Spark를 사용하다보면 메모리 관련해서 문제가 발생되는 경우가 많습니다. 최근 연구하는데 있어서 Apach Spark의 Structured Streaming(https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html)을 사용할 일이 있어서 사용하는데 메모리 관련해서 문제가 자주 발생되어 이와 관련된 공부한 내용을 적습니다.
본격적인 스파크의 메모리 관리를 알아보기 위해서는 Spark가 왜 메모리 관리 관련해서 알아야되는지 알아야합니다.
왜 스파크의 메모리 관리에 대해서 알아야 하는가? 🤯
스파크는 Task가 수행하는데 있어서 모든 계산이 메모리 내에서 발생하는 메모리 내 처리 엔진입니다 (정확히는 In-Memory technology라고 하기에는 데이터 처리하는데 persist하는게 아닌 cacheg하기 때문에 맞지 않을 수 있습니다). 따라서 Spark Application을 개발고 성능 조정하는데 있어서 메모리 관리는 도움이 될 수 있습니다. 커밋할 때 메모리 할당이 너무 크면 리소스를 많이 차지하고, 메모리 할당량이 너무 적으면 메모리 오버플로 및 전체 GC 문제가 쉽게 발생합니다. 따라서 효율적인 메모리 사용은 좋은 성능을 위해서 중요하지만 그 반대로도 비효율적인 메모리 사용은 성능을 저하시킬수 있다는 것을 알아야합니다.
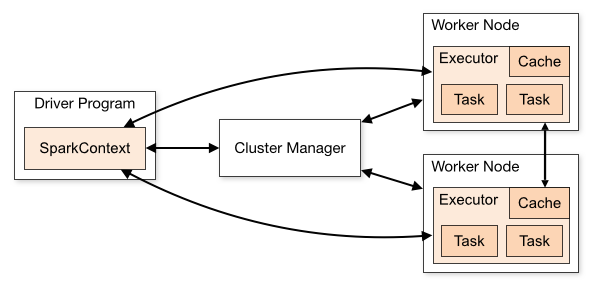
Spark Application에는 Driver와 Executor라는 두가 JVM 프로세스가 포함되어 있습니다.
- Driver : Driver는 SparkSession/SparkContext를 생성하고, Job을 submit하고, Job을 Task로 변환하고, Worker 간의 Task 실행을 조정하는 주요 프로세스입니다.
- Executor : Executor는 주로 특정 계산 작업을 수행하고 결과를 Driver에게 반환하는 일을 담당합니다.
Driver의 메모리 관리는 비교적 간단하며, Spark는 구체적인 계획을 세우지 않습니다. 이번 포스팅에서는 Executor 메모리 관리에 대해 알아봅니다.
👉 Executor의 메모리를 알아보자
Executor는 Worker 노드에서 실행되는 JVM 프로세스 역할을 합니다. 따라서 JVM 메모리 관리를 이해하는 것이 중요합니다.
JVM 메모리 관리는 두가지로 나눌 수 있습니다.
- On-Heap Memory Managment (In-Memory) : Object는 JVM heap에 할당되고 GC에 의해 바인딩됩니다.
- Off-Heap Memory Managment (External-Memory) : Object는 직렬화에 의해 JVM 외부의 메모리에 할당되고 Application에 의해 관리되며 GC에 바인딩되지 않습니다.
일반적으로 Object의 읽기 및 쓰기 속도는 ( On-Heap > Off-Heap > DISK) 순입니다.
🙌 메모리 관리의 종류
메모리 관리는 두 가지로 나뉩니다.
