
오늘의 나는 무엇을 잘했을까?
자료구조를 기본부터 다시 공부함과 동시에 위클리 미션을 빠르게 시작했다. 저번 주 위클리 미션을 확장성있게 구현해 놓아서 이번주는 수월한 것 같다.
오늘의 나는 무엇을 배웠을까?
컴퓨터가 자료를 저장하는 법
-
스토리지 (HDD, SSD)
- 영구적으로 데이터를 저장
- 단점: 느림
- 영구적으로 데이터를 저장
-
메모리 (RAM)
-
임시적으로 데이터를 저장
-
단점: 휘발성이 있음
-
장점: 스토리지보다 데이터 저장과 받아오는 속도가 빠름
-
왜 두가지가 다 필요할까?
- 영화를 재생하는 것을 예시로 들면 메모리는 데이터를 받아오는게 빠르기 때문에 스토리지에 있던 영화 파일을 메모리에 복사해서 재생하는게 훨씬 빠르다
-
자료구조를 공부할 때는 메모리가 중요하다
-
메모리의 구조
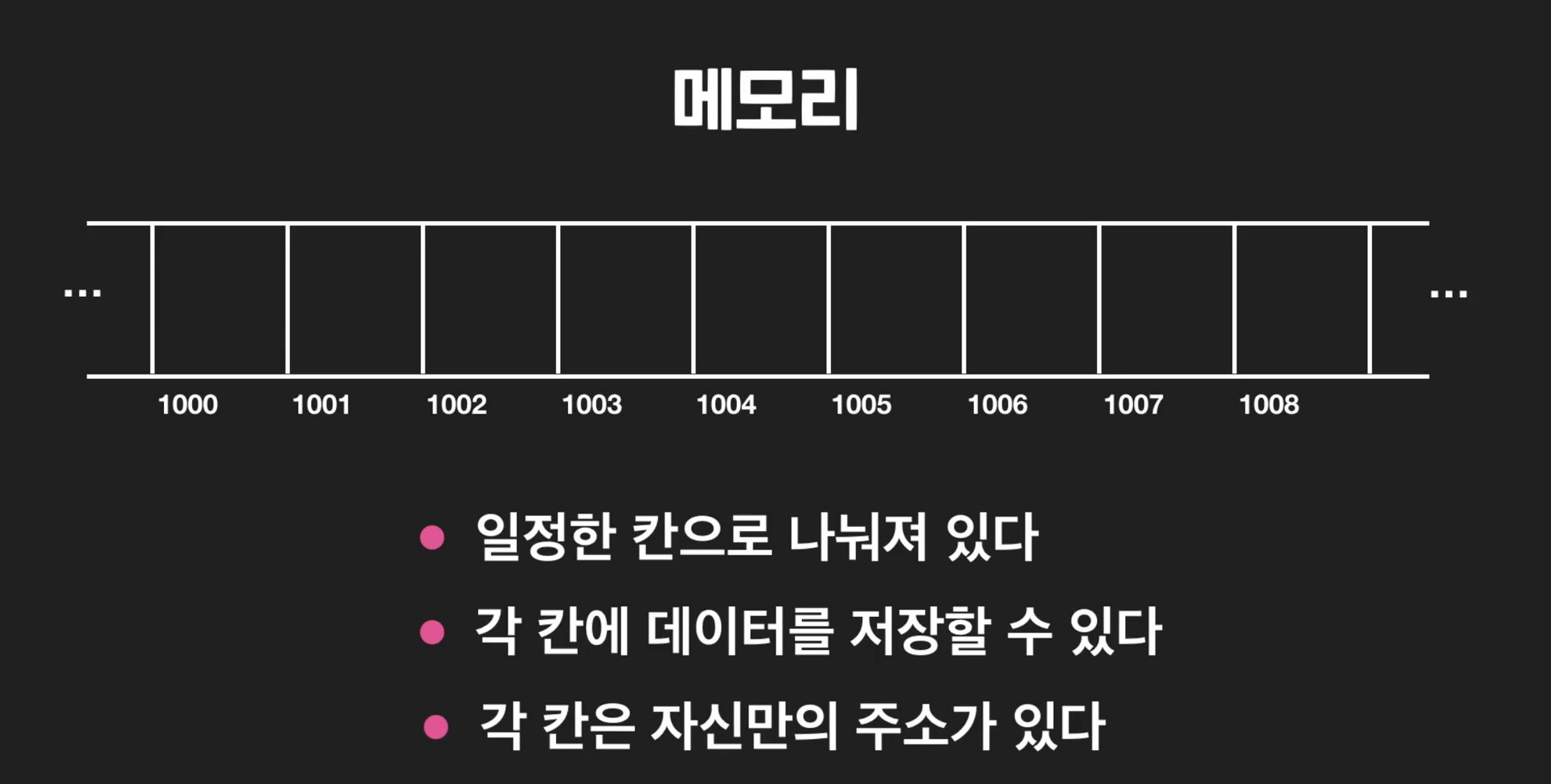
- RAM: Random access memory
- 임의 접근이란, 데이터의 저장 위치만 알면 접근 속도가 인것
-
-
레퍼런스
-
데이터에 접근할 수 있게 해주는 값을 포괄적으로 이르는 말(물리적 주소와는 사뭇 다름)
-
파이썬에서는 변수명이 레퍼런스로 취급받음.
