🌞 Day 036
- SQL : Select...
🍂 데이터 수정의 예시 이어서…
-
emp 테이블의 ename이 j로 시작하는 사원의 job을 MANAGER로 변경
update emp set job='MANAGER' where ename like 'j%';
( j로 시작하는 이름 검색 )
update emp set job='MANAGER' where ename like '%j';
( j로 끝나는 이름 검색 )
update emp set job='MANAGER' where ename like '%j%';
( j를 포함하는 이름 검색 )-
like
: %를 사용할 때 = 대신 쓰는 코드, =을 쓰면 포함관계가 아니라 완전 일치하는지를 확인할 때 사용 -
% : wildcard 코드, 어떤 것이든 올 수 있는 자리
-
-
memberlist 테이블에서 bpoint가 200이 넘는 사람만 bpoint100으로 변경
update memberlist set bpoint=bpoint100 where bpoint>=200; -
rentlist 테이블에서 할인 금액이 100이 넘으면 모두 할인 금액을 90으로 변경
update rentlist set discount=90 where bpoint>=100;
🍂 레코드의 삭제
delete from 테이블명 where 조건식
(delete와 from 사이에 *표 넣지 않도록 조심)
delete from 테이블명
=> 모든 레코드 삭제됨
-
rentlist 테이블에서 discount가 100 이하 레코드를 삭제
delete from rentlist where discount<=100; -
where 절이 없으면 테이블 내의 모든 레코드를 삭제
삭제의 제한
delete from booklist where subject = '봉제인형 살인사건';
-
위 코드를 실행하면 ERROR
⇒ ORA-02292: integrity constraint (SCOTT.FK1) violated - child record found
⇒ ⬆ 에러 메시지 : 제약 조건 위배 자식 레코드 발견 -
봉제인형 살인사건 도서가 rentlist에 대여목록으로 존재하므로...
-
다르게 얘기하면 rentlist에 booknum레코드에 '봉제인형 살인사건' 도서의 booknum이 존재하므로...
-
외래키의 참조무결성에 위배된다 따라서 이 삭제 명령은 에러가 발생
-
해결방법 #1.
-
이를 해결하려면 우선 rentlist 테이블에 해당 도서 대여목록 레코드를 모두 삭제한 후
delete from rentlist where booknum=4;
(4는 '봉제인형 살인사건'의 booknum) -
booklist 테이블에서 해당 도서를 삭제한다.
delete from booklist where subject='봉제인형 살인사건';
or
delete from booklist where booknum=4;
-
-
해결방법 #2.
-
외래키 제약조건을 삭제한 후 다시 해당 상황에 맞게 다시 생성
-
생성시에 옵션을 추가해서 참조되는 값이 삭제되면 참조하는 값도 같이 삭제되게 구성한다.
-
다시 말해 parent record가 삭제되면 child record도 함께 삭제되도록 외래키를 다시 생성
- 외래키 삭제
alter table rentlist drop constraint fk1; - 새로운 외래키 생성
alter table rentlist add constraint fk1 foreign key(booknum) references booklist(booknum) on delete cascade;
-
on delete cascade
: booklist의 도서가 삭제되면 rentlist의 해당 도서 대여내역도 함께 삭제하는 옵션 -
on update cascade [ 오라클(X), MySQL (O) ]
: 부모레코드를 수정하면 자식레코드도 같이 수정되는 옵션
-
- memberlist테이블에서 회원 한 명을 삭제하면,
rentlist테이블에서도 해당 회원이 대여한 기록을 같이 삭제하도록
외래키 설정을 바꾸기(외래키 제약조건 삭제 후 재생성)

-
참조되는 값의 수정은 아직 적용되지 않는다.
-
booklist와 memberlist 테이블의 booknum, membernum은 수정이 아직 불가능하다.
-
이를 해결하기 위해서 외래키 설정시 on update cascade 옵션을 추가하면 될 듯하지만 오라클에서는 허용하지 않는다.
-
MySQL에서만 사용이 가능하며, 오라클에서는 뒷단원의 “트리커”를 공부하면서 외래키가 수정이 되도록 하는 것을 배움
🌱 SELECT (검색)
🍂 scott 사용자가 관리하고 있는 테이블 목록
select * from tab;
select * from tabs; (좀 더 상세한 정보 제공)
🍂 특정 테이블 구조 조회 (필드리스트/ 데이터 형식)
desc dept;
desc memberlist;
(위의 두 명령은 이클립스에서는 제공X 커멘드 창에서 sqlplus로 접속해서 사용)
-
SELECT
: select와 from 사이에 조회하고자 하는 필드명을 ,로 구분하여 지목
select booknum, subject, outprice from booklist; -
모든 필드를 한 번에 지목하려면 * 를 사용 : select * from
-
from 뒤에는 대상 테이블 이름을 써준다.
