개요
현재 프로젝트에서 상품의 조회수를 증가 시키기 위해 다음과 같은 로직을 사용하고 있었습니다.
@Transactional
public ItemDetailResponse read(Long memberId, Long itemId) {
Item item = findItem(itemId);
List<ItemImage> images = itemImageRepository.findByItemId(itemId);
if (!item.isSeller(memberId)) {
item.incrementViewCount();
return ItemDetailResponse.toBuyerResponse(item, images);
}
return ItemDetailResponse.toSellerResponse(item, images);
}하지만 위 로직은 상품 조회마다 DB에 쓰기 작업을 수행하고 있었습니다. 이는 read라는 상품 조회로직에 어색할 뿐만 아니라 조회마다 추가적인 I/O 연산이 발생해 성능이 좋지 않았습니다.
이번 포스팅에서는 이를 해결하는 과정을 작성하고 추가적으로 동시성 문제를 고려한 과정을 공유하고자 합니다.
레디스를 통한 조회수 증가
조회수 증가 연산은 redis를 통해 수행하고 읽기 로직은 그대로 수행하기로 했습니다.
먼저 조회수 증가 연산을 수행하는 로직을 작성합니다.
public void increaseViewCount(Long itemId) {
String viewCountKey = RedisUtil.createItemViewCountCacheKey(itemId);
if (redisService.hasKey(viewCountKey)) {
redisService.increase(viewCountKey);
return;
}
redisService.set(viewCountKey, INITIAL_VIEW_COUNT, Duration.ofSeconds(100).toMillis());
}createItemViewCountCacheKey메서드는 주어진 상품 아이디를 통해 itemViewCount::1와 같이 키를 만드는 메서드 입니다. 해당 키가 redis에 존재하면 키의 value값을 redis의 incr 명령어를 통해 증가시키고 그렇지 않다면 1로 초기화 시킵니다.
이후 redis에 반영된 조회수 증가를 DB에 반영해야 합니다. redis의 증가된 값을 바로 DB에 반영하는 것은 레디스를 사용하는 의미가 없기 때문에 레디스에 증가분을 모았다가 스케줄러를 통해 DB에 반영하도록 합니다.
스케줄러를 통해 한 번에 DB에 반영하기
@Async("viewCountExecutor")
@Scheduled(fixedDelay = 5000L)
@Transactional
public void applyViewCountToRDB() {
List<String> itemViewCountKeys = redisService.getKeysOrderByExpiration(
RedisUtil.getProductViewCountCacheKeyPattern());
if (itemViewCountKeys.isEmpty()) {
return;
}
itemViewCountKeys.forEach(key -> {
int viewCount = redisService.getAndDelete(key);
itemRepository.findById(extractItemId(key))
.ifPresent(item -> item.addViewCount(viewCount));
});
}redisService의 getKeysOrderByExpiration 메서드는 키의 만료기한를 기준으로 만료기한이 얼마 남지 않은 키들을 가져오는 메서드 입니다.
이후 각 키들에 대해 조회수 값을 가져와 DB에 반영하도록 합니다.
동시성 고려하기
여기까지 간단하게 스케줄러와 레디스를 통해 조회수를 일정 시간마다 반영해보았습니다. 그런데 여기서 고려하지 않은 점이 있습니다. 바로 여러 명의 사용자가 같은 상품에 동시에 접근했을 경우 입니다. 상품 조회의 경우 여러 사람이 동시에 접근하는 것이 가능하다고 생각했기 때문에 이를 고려하여 로직을 작성하려 합니다.