- Static Memory Manager (Static Memory Management) 정적
- Unified Memory Manager (Unified memory management) 통합
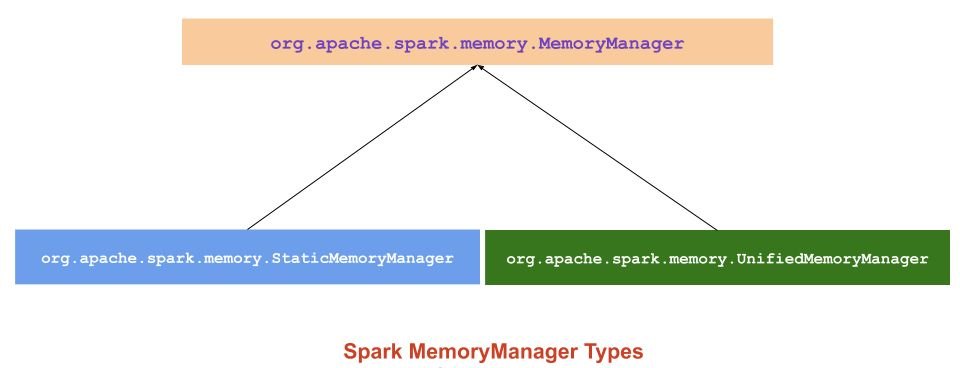
Spark 1.6.0부터 통합 메모리 관리자가 Spark의 기본 메모리 관리자로 설정되었습니다.
정적 메모리 관리자는 유연성 부족으로 인해 더 이상 사용되지 않습니다.
두 메모리 관리자 모두에서 Java 힙의 일부는 Spark 애플리케이션 처리를 위해 위치하며 나머지 메모리는 Java 클래스 참조 및 메타데이터 사용을 위해 예약됩니다.
참고: JVM당 하나의 MemoryManager만 있습니다.
메모리에 대한 정보를 저장하기 위해 두 메모리 관리자는 두 개의 메모리 풀을 사용합니다.
- ExecutionMemoryPool
- StorageMemoryPool
🧎 Static Memory Manager (Static Memory Management) 정적 메모리 관리
Spark 1.0부터SMM(Static Memory Manager)은 메모리 관리를 위한 전통적인 모델이자 간단한 체계입니다.
메모리를 정적으로 두 개의 고정 파티션으로 나눕니다.
Storage Memory, Execution Memory 및 기타 Memory의 크기는 응용 프로그램 처리 중에 고정되지만 응용 프로그램이 시작되기 전에 사용자가 구성할 수 있습니다.
참고: 정적 메모리 할당 방법은 Spark 3.0에서 제거되었습니다.
장점:
- Static Memory Manager 메커니즘은 구현하기 쉽습니다.
단점 :
- 저장 메모리에 여유 공간이 있어도 사용할 수 없으며 실행기 메모리가 가득 차서 디스크 유출이 있습니다. (반대의 경우도 마찬가지).
Spark 1.6 이상에서는 spark.memory.useLegacyMode=true 매개변수 를 통해 정적 메모리 관리를 활성화할 수 있습니다 .
| 매개변수 | 설명 |
|---|---|
| spark.memory.useLegacyMode(기본 fasle) | 힙 공간을 고정 크기 영역으로 나누는 옵션 |
| spark.shuffle.memoryFraction(기본값 0.2) | 셔플 중 집계 및 공동 그룹에 사용되는 힙의 비율입니다. spark.memory.useLegacyMode=true인 경우에만 작동 합니다. |
| spark.storage.memoryFraction(기본값 0.6) | Spark의 메모리 캐시에 사용되는 힙의 비율입니다. spark.memory.useLegacyMode=true인 경우에만 작동 합니다. |
| spark.storage.unrollFraction(기본값 0.2) | 메모리에서 블록을 펼치는 데 사용되는 spark.storage.memoryFraction 의 비율입니다 . 이것은 새 블록을 완전히 풀기에 충분한 여유 저장 공간이 없을 때 기존 블록을 삭제하여 동적으로 할당됩니다. spark.memory.useLegacyMode=true 인 경우에만 작동 합니다 . |
참고 :
정적 메모리 관리는 저장을 위해 오프 힙 메모리 사용을 지원하지 않으므로 모두 실행 공간에 할당됩니다.🏃 Unified Memory Manager (Unified memory management) 통합 메모리 관리
Spark 1.6 이상부터1.6.0 스파크 이상부터, 새로운 메모리 관리자는 스파크를 제공하는 정적 메모리 관리자를 대체 채용 D ynamic 메모리 할당.
