1. 1차
1.1 🧾전처리
1.1.1 공공데이터의 범위가 너무 넓어서 서비스 지역을 2호선에 한정하고 그에 따른 전처리 진행
# 역 이름순으로 정렬
data = self.passengers.sort_values(by='역명') # = station_location.sort_values(by='역명')
# 사용할 호선인 2호선만 추출
line2 = data[data["노선명"] == "2호선"]
print(line2)1.1.2 y값 생성
-
원본 데이터에서는 승차총승객수와 하차총승객수만 나와있어서 y값으로 사용할 컬럼이 없는 상태이므로 각 일자별 승하차 변동을 나타내는 컬럼을 추가
for i, j in enumerate(data['승차총승객수']): if i != 0: on_rate.append(round((data['승차총승객수'][i] - data['승차총승객수'][i-1])/data['승차총승객수'][i-1]*100, 2)) off_rate.append(round((data['하차총승객수'][i] - data['하차총승객수'][i-1])/data['하차총승객수'][i-1]*100, 2)) else: on_rate.append(0) off_rate.append(0) else: pass df_on = pd.DataFrame(on_rate, columns=['승차변동(%)']) df_off = pd.DataFrame(off_rate, columns=['하차변동(%)']) df = pd.concat([data, df_on, df_off], axis=1) print(df) df.to_csv(path_or_buf=f"./data/rate/{k}역.csv", index=False) print(f"{k}역 저장 완료") on_rate.clear() off_rate.clear()1.1.2.1 전처리 과정에 역별로 csv파일을 분리하는 과정 추가
data = pd.read_csv('./data/sorted_subway.csv') meta = self.count_index() df_rows = [] # 역 이름별로 csv 파일 분리 for k in meta: for i, j in enumerate(data['역명']): if j == k: df_rows.append(data.loc[i]) else: pass df = pd.DataFrame(df_rows, columns=['사용일자', '역명', '승차총승객수', '하차총승객수']) df.to_csv(path_or_buf=f"{k}역.csv", index=False) print(f"{k}역 저장 완료") df_rows.clear()1.1.2.2 역별 csv로 변경한 이후 아래 코드로 y값 생성
meta = self.count_index() on_rate = [] off_rate = [] for k in meta: data = pd.read_csv(f'./data/save/{k}역.csv') for i, j in enumerate(data['승차총승객수']): if i != 0: on_rate.append(round((data['승차총승객수'][i] - data['승차총승객수'][i-1])/data['승차총승객수'][i-1]*100, 2)) off_rate.append(round((data['하차총승객수'][i] - data['하차총승객수'][i-1])/data['하차총승객수'][i-1]*100, 2)) else: on_rate.append(0) off_rate.append(0) else: pass df_on = pd.DataFrame(on_rate, columns=['승차변동(%)']) df_off = pd.DataFrame(off_rate, columns=['하차변동(%)']) df = pd.concat([data, df_on, df_off], axis=1) print(df) df.to_csv(path_or_buf=f"./data/rate/{k}역.csv", index=False) print(f"{k}역 저장 완료") on_rate.clear() off_rate.clear()1.1.2.3 분할 및 y값 생성 결과
-
전처리 이전
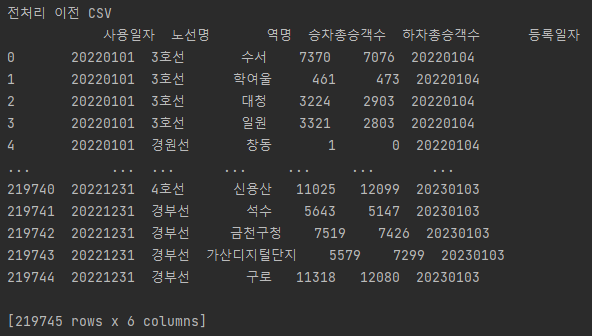
-
서비스 대상 지역 축소
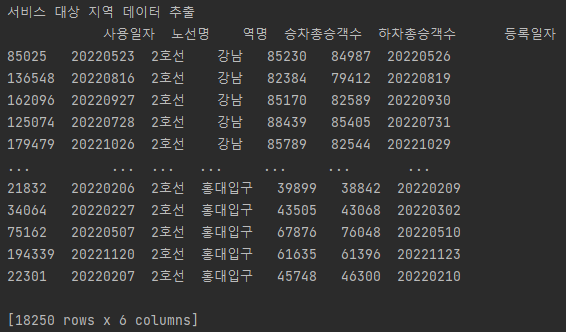
-
각 역별 csv 생성
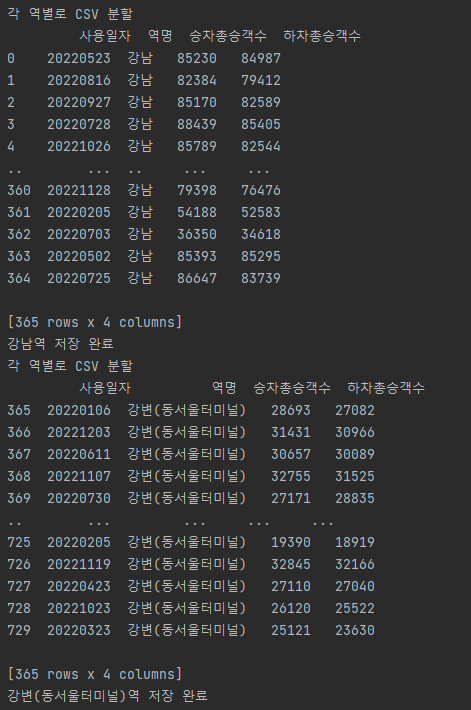
-
y값인 승하차 승객수 변동 컬럼 추가
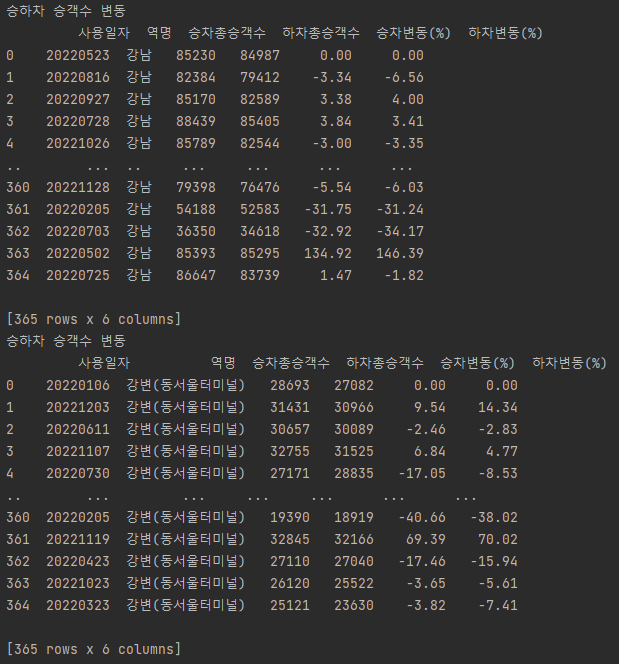
1.1.3 Min Max Scale
numerator = data - np.min(data, 0)
denominator = np.max(data, 0) - np.min(data, 0)
return numerator / (denominator + 1e-7) # 0으로 나누는 에러가 발생을 막기 위해 매우 작은 값(1e-7)을 더해서 나눈다
df = pd.read_csv('./data/rate/강남역.csv')
dfx = df[['사용일자', '승차총승객수', '하차총승객수']]
dfx = self.min_max_scaler(dfx)
dfy = df[['승차변동(%)']]
print(f'dfx : {dfx.head()}')
print(f'0~1 : {dfx.describe()}')
print(f'y : {dfy}') 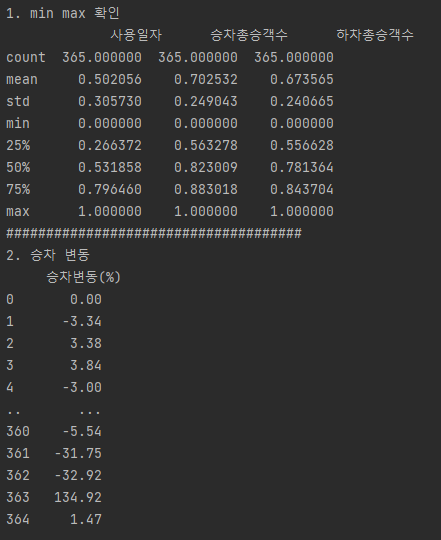
1.2 모델 생성
-
계획 : 각 역별로 일별 승하차총승객수를 바탕으로 하차총승객수를 예측한다
import gmaps import keras import pandas as pd import numpy as np from keras import Sequential from keras.layers import Dropout, LSTM, Dense from matplotlib import pyplot as plt from preprocess import Preprocess
class Forecast_model():
def init(self):
pass
def model(self):
meta = Preprocess()
for k in meta.count_index():
df = pd.read_csv(f'./data/rate/{k}역.csv')
dfx = df[['사용일자', '승차총승객수', '하차총승객수']]
dfx = meta.min_max_scaler(dfx)
dfy = df[['하차변동(%)']]
print(f'1. min max 확인')
print(dfx.describe())
print('#####################################')
print('2. 하차 변동')
print(dfy)
X = dfx.values.tolist()
y = dfy.values.tolist()
window_size = 10
data_X = []
