
11장 뉴스 피드 시스템 설계
뉴스 피드라고 하니 뭔가 BBC나 네이버 뉴스 같은 느낌이 들 수 있지만 그런건 아니다. 이번 장에서 말하는 뉴스 피드는 인스타그램, 페이스북, 트위터 같은 SNS의 메인 피드를 말한다. 그러니까 다른 사람들이 쓴 글이 무한 스크롤로 보여지는 그 공간이다.
큰 그림
같은 시간이더라도 내가 보는 피드 화면과 내 친구가 보는 피드 화면은 다르다. 팔로잉과 팔로워, 좋아요와 댓글, 공유, 차단 등 활동이 다르기 때문이다. 피드 시스템은 각 유저별로 서로 다른 화면을 보여줘야 한다.
피드 시스템은 크게 2가지 부분으로 이루어진다. 유저 한 명마다 서로 다른 게시물을 보여줘야 하는 목표를 효율적으로 달성하기 위해서다.
- 피드 발행 시스템: 사용자 1명이 새 게시물을 만들었을 때 작동한다. 인증, 처리율 제한, 팬아웃(fanout) 서비스가 발행 시스템에 속한다.
- 피드 읽기 시스템: 사용자 1명이 앱에 접속해서 피드를 볼 때 작동한다. 새로고침 할 때마다 게시글 구성이 달라지는 피드도 있다. CDN, 캐시 서비스가 읽기 시스템에 속한다.
피드를 만드는 2가지 방법
정확히는 ‘게시물을 전파하는’ 방법이 2가지가 있다. 사용자가 새 게시물을 썼을 때, 그 글을 봐야 하는 모든 사람들(예: 인스타그램의 팔로워, 페이스북의 친구)에게 전달하는 과정이다. 이를 팬아웃(fanout)이라고 한다.
- Push model 푸시 모델 (혹은 fanout-on-write): 쓰기 시점에 팬아웃하는 것.
- 즉, 사용자 1명이 게시글을 적을 때마다 자신의 팔로워 모두에게 해당 글을 전파한다.
- Pull model 풀 모델 (혹은 fanout-on-read): 읽기 시점에 팬아웃하는 것.
- 게시글을 적을 때는 별 동작이 없다가 팔로워 1명이 새로고침 하는 시점에 그 사람의 피드만 갱신한다.
- 따라서 on-demand 모델이다. Lazy 하다고도 표현할 수 있겠다.
- 게시글을 적을 때는 별 동작이 없다가 팔로워 1명이 새로고침 하는 시점에 그 사람의 피드만 갱신한다.
Push model 푸시 모델
사용자 A가 새 글을 기록할 때마다 A의 친구 목록에 있는 사람들 모두에게 글이 전송된다.
장점
- 피드가 실시간으로 갱신된다.
- 피드를 읽는데 드는 시간이 짧아진다. 새 포스팅이 기록되는 순간, 피드가 이미 수정되기 때문이다.
단점
- Hotkey problem 핫 키 문제: 친구가 많은 사용자의 경우, 그 목록에 있는 모든 사람의 피드를 갱신하는데 오랜 시간이 걸린다.
- 예) 아래 기사에 따르면, 트위터의 일론 머스크가 게시글 1개를 적을 때마다 1억개가 넘는 피드를 갱신해야만 한다.

- 컴퓨팅 자원이 낭비될 수 있다. 서비스를 자주 사용하지 않는 사람의 피드까지 갱신해야 하기 때문이다.
Pull model 풀 모델
사용자 A가 피드를 읽을 때마다 새로운 글을 가져와서 A의 피드를 갱신한다.
장점
- 비활성 사용자 수, 혹은 자주 접속하지 않는 사용자가 꽤 많다면 이 모델이 더 유리하다. 로그인해서 피드 새로고침하기 전까지는 그 어떤 자원도 사용하지 않기 때문이다.
- 핫 키 문제가 생기지 않는다.
단점
- 피드를 읽는 시간이 비교적 오래 걸린다. 읽기 전까지는 과거 이력에 머물러 있던 피드를 수정해야하기 때문이다.