Storage 및 Execution이 공유하는 통합 메모리 컨테이너로 메모리 영역을 할당합니다.
Execution 메모리를 사용하지 않는 경우 Storage 메모리는 사용 가능한 모든 메모리를 획득할 수 있으며 그 반대의 경우도 마찬가지입니다.
Storage 또는 Execution 메모리에 더 많은 공간이 필요한 경우, acquireMemory()라는 함수가 메모리 풀 중 하나를 확장하고 다른 메모리 풀을 축소합니다.
빌린 스토리지 메모리는 언제든지 제거할 수 있습니다. 그러나 빌린 실행 메모리는 구현의 복잡성으로 인해 첫 번째 디자인에서 제거되지 않습니다.
장점:
- Storage 메모리와 Execution 메모리 사이의 경계는 고정되어 있지 않으며 메모리 부족의 경우 경계가 이동됩니다. 즉, 한 영역이 다른 영역에서 공간을 차용하여 확장됩니다.
- 응용 프로그램에 캐시 및 전파가 없는 경우 불필요한 디스크 오버플로를 방지하기 위해 실행 시 모든 메모리를 사용합니다.
- 응용 프로그램에 캐시가 있는 경우 데이터 블록이 영향을 받지 않도록 최소 Storage 메모리를 예약합니다.
- 이 접근 방식은 메모리가 내부적으로 분할되는 방식에 대한 사용자 전문 지식 없이도 다양한 워크로드에 대해 즉시 사용 가능한 합리적인 성능을 제공합니다.
JVM에는 두 가지 유형의 메모리가 있습니다.
- 온힙 메모리
- 오프 힙 메모리
위의 두 가지 JVM 메모리 유형 외에도 Spark에서 액세스하는 메모리 세그먼트(예: 외부 프로세스 메모리)가 하나 더 있습니다. 이러한 종류의 메모리는 주로 PySpark 및 SparkR 응용 프로그램에 사용됩니다. 이것은 JVM 외부에 있는 Python/R 프로세스에서 사용하는 메모리입니다.
온힙 메모리 (On-Heap Memory)💎
기본적으로 Spark는 온힙 메모리만 사용합니다. 온힙 메모리의 크기 는 Spark 애플리케이션이 시작될 때 --executor -memory 또는 spark.executor.memory 매개변수에 의해 구성됩니다.
Executor 내에서 실행되는 동시 작업은 JVM의 힙 메모리를 공유합니다.
실행기 메모리 할당을 제어하는 두 가지 주요 구성:
| 매개변수 | 설명 |
|---|---|
| spark.memory.fraction (기본값 0.6) | 실행 및 저장에 사용되는 힙 공간의 비율입니다. 이 값이 낮을수록 유출 및 캐시된 데이터 제거가 더 자주 발생합니다. 이 구성의 목적은 내부 메타데이터, 사용자 데이터 구조 및 희소하고 비정상적으로 큰 레코드의 경우 부정확한 크기 추정을 위한 메모리를 따로 확보하는 것입니다. |
| spark.memory.storageFraction (기본값 0.5) | spark.memory.fraction 에 의해 따로 설정된 공간 내 저장 영역의 크기입니다 . 캐시된 데이터는 총 스토리지가 이 영역을 초과하는 경우에만 제거될 수 있습니다. |
참고: Spark 1.6에서 spark.memory.fraction 값은 0.75이고 spark.memory.storageFraction 값은 0.5입니다.
Apache Spark는 세 가지 메모리 영역을 지원합니다.
