[AIB]Note231~2 Choose Your ML Problems, Data Wrangling
AIB 학습

1. Choose Your ML Problems
1.1 Accuracy만 사용하면?
- 일전에 한번 언급했었는데, 편향된 데이터 값을 사용하면 문제가 발생할 수 있다. (더 보러 가기)
1.2 데이터 과학자 실무 프로세스
- 비즈니스 문제 파악
- 데이터 문제 파악
- 데이터 문제 해결(데이터 처리 및 시각화, 머신러닝 기법과 통계학을 사용)
- 비즈니스 문제 해결
문제 정의가 중요
1.3 문제 파악
지도학습(Supervised Learning): 예측해야하는 타겟이 무엇인지 확실히 정해야한다. 타겟은 이산형인지, 순서형인지, 범주형인지 등등 어떤 형태로 표현되어야 하는지도 명확히 이해하고 있어야 한다.
1.4 정보의 누수(Data Leakage)
정보의 누수도 과거 언급했었다. (더 보러 가기) 정보의 누수가 가지는 문제점은 모델이 실전에서 성능이 급격히 떨어질 수 있다는 것!! 그렇기에 항상 조심해야한다.
1.5 문제에 적합한 평가지표
분류: Accuracy, Precision, Recall, F1 등등
회귀: MSE, MAE, RMSE, R-squared
분류인데 회귀 평가지표를 사용하고, 회귀인데 분류 평가지표를 사용하고.... 그런 경우는 일어나서는 안된다...
수능에서 수리 가형과 수리 나형의 원점수를 그냥 비교하면 되겠는가,,,,,
1.6 불균형 클래스
Class_weight: 데이터에 A Class에 속한 데이터가 적으면 Oversampling, 많으면 Undersampling 등을 적용한다. 물론 Test에는 사용하면 안됨!! 아니면 직접 Class에 가중치를 부여해준다.
OverSampling: 데이터에 노이즈를 넣어서 Overfitting을 방지한다. 대표적인 방법은 SMOTE
UnderSampling: B Class에 속한 데이터가 많으면, 그 데이터를 적게 샘플링한다.
1.7 회귀 분석에서 타겟의 분포
회귀 분석은 기본적으로
1. 특성과 타겟사이에 선형을 가정한다.
2. 특성과 타겟이 정규분포일 때 좋은 성능을 나타낸다.
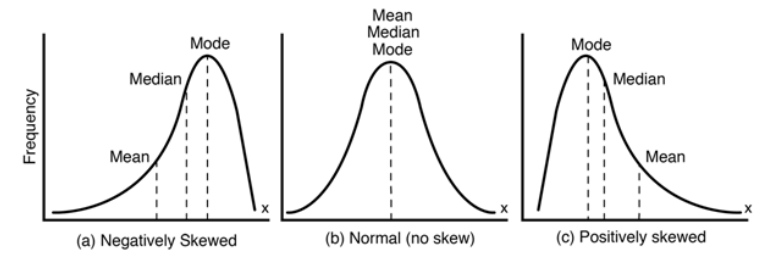
위의 그림과 같이 한쪽으로 치우친(Skewed) 분포가 있으면 성능이 잘 나오지 않는다...
- 오른쪽에 있는 그림이 Right skewed 분포라고 한다. 꼬리가 오른쪽으로 길다 == 자료가 왼쪽으로 치우처져있다. (왼쪽으로 꼬리가 긴 경우보다 많이 나타난다고 한다.)
이럴 때에는 log변환을 해주면 정규 분포의 형태로 변환시킬 수 있다. - 왼쪽에 있는 그림은 반대로 생각하면 된다. Left skewed 분포.
이럴 때에는 루트변환해주면 좋다고 한다.
단, 로그, 루트 모두 딱 정해진 답은 아니고 그 때, 그 때의 흐름, 형태 등에 따라서 기본적인 개념을 잡고 다양한 수식으로 변환시켜 주면 된다!
2. Data Wrangling
- 데이터 랭글링은 분석, 모델 설계 등에 앞서 데이터를 변환하거나 맵핑하는 과정. 보통 모델링 과정 중 가장 많은 시간이 소요된다.
- Pandas Dataframe, groupby, merge, count_values, sort_values, apply, condition(isin, query, etc) 등등 다양한 함수를 사용해서 데이터를 모으고, 분석하고, 정렬하고 등등을 한다.
- 가장 큰 줄기는 Pandas dataframe으로 뭉친다. 그렇기에 Pandas만 잘 잡고 가도 실무에서도 분석을 잘 할 수 있다.
+
-
'if not x['base_correct']'가 base_correct가 False이면 1이라는 뜻인가요?
네 -
로직 vs 알고리즘
로직: 좀 간단한 거
알고리즘: 좀 더 복잡한 문제를 풀고 그러는 것.