x = 15 print(x + 5)- 위와 같은 코드에서 x는 15를 가리키는 레퍼런스를 담고있고, 실제로 변수를 사용할 때는 5라는 값을 알아서 받아온다.
- 파이썬의 id함수를 사용하면 데이터가 저장된 주소값을 정수형태로 받아온다
list1 = [1, 2, 3] print(id(list1)) # 140237662138184
-
배열 자료구조
파이썬에서는 C언어와 다르게 배열의 크기가 고정되어있지 않고, 다양한 타입을 저장할 수 있다.
-
C 배열
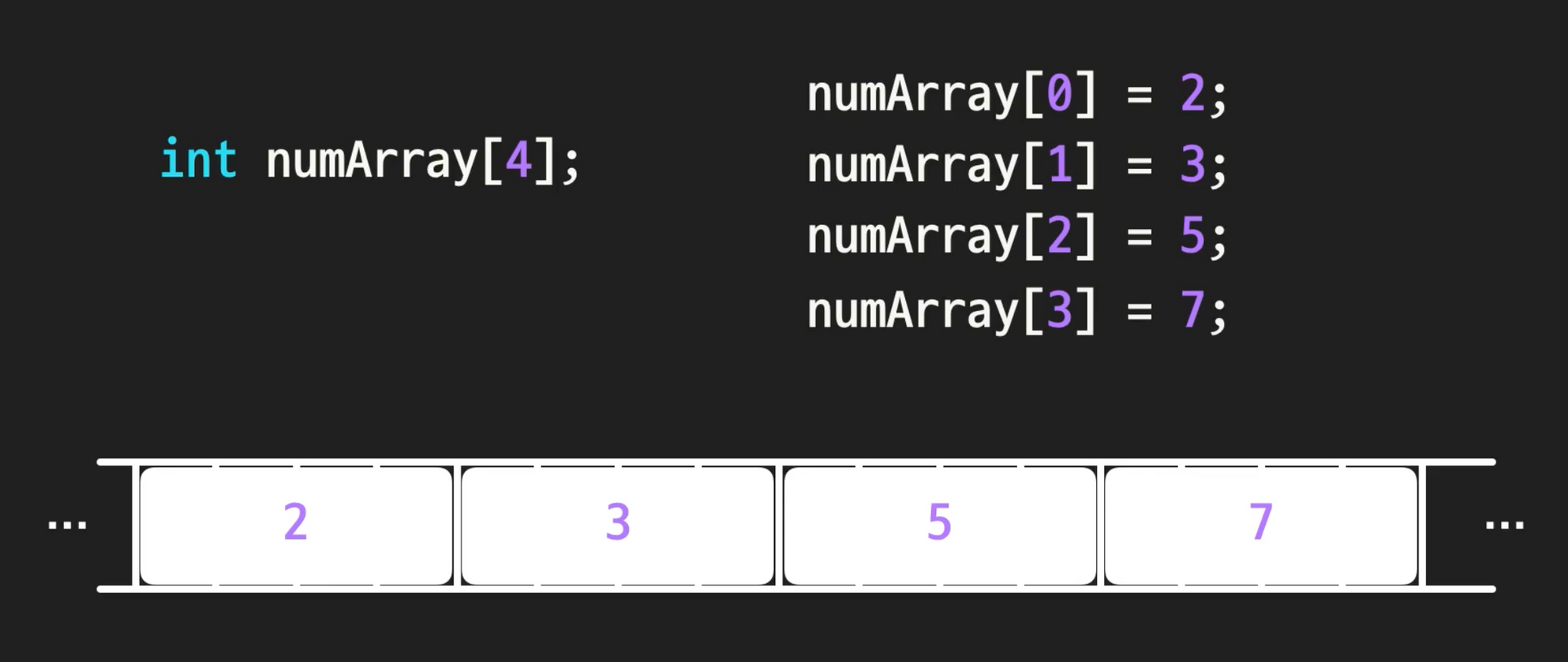
- 데이터가 메모리에 연속적으로 저장됨
- 정적 배열