- Reserved Memory
- User Memory
- Spark Memory
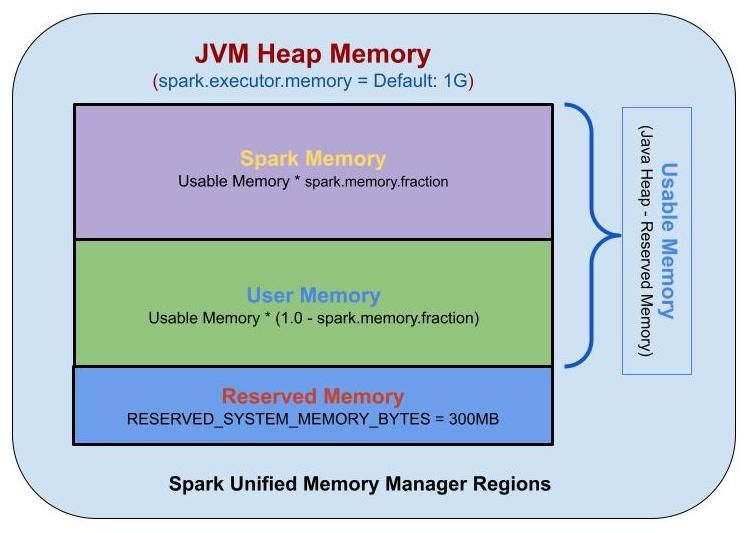
Spark Memory 1. Reserved Memory
예약된 메모리는 시스템용으로 예약된 메모리이며 Spark의 내부 개체를 저장하는 데 사용됩니다.
Spark v1.6.0+부터 값은 300MB입니다. 즉, 300MB의 RAM이 Spark 메모리 영역 크기 계산에 참여하지 않습니다( SPARK-12081 ).
예약된 메모리의 크기는 하드코딩되어 있으며 Spark 재컴파일 또는 spark.testing.reservedMemory 설정 없이는 크기를 변경할 수 없습니다 . 이는 프로덕션 환경에서 사용되지 않는 테스트 매개변수이므로 권장하지 않습니다.
공식 :
RESERVED_SYSTEM_MEMORY_BYTES = 300 * 1024 * 1024 BYTES = 300MB참고: 실행기 메모리 가 예약된 메모리 ( 1.5 * 예약된 메모리 = 450MB 힙 ) 의 1.5배 미만인 경우 다음 예외 메시지와 함께 Spark 작업이 실패합니다.
spark-shell --executor-memory 300m21/06/21 03:55:51 ERROR repl.Main: Failed to initialize Spark session.
java.lang.IllegalArgumentException: Executor memory 314572800 must be at least 471859200. Please increase executor memory using the --executor-memory option or spark.executor.memory in Spark configuration.
at org.apache.spark.memory.UnifiedMemoryManager$.getMaxMemory(UnifiedMemoryManager.scala:225)
at org.apache.spark.memory.UnifiedMemoryManager$.apply(UnifiedMemoryManager.scala:199)Spark Memory 2. User Memory
사용자 메모리는 사용자 정의 데이터 구조, Spark 내부 메타데이터, 사용자가 생성한 모든 UDF, RDD 종속성 정보에 대한 정보 등 RDD 변환 작업에 필요한 데이터를 저장하는 데 사용되는 메모리입니다.
예를 들어, 이 집계가 실행되도록 해시 테이블을 유지 관리하는 mapPartitions 변환을 사용하여 Spark 집계를 다시 작성할 수 있으며, 이는 소위 사용자 메모리를 소모합니다.
이 메모리 세그먼트는 Spark에서 관리하지 않습니다. Spark는 이 메모리 세그먼트를 인식/유지하지 않습니다.
