과제 및 학습 내용
- 커맨드라인에서 프로그램명 + 인자들을 받았을 때 이를 커널에서 어떻게 처리하고 어디에 전달할지를 학습하며 전체 흐름을 학습했다.
- 파일을 open, close하고 프로세스마다 연 파일들을 어떻게 관리하는지(파일 디스크립터 테이블을 통해, 상호 간에 수정하지 못하도록 lock을 걸면서) 학습할 수 있었다.
- 시스템콜을 처리하는 코드를 작성하면서 각 시스템콜들이 하는 일에 대해 학습할 수 있었다.
- 이에 대한 이해하기 위해 페이징 기법, 파일 관리, 가상 주소 공간 등을 학습했다.
코드에서 커널모드와 유저 모드
-
코드를 구현하면서 커널모드와 유저모드로의 전환과 그 사이에서의 데이터 이동에 대해서 이해할 수 있었다
-
pintOS에서는 저장할 스레드의 정보를 인터럽트 프레임이라는 구조체에 전달하고 여기에 전달해서 커널에서 유저프로그램으로 정보를 전달한다.
-
iret이라는 명령어가 중요했는데 과연 커널에서 유저 모드로 어떻게 갈까가 궁금했다. 답은 점프를 통해서이다.
- 주의해야 한다. 처음에 커널 쓰레드 따로 유저 쓰레드 따로 있는 것으로 이해하고 컨텍스트 스위치가 이루어지는 것으로 이해했는데 아무리 코드를 봐도 이에 대한 코드가 없어서 찾아보니
- 동일 쓰레드 내에서 가리키는 포인터가 바뀌면서 유저모드와 커널모드로 변환되는 것이다. (코드내에서는 rsp 포인터가 이동)
-
커맨드라인에 프로그램명과 인자들을 받았을 때 인터럽트 프레임(데이터 전달 매개체)에 이렇게 쌓았다.
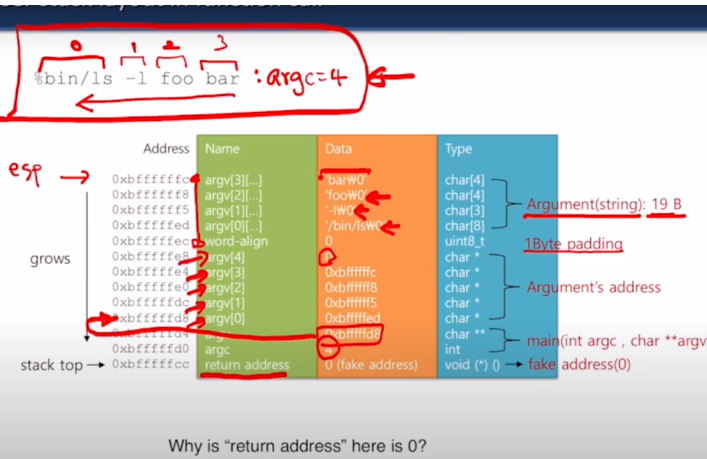 (사진 출처, 카이스트 핀토스 자료)
(사진 출처, 카이스트 핀토스 자료) - 인터럽트 프레임에 이미 쌓을 때 rsp가 UserProgram을 가리키고 있기 때문에 사실에 유저 프로그램에 해당 인자들을 쌓는 방식으로 진행된다.
- 처음에는 이 rsp가 상수 값으로 지정되어 있어, 유저마다 다른 주소를 가질 텐데 어떻게 이 상수로 고정이 되지? 했는데 커널에서도 virtual address를 쓰기 때문에 이를 상수 값으로 쓴다해도 각 유저 프로세스의 주소에 입력될 수 있다.
- 이를 실지 물리 주소로 변환해주는 것으 하드웨어가 해준다(MMU)
-
그리고 do_iret 코드를 보면
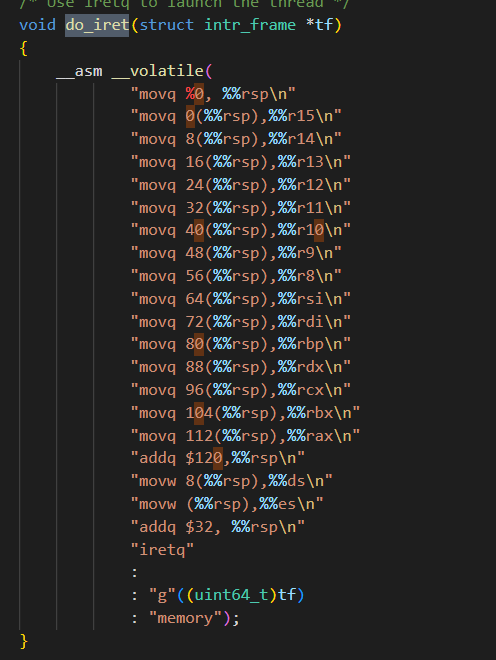 이렇게 rsp 기준으로 쌓은 값을 레지스터로 올린다. 그러면 이제 iret을 해서 유저 모드로 가게 되면 레지스터에도, 유저 스택에도 사용할 정보들이 쌓인 상태가 된다고 이해했다.