-
파이썬 배열
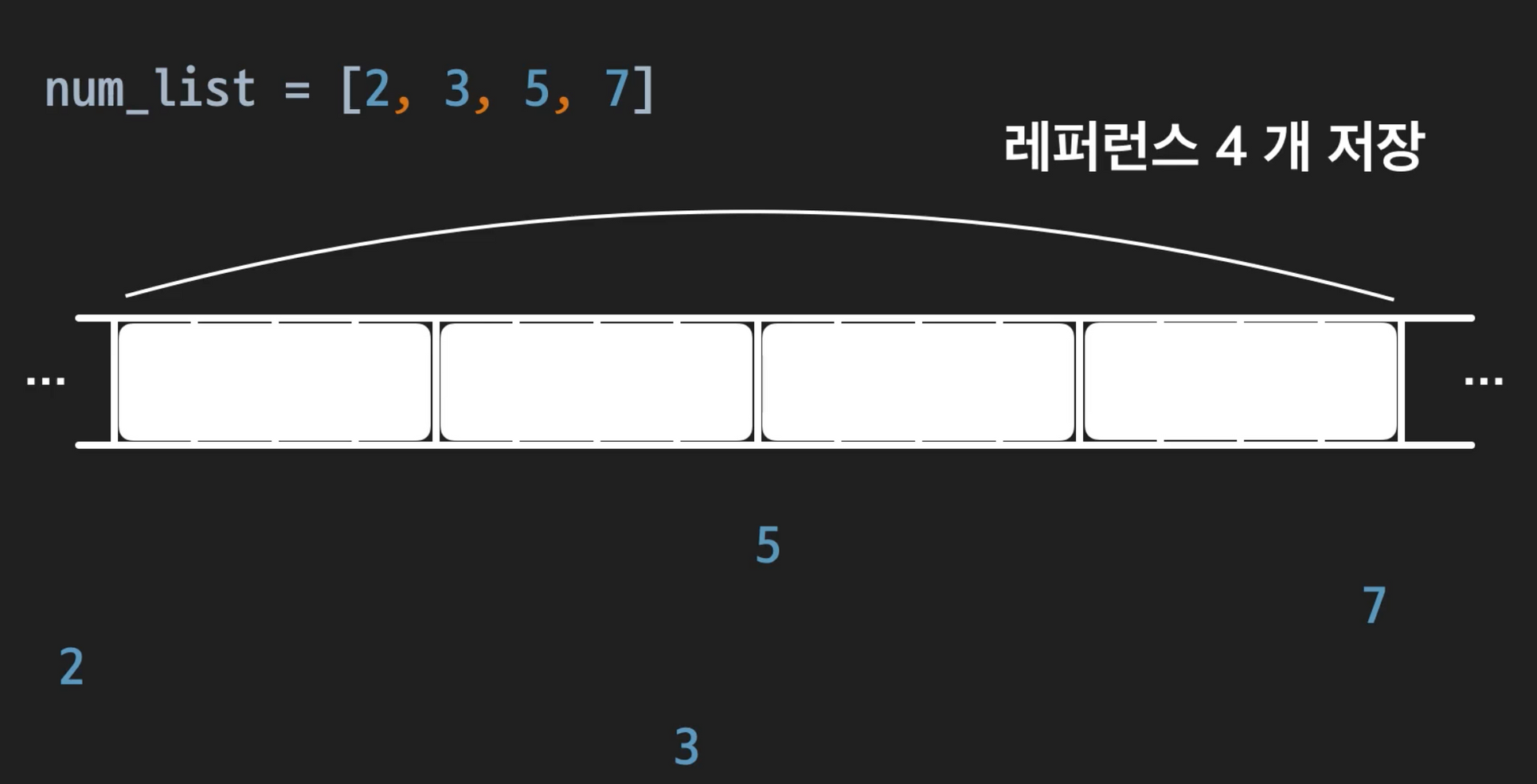
- num_list의 값들은 정수 2, 3, 5, 7을 담고있는 것이 아닌, 숫자들의 레퍼런스를 담고있음. 실제 정수들은 메모리에 랜덤한 위치에 흩어져서 저장됨. 그래서 다양한 타입들을 저장할 수 있음
- 동적 배열
- 정적 배열: 크기가 고정되어있음
- 동적 배열: 크기가 변함 (요소를 추가할 수 있음)
- 정적 배열로 만들어져 있으나, 공간이 꽉 차면 상황에 맞게 크기를 조절한다
- 예를 들면 4칸짜리로 시작해서 하나를 추가하면, 기존 크기의 2배인 8칸으로 늘리는 방법이 있다.
