
🔍 정규화란 ?
정규화(Normalization)의 기본 목표는 테이블 간에 중복된 데이타를 허용하지 않는다는 것이다.
중복된 데이터를 허용하지 않음으로써 무결성(Integrity)를 유지할 수 있으며, DB의 저장 용량 역시 줄일 수 있다.
🔍 제 1 정규화
만약에 체육관에서 체육관 등록한 사람들에 대한 데이터베이스를 만든다고 가정해보자.
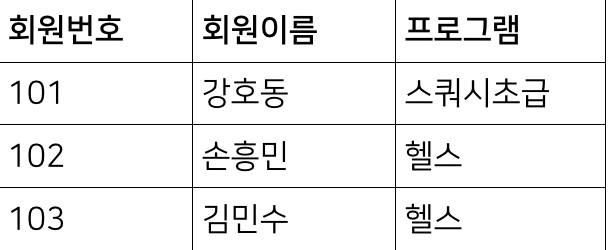
하지만 여기서 김민수라는 사람이 헬스가 아닌 골프를 추가적으로 등록했다고 한다면 데이터를 어떻게 추가해야하는가?

이런식으로 하나의 열에 여러개의 데이터를 넣어서 저장할수도 있겠지만, 이렇게 된다면 성능 이슈가 발생할 수 있다.
데이터를 찾기위한 쿼리문도 상당히 복잡해지고 배열로 저장한다고 하더라도, 배열에서는 일부만 수정하는것이 불가능하기 때문이다.

데이터를 새롭게 저장한다면 위의 사진처럼 똑같은 사람이더라도, 새롭게 행을 만들어주는것이 낫다.
이런식으로 하나의 행엔 하나의 데이터만 갖도록 하는것이 제 1 정규화다.
🔍 제 2 정규화
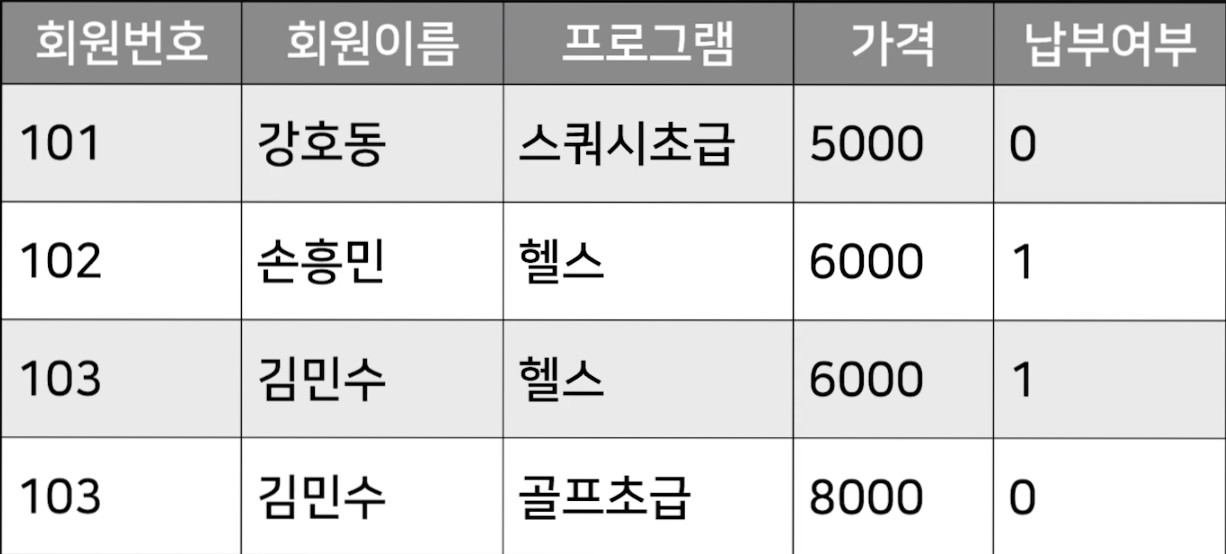
위와 똑같이 수강 등록 현황에 대한 데이터베이스를 만든다고 가정해보자.
헬스를 등록한 회원이 100명이고, 저 데이터베이스에서 헬스에 대한 가격이 8000원으로 변경 됐다면?
일일이 헬스를 등록한 회원을 찾아서 가격을 8000원으로 다 고쳐줘야한다.
이럴때 필요한게 제 2 정규화 작업이다.
제 2 정규화는 현재 테이블과 관련 없는 컬럼을 다른 테이블로 빼는것을 의미한다.
위의 표에서는 회원 등록 테이블이기때문에 저기서 프로그램의 가격 컬럼은 필요하지가 않다.
