텐서플로2를 공부하며 헷갈리는 개념이 있었다.
TFRecord라는 새로운 자료 구조와 함께 등장한 ProtoBuf(프로토콜 버퍼)이다.
공부하다보니 헷갈리고 어려워서 나름대로 정리하다보니 이해할 수 있었다.
TFRecord의 장점
TFRecord는 구글의 Protocol Buffer의 포맷으로 파일을 저장하는 바이너리 데이타 포맷이다.
일반적으로 이미지 파일(JPG, PNG)등을 읽을때는 이미지 파일, 메타 데이터 등을 별도로 읽어야 해서 복잡하고 시간이 오래 걸린다. 또 매번 이미지 파일 포맷으로 읽어 디코딩하면 성능 저하가 발생한다.
그렇지만 TFRecord는 1) 코드 구현 시 디코딩 없이 바로 읽어오면 되므로 구현을 편리하게 해주고, 2) 따로 읽을 필요 없이 한 번에 레이블과 데이터를 읽어 간편하게 할 수 있다. 3) 바이너리 포맷이므로 파일 용량 역시 줄어들어 학습 속도에 개선을 이룰 수 있다.
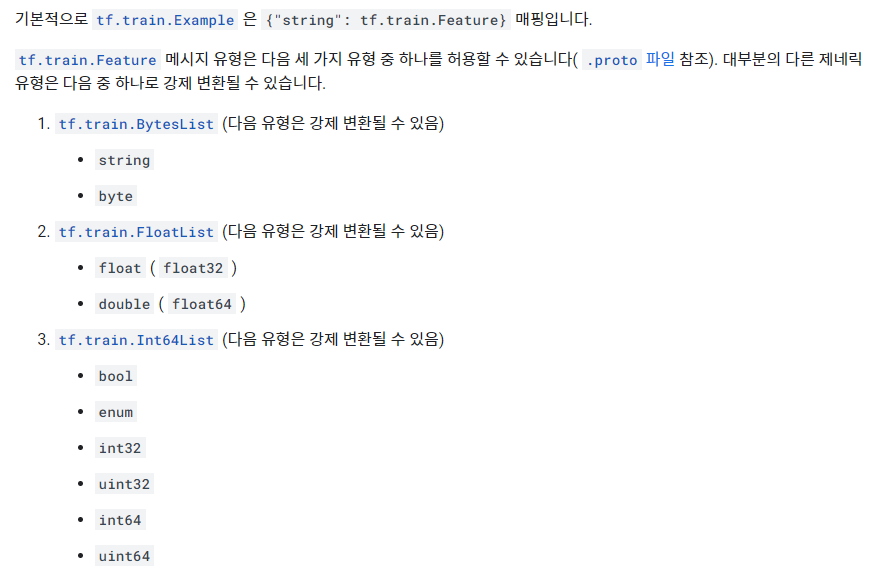
TFRecord 구조
파일 포맷은 .tfrecord이며, 구조는 다음과 같다.
syntax = "proto3";
message BytesList { repeated bytes value = 1; }
message FloatList { repeated float value = 1 [packed = true]; }
message Int64List { repeated int64 value = 1 [packed = true]; }
message Feature {
oneof kind {
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
message Features { map<string, Feature> feature = 1; };
message Example { Features features = 1; };출처 : rickiepark, https://github.com/rickiepark/handson-ml2/blob/master/13_loading_and_preprocessing_data.ipynb
하나하나 살펴보자.
가장 큰 구조형은 Example이다. 이는 하나의 Features를 가진다.
Features는 feature과 string이 매핑된 딕셔너리이다. 쉽게 말해서 feature에 이름을 붙인 것들을 모아서 가지고 있다.
Feature는 BytesList, FloatList, Int64List 중 하나를 담고 있는 특성 개체이다.
BytesList, FloatList, Int64List는 각각 Byte형, Float형, Int64형 데이터를 가질 수 있다는 것이다. [packed=true]는 반복적인 수치 필드에 사용된다.
즉 Example - Features 1개로 구성.
Features - feature : string (딕셔너리) 여러 개로 구성.
Feature - BytesList, FloatList, Int64List 중 하나로 구성됨.
왜 Example이라는 쓸데없는 객체를 만들었을까? 그 이유는 확장성 때문이다.
추후에 Example을 담는 무언가를 만들 수도 있기에 확장할 수 있는 여지를 남겨둔 것이다.
아래는 텐서플로우 공식 설명이다.
구현 코드
실제로 예시를 통해 구현해보자.
data_train, data_test = tf.keras.datasets.mnist.load_data()
(images_train, labels_train) = data_train
(images_test, labels_test) = data_test먼저 MNIST 데이터를 로드해준다. keras dataset에 잘 있으니 그대로 로드만 해주면 된다.
print(images_train.shape)
#(60000, 28, 28)
print(images_train[0].dtype)
#uint8
print(labels_train.shape)
#(60000,)
print(labels_train.dtype)
#uint8이제 자료형을 살펴보자. uint8로 저장된(즉 1바이트 정수, 이것이 중요하다.. int32로 잘못 변환해서 허송세월을 날렸다..) 자료형이니 복원도 uint8로 해줘야함을 알 수 있다.
def _bytes_feature(value):
"""Returns a bytes_list from a string / byte."""
if isinstance(value, type(tf.constant(0))):
value = value.numpy() # BytesList won't unpack a string from an EagerTensor.
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def _float_feature(value):
"""Returns a float_list from a float / double."""
return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))
def _int64_feature(value):
"""Returns an int64_list from a bool / enum / int / uint."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))Feature를 만드는 코드이다. 크게 이해가 되지 않는 부분은 없다(텐서플로 공식 홈페이지에 나와있는 코드이다). 처음에 _bytes_feature는 타입이 tf.int32와 같이 numpy가 아니라면 numpy로 바꿔준다.