- 동적 배열의 append 연산(추가) 시간 복잡도
- 남는 공간 있을 때:
- 남는 공간 없을 때:
- 분할 상환 분석(할부 개념) 적용:
- 동적 배열의 inser연산(특정위치 삽입) 시간 복잡도
- 남는 공간 있을 때:
- 남는 공간 없을 때:
- 동적 배열의 delete연산 시간 복잡도
- 최악의 경우(랜덤 인덱스 지울 때):
- 가장 뒤에 있는 요소 지울 때:
- 분할 상환 분석(할부 개념) 적용:
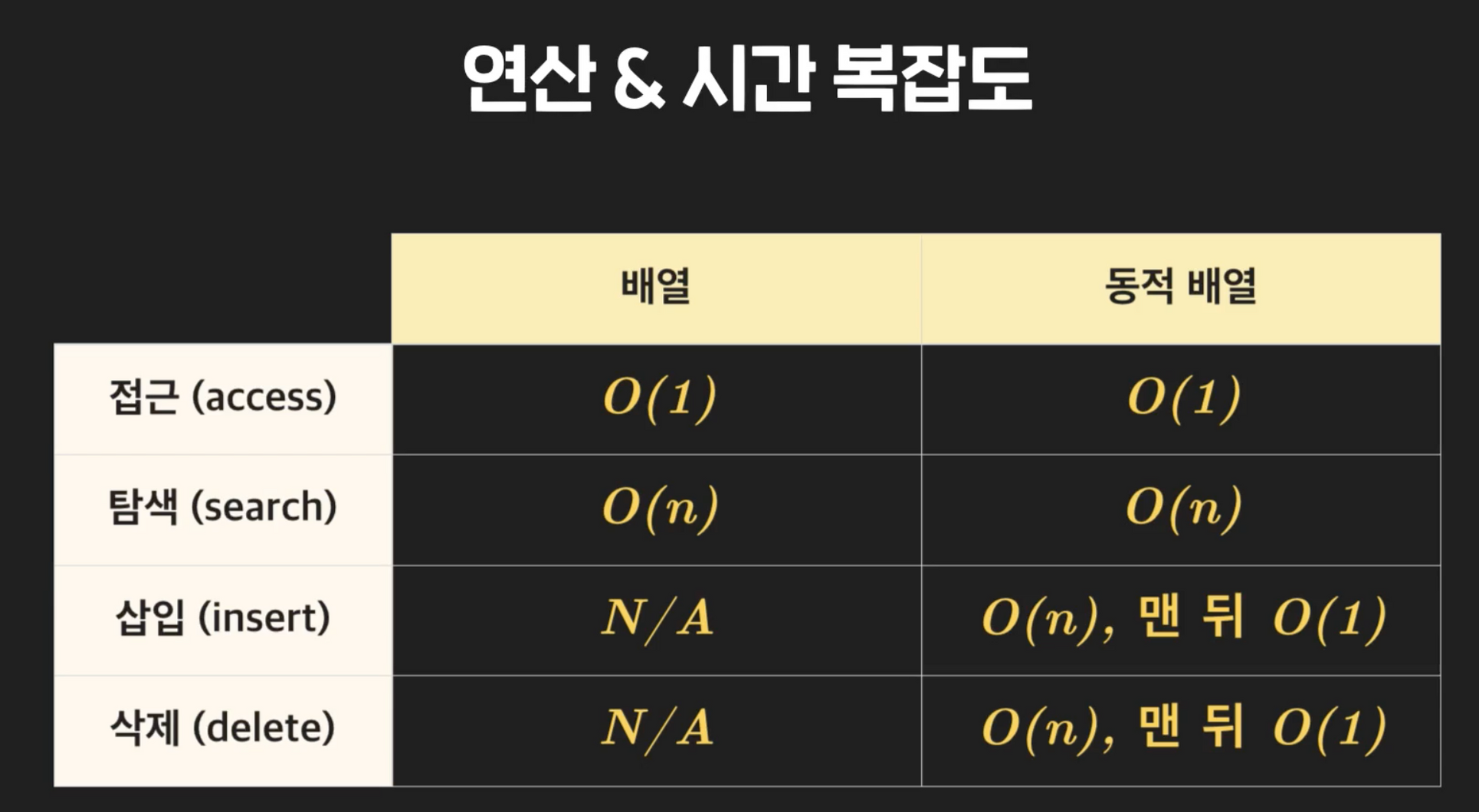
- 동적 vs 정적 배열 정리
- num_list의 값들은 정수 2, 3, 5, 7을 담고있는 것이 아닌, 숫자들의 레퍼런스를 담고있음. 실제 정수들은 메모리에 랜덤한 위치에 흩어져서 저장됨. 그래서 다양한 타입들을 저장할 수 있음
링크드 리스트 자료구조
링크드 리스트 자료구조 또한 데이터를 순서대로 저장해주고, 요소를 계속 추가할 수 있다는 점점에서 동적 배열과 유사하지만, 그 구현 방식이 완전히 다르다.
-
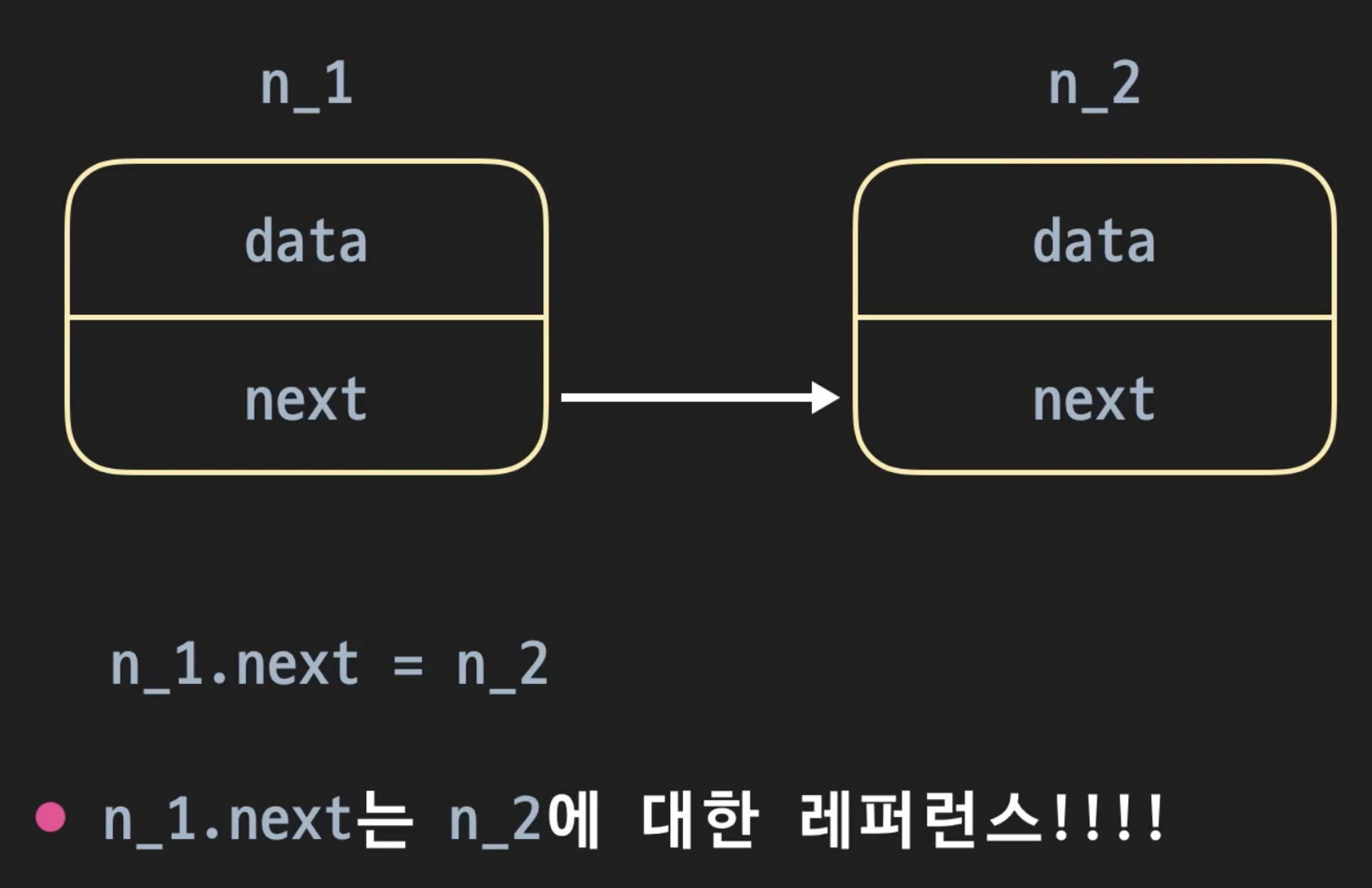
노드
-
링크드 리스트에 저장한 하나의 자료가 담기는 박스
-
노드는 데이터와 다음 노드에 대한 레퍼런스로 이루어져 있다.
-
실제 메모리에서는 노드들이 여기저기 흩어져 있다. 즉, 배열처럼 연속적인 공간에 할당되지 않는다.
-
-
간단한 링크드 리스트 만들기
