
오늘의 나는 무엇을 잘했을까?
오늘의 나는 무엇을 배웠을까?
-
해시테이블
- Direct Access Table
- 효율적으로 key- value쌍을 저장하고 가져올 수 있지만, 낭비하는 공간이 많다. 예를 들어 데이터네 101호에 kenny가 살고 941호에 Tony가 산다는 정보가 있을때 Direct Access Table을 사용한다면, 인덱스가 941까지 있는 942칸을 만들어 놓고 2개의 인덱스만 사용하는 낭비가 발생한다.
- 해시함수
- 특정 값을 원하는 범위의 자연수로 바꿔주는 함수
- 키가 아무리 커도 항상 원하는 범위의 자연수로 바꿀 수 있다. 위의 예시라면, 해시함수를 이용하여 101호는 1, 942호는 2라는 자연수로 바꾸어 2칸만 쓸 수 있다.
- 해시 테이블
- 키를 해시함수에 넣어 원하는 자연수로 만들어 쓰는 자료구조
- 고정된 크기의 배열을 만든다.
- 키를 해싱하여 나온 그 인덱스에 (키, 값) 쌍을 넣는다.
- 해시 테이블 충돌
-
동일한 인덱스에 두개의 데이터 쌍을 저장해야 하는 경우
-
체이닝이라 부르는 기법을 통해 해결할 수 있음
-
open addressing으로도 해결할 수 있음.
-
체이닝: 인덱스에 두 값을 체인처럼 엮어 저장한다는 뜻. 보통 링크드 리스트로 값을 엮을 수 있다.
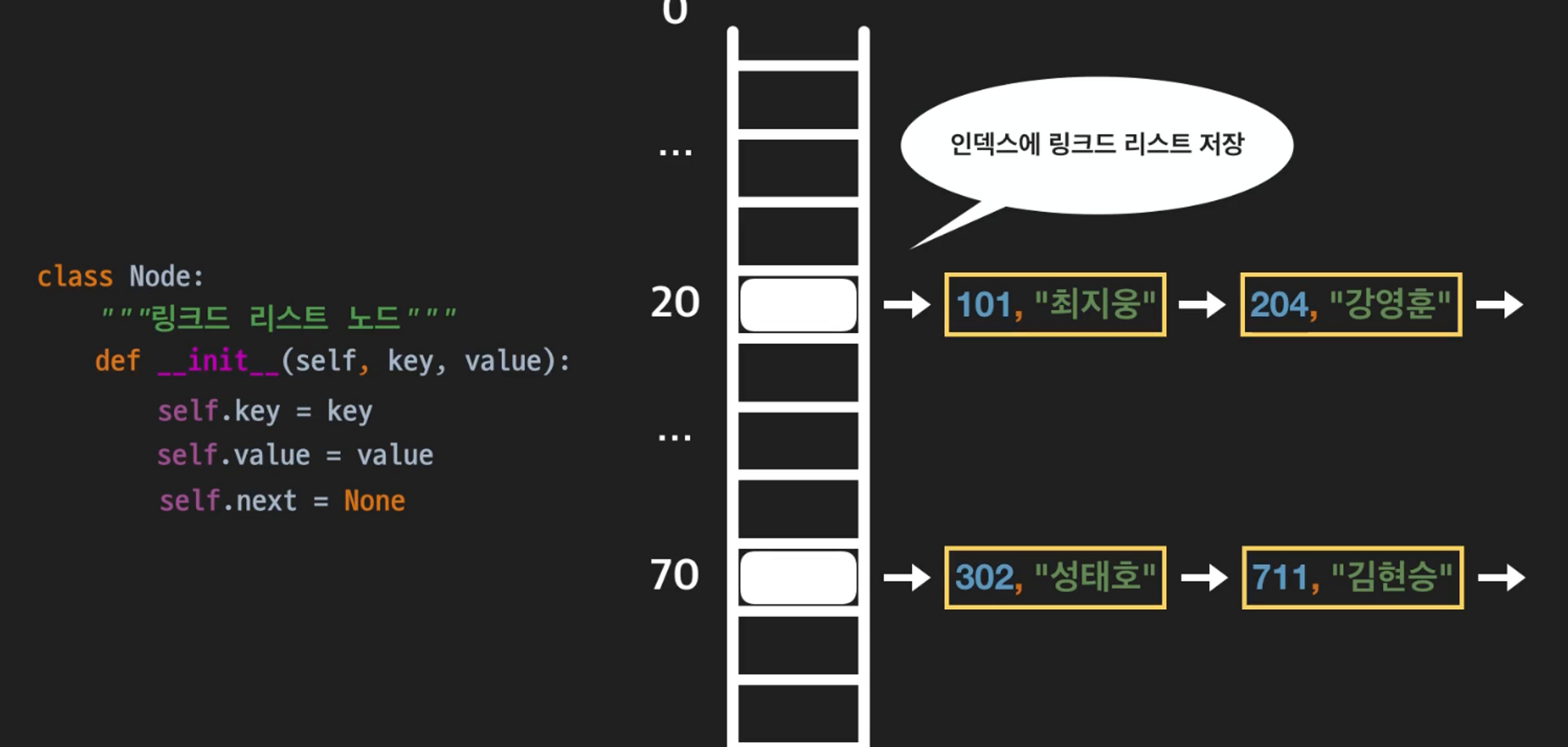
-
- 해시테이블 연산
- 탐색: 저장 순서를 고려하지 않기 때문에 접근 연산이 없다. 해시함수 계산 → 배열 인덱스 접근 →링크드 리스트 탐색이므로
- 삽입: 해시함수 계산→인덱스 접근→링크드 리스트 노드 탐색(같은 키가 있다면 대체하려고 탐색하는 과정이 필요함) → 노드 추가 및 수정
- 삭제: 해시함수 계산 → 배열 인덱스 접근 → 노드 탐색 → 삭제:
- 그런데 각 인덱스에 실질적으로 모든 노드들이 들어가는 것이 아니라 공평하게 분배되므로, 저 n은 하나의 인덱스에 평균적으로 들어가는 리스트의 길이일 것임.
- 그렇게 계산 해보면 평균적으로 해시 테이블 탐색, 삽입, 삭제 연산은 이라고 한다. 말 그대로 최악의 경우일 때만
- Direct Access Table
오늘의 나는 어떤 어려움이 있었을까?
내일의 나는 무엇을 해야할까?

Let's get after it