-
where 절을 붙여서 조건에 맞는 행만 골라내기도 한다.(행, 가로, 레코드)
select ... from ... where ... -
아래와 같이 연산식을 써서 연산된 결과를 필드로 조회하고자 할 땐 as와 함께 만들어진 필드명을 지어주기도 한다.
-
select empno || '-' || ename from emp;
empno || '-' || ename 가 출력화면에 필드명으로 그대로 뜸
select empno || '-' || ename as emp_info from emp;
emp_info는 임의로 지은 필드명 -
오라클 SL에서 ||는 이어붙이기 연산이다.
-
empno || '-' || ename
: empno 값과 ename 값을 '-'와 함께 이어 붙이기하고 그렇게 만들어진 필드의 이름을 emp_info로 설정한다.
-
-
필드명에 공백이 있거나 이해하기 어려운 필드명일때도 as로 별칭을 붙이기도 한다.
select empno as "사원 번호", ename as 사원성명 from emp;
(empno필드를 '사원 번호'별칭으로 출력하고, ename 필드를 '사원성명' 별칭으로 출력하라는 명령어) -
새로 생성된 필드명에는 공백이 있어서는 안된다.
다만 반드시 공백이 같이 있어야 한다면 위와 같이 " "로 묶어서 사용 -
이때 사용되는 필드명은 테이블에 입력된 필드값이 아니라, 필드의 이름으로 사용되므로 큰따옴표로 묶어 사용한다. (출력에서만 잠시 사용하는 것)
select MGR as manager_empno from emp;
🍂 특정 테이블의 모든 DATA 표시
select * from rentlist;
🍂 모든 컬럼(필드명)이 아닌, 필요한 필드만 조회
select subject, makeyear from booklist;
🍂 각각의 필드명에 별칭을 부여해서 출력
select subject as 도서제목, makeyear as 출판년도 from booklist;
- subject ➡️ 도서제목
- makeyear ➡️ 출판년도
🍂 중복 제거 : distinct
select distinct discount from rentlist;
- rentlist에서 membernum을 중복 제거 후 조회
select distinct membernum from rentlist;
연습
-
검색 조건의 추가 : 입고가격이 20000원 이상인 book 목록
select * from booklist where inprice>=20000; -
이름이 '홍'으로 시작하는 회원의 모든 회원정보 출력
select * from memberlist where name like '홍%'; -
1983년도 이후 태어난 회원의 모든 회원정보
select * from memberlist where birth>'82-12-31'; -
사은포인트(BPPOINT)가 250점 이상이고 82년 이후로 태어난 회원의 모든 회원 정보 (and, or 연산자 사용)
select * from memberlist where bpoint>=250 and birth>='82-01-01'; -
제작 년도가 2016년 이전이거나 입고 가격(inprice)이 18000 이하인 book 정보
select * from booklist where makeyear<=2016 or inprice<=18000; -
성명이 '이'로 시작하는 회원의 모든 회원 정보
select * from memberlist where name like '이%'; -
이름이 '서'로 끝나는 회원의 정보
select * from memberlist where name like '%서'; -
도서 제목에 '이'가 포함되는 도서 정보
select * from booklist where subject like '%이%'; -
memberlist에서 성별이 null이 아닌 회원의 이름과 전화번호
select * from memberlist where gender is null;
( =null 하면 에러는 안 나는데 결과도 안 나옴, null은 is 와 같이 쓰자!! ) -
성별이 null이 아닌 회원들만 조회
select * from memberlist where gender is not null; -
성별이 null인 회원의 성별을 모두 'M'으로 수정하기
update memberlist set gender='M' where gender is null; -
나이가 null인 회원의 나이를 모두 30세로 수정하기
update memberlist set age=30 where age is null; -
booklist에서 도서 제목에 두번째 글자가 '비'인 도서 정보
select * from booklist where subject like '_비%'; -
emp 테이블에서 deptno가 10, 20, 30, 40 중 하나인 데이터 모두
select * from emp where deptno=10 or deptno=20 or deptno=30 or deptno=40;
(간단히 쓰면 아래처럼 쓸 수도 있다.)
select * from emp where deptno in(10, 20, 30, 40);
조건식
- 조건식(ANY, SOME, ALL, (IN) )
: where 절에서 사용하는 그룹 내 해당 요소 찾기 함수들
⇒ IN과는 다르게 등호(=)가 사용되기도 한다.
