
JPA에서 테이블 간 연관 관계는 객체의 참조를 통해 이뤄집니다. 서비스가 커질수록, 참조하는 객체가 많아지고, 객체가 가지는 데이터의 양이 많아집니다. 이렇게 객체가 커질수록, DB로부터 참조하는 객체들의 데이터까지 한꺼번에 가져오는 행동은 부담이 커집니다. 따라서 JPA는 참조하는 객체들의 데이터를 가져오는 시점을 정할 수 있는데, 이것을 Fetch Type이라고 합니다.
Fetch Type
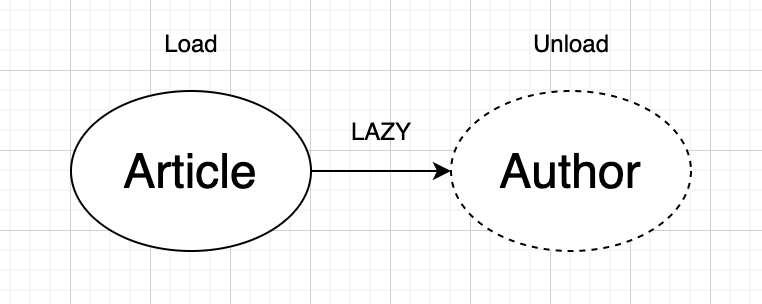
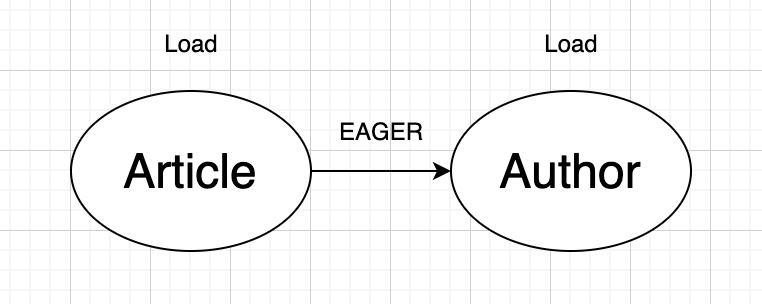
Fetch Type에는 두 가지가 있습니다.
- EAGER
- LAZY
EAGER는 성실한, 열심인 이라는 뜻을 가지고 있습니다. 말 그대로 데이터를 가져오는데 성실하죠. 하나의 객체를 DB로부터 읽어올 때 참조 객체들의 데이터까지 전부 읽어오는 방식을 뜻합니다. 반대로 LAZY 타입은 게을러서, 참조 객체들의 데이터들은 무시하고 해당 엔티티의 데이터만을 가져옵니다. 그렇다면 언제 어떤 방식을 써야 할까요?
EAGER의 장점?
EAGER는 언제나 한 번의 쿼리로 모든 정보를 가져옵니다. 반대로 LAZY는 참조객체의 데이터를 사용하기 위해서 여러 번의 쿼리를 사용할 수 있습니다. 따라서 참조 객체와 항상 함께 로드되어야 하는 조건을 가진 엔티티에 대해선 LAZY 방식보단 EAGER 방식이 더 좋습니다.
예를 들어 게시판의 글과 저자를 생각해봅시다.
Article.java
@NoArgsConstructor
@Getter @Setter
@Entity
public class Article {
@Id @GeneratedValue
@Column(name = "ARTICLE_ID")
private Long id;
private String content;
@ManyToOne
@JoinColumn(name = "AUTHOR_ID")
private Author author;
}Author.java
@NoArgsConstructor
@Getter @Setter
@Entity
public class Author {
@Id @GeneratedValue
@Column(name = "AUTHOR_ID")
private Long id;
private String name;
@OneToMany(mappedBy = "author", cascade = ALL)
private List<Article> articles = new ArrayList<>();
public void addArticle(Article article) {
articles.add(article);
article.setAuthor(this);
}
}(예제를 위한 Setter이므로 양해 부탁드립니다 😭)
게시글과 저자는 ManyToOne 양방향 연관 관계를 가지고 있습니다. 게시글을 불러올 때, 항상 저자의 이름과 함께 로드되어야 한다면, 서비스는 다음과 같은 순서로 수행될 것입니다.
Article findArticle = em.find(Article.class, article1.getId());
System.out.println("Author Name : " + findArticle.getAuthor().getName());
System.out.println("Article Content : " + findArticle.getContent());
쿼리문 결과는 다음과 같습니다.
- EAGER의 경우