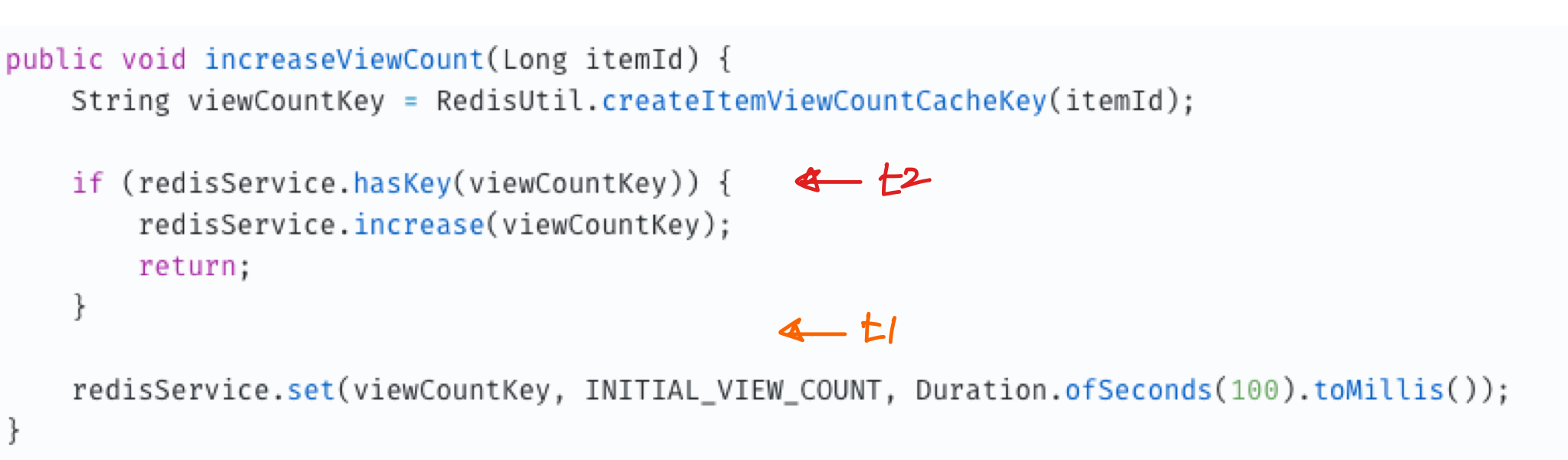
위 그림과 같이 두 명의 사용자가 동시에 increaseViewCount 메서드에 접근한다고 가정해보겠습니다. t1 스레드가 아직 레디스에 값을 저장하지 않았다고 했을 때 t2 스레드가 redisService.hasKey 메서드에 접근한다면 false를 얻을 것이고 조회수가 누락되게 됩니다.
이를 고려해 키가 존재하는지 확인하기 전 lock을 통해 문제를 해결하고자 합니다.
우리는 레디스를 사용하고 있기 때문에 redis의 동시성 문제를 해결할 수 있는 방법 두 가지를 고려해보고자 합니다.
- Lettuce
- Redisson
Lettuce 사용하기
lettuce를 통해 문제를 해결할 수 있습니다. lettuce의 setNx 명령어는 set if not exist의 줄임말로 키와 밸류를 설정할 때 기존의 값이 없을 때만 적용되는 명령어 입니다.
이 방식은 spin lock 방식으로 lock 획득에 실패했을 때의 retry 로직을 개발자가 직접 작성해주어야 합니다.
spin lock? 🧐
스핀 락은 락을 획득하려는 스레드가 락을 획득할 수 있는지 계속해서 반복적으로 확인하면서 락 획득을 시도하는 방식입니다.
먼저 RedisLockService를 생성하고 lock 획득과 해제 로직을 작성해줍니다.
@RequiredArgsConstructor
@Component
public class RedisLockService {
private final RedisTemplate<String, Object> redisTemplate;
public Boolean lock(String key) {
return redisTemplate
.opsForValue()
.setIfAbsent(key, "lock", Duration.ofMillis(3000L));
}
public Boolean unlock(String key) {
return redisTemplate.delete(key);
}
}이후 락을 획득한 스레드에 대해서만 값을 변경 혹은 설정할 수 있도록 해줍니다.
public void increaseViewCount(Long itemId) {
String viewCountKey = RedisUtil.createItemViewCountCacheKey(itemId);
// locking - spinlock
while (!redisLockRepository.lock("lock::" + viewCountKey)) {
try {
Thread.sleep(100);
} catch (InterruptedException ignored) {
}
}
try {
if (redisService.hasKey(viewCountKey)) {
redisService.increase(viewCountKey);
return;
}
redisService.set(viewCountKey, INITIAL_VIEW_COUNT, Duration.ofSeconds(100).toMillis());
} finally {
redisLockRepository.unlock("lock::" + viewCountKey);
}
}Redisson 사용하기
Redisson은 pub/sub 기반의 락 구현이 되어 있습니다. pub/sub 기반의 락 방식은 채널을 하나 생성하고 락을 점유 중인 스레드가 락을 획득하려고 대기중인 다른 스레드에게 락 해제를 알려주면 이를 알아챈 스레드가 락 획득 시도를 하는 방식입니다.
이 방식은 lettuce와는 다르게 별도의 retry 로직을 작성하지 않아도 됩니다.