data_y = []
for i in range(len(y) - window_size):
_X = X[i: i + window_size] # 다음 날 종가(i+windows_size)는 포함되지 않음
_y = y[i + window_size] # 다음 날 종가
data_X.append(_X)
data_y.append(_y)
print(_X, "->", _y)
print(data_X[0])
print('전체 데이터의 크기 :')
print(len(data_X), len(data_y))
train_size = int(len(data_y) * 0.7)
train_X = np.array(data_X[0: train_size])
train_y = np.array(data_y[0: train_size])
test_size = len(data_y) - train_size
test_X = np.array(data_X[train_size: len(data_X)])
test_y = np.array(data_y[train_size: len(data_y)])
print('훈련 데이터의 크기 :', train_X.shape, train_y.shape)
print('테스트 데이터의 크기 :', test_X.shape, test_y.shape)
model = Sequential()
model.add(LSTM(units=20, activation='relu', return_sequences=True, input_shape=(10, 3))) #!!!ValueError: Input 0 of layer "sequential" is incompatible with the layer: expected shape=(None, 10, 4), found shape=(None, 10, 3)
model.add(Dropout(0.1))
model.add(LSTM(units=20, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(units=1))
model.summary()
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(train_X, train_y, epochs=70, batch_size=30)
pred_y = model.predict(test_X)
plt.figure()
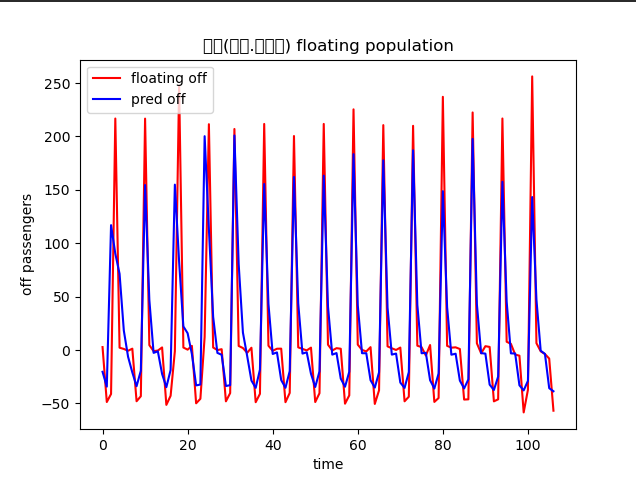
plt.plot(test_y, color='red', label='floating off')
plt.plot(pred_y, color='blue', label='pred off')
plt.title(f'{k} floating population', family='Malgun Gothic')
plt.xlabel('time')
plt.ylabel('off passengers')
plt.legend()
plt.show()
model.save(f'./model/{k}역_예측.h5') if name == 'main':
Forecast_model().model()
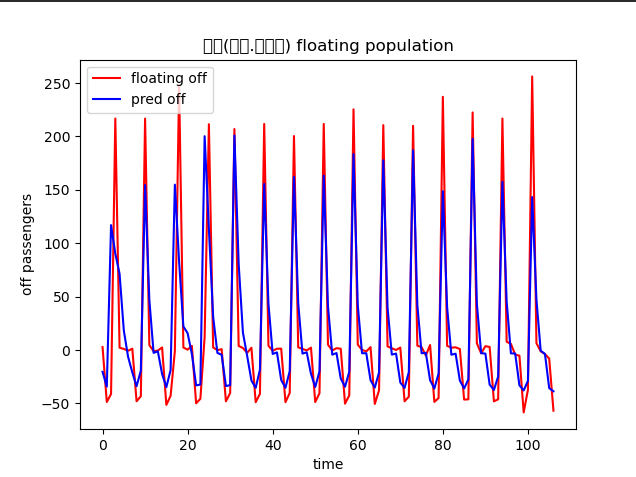
> ## 보완사항
각 역별로 모델을 만들고 같은 기간동안 지하철 승객 변동이 가장 심한 지역 위주로 지도에 나타내는게 기존의 계획이었으나 모든 역이 요일을 기준으로 거의 일정한 요동인구 변화를 나타내기 때문에 지하철을 이용한 승객 변화를 통해 학습한 모델의 메리트가 떨어진다.
