Transfer learning을 사용하는 이유
https://www.tensorflow.org/tutorials/images/transfer_learning
일반적으로 딥러닝 모델을 제대로 훈련시키려면 많은 수의 데이터가 필요하다. 하지만 현실에서는 충분히 큰 데이터셋을 얻는 것은 쉽지 않은 일이다. 데이터를 얻는 일은 많은 비용이 발생하고 모든 개인, 기업이 이런 비용을 감당하는 일은 쉽지 않다. 또한 모델을 처음부터 학습하는 경우 매우 오랜시간 학습을 해야하는 경우가 빈번하게 일어난다. 이를 극복하기 위해 우리는 대규모 학습 데이터 기반으로 사전에 훈련된 모델(pre-trained model)을 활용할 수 있다.
이미지 분야내에서 바라보면 사전 훈련된 모델(pre-trained model)은 이전에 대규모 데이터셋에서 훈련되고 저장된 네트워크로, 일반적으로 대규모 이미지 분류 작업에서 훈련된 것이다. 사전 훈련된 모델을 그대로 사용하거나 전이 학습(Transfer learning)을 사용하여 이 모델을 주어진 작업으로 커스텀 할 수 있다.
이미지 분류를 위한 전이 학습을 직관적인 시각에서 바라보면 모델이 충분히 크고 일반적인 데이터 집합에서 훈련된다면, 이 모델은 사실상 시각 세계의 일반적인 모델로서 기능할 것이라는 점이다. 그런 다음 대규모 데이터셋에서 대규모 모델을 교육하여 처음부터 시작할 필요 없이 이러한 학습된 특징 맵을 활용할 수 있다.
모델을 fine-tuning 하는 방법
Pre-trained Model을 다음과 같은 형태로 사용될 수 있다.
1. Feature extraction
output layer만 새로운 문제에 맞게 수정하고 그대로 사용
2. pre-trained model 아키텍쳐 사용
아키텍쳐만 채용하고 weight는 initialize
3. 일부 layer만 training하고 나머지 layer는 고정
부분적으로 training 하는 방법. 보통 초기 layer (input에 가까운 layer)를 고정하고 상위 layer(output에 가까운 layer)를 training 하는 방법을 사용함.
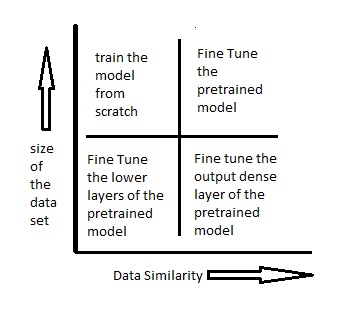
위의 diagram은 Pretrained model을 어떻게 활용해서 사용 할 수 있는지 아는데 도움을 줄 수 있다.
-
시나리오 1 – 데이터 세트의 크기는 작은 반면 데이터 유사성은 매우 높은 경우
이 경우 데이터 유사도가 매우 높기 때문에 모델을 재학습할 필요가 없다. 해야 할 일은 출력 레이어를 해당 문제에 맞게 수정하는 것이다. (softmax layer와 dense layer만 수정) 사전 훈련된 모델을 feature extrator로 사용한다. -
시나리오 2 - 데이터 크기가 작고 데이터 유사도가 매우 낮은 경우
이 경우 사전 훈련된 모델의 초기 layers 을 freeze하고 나머지 layers만 다시 훈련할 수 있다. 그런 다음 top layer는 새 데이터 세트에 맞게 커스텀 한다. 새 데이터 세트는 유사성이 낮기 때문에 새 데이터 세트에 따라 상위 layer(출력에 가까운 layer)를 다시 훈련하고 커스텀하는 것이 중요하다. 작은 크기의 데이터 세트는 초기 layer가 pretrained된 상태로 유지되고(이전에 큰 데이터 세트에서 훈련된) 해당 계층의 가중치가 고정됨을 의미한다. -
시나리오 3 - 데이터 세트의 크기는 크지만 데이터 유사성은 매우 낮은 경우
이 경우 데이터 세트가 크기 때문에 신경망 훈련 하는 것 자체가 효과적이다. 그러나 데이터는 사전 훈련된 모델을 훈련하는 데 사용된 데이터와 비교할 때 매우 다르기때문에 사전 훈련된 모델을 사용하여 만든 예측은 효과적이지 않다. 따라서 데이터에 따라 신경망을 처음부터 훈련하는 것이 가장 좋다. -
시나리오 4 – 데이터의 크기가 크고 데이터 유사도가 높은 경우
이상적인 상황. 이 경우 사전 훈련된 모델이 가장 효과적인 상황이라고 볼 수 있다. 모델을 사용하는 가장 좋은 방법은 모델의 아키텍처와 모델의 초기 가중치를 유지하는 것이다. 그런 다음 사전 훈련된 모델에서 초기화된 가중치를 사용하여 이 모델을 다시 훈련할 수 있다.

Wonderful post! We are linking to this great post on our website. Keep up the great writing.
https://infocampus.co.in/ui-development-training-in-bangalore.html
https://infocampus.co.in/web-development-training-in-bangalore.html
https://infocampus.co.in/mern-stack-training-in-bangalore.html
https://infocampus.co.in/reactjs-training-in-marathahalli-bangalore.html
https://infocampus.co.in/javascript-jquery-training-in-bangalore.html
https://infocampus.co.in/data-structure-algorithms-training-in-bangalore.html
https://infocampus.co.in/angularjs-training-in-bangalore.html
https://infocampus.co.in/
https://infocampus.co.in/mean-stack-development-training-in-banglore.html
https://infocampus.co.in/web-designing-training-in-bangalore.html
https://infocampus.co.in/front-end-development-course-in-bangalore.html