공식 :
(Java Heap — Reserved Memory) * (1.0 — spark.memory.fraction)Spark Memory 3. Spark Memory (Unified Memory)
Spark 메모리는 Apache Spark에서 관리하는 메모리 풀입니다. Spark 메모리는 조인과 같은 작업 실행을 수행하거나 브로드캐스트 변수를 저장하는 동안 중간 상태를 저장하는 역할을 합니다.
모든 캐시/지속 데이터는 이 세그먼트, 특히 이 세그먼트의 스토리지 메모리에 저장됩니다.
공식 :
(Java Heap — Reserved Memory) * spark.memory.fractionSpark 작업은 두 가지 기본 메모리 영역에서 작동합니다.
- Execution – 셔플, 조인, 정렬 및 집계에 사용됩니다.
- Storage – 데이터 파티션을 캐시하는 데 사용됩니다.
이들 사이의 경계는 spark.memory.storageFraction 매개변수에 의해 설정되며 기본값은 0.5 또는 50%입니다.
- Storage Memory
Storage 메모리는 모든 캐시된 데이터, 브로드캐스트 변수 및 언롤 데이터 등을 저장하는 데 사용됩니다. "unroll"은 본질적으로 직렬화된 데이터를 역직렬화하는 프로세스입니다.
MEMORY를 포함하는 모든 지속 옵션에 대해 Spark는 해당 데이터를 이 세그먼트에 저장합니다.
Spark는 LRU(Least Recent Used) 메커니즘을 기반으로 오래된 캐시된 개체를 제거하여 새 캐시 요청을 위한 공간을 지웁니다.
캐시된 데이터가 Storage에서 나오면 디스크에 기록되거나 구성에 따라 다시 계산됩니다. 브로드캐스트 변수는 MEMORY_AND_DISK 영구 수준으로 캐시에 저장됩니다. 여기에 캐시된 데이터와 수명이 긴 데이터가 저장됩니다.
공식 :
(Java Heap — Reserved Memory) * spark.memory.fraction * spark.memory.storageFraction- Execution Memory
Execution 메모리는 Spark 작업을 실행하는 동안 필요한 개체를 저장하는 데 사용됩니다.
예를 들어, 메모리의 Map 측에 셔플 중간 버퍼를 저장하는 데 사용됩니다. 또한 해시 집계 단계를 위한 해시 테이블을 저장하는 데 사용됩니다.
이 풀은 또한 사용 가능한 메모리가 충분하지 않은 경우 디스크 유출을 지원하지만 이 풀의 블록은 다른 스레드(작업)에 의해 강제로 제거될 수 없습니다.
Execution 메모리는 Storage보다 수명이 짧은 경향이 있습니다. 각 작업 후 즉시 제거되어 다음 작업을 위한 공간을 만듭니다.
공식 :
(Java Heap — Reserved Memory) * spark.memory.fraction * (1.0 - spark.memory.storageFraction)Spark 1.6+에서는 Execution 메모리와 Storage 메모리 사이에 엄격한 경계가 없습니다.
Execution 메모리의 특성으로 인해 이 풀에서 블록을 강제로 제거할 수 없습니다. 그렇지 않으면 참조하는 블록을 찾을 수 없기 때문에 실행이 중단됩니다.
그러나 Storage 메모리의 경우 필요에 따라 블록을 메모리에서 제거하고 디스크에 쓰거나 다시 계산할 수 있습니다(지속성 수준이 MEMORY_ONLY인 경우).
Execution 및 Storage 풀 차용 규칙:
- Storage 메모리는 블록이 실행 메모리에서 사용되지 않는 경우에만 Execution 메모리에서 공간을 빌릴 수 있습니다.
- Execution 메모리는 블록이 스토리지 메모리에서 사용되지 않는 경우 Storage 메모리에서 공간을 빌릴 수도 있습니다.
- Execution 메모리의 블록이 Storage 메모리에서 사용되고 실행에 더 많은 메모리가 필요한 경우 Storage 메모리가 차지하는 초과 블록을 강제로 축출할 수 있습니다.