1. ANY
- 부서번호가 10, 20, 30 중 하나인 사원의 모든 정보
select * from emp where deptno = any(10,20,30);
- ANY() 괄호 안에 나열된 내용 중 어느 하나라도 해당하는 것이 있다면 검색 대상으로 함
2. SOME 조건식 (ANY와 동일, IN과도 동일)
- 부서번호가 10, 20, 30 중 하나인 사원의 모든 정보
select * from emp where deptno = some(10,20,30);
3. ALL
-
select * from emp where sal = all(2000,3000,4000);
(에러는 없으나 적절한 사용 방법은 아님) -
select * from emp where sal <> all(2000, 3000, 4000);
-
'<>' : = 의 반대, 같지 않다. 자바의 !=과 동일한 연산
-
괄호 안의 모든 값이 동시에 만족해야하는 조건이므로 첫번째 문장에 해당하는 레코드가 없을 때가 대부분이다.
-
두 번째 사용 예처럼 모두와 다를 때를 위해 사용되곤 한다.
사용 빈도수가 낮음
4. 논리 조건식 not
-
select * from emp where deptno not in(10,20,40);
-
in() 안에 있는 것과 하나도 매칭 되지 않은 값이 검색 대상
정렬(Sort)
-
where 구문 뒤에, 또는 구문의 맨 끝에
Order by 필드명 [desc] -
select 명령의 결과를 특정 필드값의 오름차순이나 내림차순으로 정렬하라는 명령
-
asc : 오름차순 정렬, 쓰지 않으면 기본 오름차순 정렬로 실행
-
desc : 내림차순 정렬, 내림 차순 정렬을 위해서는 반드시 필드명 뒤에 써야하는 키워드
-
-
emp 테이블에서 sal이 1000 이상인 데이터를 ename의 오름차순으로 정렬하여 조회
select * from emp where sal>=1000 order by ename;
(오름차순 asc는 생략) -
emp 테이블에서 sal이 1000 이상인 데이터를 ename의 오름차순으로 정렬하여 조회
select * from emp where sal>=1000 order by ename; -
sal이 1000이상인 데이터를 ename의 내림차순으로 정렬하여 조회
select * from emp where sal>=1000 order by ename desc; -
위 예제와 같은 조건에 job으로 내림차순 정렬
select * from emp where sal>=1000 order by job desc; -
job으로 내림차순 정렬 후, 같은 job_id 사이에서는 순서를 hiredate의 내림차순으로 정렬
select * from emp order by job desc, hiredate desc;-
두 개 이상의 정렬 기준이 필요하다면 위와 같이 (,)로 구분해서 두가지 기준을 지정해준다.
-
위의 예제로 봤을 때 job으로 1차 내림차순 정렬하고,
같은 job값들 사이에 hiredate로 내림차순 정렬한다.
-
그 외 활용하기 좋은 select에 대한 예제
-
부서번호가 10이 아닌 사원 (아래 두 문장은 같은 의미의 명령)
select * from emp where not(deptno=10);
select * from emp where deptno <> 10; -
급여가 1000달러 이상, 3000달러 이하
select * from emp where sal>=1000 and sal<=3000;
select * from emp where sal between 1000 and 3000; -
특정 필드값이 null인 레코드 또는 널이 아닌 레코드
select * from emp where comm is null
( comm필드가 null인 레코드 )
select * from emp where comm is not null
( comm필드가 null이 아닌 레코드 ) -
사원의 연봉 출력
select deptno, ename, sal*12 as 연봉 from emp;
(deptno, ename을 출력하고 sal은 x12해서 연봉이라는 별칭으로 출력하기)
🌳 Function : 라이브러리 함수
오라클 명령어 : 내장 함수
-
샘플 테이블인 dual 테이블
select * from tab;➡️ 현재 관리하고 있는 테이블 목록
select * from dual;➡️ 내용 없는 테이블을 볼 수 있다. -
dual
: 테이블이 대상이 아닌 연산을 하려고 할 때 from 다음에 형식적으로 붙이는 없는 테이블의 이름 -