>
> ## 대안
모든 역에 대한 수요예측 후 비교라는 초반의 방식을 버리고 하나의 역에 대한 작업 우선 진행
강남 하나만 집어서 날씨 등 다른 변수 추가 (2023-02-27)
# 2. 2차(날씨 추가)
## 2.1 전처리
- 이전 단계에서 사용한 데이터셋에는 변수가 너무 적기 때문에 하나의 역을 정해서 강수 여부를 추가import pandas as pd
class Weather():
def adding_y(self):
data = pd.read_csv('./data/rate/강남역.csv')
rain = pd.DataFrame(pd.read_csv('./data/extremum_20230306105846.csv', encoding= 'euc-kr')['일강수량(mm)'])
print(f'원본 인덱스 수 : {len(data.index)}')
print(f"강수량 인덱스 수 : {len(pd.read_csv('./data/extremum_20230306105846.csv', encoding= 'euc-kr').index)}")
rain_data = rain.rename(columns={'일강수량(mm)': '강수여부'})
add = []
for i in rain_data['강수여부']:
if i > 0.0:
add.append(i)
else:
add.append(i)
rain_add = pd.DataFrame(add, columns=['강수여부'])
df = pd.concat([data, rain_add], axis=1)
df.to_csv('./data/rain/강남역.csv')
## 2.2 학습
### 2.2.1 결과
- 서비스 항목인 우산과 비슷하게 날씨에 영향을 받는 상품의 수요 변화를 변수로 둘 필요가 있다
> **날씨 추가 후**
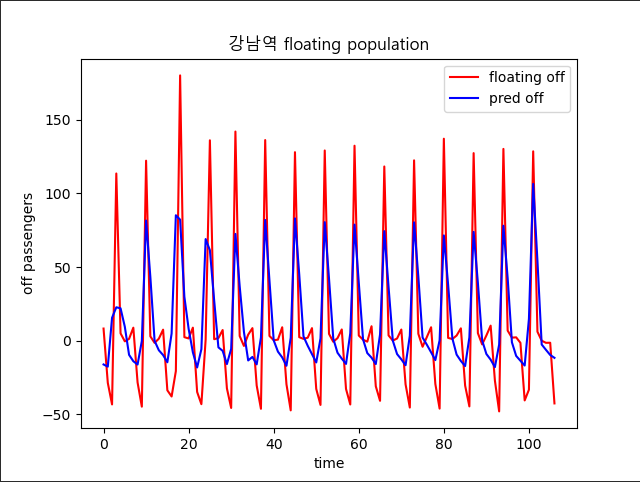
😅 다시 생각해보니 날씨가 지하철을 이용량에 영향을 미치지 않고 이걸 뽑아내더라도 우산 대여와 관련이 없다
---
# 3. 3차(따릉이 대여정보 추가)
## 3.1 전처리
> 우산과 수요가 반비례하는 따릉이의 자료를 가져오고 y값을 승하차 변동률이 아니라 따릉이 대여량으로 바꾸기 위해 전처리 과정을 거침'
### 3.1.1 서울역 승하차정보 추출
- 서울역의 역별 승하차 정보와 따릉이 대여소 위치정보 간의 연결이 가장 수월하기 때문에 강남역을 대상으로 한 이전 전처리 결과를 버리고 서울역으로 다시 진행