- Storage 메모리의 블록이 Execution 메모리에서 사용되고 스토리지가 더 많은 메모리를 필요로 하는 경우 Execution 메모리가 차지하는 초과 블록을 강제로 축출할 수 없습니다. 그것은 더 적은 메모리 영역을 갖게 될 것입니다. Spark가 Execution 메모리에 저장된 초과 블록을 해제할 때까지 기다렸다가 이를 차지합니다.
5GB 실행기 메모리에 대한 메모리 계산:
Reserved 메모리, User 메모리, Spark 메모리, Storage 메모리 및 Execution 메모리를 계산하기 위해 다음 매개변수를 사용합니다.
spark.executor.memory=5g
spark.memory.fraction=0.6
spark.memory.storageFraction=0.5Java Heap Memory = 5 GB
= 5 * 1024 MB
= 5120 MB
Reserved Memory = 300 MB
Usable Memory = (Java Heap Memory — Reserved Memory)
= 5120 MB - 300 MB
= 4820 MB
User Memory = Usable Memory * (1.0 — spark.memory.fraction)
= 4820 MB * (1.0 - 0.6)
= 4820 MB * 0.4
= 1928 MB
Spark Memory = Usable Memory * spark.memory.fraction
= 4820 MB * 0.6
= 2892 MB
Spark Storage Memory = Spark Memory * spark.memory.storageFraction
= 2892 MB * 0.5
= 1446 MB
Spark Execution Memory = Spark Memory * (1.0 - spark.memory.storageFraction)
= 2892 MB * ( 1 - 0.5)
= 2892 MB * 0.5
= 1446 MB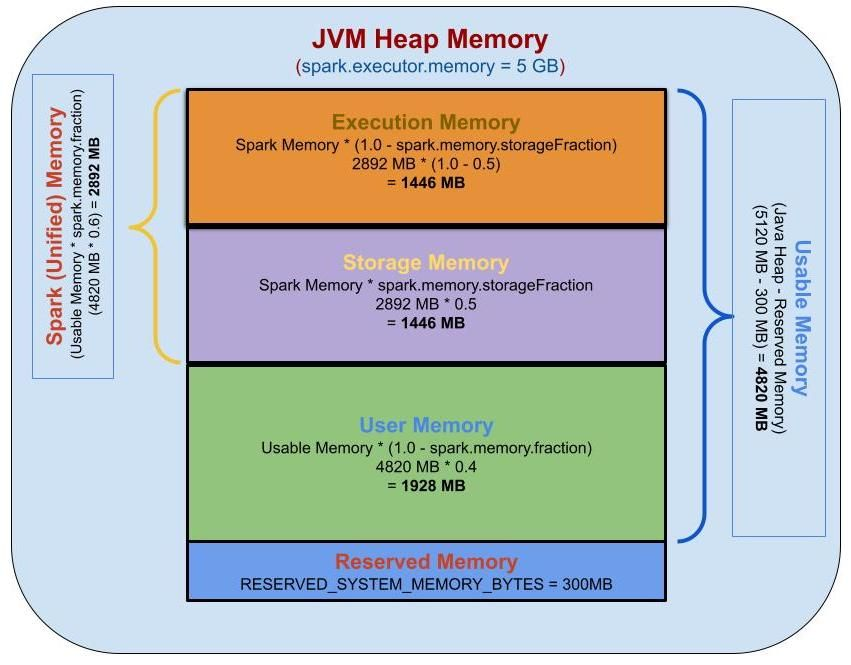
Reserved Memory — 300 MB — 5.85%
User Memory — 1928 MB — 37.65%
Spark Memory — 2892 MB — 56.48%오프힙 메모리 (Off-Heap Memory)💎
오프 힙 메모리는 운영 체제(가상 머신이 아님)에서 직접 관리하지만 네이티브로 프로세스 힙 외부에 저장되는 JVM(Java Virtual Machine) 힙 외부의 메모리에 메모리 객체(바이트 배열로 직렬화됨)를 할당하는 것을 의미합니다. 메모리(따라서 가비지 수집기에 의해 처리되지 않음).