이렇게 rsp 기준으로 쌓은 값을 레지스터로 올린다. 그러면 이제 iret을 해서 유저 모드로 가게 되면 레지스터에도, 유저 스택에도 사용할 정보들이 쌓인 상태가 된다고 이해했다.
시스템콜
- 시스템 콜이 일어나면 어떻게 데이터가 교환되고 어떻게 시스템 콜 관련 함수가 처리되는지, 이를 처리한 커널 모드에서 어떻게 유저 모드로 전환되는지를 학습할 수 있었다.
예외 처리
- (출처: 반효경 교수님 강의) CPU는 한 줄의 인스트럭션을 실행 한후 Interrupt Line(인터럽트가 들어왔는지)체크한다. interrupt line 들어왔으면 하던 일을 멈추고 cpu의 제어권이 os한테 간다.
- (권영진 교수님 수업 정리-비공개 여기서 유저모드에서 커널 모드로 바꿔주는 것은 하드웨어. 포인터가 이동한다.
- 인터럽트 마다 왜 인터럽트가 걸렸는지 처리해야 할 일들이 운영체제 안에 커널 함수로 정의되어 있다. (pintOS에서 구현한 부분)
) - 어떤 커널 함수로 가야하는지에 대해선 예외 테이블을 참고한다. 시스템 부팅시에 운영체제는 예외 테이블을 할당하고 각 테이블에는 각 예외 사항에 대한 핸들러 코드의 주소가 있다.
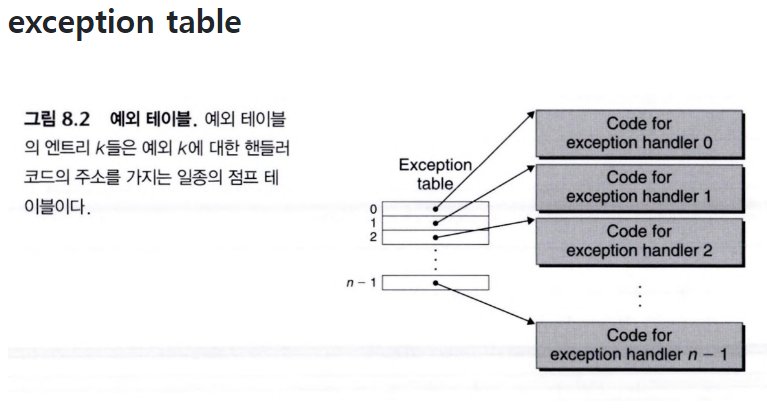
- 주의. 이 점프해서 커널 모드로 갔기 때문에 계속 아까 그 유저모드에서 사용된 쓰레드가 계속 동작하는 것이다.
- 핸들링이 끝나면 '하드웨어'가 인터럽트에 의해 중단된 프로세스로 돌아가는 경우가 있는데(아닌 경우도 있다) 어쨌든 이 경우에는 원래 프로세스 제어 상태와 데이터 레지스터 상태를 스택으로부터 팝해서 돌려준다. (우리가 인터럽트 프레임에 쌓아놓고 POP 하면서 돌려준 부분)
lock, Condition Variables Semaphore
- https://velog.io/@bongf/Pintos-lock-Condition-Variables-Semaphore
- OS 책: “Operating Systems: Three Easy Pieces” 과 권영진 교수님의 강의로 이론 학습 및, 코드를 작성하면서 이들이 어떻게 다르고 어떻게 사용할 수 있는지 학습했다.
- 특히, 위 링크에 작성하며 학습한 부분이 재밌었다. 쎄마포어 초기값에 따라서 lock으로도 동작할 수 있고 시그널을 받는 순서를 정하는 용도로도 사용할 수 있다는 것을 학습했다.