class Node: # 링크드 리스트의 노드 클래스 def __init__(self, data): self.data = data # 노드가 저장하는 데이터 self.next = None # 다음 노드에 대한 레퍼런스 # 데이터 2,3,5,7,11을 담는 노드들을 생성 head_node = Node(2) node_1 = Node(3) node_2 = Node(5) node_3 = Node(7) tail_node = Node(11) # 노드들을 연결 head_node.next = node_1 node_1.next = node_2 node_2.next = node_3 node_3.next = tail_node # 노드 순서대로 출력 iterator = head_node while iterator is not None: print(iterator.data) iterator = iterator.next # 실행 결과 # 2 # 3 # 5 # 7 # 11 -
링크드 리스트 추가연산
- 시간 복잡도:
class LinkedList: def __init__(self, data): self.head = None self.tail = None def append(self, data): # 링크드 리스트 추가 연산 메서드 new_node = Node(data) if self.head is None: # 링크드 리스트가 비어있는 경우 self.head = new_node self.tail = new_node else: # 링크드 리스트가 비어있지 않은 경우 self.tail.next = new_node self.tail = new_node def __str__(self): """링크드 리스트를 문자열로 표현해서 리턴하는 메소드""" res_str = "|" # 링크드 리스트 안에 모든 노드를 돌기 위한 변수. 일단 가장 앞 노드로 정의한다. iterator = self.head # 링크드 리스트 끝까지 돈다 while iterator is not None: # 각 노드의 데이터를 리턴하는 문자열에 더해준다 res_str += f" {iterator.data} |" iterator = iterator.next # 다음 노드로 넘어간다 return res_str # 새로운 링크드 리스트 생성 my_list = LinkedList() # 링크드 리스트에 데이터 추가 my_list.append(2) my_list.append(3) my_list.append(5) my_list.append(7) my_list.append(11) # 노드 데이터 순서대로 출력 print(my_list) # 실행 결과 # | 2 | 3 | 5 | 7 | 11 | -
링크드 리스트 접근 연산
- 시간 복잡도: 인덱스 x에 있는 노드에 접근하려면 head에서 다음 노드로 x번 가야함.
class LinkedList: ... def find_node_at(self, index): # 링크드 리스트 접근 연산 메서드, 파라미터 인덱스는 항상 있다고 가정 iterator = self.head for _ in range(index): iterator = iterator.next return iterator ... print(my_list.find_node_at(3).data) # 실행 결과 # 7 - 시간 복잡도: 인덱스 x에 있는 노드에 접근하려면 head에서 다음 노드로 x번 가야함.