코드로 적용해보겠습니다. 먼저 redisson을 사용하기 위해서는 별도의 dependency를 추가해줘야 합니다.
implementation 'org.redisson:redisson-spring-boot-starter:3.23.5'이후 RedissonClient를 DI받고 조회수를 증가시키는 로직을 작성합니다.
public void increaseViewCount(Long itemId) {
String viewCountKey = RedisUtil.createItemViewCountCacheKey(itemId);
RLock lock = redissonClient.getLock("lock::" + viewCountKey);
try {
boolean available = lock.tryLock(10, 1, TimeUnit.SECONDS);
if (!available) {
return;
}
if (redisService.hasKey(viewCountKey)) {
redisService.increase(viewCountKey);
return;
}
redisService.set(viewCountKey, INITIAL_VIEW_COUNT, Duration.ofSeconds(100).toMillis());
} catch (InterruptedException ignored) {
} finally {
lock.unlock();
}
}- redissonClient.getLock 메서드를 통해 락을 생성합니다.
- 이후 tryLock 메서드를 통해 락 획득을 몇 초 동안 시도할 것인지, 몇 초 동안 점유할 것인지 설정한 후 락을 획득합니다.
- 락 획득에 성공했다면 조회수를 증가시키고 그렇지 않으면 return 합니다.
- 모든 로직이 수행되었다면 unlock 메서드를 통해 락을 해제해줍니다.
redisson은 pub/sub 구조를 이용하기 때문에 lettuce 를 이용한 방식보다는 레디스에 부하를 덜 준다는 장점이 있습니다. 그렇지만 라이브러리를 별도로 추가해주어야 한다는 부담감과 구현이 복잡하다는 단점이 존재합니다.
더 나아가 현재 단일 인스턴스 환경에서 스케줄러를 구성했습니다. 만약 WAS의 개수가 늘어나게 되면 동일한 스케줄러가 같은 레디스에 접근하게 될 텐데 이를 어떻게 해결할 수 있을지 고민해야겠습니다.
성능테스트
매 상품 조회마다 DB에 I/O 연산을 수행하는 것보다 얼마나 많은 차이가 있는지 확인하기 위해 JMeter를 통해 TPS를 측정해보았습니다.
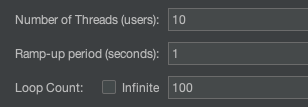
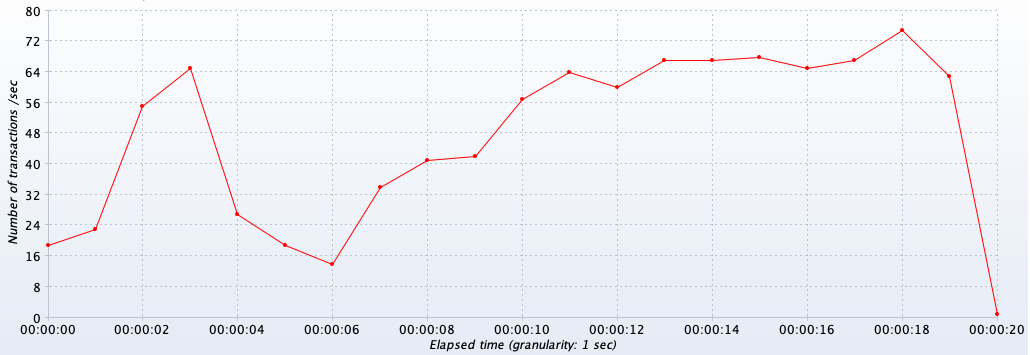
최대 60-70 정도의 TPS가 나오고 있는 것을 확인할 수 있었습니다. 이제 레디스와 스케줄러를 통해 개선된 방법의 경우 TPS를 측정해보았습니다.
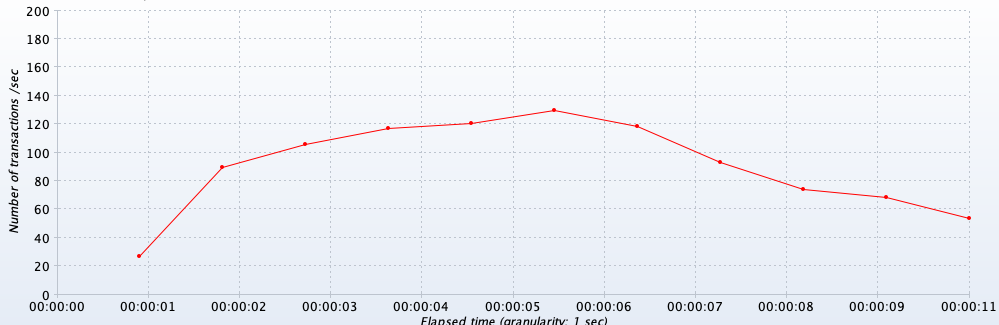
최대 120-130 정도의 TPS가 나오고 있는 것을 확인할 수 있었습니다.