임시 데이터 출력
select 1234*1234 from dual;
🍂 문자열 처리 관련 함수
-
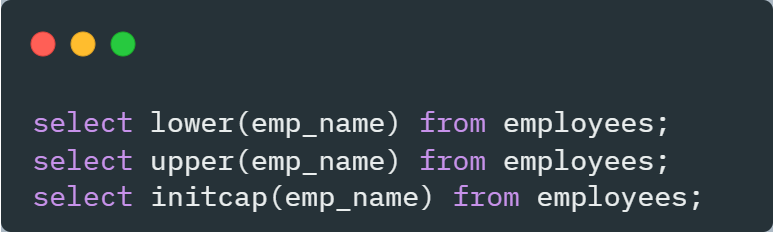
lower() : 모든 문자를 소문자로 변환
select lower('Hong Kil Dong') as "소문자" from dual; -
upper() : 모든 문자를 대문자로 변환
select upper('Hong Kil Dong') as "대문자" from dual; -
initcap() : 첫자만 대문자로 변환
select initcap('Hong Kil Dong') as "첫 글자만 대문자" from dual;- 테이블을 대상으로 하는 경우
- 테이블을 대상으로 하는 경우
-
connat() : 문자열 연결
select concat('이젠IT','아카데미') from dual;
select '이젠IT'||'아카데미' from dual; -
length() : 문자열의 길이
select length('이젠 아이티 아카데미'), length('The ezen IT') from dual; -
substr() : 문자열 추출(데이터, 인덱스(1), 카운트)
select substr('홍길동만세', 2, 4) from dual; ➡️ 길동만세- substr의 경우 자바 substring처럼 시작번째부터 끝번째+1이 아니라
- 시작번째부터 글자수를 나타냄 위의 경우 2번째글자부터 네글자 표시
(2번째부터 4개) - 인덱스도 0부터가 아니고 1부터 시작
-
instr() : 문자열 시작 위치
select instr('홍길동 만세 동그라미', '동') from dual;
➡️ 3 (세번째 글자가 '동'이므로 3 출력) -
lpad(), rpad() : 자리 채우기
-
select lpad('Oracle', 20, '#') from dual;
➡️ ####################Oracle
('Oracle' 왼쪽에 #을 20개 채우기) -
select rpad('Oracle', 20, '*') from dual;
➡️Oracle********************
('Oracle' 오른쪽에 별표를 20개 채우기)
-
-
trim()
: 컬럼이나 대상 문자열에서 특정 문자가 첫 글자이거나 마지막 글자이면 잘라내고 남은 문자열만 반환
select trim('a' from 'aaaOracleaaaaaaaa') as result from dual;
➡️ Oracle
select trim(' ' from ' Oracle ') as result from dual;
➡️ Oracle
( 작은 따옴표 사이에 빈칸 1개 = 공백 꼭 넣어야함)
🍂 수식 처리 관련 함수
-
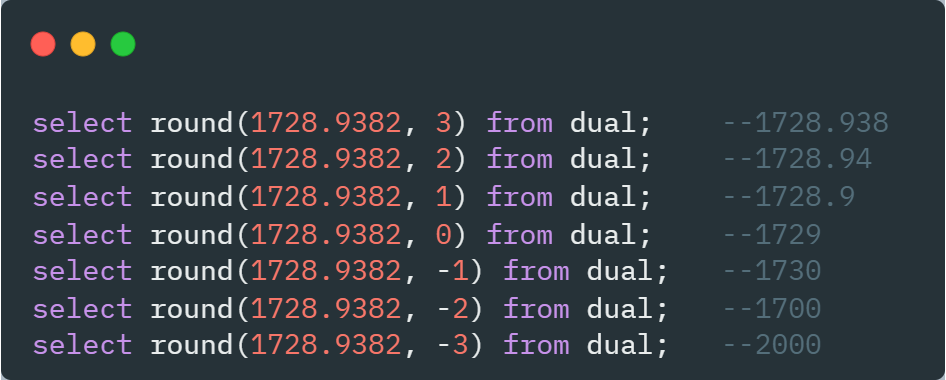
round() : 반올림(음수 : 소수점 이상 자리)
select round(12.3456, 3) from dual;
12.3456 : 반올림 하려는 대상 숫자 3
: 반올림하여 표시하고자 하는 마지막 자리수- 3 : 소수점 넷째 자리에서 반올림하여 셋째 자리까지 남김
- 2 : 소수점 셋째 자리에서 반올림하여 둘째 자리까지 남김
- 1 : 소수점 둘째 자리에서 반올림하여 첫째 자리까지 남김
- 0 : 소수점 첫째 자리에서 반올림하여 소수점 자리수 없앰
- -1 : 1의 자리에서 반올림하여 10자리까지 남김
- -2 : 10의 자리에서 반올림하여 100자리까지 남김
- -3 : 100의 자리에서 반올림하여 1000자리까지 남김
-
abs() : 절댓값
select abs(-10) from dual; -- 10 -
floor() : 소수점 아래 버림 - 반올림 없음
select floor(12.94567) from dual; ➡️ 12 -
ceil() : 소수점 올림
select ceil(12.94567) from dual; ➡️ 12 -
trunc() : 특정 자리 자르기 - 반올림 없음, 3은 남기고 싶은 소수점 아래 자리수
select trunc(12.34567, 3) from dual; ➡️ 12.345 -
mod() : 나머지 ( 8을 5로 나눈 나머지 )
select mod(8,5) from dual; ➡️ 3
🍂 날짜 처리 관련 함수
-
sysdate : 날짜
select sysdate from dual; ➡️ 오늘 날짜와 현재 시간 -
months_between() : 개월 수 구하기(s 빼먹지 말 것!!)