TFRecord 저장
def make_example(image, label):
return Example(features=Features(feature={
"image": _bytes_feature(image),
"label": _int64_feature(label)
}))
def write_tfrecord(images, labels, filename):
writer = tf.io.TFRecordWriter(filename)
labels = labels.astype(np.int64)
for image, label in zip(images, labels):
example_tmp = make_example(image.tobytes(), label)
writer.write(example_tmp.SerializeToString())
writer.close()
write_tfrecord(images_train, labels_train, "mnist_train.tfrecord")
write_tfrecord(images_test, labels_test, "mnist_test.tfrecord")이제 본격적으로 TFRecord를 만들어보자.
먼저 make_example 함수에서는 image, label feature를 가진 Example을 반환한다.
write_tfrecord 함수는 image와 label의 리스트, 그리고 파일 이름 받아 .tfrecord 형식으로 저장한다. 여기서 make_example의 feature 타입에 맞게 label은 astype 함수로 np.int64로 변환했고 image 역시 tobytes 함수로 바이트 형태로 변환했다.
raw_dataset = tf.data.TFRecordDataset("mnist_train.tfrecord")
for raw_record in raw_dataset.take(1):
example = tf.train.Example()
example.ParseFromString(raw_record.numpy())
print(example)이제 잘 저장되었는지 확인해보자. 아래는 출력값이다. 원하는 대로 저장이 된 것 같다! 그렇다면 이제 TFRecord 파일을 불러와서 읽어보자.
feature {
key: "image"
value {
bytes_list {
value: "\000\000\000\000\000\000...\000\000"
}
}
}
feature {
key: "label"
value {
int64_list {
value: 5
}
}
}
}
TFRecord 불러오기
def _parse_tfrecord(tfrecord):
feature_desc = {
"image": tf.io.FixedLenFeature([], tf.string),
"label": tf.io.FixedLenFeature([], tf.int64)
}
x = tf.io.parse_single_example(tfrecord, feature_desc)
image = tf.reshape(tf.io.decode_raw(x["image"], tf.uint8), [28, 28])
label = x["label"]
return image, label먼저 한 Example씩 파싱하는 함수이다. 추후에 map 함수에 쓰기 위해 parse_single_example를 사용해서 하나씩 추출했다. 여기서 중요한 것은 image는 uint8로 decode하고, shape을 바꿔준 것이다.
def load_tfrecord_dataset(filename, batch_size=32, shuffle=True, buffer_size=10000, repeat=1):
mnist_dataset = tf.data.TFRecordDataset(filename)
mnist_dataset = mnist_dataset.repeat(repeat)
if shuffle:
mnist_dataset = mnist_dataset.shuffle(buffer_size=buffer_size)
parsed_mnist = mnist_dataset.map(_parse_tfrecord,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
parsed_mnist = parsed_mnist.batch(batch_size)
return parsed_mnist.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)이제 TFRecord 데이터셋을 로드하는 함수이다. 각 함수는 다음 단계로 진행된다.
TFRecordDataset : file명으로 데이터셋을 불러온다.
Repeat -> Shuffle -> Mapping(앞서 작성한 파싱 함수, 속도를 위해 병렬 호출한다)
-> Batch -> Prefetch 의 단계로 진행된다.
데이터 Plot
parsed_mnist = load_tfrecord_dataset("mnist_train.tfrecord")
for img, label in parsed_mnist.take(1):
plt.imshow(img[0])
plt.title(label[0].numpy())데이터가 잘 되는지 직접 로드하고 matplotlib으로 plot했다. Label의 경우 plt.title을 쓰기 위해 numpy로 변경해줬다(하지 않으면 TypeError: Cannot convert '' to EagerTensor of dtype int64가 뜬다).
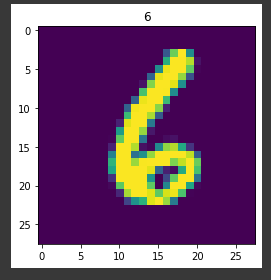
성공적이다! 예시 코드지만 추후 학습에 실제로 사용한다면 잘 작동할 것이다. 물론 audio, image(JPEG, PNG...) 등 다양한 파일에 맞춰 수정해야 하지만 기본적인 틀은 갖춘 것 같다.
후기
상당히 오래걸렸다.. 처음보는 자료 구조라 어렵기도 하고 코드 에러가 나는데 Stackoverflow에도 잘 나오지 않아서 끙끙댄 것 같다. 그렇지만 여러 블로그, github, 공식 홈페이지 코드를 참고하며 계속 생각해보니 마침내 짤 수 있었던 것 같다.
사실 그렇게 Deep하게 다룬 내용은 아니지만 뭔가 언젠가 많이 쓸 것 같기도 하고 찾아도 안 나오는 내용에 오기가 생겨서 더 열심히 한 것 같다. 결과적으로 뿌듯하니 된거다.
코드를 .ipynb 파일로 만들어 github에 올렸다. 내 첫 코드다! 신난다!
앞으로도 많이 작성해서 올려야겠다.
깔끔하게 작성된 코드는 제 Github에 있습니다.
https://github.com/YosepParkKAI/TFRecord_MNIST
Reference
https://www.tensorflow.org/tutorials/load_data/tfrecord?hl=ko
https://velog.io/@riverdeer/TFRecord-%ED%8C%8C%EC%9D%BC-%EC%9D%BD%EA%B3%A0-%EC%93%B0%EA%B8%B0