하이브리드 모델
대부분 컴퓨터 엔지니어링 기법이 그렇듯, 한가지 방식만 쓰면 장단점이 너무 명확하기 때문에 이 둘을 섞어서 쓰면 좀 더 나은 방법이 탄생한다. 여기서도 그렇다. 위 2가지 모델의 장점만 취하고자 한다면 아래와 같은 방법을 생각해볼 수 있다.
- 대부분의 사용자에 대해서는 푸시 모델을 사용한다. 피드를 빠르게 가져오는 일이 상당히 중요하기 때문이다. (점점 로딩 시간을 견디기 힘들어하는 사람들이 많아지고 있다.^^)
- 유명인, 그러니까 핫 키 문제의 주인공이 되는 사용자는 푸시 모델에서 제외한다.
- 대신 그런 사람들의 포스팅은 풀 모델을 사용해서 가져오도록 한다.
그림으로 표현하면 다음과 같다. 시간은 왼쪽에서 오른쪽으로 흐른다.
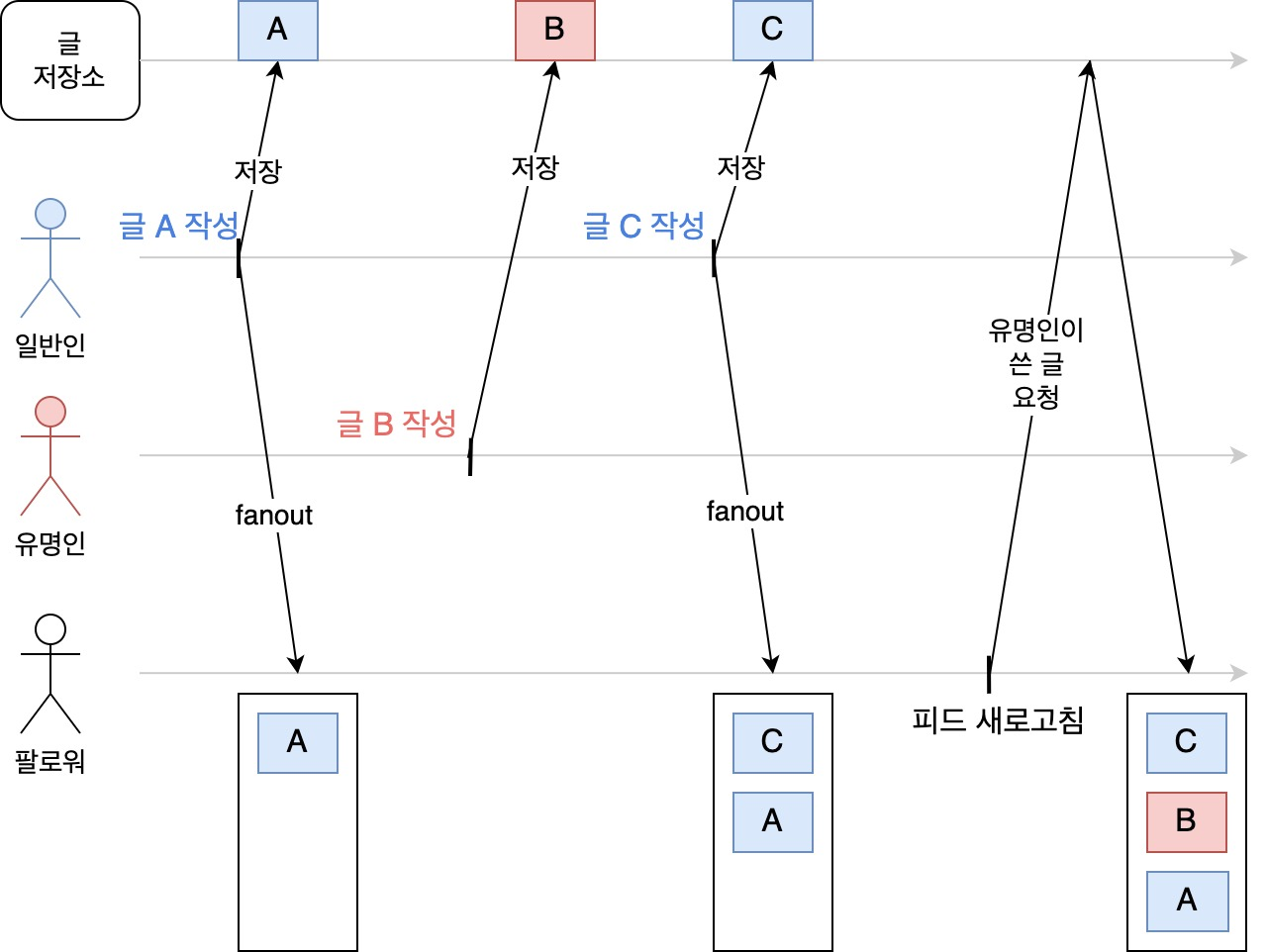
일반인 1과 유명인 1을 모두 팔로우하고 있는 팔로워 1명이 있다고 하자. 가장 아랫줄에 있는 흰색 네모가 팔로워가 보는 피드다. 일반인 1이 글 A를 쓰면 해당 글을 글 저장소로 저장함과 동시에 팔로워의 피드에도 저장된다. 일반인의 글은 푸시 모델의 대상이 되기 때문이다. 일반인 1이 적은 글 C도 마찬가지다.
반면 유명인 1이 적은 글 B는 팔로워의 피드에 곧바로 전파되지 않는다. 대신 글 저장소에 저장만 된다. 그러면 글 B는 언제 팔로워에게 보여지게 될까? 바로 팔로워가 피드를 새로고침 했을 때다. 새로고침을 하면 팔로워의 친구 목록에 유명인, 즉 풀 모델의 대상이 되는 사람이 있는지 확인하고 글 저장소에 그 사람들의 글을 요청한다. 그 다음 그 글을 피드에 적절히 추가한다. 위 그림에서는 피드를 최신순으로 나열하는 경우를 표현한 것이다.