select floor( months_between('2021-12-31','2020-07-10')) from dual;
select months_between('2021-12-31','2020-07-10') from dual;- floor함수를 사용하지 않았을 때 : 17.677419...
- floor함수를 사용했을 때 : 17
-
add_months() : 개월 수 더하기
- 오늘 날짜부터 200개월 후의 날짜
select add_months(sysdate, 200) from dual;
➡️ 2039-07-17 14:33:30.0
- 오늘 날짜부터 200개월 후의 날짜
-
next_day() : 다가올 요일에 해당하는 날짜
-
오늘 날짜(sysdate)에서 가장 가까운 일요일
select next_day(sysdate, '일요일') from dual;
➡️ 2022-11-20 14:36:04.0 -
영어로 'sunday', 'SUN' 다 에러났음 검색해보니
반드시 해당 세션의 해당 국가의 언어로 써야 한단다..
주말에 다시 복습 & 학습하기
-
-
last_day() : 해당 달의 마지막 일 수
select last_day(sysdate) from dual;
➡️ 2022-11-30 14:36:04.0 (오늘이 있는 달, 이번 달)select last_day('2020-12-15') from dual;
➡️ 2020-12-31 00:00:00.0 -
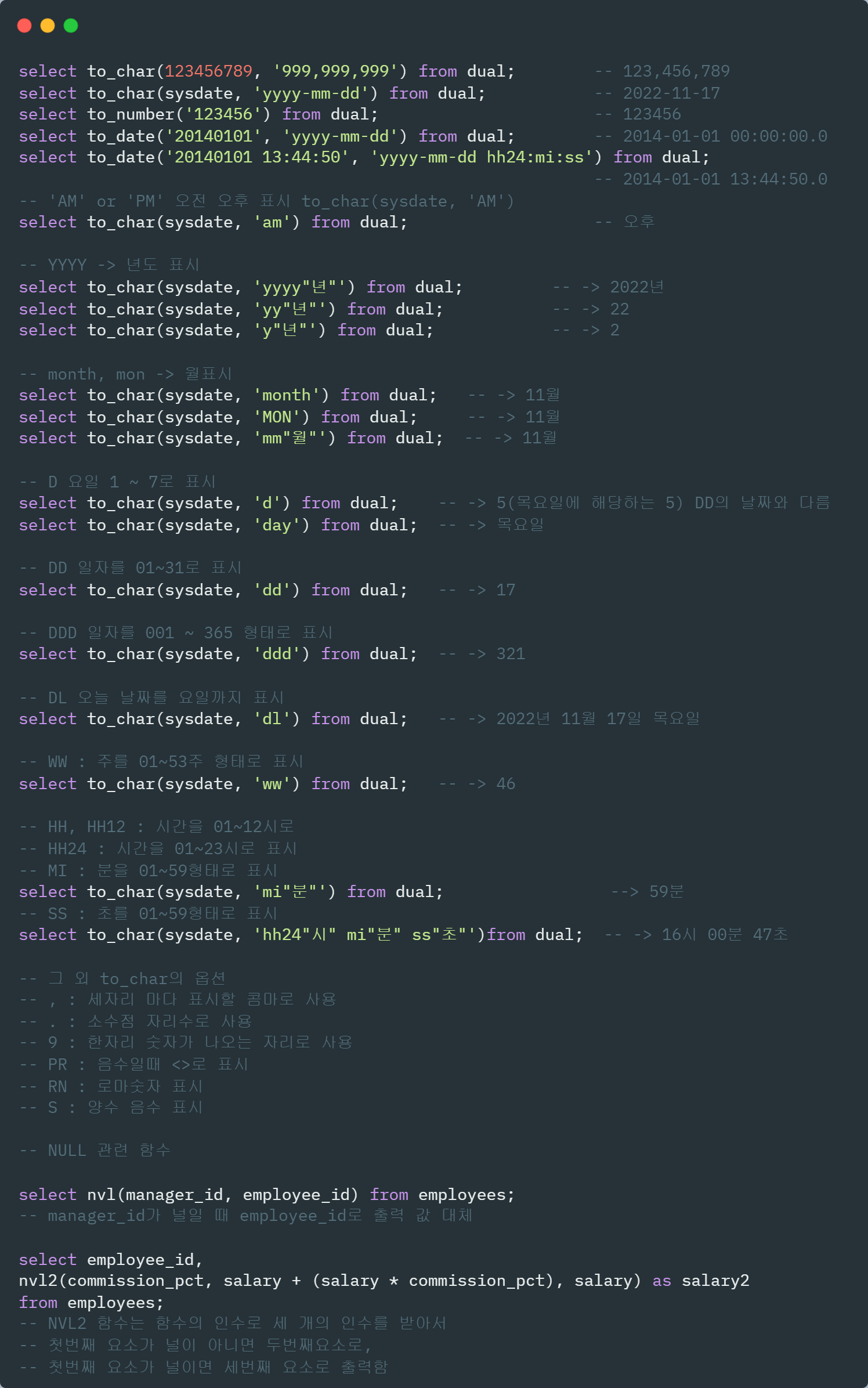
to_char() : 문자열로 반환
select to_char(sysdate, 'yyyy-mm-dd') from dual;
-
to_date() : 날짜형(date)으로 변환
select to_date('2019/12/31', 'yyyy/mm/dd') from dual;
🍂 그 외 활용 가능한 함수들
-
nvl() : NULL인 데이터를 다른 데이터로 변경