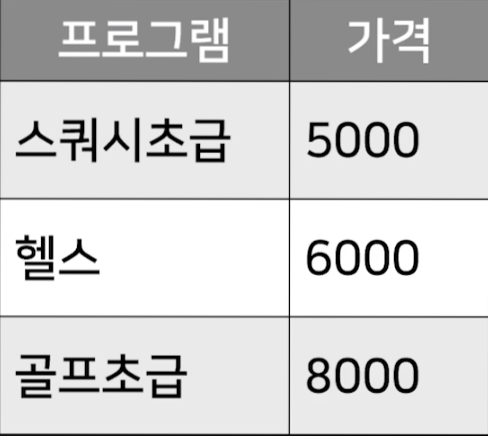
이런식으로 프로그램에 관한 테이블을 하나 더 만들어주는 것이다.
제 2 정규화는
- 1정규형을 만족해야 한다.
- 모든 컬럼이 부분적 종속(Partial Dependency)이 없어야 한다. == 모든 칼럼이 완전 함수 종속을 만족해야 한다.
🔍 Partial Dependency 란?
composite primary key 중에서 하나의 컬럼에만 종속되어 있는 컬럼을 partial dependency라고 표현한다.
🔍 composite primary key 란?

primary key 는 각각의 행들을 서로 구분할수 있는 유니크한 데이터를 갖고있는 컬럼이다.
하지만 위의 사진은 각각 다 중복되는 데이터가 있으므로, 모든 컬럼이 primary key 역할을 하지 못한다.
하지만 회원번호 + 프로그램의 컬럼을 합친다면 primary key의 역할이 가능한데, 이처럼 여러개의 컬럼(갯수 상관없음)을 합쳐서 primary key 역할을 할수 있는 것을 composite primary key 라고 한다.
다시 partial dependency 에 대한 설명으로 돌아가자면, 위의 사진으로 예를 들어서 가격은 프로그램에는 종속성이 있지만, 회원번호에는 종속되지 않는다. 이럴때 가격은 프로그램 컬럼에 Partial dependency 가 있다고 표현한다.
🔍 제 3 정규화란?
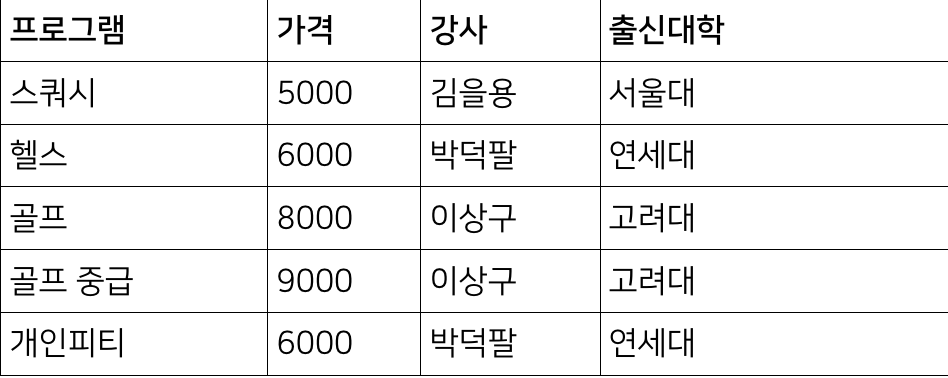
위의 사진은 Partial dependency 가 없으므로 제 2정규화를 만족한다. (프로그램 자체가 Primary key 이기 때문)
하지만 출신대학 컬럼은 강사 컬럼에만 종속되어있는데, 이럴때 강사와 출신대학을 따로 테이블로 빼면 제3 정규화를 만족한다.