- [비공개][Operating Systems: Three Easy Pieces/ Project1: Threads - Priority Scheduling 책 정리 - Semaphore](https://velog.io/@bongf/Pintos-Priority-Scheduling-%EC%B1%85-%EC%A0%95%EB%A6%AC-Semaphore)
fork
- 다른 자료들을 긁어모아 정리해서, 비공개 https://velog.io/@bongf/PintOS-Usrprogrm-syscall-fork
- fork 후에 자식과 부모가 다른 pid 값을 가져야 하는데 어떻게 처리해줄까에 대한 고민을 했다.
- 이에 대한 해결방법을 중심으로 학습했다.
- 이를 인터럽트 프레임의 함수의 return값을 저장하는 rax 값에 해당 값을 넣어준다.
File Management
https://velog.io/@bongf/Pintos-File-Management
- 비공개
- 파일 디스크립터 테이블이 각 프로세스 마다 있고, 같은 파일이라해도 각 프로세스에 해당된 fd가 다르다.
- 단 이 fd에 의해 파일을 찾아올 때는 해당 파일 자체는 메모리에 동일공간에 올라가 있어서 (각 파일 디스크립터 테이블에 같은 주소가 써있다) 같은 파일이 여러 번 메모리에 올라가는 것을 막을 수 있다.
가상 메모리 주소 공간
- 다른 자료를 긁어 정리해 비공개
- virtual memeory를 사용하면서 왜 사용자마다 각기 주소공간을 가졌다고 착각할 수 있는지, 심지어 커널에서 쓰는 주소공간조차 가상 주소를 의미한다는 것을 코드를 작성하면서 알 수 있었다.
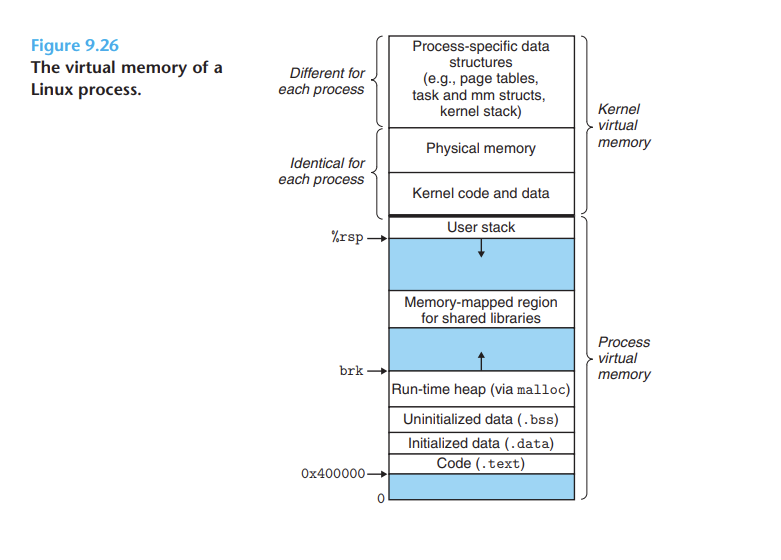 32비트 기준 4G의 주소공간을 가질 수 있는데 그래서 각 프로세스는 자신이 각각 4G의 주소공간을 가질 수 있다고 착각한다.
32비트 기준 4G의 주소공간을 가질 수 있는데 그래서 각 프로세스는 자신이 각각 4G의 주소공간을 가질 수 있다고 착각한다. - Kernel Virtual Memory 부분은 항상 메모리에 상주해야 한다. 그리고 이부분에 대한 데이터는 모든 프로세스마다 동일할 것이다. 그렇기 때문에 실제로 이부분에 대한 메모리는 공유 되어야 하기 때문에 이 부분에 대해서는 RAM과 일대일 매핑된다.