data = self.passengers.sort_values(by='역명') # 역 이름별로 정렬
data = data[data["노선명"] == "1호선"] # 호선만 반환
data = data[data["역명"] == "서울역"] # 서울역만 반환
print(sorted_csv.isnull().sum()) # 널 체크
sorted_data = data.sort_values(by='사용일자')
print(sorted_data)
sorted_data.to_csv(f"{self.save_dir}/sorted_서울역.csv", index=False)
### 3.1.2 따릉이 대여량 추출
> 1년치 따릉이 대여정보가 하루를 기준으로 적게는 5만에서 20만개의 데이터가 모여있어서 전처리가 필수
- 서울역 승하차 정보와 따릉이 대여량 join data = self.passengers.sort_values(by='역명') # 역 이름별로 정렬
data = data[data["노선명"] == "1호선"] # 호선만 반환
data = data[data["역명"] == "서울역"] # 서울역만 반환
print(sorted_csv.isnull().sum()) # 널 체크
sorted_data = data.sort_values(by='사용일자')
print(sorted_data)
sorted_data.to_csv(f"{self.save_dir}/sorted_서울역.csv", index=False)
ttareungi = pd.read_csv(f"{self.save_dir}/서울역_따릉이_대여량.csv")
ttareungi = ttareungi['따릉이 대여량']
join_df = pd.concat([sorted_data, ttareungi], axis=1)
join_df.to_csv(f"{self.save_dir}/ttareungi_서울역.csv", index=False)
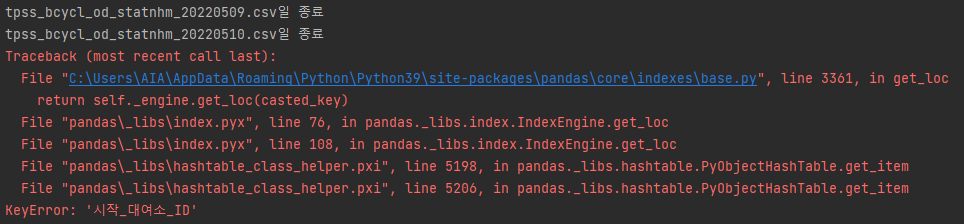
- 365개의 csv 파일 중 일부 파일의 메타데이터, 인코딩 방식이 일치하지 않아서 에러 발생
>앞의 코드 앞에 아래 코드 추가
>```
dirs = os.listdir('.\\data\\tpss')
for i in dirs: # 월
dir = os.listdir(f'.\\data\\tpss\\{i}')
for j in dir: # 일
try:
df = pd.read_csv(f'.\\data\\tpss\\{i}\\{j}', encoding='cp949')
if df.columns[2] != '시작_대여소_ID':
df.rename(columns={df.columns[2]: '시작_대여소_ID'}, inplace=True)
df.to_csv(f'.\\data\\tpss\\{i}\\{j}')
except UnicodeDecodeError as df:
df = pd.read_csv(f'.\\data\\tpss\\{i}\\{j}', encoding='utf8')
if df.columns[2] != '시작_대여소_ID':
df.rename(columns={df.columns[2]: '시작_대여소_ID'}, inplace=True)
df.to_csv(f'.\\data\\tpss\\{i}\\{j}')
print(f'{j}일 종료')
## 3.2 학습
### 3.2.1 결과
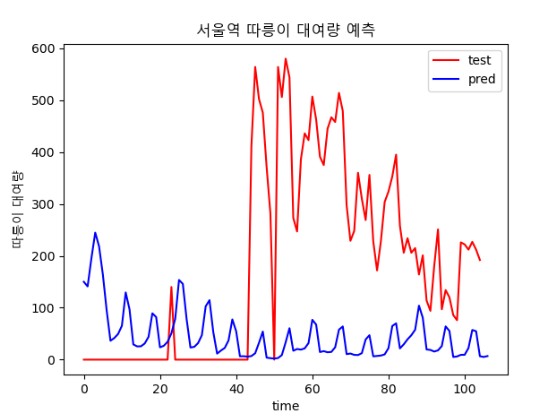
- epoch : 80
- epoch : 800
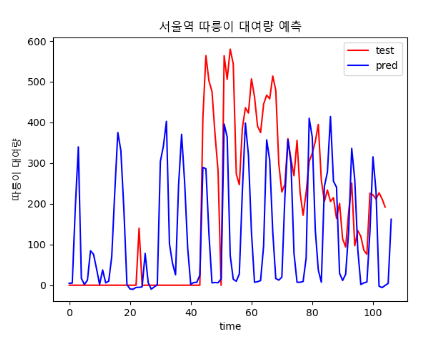
> 날씨 데이터가 빠진 채로 학습해서 그런거라고 생각된다
---
# 4. 4차(기온, 풍속 추가)
## 4.1 전처리
- 3차 시기의 데이터에 기온, 풍속 등 변수 추가
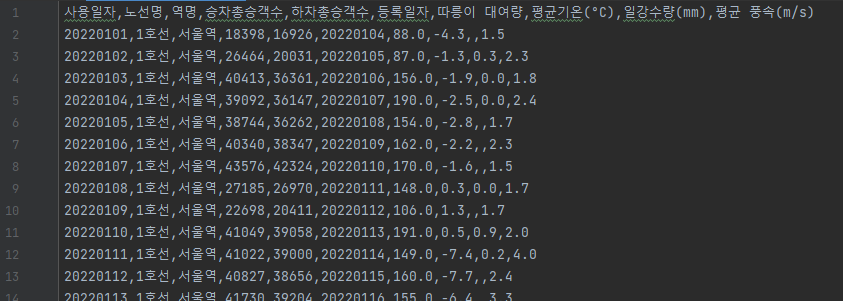
## 4.2 학습
### 4.2.1 결과
- 3차 시도 때보다는 loss가 감소했다
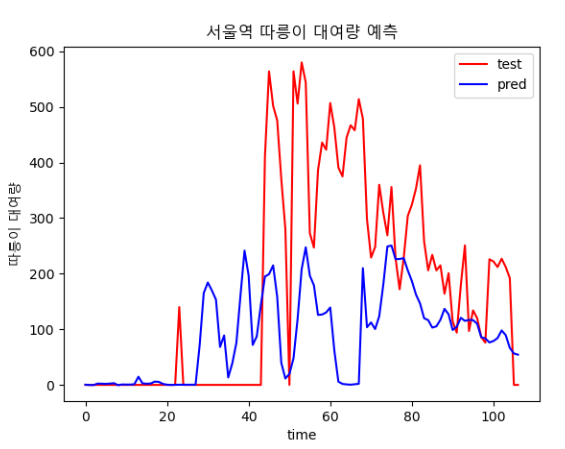
### 4.2.2 epoch, batch_size에 따른 결과 비교
- 400,30
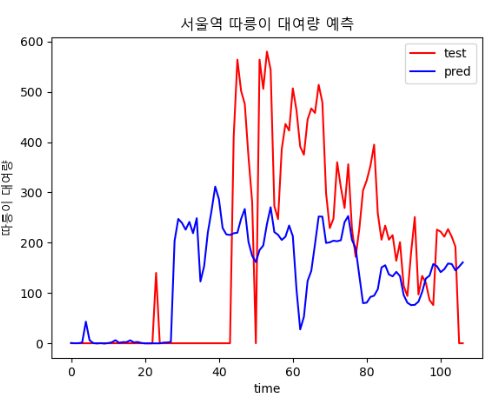
- 700,30
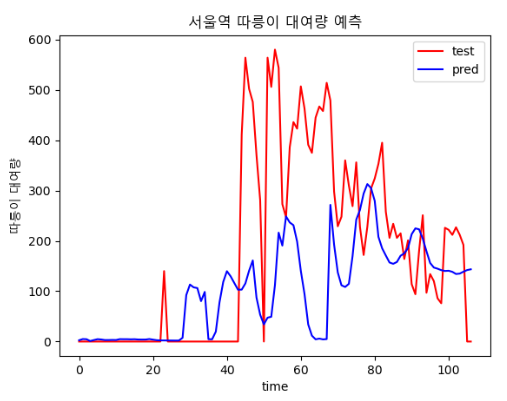
- 400,20
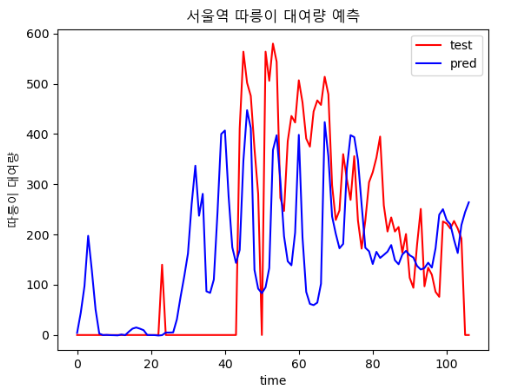
- 300, 20
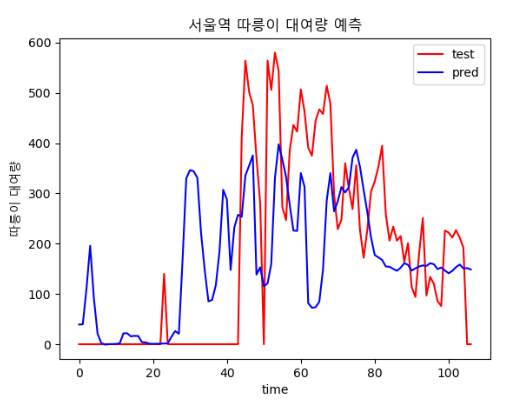
- 500, 20
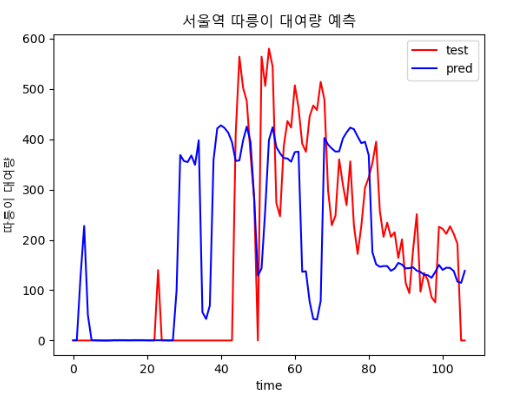
- 600, 12
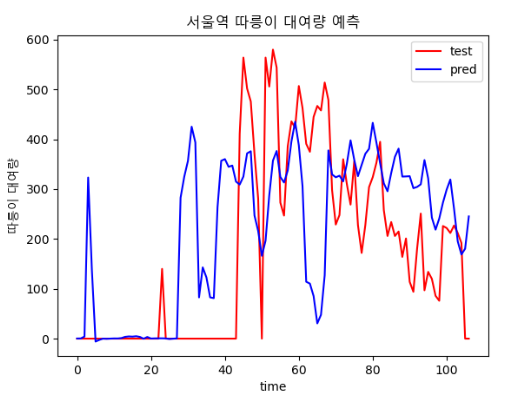
- 800, 15
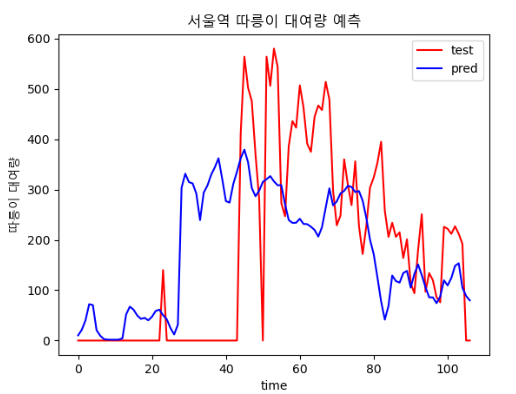
-4000, 64
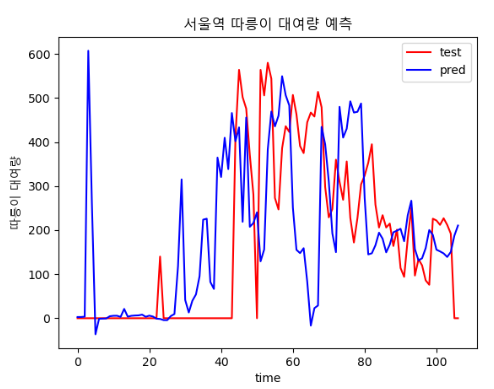