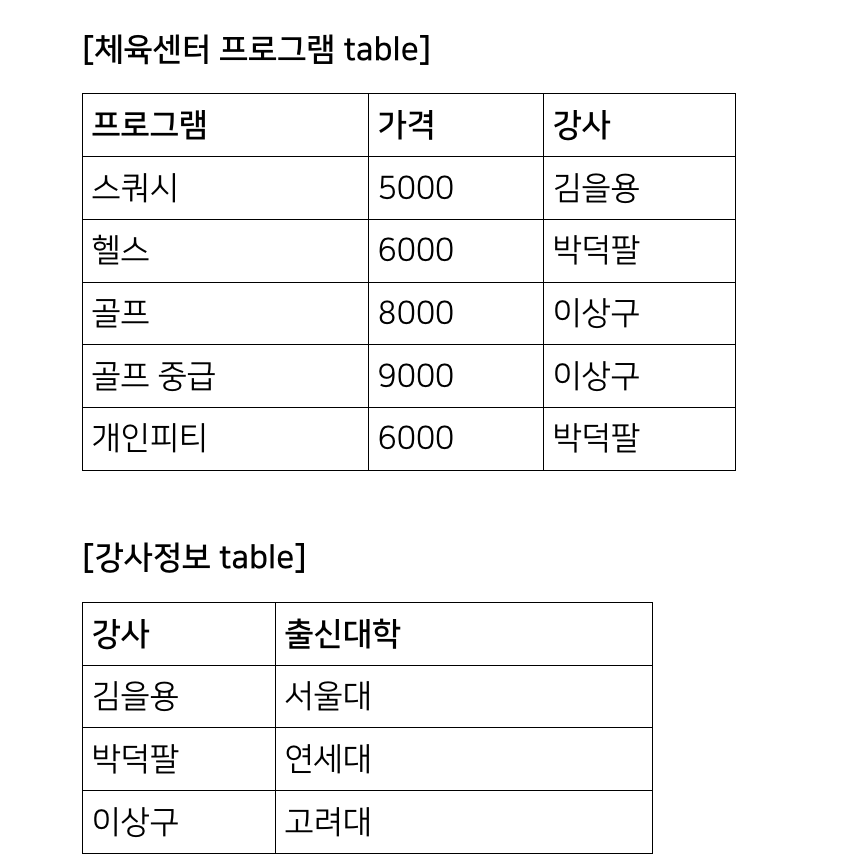
이런식으로 테이블 2개를 만들어 놓는다면, 박덕팔 강사의 학력이 만약에 변경됐다고하더라도, 강사정보테이블에서 변경만 해주면 되는거기때문에 효율성을 높일 수 있다.
제 3 정규화는
- 2 정규형을 만족해야 한다.
- 기본키를 제외한 속성들 간의 이행 종속성 (Transitive Dependency)이 없어야 한다.
🔍 Transitive Dependency 란?
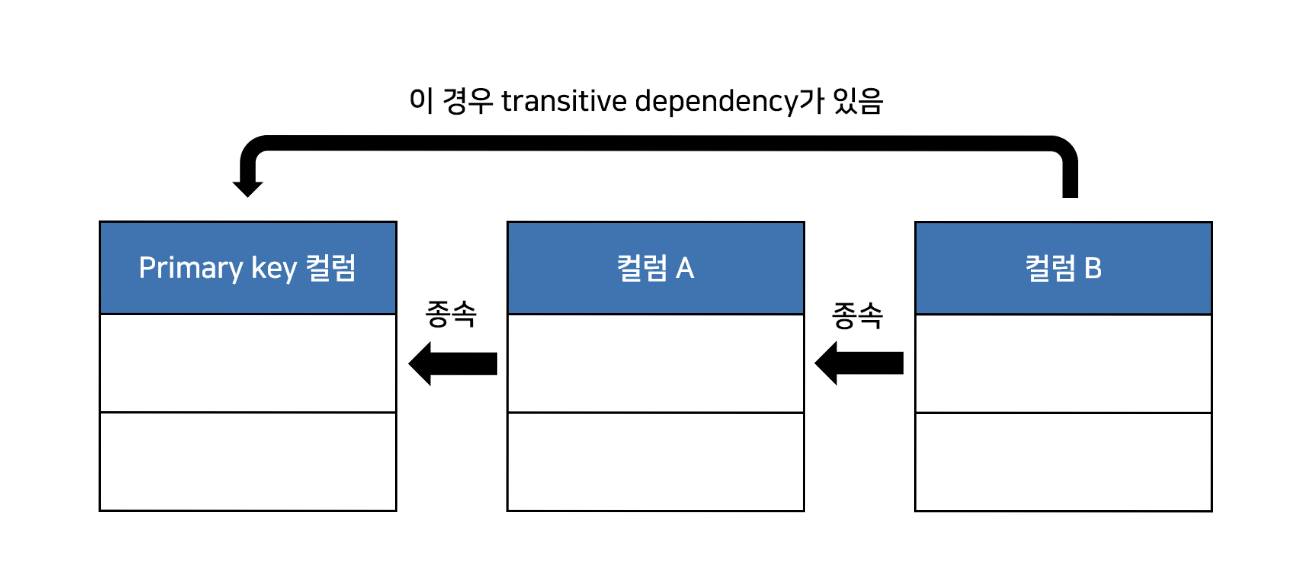
이처럼 Primary 컬럼이 하나 있고, 컬럼 A, 컬럼 B가 있는데 컬럼 B가 컬럼 A에 종속될때
transitive dependency가 있다고 표현한다.
🔍 정규화 할때 유의점
1. 테이블을 만들때 첫 컬럼은 항상 Primary Key를 넣어주는것이 좋다.