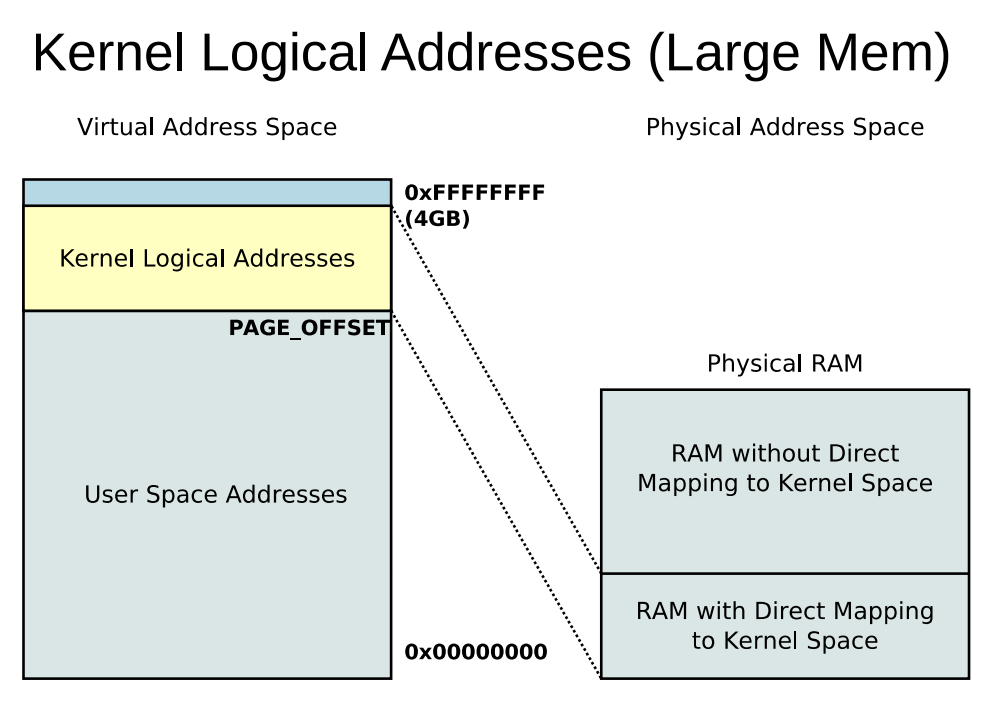 출처 https://elinux.org/images/4/4c/Ott.pdf
출처 https://elinux.org/images/4/4c/Ott.pdf - 그렇지만 각 프로세스는 각자 자신의 주소공간을 가진다고 착각
- RAM의 나머지 부분에 대해서는 모든 유저 프로세스 들의 공간에 대한 메모리가 다 올라간 것은 아니고 필요한 것이 메모리에 올라오고 내려오고 하면서 마치 각자가 저만큼의 주소공간을 갖도록 착각하게 하는 것이 Virtual Memory
- 이 주소변환을 해주는 것은 MMU라는 하드웨어! (빠르기 때문에 소프트웨어가 아닌 하드웨어 사용한다)
- 그렇다면 각 가상 주소공간이 같은 메모리를 참조할 때 이에 write를 하려고 하면 어떻게 될까? 이 때 쓰는 기법이 copy-on-write
- 둘이 읽을 때까지는 같은 공간을 참조(동일 데이터를 메모리에 두 번 올리는 것을 지연)
- 그러다가 write 요청이 오면 동일 데이터를 메모리에 복제해서 올림
세그먼트 페이징 기법
-
필요한 데이터만 메모리에 올리려면 필요한 기법이 페이징 기법과 세그먼트 기법
-
이에 대해 반효경 교수님 수업으로 정리 비공개
-
세그먼트 기법을 쓰면 권한 관리가 쉽다. 예를 들어 힙, 데이터, 코드 등으로 분할해서 올린다고 하면 해당 부분은 읽을 수 있다, 쓸 수 있다 이렇게 권한 확인이 용이하다.
-
그런데 세그먼트 기법을 쓰면 올리는 데이터의 단위가 달라지기 때문에 (힙, 데이터 각각의 크기가 다를 것) 메모리에 쭉 올리지 못하고 hole이 많이 발생하는 문제들이 생기게 된다.
-
페이징 기법으로 정량화된 페이지 단위로 올리면 이를 해결할 수 있지만 세그먼트 기법에서 활용할 수 있었던 의미별 권한 확인은 불가하다
- 또한 페이징 기법은 페이지가 각 어디에 있느지를 저장하는 페이지 테이블이 공간을 많이 차지한다.
-
세그먼트 페이징 기법은 있는데 이는 권영진 교수님의 강의(비공개로 정리했다.
추가 궁금했던
- 왜 BSS영역은 따로 둘까?
- 그냥 데이터 영역에 두면 될텐데 왜 따로 둘까 했는데 굳이 0이라는 값을 써줄 필요가 없다. BSS영역을 따로 두면 값이 없는 것이 보장 되므로. 그렇기 때문에 공간을 절약 할 수 있다. 또한, 날라가도 저장할 값이 없기 때문에 ROM에 있을 필요가 없어 이를 분리했다.
- https://velog.io/@bongf/Pintos-BSS-%EC%98%81%EC%97%AD