추가로 고려할 점
웹 서버의 역할
웹서버는 사용자의 게시글 생성 요청을 받았을 때, 다음과 같은 일을 수행해야 한다.
- 인증: 올바른 인증 토큰을 갖고 API를 호출한 사용자인지 확인
- 처리율 제한: 스팸, 트래픽 공격 등을 막기 위해 특정 기간동안 한 사용자가 올릴 수 있는 포스팅 수 제한
글 저장, 글 전송, 알림
새로운 글 1개에 대해 위 3가지 이벤트가 모두 일어나야 한다. 사용자가 적은 글을 저장해야 하고, 그 글을 친구 목록에 있는 다른 사용자에게 전파해서 그들의 피드에도 새 글을 저장해야 한다. 물론 새 글 전체를 중복으로 저장하는건 너무 용량을 많이 먹기 때문에 메타데이터만 저장할 것이다. 마지막으로 새 글이 올라왔다는 알림도 보내면 된다.
그래프 데이터베이스
그래프 데이터베이스 데이터를 마치 그래프처럼 관리하는 DB다. 노드와 엣지, 프로퍼티로 구성된다. 각 데이터간의 관계를 저장하기 좋은 데이터베이스의 일종이다. 따라서 친구 관계 관리, 친구 추천 등을 구현하는데 유용하게 쓰인다. 피드 시스템에서는 풀 모델, 푸시 모델에서 ‘친구 목록'을 불러올 때 이 DB에서 가져오게 된다.
캐시와 메세지 큐
이 둘은 모두 속도를 높이기 위해 사용된다. 캐시를 한 군데만 두는게 아니라 여러 계층으로도 둘 수 있다. 책에서 제시한 방법은 캐시를 5계층으로 나눈다: 피드의 ID를 보관하는 피드 계층, 포스팅 데이터를 보관하는 콘텐츠 계층, 사용자 간 관계 정보를 보관하는 소셜 그래프, 포스팅에 대한 좋아요, 답글 등 행동을 저장하는 행동 계층, 마지막으로 좋아요, 응답, 팔로어 수 등을 저장하는 횟수 계층이다. 캐시의 일종으로 CDN을 사용할 수도 있다.