select comm/100 as comm_pct from emp;
comm 필드 값에 따라서 일부 레코드는 계산겨로가가 null이 나올 수 있음select nvl(comm, 1)/100 as comm_pct from emp;
해당 필드 값이 null 이면 1로 바꿔서 계산에 참여 -
POWER 함수
select power(3,2), power(3,3), power(3, 3.0001) from dual;
➡️ 9 / 27 / 27.xxxxxx
첫번째 요소값을 두번째 요소만큼 거듭 제곱 -
제곱근 SQRT
select SQRT(2), SQRT(5) from dual;
➡️ 제곱근 값이 출력 -
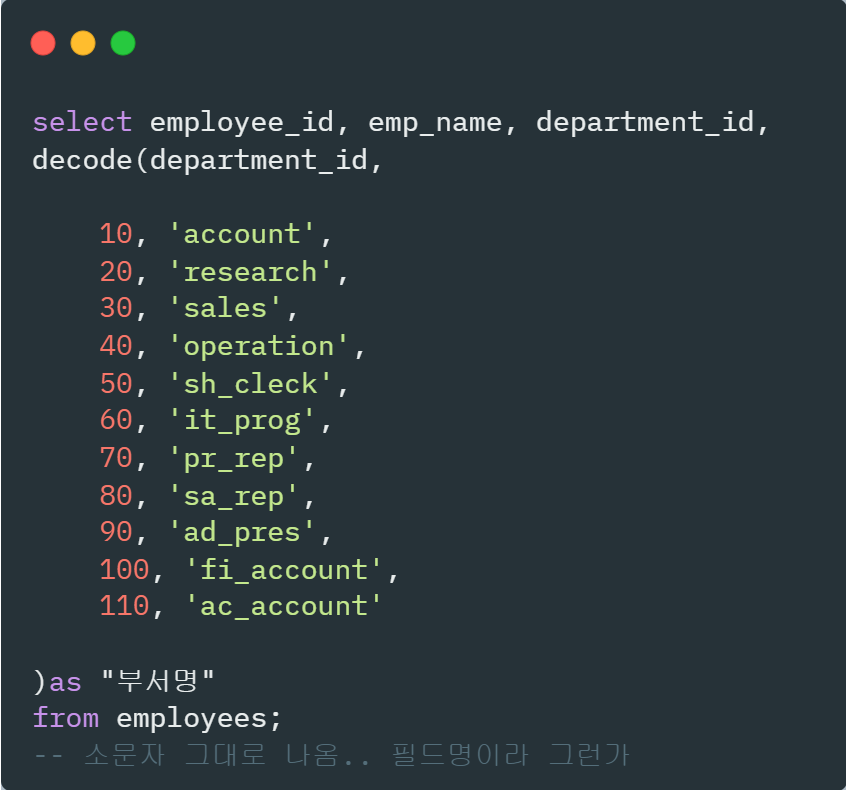
decode() : switch문과 같은 기능
-
case() : if ~ else if ~와 비슷한 구조

-
mod와 remainder
-
둘다 첫번째 요소를 두번재 요소로 나눈 나머지와 같은 값을 계산하지만 내부적 계산법이 조금 다름
select mod(19,4), mod(19.9, 4.2) from dual;
➡️ 어쨋든 양수 출력됨 4 / 4.xxx
select remainder(19,4), remainder(19.9, 4.2) from dual;
➡️ 음수가 출력이 됨 -
mod : 19-4 * floor(19/4)
-
remainder : 19-4 * round(19/4)
-
-
문자함수 replace
select replace ('나는 너를 모르는데 너는 나를 알겠는가?', '나', '너') from dual;
(문장의 '나'가 전부 '너'로 바뀜)-
replace(문자열1, 문자열2, 문자열3)
문자열 1에 있는 글자 중에 문자열2를 찾아서 문자열3으로 대체 -
select replace(' ABC DEF ', ' ', '') from dual
➡️ ABCDEF (빈칸(공백)을 빈칸없음 으로 대체)
-
-
컴퓨터의 뺄셈 (컴퓨터에는 사실 뺄셈이 없다?!)