### 4.2.3 batch size
> 각 사이즈 테스트시 에포크는 1000
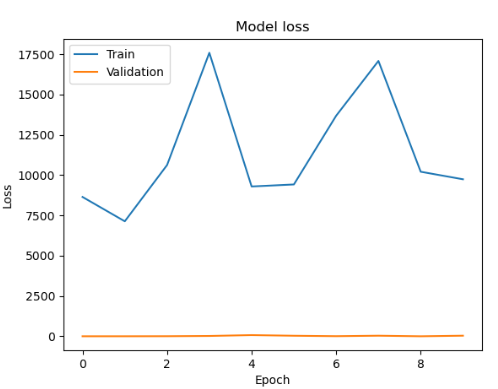
history = model.fit(train_X, train_y, batch_size=32, epochs=10, validation_split=0.2)
# 손실 그래프
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()
# 정확도 그래프
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
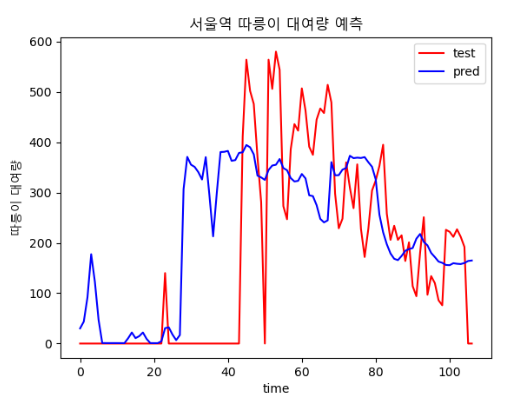
plt.legend(['Train', 'Validation'], loc='upper left')- batch : 64
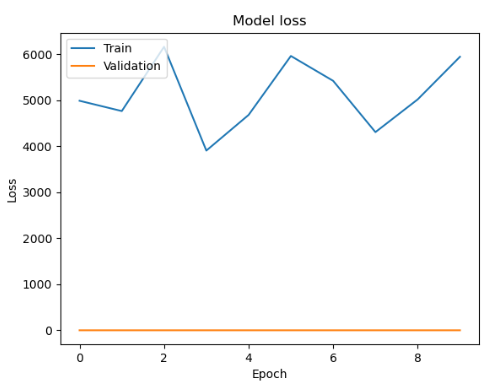
- batch : 30
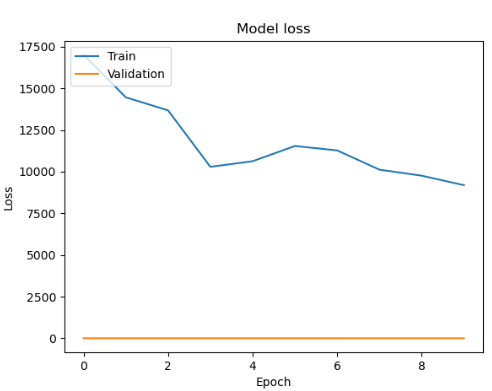
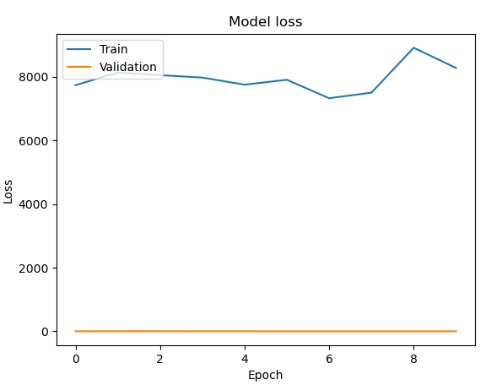
- batch : 20
- batch : 15
### 4.2.4 하나씩 찾아보기 힘들어졌다 한 번에 알아보자
batch_sizes = [비교할 batch 사이즈들]
losses = []
for batch_size in batch_sizes:
history = model.fit(train_X, train_y, epochs=10, batch_size=batch_size, verbose=0)
losses.append(history.history['loss'])
for i in range(len(batch_sizes)):
plt.plot(np.arange(1, 11), losses[i], label='batch_size=' + str(batch_sizes[i]))
plt.title('Model loss by batch size')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(loc='upper right')
plt.show()- 16 단위로 batch 사이즈 비교
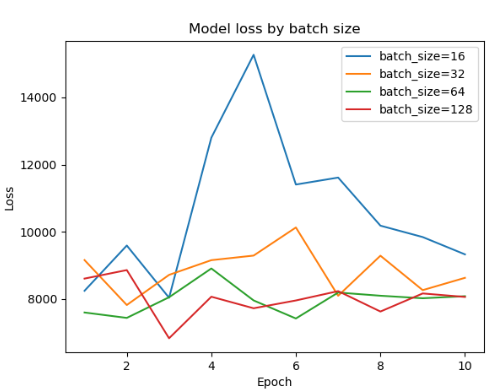
- 5 단위로 비교
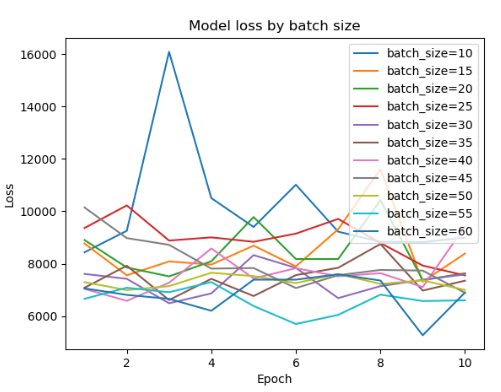
---
# ?. 에러😳
## ?.1 한글 깨짐
> 문제 발생지점에
