수는 컨슈머 수와 동일하게 8개로 맞추어 각 컨슈머마다 각각의 파티션에 접근 할 수 있게 해야 합니다.
이런 식으로 예상 목표치를 가지고 파티션을 할당하는 것이 이상적이긴 하지만 어렵습니다. 이를 하기 위해서는 파티션의 개수를 위에서 아래로 낮춰가면서 적절한 파티션 수를 찾는 방식보다는 아래에서 위로 올라가는 방식을 취해야 합니다. 카프카의 증가는 필요한 경우 아무 때나 변경이 가능하지만, 반대로 파티션의 수를 줄이는 방법은 제공하지 않습니다. 파티션의 수를 줄이는 방법은 삭제하고 다시 만드는 방법밖에 없습니다. 그렇기 때문에 카프카의 토픽에 적절한 파티션 수를 찾기 위해서는 우리는 예상 목표치를 정하고 파티션의 수를 아래에서부터 병목현상이 발생될 때 조금씩 파티션 수와 프로듀서 또는 컨슈머를 늘려가는 방법으로 적정 파티션 수를 할당합니다.
오프셋과 메시지 순서 💻

각 파티션마다 메시지가 저장되는 위치를 오프셋(offset)이라고 부르고, 오프셋은 파티션 내에서 유일하고 순차적으로 증가하는 숫자 형태로 되어 있습니다.
만약 컨슈머가 파티션 0에서 데이터를 가져간다고 가정하면, 오프셋 0 -> 1 -> 2 -> 3 순서대로만 가져갈 수 있습니다. 절대로 오프셋 순서가 바뀐 상태로는 가져갈 수 없습니다.
마무리
이번 포스팅을 통해서 카프카의 데이터 모델을 위한 토픽과 파티션, 오프셋과 메시지 순서을 알아보았습니다. 토픽은 메시지를 받을 수 있도록 논리적으로 묶으며, 파티션을 통해서 병렬 확장하도록 한다는 것을 알았습니다.
REFERENCE
해당 글의 모든 레퍼런스는 "카프카, 데이터 플랫폼의 최강자" (고승범, 공용준 지음) 을 알립니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