- 70-23 -> 47
- 23의 보수 -> 100에서 23을 뺀 숫자: 77
- 77을 70에 합산 147
- 올림수를 버린다. -> 47
-
변환함수 : 정리해 놓고 필요할 때 찾아쓰기
🌳 Group Function
- sum() : 특정 필드의 합계

- count(*) : 필드내의 데이터 갯수(레코드 갯수)

-
avg : 평균
SELECT round( AVG(INPRICE) , 0 ) FROM booklist;
( booklist에서 inprice의 평균을 계산 후 round()로 소수점은 반올림 한 결과를 출력한다. )
-
MAX : 최대값
SELECT MAX(INPRICE) FROM booklist
-
MIN : 최소값
SELECT MIN(INPRICE) FROM booklist
-
VARIANCE(분산), STDDEV(표준편차)
SELECT VARIANCE(salary), STDDEV(salary) FROM employees;
🍂 group by
-
group by : 하나의 필드를 지목해서 같은 값끼리 그룹을 형성한 결과를 도출합니다
-
rentlist 테이블에서 할인금액 100, 200, 300일 때 건수 (각각 따로)

< 출력화면 >
| 할인금액 | 대여건수 | |
|---|---|---|
| 1 | 100 | 5 |
| 2 | 200 | 3 |
| 3 | 300 | 2 |
-
각 도서별 대여 건수 : 한번도 대여 안된 도서 제외

-
rentlist 날짜별 할인금액의 평균

-
rentlist 날짜별 대여 건수

-
employees 테이블의 부서id별 급여의 평균

-
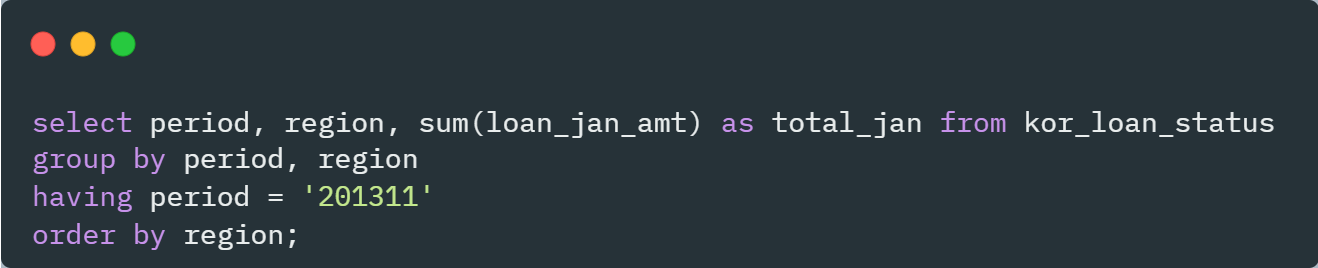
kor_loan_status 테이블의 period(년도와 월)을 1차 그룹으로 region(지역)을 2차 그룹으로 한 대출 잔액(loan_jan_amt)의 합계

🍂 HAVING 절 : 그룹핑된 내용들에 조건을 붙일 때
-
날짜별 할인 금액의 평균을 출력한다. 다만 그 평균 금액이 180 미만인 그룹만 출력
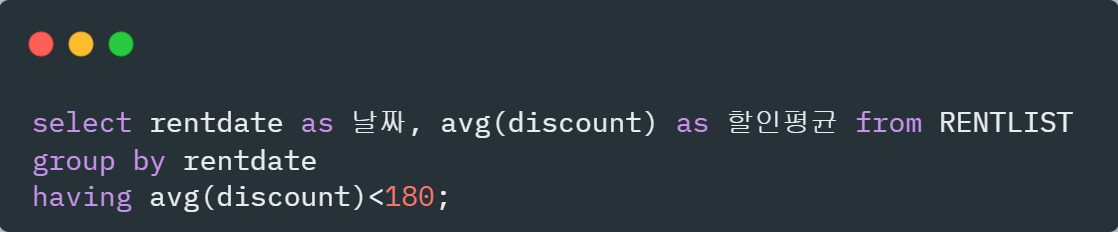
-
kor_loan_status 테이블의 날짜별 대출 잔액의 합계 중 period가 2013년 11월 인 데이터 출력
🌳 JOIN
데이터베이스의 특징
: 특징이기도 하지만 반드시 지켜져야할 규칙이기도 하다
-
계속적인 변화
: 데이터의 삽입(insert), 갱신(update), 삭제(delete) 작업을 통해 항상 최신의 데이터를 유지 -
실시간 접근
: 쿼리(Query-질의어:사용자가 사용하여 요청하는 sql문)에 대해 실시간 처리 응답을 할 수 있다(있어야 한다) -
동시접근, 동시공유
: 컴퓨터가 접근할 수 있는 저장매체에 저장되어 둘 이상의 사용자나 응용프로그램이 언제든지 동시에 이용할 수 있다. -
내용에의한 참조
: 데이터의 물리적 주소가 아닌 내용, 즉 데이터의 값에 의한 참조를 할 수 있다. -
데이터 중복의 최소화