-
링크드 리스트 삽입 연산
- 시간 복잡도:
class LinkedList: ... def insert_after(self, prev_node, data): # 링크드 리스트 주어진 노드 위 삽입 연산 메서드 new_node = Node(data) # 가장 마지막 순서로 삽입하는 경우 if prev_node is self.tail: self.tail.next = new_node self.tail = new_node else: # 두 노드 사이에 삽입하는 경우 new_node.next = prev_node.next prev_node.next = new_node def prepend(self, data): """링크드 리스트의 가장 앞에 데이터 삽입""" # 코드를 쓰세요 new_node = Node(data) if self.head is None: self.head = new_node self.tail = new_node else: new_node.next = self.head self.head = new_node -
링크드 리스트 삭제연산
- 시간 복잡도:class LinkedList: ... def delete_after(self, prev_node): # 링크드 리스트 삭제연산, 주어진 노드 뒤 노드를 삭제한다 data = prev_node.next.data if prev_node.next is self.tail: # 삭제하려는 노드가 tail일 경우 prev_node.next = None self.tail = prev_node else: # 두 노드 사이 노드를 지울 때 prev_node.next = prev_node.next.next return data def pop_left(self): # 링크드 리스트의 가장 앞 노드 삭제 메소드. 단, 링크드 리스트에 항상 노드가 있다고 가정한다 data = self.head.data if self.head is self.tail: self.head = None self.tail = None return data self.head = self.head.next return data ...더블리 링크드 리스트 자료구조
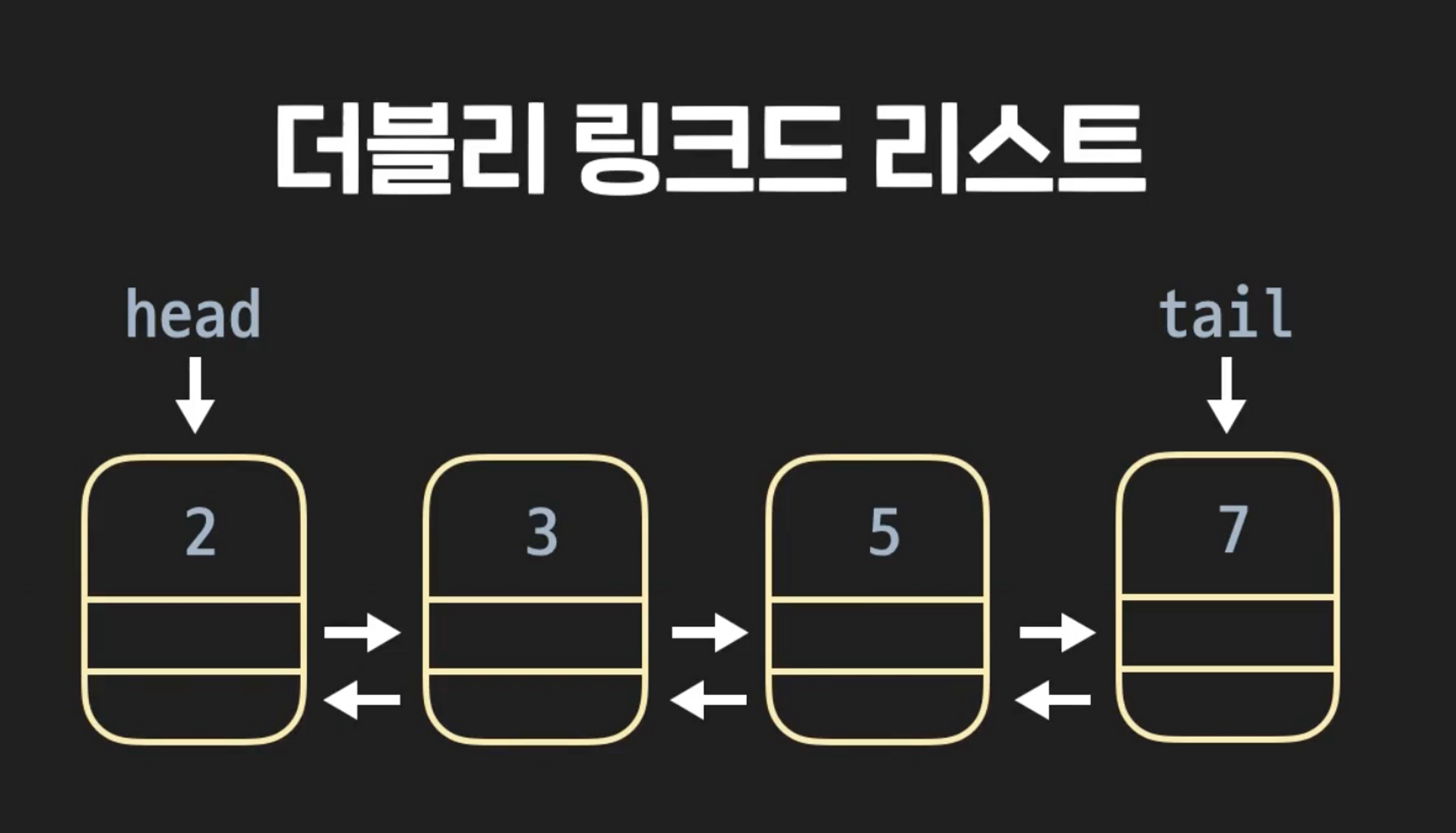
각 노드가 앞 노드와 뒤 노드에 대한 레퍼런스를 가지는 링크드 리스트 자료구조이다.