그 결과 애플리케이션에 대한 가비지 수집의 영향을 줄이기 위해 더 작은 힙을 유지합니다.
이 데이터에 액세스하는 것은 온힙 스토리지에 액세스하는 것보다 약간 느리지만 디스크에서 읽기/쓰기보다 여전히 빠릅니다. 단점은 사용자가 할당된 메모리를 수동으로 관리해야 한다는 것입니다.
이 모델은 JVM 메모리 내에서 적용되지 않고, malloc() 내부에서 C와 같은 안전하지 않은 관련 언어에 대한 Java API를 메모리용 운영 체제에 직접 호출합니다. 이 방법은 JVM 메모리 관리를 하지 않았으므로 빈번한 GC는 피한다. 이 응용 프로그램의 단점은 메모리가 자체 논리 및 메모리 응용 프로그램 릴리스를 작성해야 한다는 것입니다.
Spark 1.6+에서는 오프힙 메모리 ( SPARK-11389 )를 도입하기 시작했습니다. 통합 메모리 관리자는 오프 힙 메모리를 사용하여 선택적으로 할당할 수 있습니다.
| 매개변수 | 설명 |
|---|---|
| spark.memory.offHeap.enabled(기본값 false) | 특정 작업에 오프 힙 메모리를 사용하는 옵션 |
| spark.memory.offHeap.size(기본값 0) | 오프 힙 할당을 위한 총 메모리 양(바이트)입니다. 힙 메모리 사용에 영향을 미치지 않으므로 실행기의 총 제한을 초과하지 않도록 하십시오. |
기본적으로 오프힙 메모리는 비활성화되어 있지만 spark.memory.offHeap.enabled(기본적으로 false) 매개변수로 활성화하고 spark.memory.offHeap.size(기본적으로 0) 매개변수로 메모리 크기를 설정할 수 있습니다. .
spark-shell \
--conf spark.memory.offHeap.enabled=true \
--conf spark.memory.offHeap.size=5g오프 힙 메모리 는 OFF_HEAP 지속성 수준을 지원 합니다. on-heap 메모리에 비해 off-heap 메모리의 모델은 Storage Memory와 Execution Memory만 포함하여 비교적 단순합니다.
[##Image|kage@rZPSg/btrrAdTUEPm/qmGALAGuaKv9hiWKajIntK/img.jpg|CDM|1.3|{"originWidth":518,"originHeight":349,"style":"alignCenter"}##]
오프 힙 메모리가 활성화된 경우 Executor에 온 힙 및 오프 힙 메모리가 모두 있습니다.
[##Image|kage@26YnI/btrrxY3Naa2/rkjZOFIuKekWxpZE881Hk1/img.png|CDM|1.3|{"originWidth":998,"originHeight":187,"style":"alignCenter"}##]
Executor 의 실행 메모리 는 힙 내부의 실행 메모리 와 힙 외부의 Execution 메모리 의 합입니다 . Storage 메모리 도 마찬가지입니다 .
장점:
- 여전히 메모리 사용량을 줄이고 빈번한 GC를 줄이고 프로그램 성능을 향상시킬 수 있습니다.
- 실행기가 종료되면 해당 실행기의 모든 캐시된 데이터가 사라지지만 오프힙 메모리를 사용하면 데이터가 계속 유지됩니다. JVM의 수명과 캐시된 데이터의 수명은 분리됩니다.
단점:
- OFF_HEAP 를 사용 하면 데이터를 백업하지 않으며 alluxio 처럼 높은 데이터 가용성을 보장 할 수 없으며 데이터 손실은 재계산이 필요합니다.
REFERENCE
- https://community.cloudera.com/t5/Community-Articles/Spark-Memory-Management/ta-p/317794