2. 다른 테이블의 데이터 사용시 해당 테이블의 Primary key를 적을 수 있다면 적는것이 좋다.
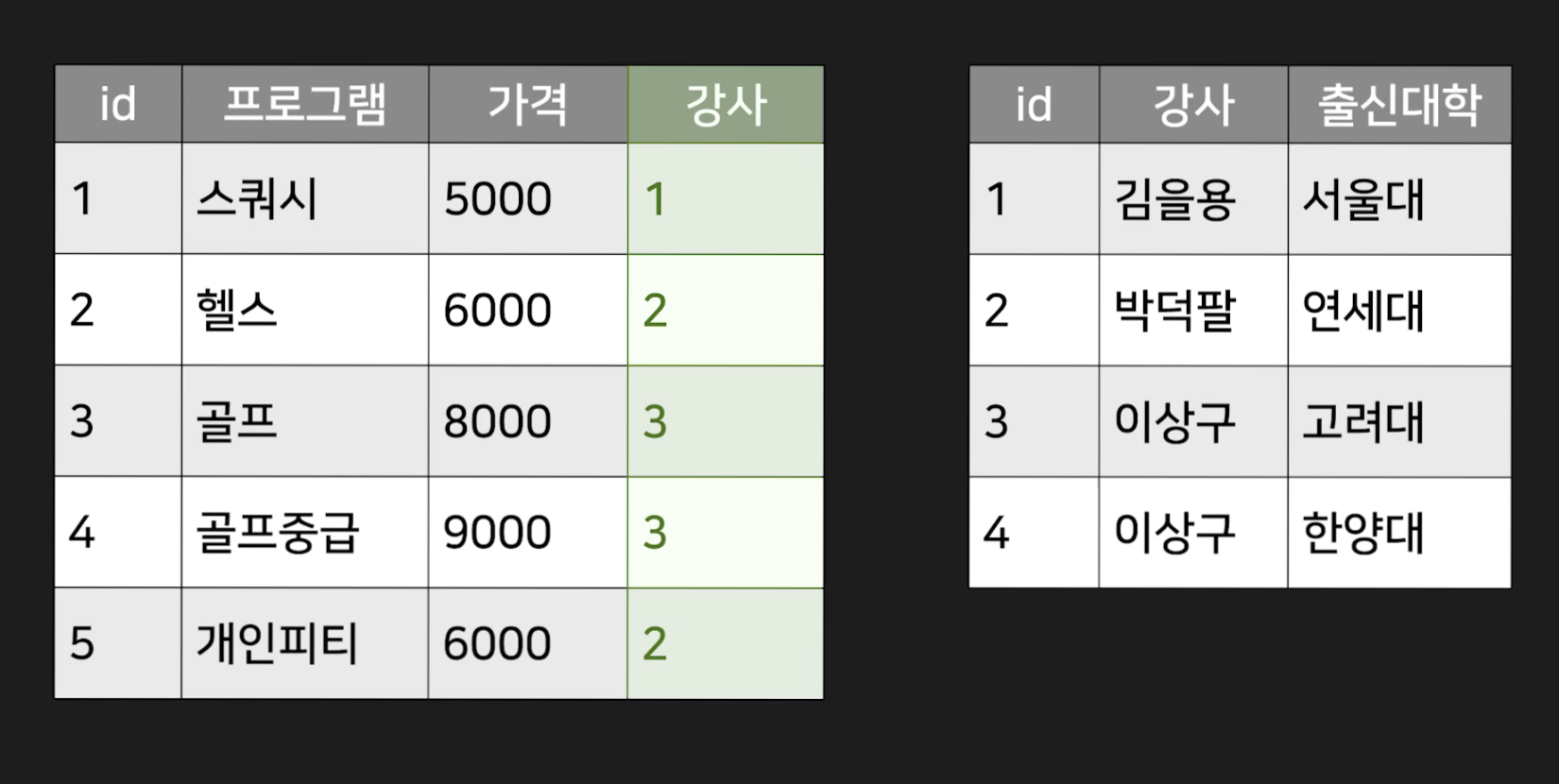
강사 테이블에 있는것처럼, 이상구라는 동명이인의 강사 데이터가 추가 됐다고 했을때,
프로그램 테이블에서 강사 이름을 그대로 적는다면 어떤 학교의 강사인지 알 수없다.
그렇기 때문에 해당 테이블의 Primary key 를 적어주는것이 좋다.
그리고 다른 테이블의 Primary key를 해당 테이블에서 사용할때, 그 Primary key를 해당 테이블에선 Foreign key 라고 부른다.
위의 사진에서는 강사 테이블의 id (강사 테이블의 Primary key)가 프로그램 테이블에서 Foreign key가 되는 것이다.