```, family='Malgun Gothic'``` 추가
## ?.2 ValueError: Length of values (18200) dose not match length of index (18250)
>#### **원인**
> - 이전 일자와 비교해서 y값을 만들려고 했으나 i와 i+1의 역이름이 다른 지점들에서는 nall값이 발생
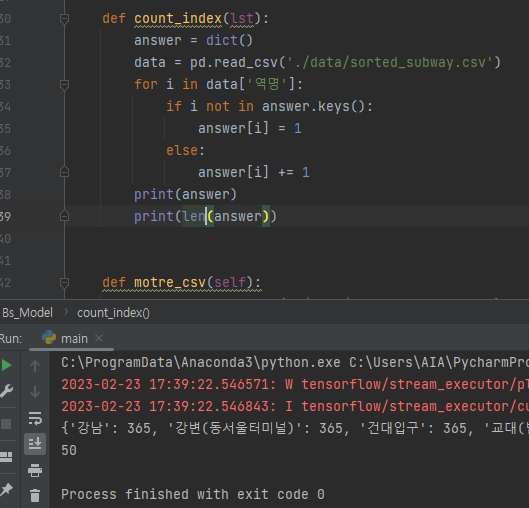
> - 정확히 역의 종류만큼 value의 길이가 줄어들었다는 것을 확인
> ---
> #### **계획 변경**
- 모든 역을 한 번에 비교하기보다 각 역별 이동인구 변동율을 예측하고 이를 비교하는 방향으로 변경
- 2.1.2에서 y값 추가시 인덱스의 길이가 맞지 않아 발생한 에러 해결
- 모든 역을 한 번에 비교할 경우 효율이 낮음
## ?.3
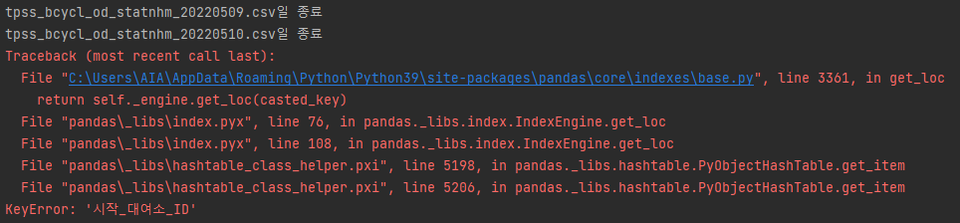
> 원인
365개의 csv 파일 중 일부 파일의 메타데이터, 인코딩 방식이 일치하지 않아서 에러 발생
> 해결
따로 정해진 방식은 없고 아래 코드를 통해 해결dirs = os.listdir('.\data\tpss')
for i in dirs: # 월
dir = os.listdir(f'.\data\tpss\{i}')
for j in dir: # 일
try:
df = pd.readcsv(f'.\data\tpss\{i}\{j}', encoding='cp949')
if df.columns[2] != '시작대여소ID':
df.rename(columns={df.columns[2]: '시작대여소ID'}, inplace=True)
df.to_csv(f'.\data\tpss\{i}\{j}')
except UnicodeDecodeError as df:
df = pd.read_csv(f'.\data\tpss\{i}\{j}', encoding='utf8')
if df.columns[2] != '시작대여소ID':
df.rename(columns={df.columns[2]: '시작대여소_ID'}, inplace=True)
df.to_csv(f'.\data\tpss\{i}\{j}')
print(f'{j}일 종료')
## ?.4 TypeError: numpy boolean subtract,
> 해결
MinMaxScale 과정에서 String값을 가지는 컬럼까지 포함돼서 발생한 문제로 int값만 사용될 수 있도록 바꿔준다