- LAZY의 경우


EAGER의 경우 쿼리문이 한 번만 실행되지만, LAZY의 경우 2번의 쿼리문이 실행되므로 성능이 떨어진다고 볼 수 있습니다.
이래도 LAZY입니까?
사실 이러한 장점에도 불구하고 Fetch type은 항상 LAZY를 써야 하는 게 맞습니다. 다음 두 경우를 살펴봅시다.
참조가 많아지는 경우
Article의 참조가 많아진다면 어떻게 될까요?
 Article에 Favorite과 Comment 참조가 추가된 경우
Article을 가져올 때 알 수 없는 테이블들이 전부 join이 되어 등장합니다. 테이블 설계가 복잡해질수록, 하나의 엔티티가 참조하는 테이블들은 늘어날 테고, 그에 따른 쿼리문도 굉장히 길어지겠죠. 이런 복잡한 쿼리문을 본 개발자는 해당 도메인이 어떻게 설계되었는지 확인해보아야 하고, 논리적인 Layer 분리가 이뤄지지 않은 셈이 되죠. 이러한 부분은 유지 보수를 힘들게 만들 수 있습니다.
Article에 Favorite과 Comment 참조가 추가된 경우
Article을 가져올 때 알 수 없는 테이블들이 전부 join이 되어 등장합니다. 테이블 설계가 복잡해질수록, 하나의 엔티티가 참조하는 테이블들은 늘어날 테고, 그에 따른 쿼리문도 굉장히 길어지겠죠. 이런 복잡한 쿼리문을 본 개발자는 해당 도메인이 어떻게 설계되었는지 확인해보아야 하고, 논리적인 Layer 분리가 이뤄지지 않은 셈이 되죠. 이러한 부분은 유지 보수를 힘들게 만들 수 있습니다.
JPQL의 사용
만약 JPQL을 통해 Article을 전부 가져온다면 어떻게 될까요?
Article article1 = new Article();
article1.setContent("집사! 빵이 먹고싶어요.");
Article article2 = new Article();
article2.setContent("집산가요? 냠냠이는 어디있죠?");
Article article3 = new Article();
article3.setContent("이보게. 엉덩이좀 두들겨주게나");
Author author1 = new Author();
author1.setName("디디");
Author author2 = new Author();
author2.setName("루루");
Author author3 = new Author();
author3.setName("모모");위 처럼 3개의 저자가 각자 한 개의 글을 썼다고 가정해봅시다.
List findArticles = em.createQuery("select a from Article a")
.getResultList();위 JPQL 실행 시 발생하는 쿼리문은 다음과 같습니다.




하나의 JPQL 문에 대해 총 쿼리문이 4개나 실행됐습니다. 이를 N+1 Select Problem이라고 하죠. 하나의 Select 요청에 대한 Select문이 n개나 추가되는 현상을 의미합니다. 왜 이런 일이 발생할까요? 이는 Fetch Type이 EAGER인 경우, Article 내의 Author 참조에 대한 데이터를 모두 가져와야 하기 때문입니다. 그 결과 단순한 조회 쿼리 하나가 지나치게 많은 쿼리문을 수행하게 되어 성능 저하를 유발할 수 있습니다.
결론
아무리 단순한 구조의 설계라도, 시간이 지나면 변화되고 추가되기 마련입니다. 개발 과정에서 임시로 사용하는 게 아니라면, 항상 지연 로딩을 사용함으로써 성능 이슈가 발생할 가능성을 줄여주는 것이 좋습니다.

좋은 글이네요...!