: 동일한 자료는 중복되어 저장되지 않게 한다.
🌱 JOIN이란?
-
두 개 이상의 테이블에 나눠져있는 관련 데이터들을 하나의 테이블로 모아서 조회하고자 할 때 사용하는 명령
-
Douglas Grant가 근무하는 부서명을 출력하고자 한다면...
(대상 테이블은 employees, departments)-
select department_id from employees where emp_name='Douglas Grant';
-
위의 명령을 실행 후 얻어진 부서번호로 아래와 같이 부서번호 검색하여 부서명을 알아낸다.
-
select department_name from DEPARTMENTS where department_id=50;
-
-
위 두개의 명령을 하나의 명령으로 합해주는 역할을 join 명령이 실행
-
join
: 두개 이상의 테이블에 나누어져 있는 데이터를 한번의 sql문으로 원하는 결과를 얻는다.
🍂 cross join
: 두 개 이상의 테이블이 조인될 때 where절에 의해 공통되는 컬럼에 의한 결합이 발생하지 않는 경우
-
외래키로 연결되어 있지 않은 두 개의 테이블을 where절 없이 조인할 때가 최악의 결과가 나타난다.
-
가장 최악의 결과를 얻는 조인방식
-
A테이블과 B테이블의 cross join 된다면
-
A테이블의 1번 레코드와 B테이블의 모든 레코드와 하나하나 모두 조합
-
A테이블의 2번 레코드와 B테이블의 모든 레코드와 하나하나 모두 조합
-
A테이블의 3번 레코드와 B테이블의 모든 레코드와 하나하나 모두 조합
-
...
-
A테이블의 필드가 B,C,D가 있고 B테이블에 E,F,G가 있다면
크로스조인으로 합쳐진 테이블의 필드는 A,B,C,D,E,F,G가 된다. -
A테이블에 B C D 필드값이 1, 2, 3이 있고(레코드 한 개 존재)
B테이블에 E F G 필드값이 4, 5, 6하고 7, 8, 9가 있다면(레코드 2개) -
크로스 조인으로 합쳐진 테이블의 레코드는 1,2,3,4,5,6 하고 1,2,3,7,8,9 이렇게 두 개가 만들어진다.
-
위 A테이블에 4,5,6 값을 갖는 레코드가 하나 더 있다면
조인된 결과는 1 2 3 4 5 6 / 1 2 3 7 8 9 / 4 5 6 4 5 6 / 4 5 6 7 8 9
-
-
A테이블의 레코드가 8개, B테이블의 레코드가 7개 라면 총 크로즈조인의 결과 레코드 수는 8x7 = 56
-
A테이블의 필드가 8개, B테이블의 필드가 3개라면 총 크로스조인의 결과 필드 수는 8+3=11
select * from dept;-- 레코드 4, 필드 3
select * from emp;-- 레코드 14, 필드 8 -
크로스 조인
select * from DEPT, EMP;-- 레코드 56, 필드 11
🍂 equi join
: 조인 대상이 되는 두 테이블에서 공통적으로 존재하는 컬럼의 값이 일치하는 행을 연결하여 결과를 생성
select * from dept, EMP where emp.deptno = dept.deptno;