-
구현
- 싱글리 링크드 리스트와 겹치는 메서드도 있고, 그렇지 않은 메서드도 있다.
find_node_at(접근연산),find_node_with_data(탐색 연산)이 겹친다.
class Node: def __init__(self, data): self.data = data self.next = None self.prev = None ... class LinkedList: def __init__(self): self.head = None self.tail = None - 싱글리 링크드 리스트와 겹치는 메서드도 있고, 그렇지 않은 메서드도 있다.
-
더블리 링크드 리스트 추가 연산 메서드
class LinkedList: ... def append(self, data): # 더블리 링크드 리스트 맨 뒤에 추가 연산 메서드 new_node = Node(data) # 빈 리스트의 경우 if self.head is None: self.head = new_node self.tail = new_node else: self.tail.next = new_node new_node.prev = self.tail self.tail = new_node -
더블리 링크드 리스트 삽입
class LinkedList: ... def insert_after(self, prev_node, data): # 더블리 링크드 리스트 주어진 노드(prev_node) 뒤에 새 노드 삽입 연산 new_node = Node(data) if prev_node is self.tail: # 주어진 노드가 tail노드인 경우 self.tail.next = new_node new_node.prev = self.tail self.tail = new_node else: # 두 노드 사이에 삽입하는 경우 new_node.prev = prev_node new_node.next = prev_node.next prev_node.next = new_node new_node.next.prev = new_node def prepend(self, data): # 더블리 링크드 리스트 맨 앞에 새 노드를 삽입하는 메서드 new_node = Node(data) if self.head is None: # 리스트가 빈 경우 self.head = new_node self.tail = new_node else: new_node.next = self.head self.head.prev = new_node self.head = new_node -
더블리 링크드 리스트 삭제
- 싱글리 링크드 리스트와는 다르게, 지우려는 노드를 넘겨주면, 이전 노드의 레퍼런스를 가지고 있기 때문에 이전 노드를 받는 것이 아닌 지우려는 노드 자체를 받으면 된다.
class LinkedList: ... def delete(self, node_to_delete): # 더블리 링크드 리스트 삭제 연산 메소드 data = node_to_delete.data if node_to_delete is self.head: if node_to_delete is self.tail: # 마지막 노드 삭제 self.head = None self.tail = None else: self.head = node_to_delete.next self.head.prev = None elif node_to_delete is self.tail: self.tail = node_to_delete.prev self.tail.next = None else: node_to_delete.prev.next = node_to_delete.next node_to_delete.next.prev = node_to_delete.prev return data ... -
더블리 링크드 리스트는 맨 뒤의 요소를 삭제할 때 싱글리 링크드 리스트에 비해 시간복잡도를 가지므로 유리하다. 따라서 tail노드를 많이 삭제해야 할 때는 더블리 링크드 리스트로 구현하는 것이 좋다.
api로 서버에서 데이터 받아와서 커스텀 웹 컴포넌트에 전달하기
자세한 내용은 여기에 정리해 두었다.
오늘의 나는 어떤 어려움이 있었을까?
오늘은 딱히 어려움이 없었다.
내일의 나는 무엇을 해야할까?
- 위클리 미션 끝내기
- 딥다이브 북스터디 준비하기
- 알고리즘 강의 완강하기

꽤나 오만함이 느껴지는 것 같습니다.
그러나 인정합니다.